
Riconoscimento delle Entità
Il Riconoscimento delle Entità è una capacità di NLP dell'IA che identifica e categorizza le entità nominate nel testo. Scopri come funziona, le sue applicazion...
11 min di lettura

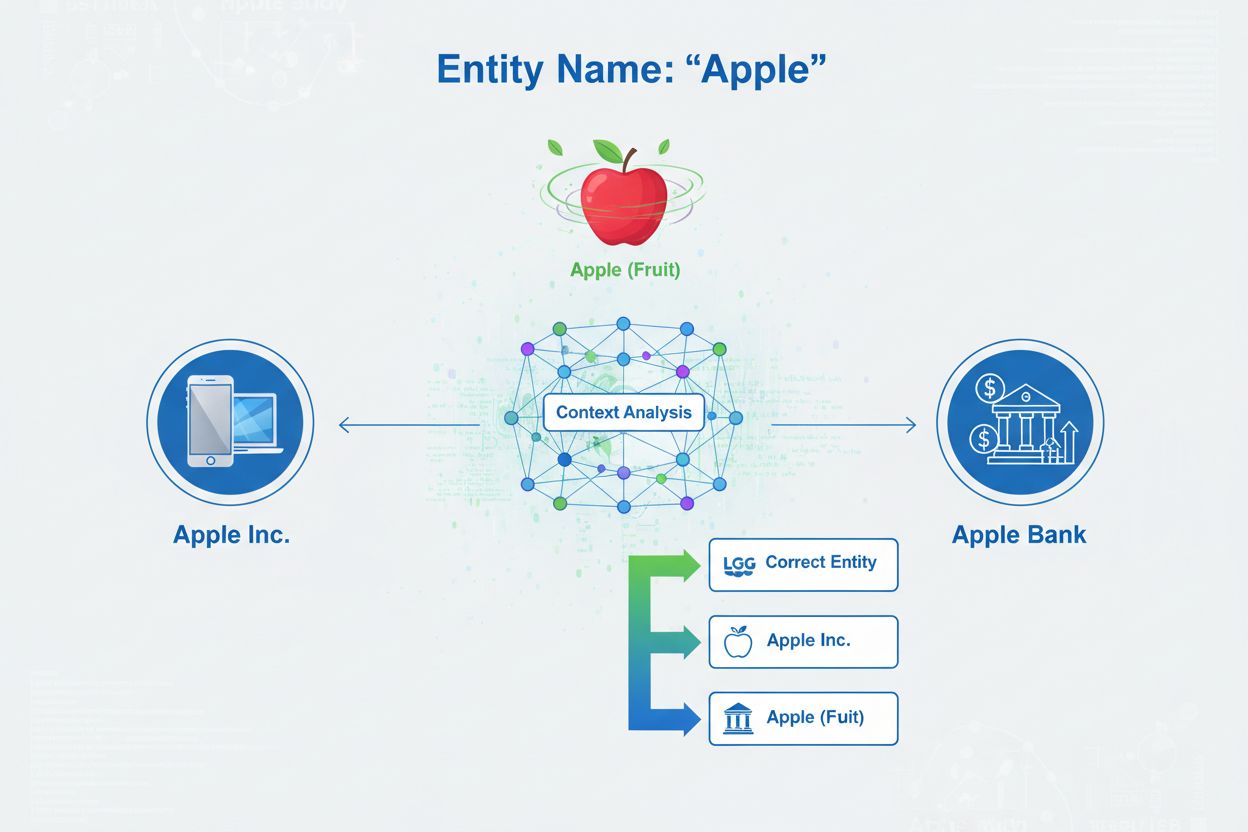
La disambiguazione delle entità è il processo di determinare a quale entità specifica si riferisce una determinata menzione quando più entità condividono lo stesso nome. Aiuta i sistemi di intelligenza artificiale a comprendere e citare accuratamente i contenuti risolvendo l’ambiguità nei riferimenti alle entità denominate, garantendo che le menzioni di ‘Apple’ identifichino correttamente se il riferimento sia ad Apple Inc., il frutto o un’altra entità con lo stesso nome.
La disambiguazione delle entità è il processo di determinare a quale entità specifica si riferisce una determinata menzione quando più entità condividono lo stesso nome. Aiuta i sistemi di intelligenza artificiale a comprendere e citare accuratamente i contenuti risolvendo l’ambiguità nei riferimenti alle entità denominate, garantendo che le menzioni di 'Apple' identifichino correttamente se il riferimento sia ad Apple Inc., il frutto o un’altra entità con lo stesso nome.
La disambiguazione delle entità è il processo di determinare a quale entità specifica si riferisce una determinata menzione quando più entità condividono lo stesso nome o riferimenti simili. Nel contesto dell’intelligenza artificiale e dell’elaborazione del linguaggio naturale (NLP), la disambiguazione delle entità assicura che, quando un sistema AI incontra un’entità nominata in un testo, identifichi correttamente quale oggetto, persona, organizzazione o luogo reale viene richiamato. Questo è fondamentalmente diverso dal riconoscimento di entità nominate (NER), che si limita a identificare la presenza di un’entità e a classificarla in una categoria come “persona”, “organizzazione” o “luogo”. Se il NER risponde alla domanda “C’è un’entità qui?”, la disambiguazione delle entità risponde a “Quale entità specifica è questa?”. Ad esempio, elaborando la frase “Apple è stata l’idea di Steve Jobs”, il NER identifica “Apple” come organizzazione, ma la disambiguazione determina se si tratta di Apple Inc., l’azienda tecnologica, o eventualmente un’altra entità con lo stesso nome. Questa distinzione è cruciale per i sistemi AI che devono comprendere e citare accuratamente i contenuti, motivo per cui AmICited.com monitora come sistemi AI come ChatGPT, Perplexity e Google AI Overviews gestiscono la disambiguazione delle entità nella generazione di risposte su brand e organizzazioni.
Il problema fondamentale che la disambiguazione delle entità risolve è l’ambiguità—la realtà che molti nomi di entità possono riferirsi a diversi oggetti reali. Questa ambiguità crea sfide significative per i sistemi AI che tentano di comprendere e generare contenuti accurati. Secondo lo Stanford AI Index 2024, oltre il 18% delle uscite di LLM che coinvolgono entità di brand contengono allucinazioni o attribuzioni errate, il che significa che i sistemi AI confondono frequentemente un’entità con un’altra o generano informazioni errate sulle entità. Questo tasso di errore ha serie implicazioni per la rappresentazione del brand e l’accuratezza dei contenuti. Quando un sistema AI identifica erroneamente un’entità, può fornire informazioni sbagliate, attribuire affermazioni all’organizzazione sbagliata o non citare la fonte corretta delle informazioni.
| Nome Entità | Possibili Significati | Tasso di Confusione AI |
|---|---|---|
| Apple | Azienda tecnologica / Frutto / Banca | Alto |
| Delta | Compagnia aerea / Azienda di rubinetti / Lettera greca | Alto |
| Jaguar | Casa automobilistica / Specie animale | Medio |
| Amazon | Azienda e-commerce / Foresta pluviale / Fiume | Alto |
| Orange | Colore / Frutto / Azienda di telecomunicazioni | Medio |
Le conseguenze di una cattiva disambiguazione delle entità vanno oltre i semplici errori fattuali. Per creatori di contenuti e brand, l’identificazione errata nelle risposte generate dalle AI può portare a perdita di visibilità, attribuzioni errate e danni alla reputazione del brand. Quando un utente chiede a un sistema AI informazioni su “Delta”, potrebbe cercare Delta Airlines, ma se il sistema la confonde con Delta Faucet Company, riceve informazioni non pertinenti. Questo è esattamente il motivo per cui AmICited.com monitora come i sistemi AI disambiguano le entità—per aiutare i brand a capire se vengono identificati e citati correttamente nei contenuti generati dalle AI su più piattaforme.
La disambiguazione delle entità opera attraverso un processo sistematico che combina diverse tecniche NLP per risolvere l’ambiguità e identificare correttamente le entità. Comprendere questo processo rivela perché alcuni sistemi AI offrono prestazioni migliori di altri nel mantenere l’accuratezza delle citazioni.
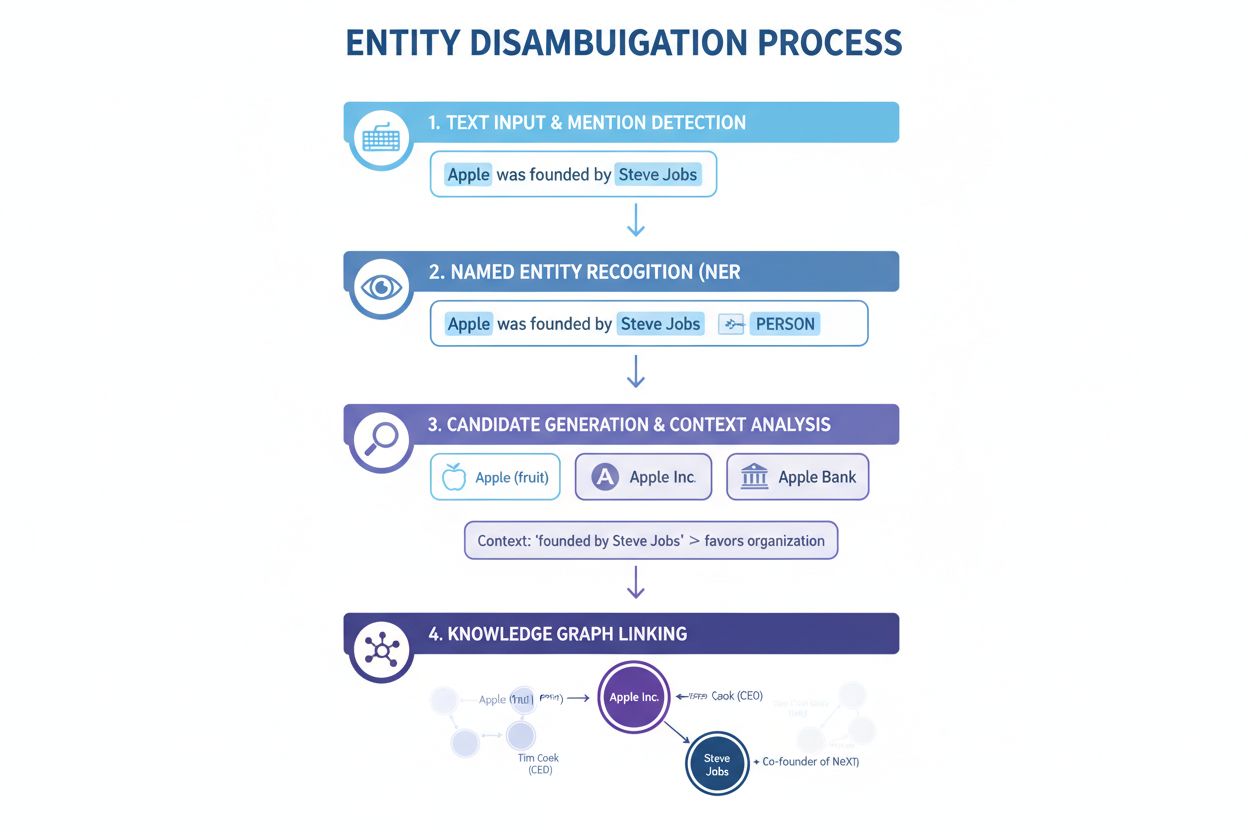
Riconoscimento di entità nominate (NER): Il primo passaggio consiste nell’identificare e classificare le entità nominate all’interno del testo. I sistemi NER scandagliano i dati testuali e individuano le menzioni di entità, assegnandole a categorie predefinite come persona, organizzazione, luogo, prodotto o data. Ad esempio, nella frase “Apple è stata l’idea di Steve Jobs”, il NER identifica sia “Apple” che “Steve Jobs” come entità e le classifica rispettivamente come organizzazione e persona. Questo passaggio è essenziale perché la disambiguazione non può avvenire senza prima identificare quali entità sono presenti nel testo.
Categorizzazione delle entità: Una volta identificate le entità, è necessario classificarle in modo più preciso. Non si tratta solo di una classificazione generale, ma di comprendere il tipo e il contesto specifico di ciascuna entità. Il sistema analizza il testo circostante per capire se “Apple” appare in un contesto tecnologico (suggerendo Apple Inc.), alimentare (il frutto) o finanziario (Apple Bank). Questa analisi contestuale aiuta a restringere le possibilità prima della disambiguazione vera e propria.
Disambiguazione: Questo è il passaggio centrale in cui il sistema determina quale entità specifica viene richiamata. Il sistema valuta più entità candidate che corrispondono al nome identificato e utilizza diversi segnali—tra cui contesto, descrizioni delle entità, relazioni semantiche e informazioni dai knowledge graph—per selezionare l’entità più probabile. Per “Apple è stata l’idea di Steve Jobs”, il sistema riconosce che Steve Jobs è fortemente associato ad Apple Inc., identificandola come l’entità corretta.
Collegamento alla knowledge base: Il passaggio finale consiste nel collegare l’entità disambiguata a un identificatore univoco in una knowledge base o un knowledge graph esterno, come Wikidata, Wikipedia o un database proprietario. Questo collegamento conferma l’identità dell’entità e arricchisce il testo con informazioni semantiche utilizzabili per ulteriori elaborazioni e analisi. All’entità viene assegnato un URI (Uniform Resource Identifier) univoco che funge da punto di riferimento definitivo.
Nel tempo si sono evoluti diversi approcci per la disambiguazione delle entità, ciascuno con vantaggi e limiti specifici. Comprendere questi approcci aiuta a spiegare perché i sistemi AI moderni variano nell’accuratezza della disambiguazione.
Approcci basati su regole: Questi sistemi utilizzano regole linguistiche predefinite e schemi euristici per disambiguare le entità. Potrebbero applicare regole come “se ‘Apple’ appare vicino a ‘iPhone’ o ‘MacBook’, si riferisce ad Apple Inc.” oppure “se ‘Delta’ appare vicino a ‘airline’ o ‘flight’, si riferisce a Delta Airlines”. Sebbene i sistemi basati su regole siano interpretabili e non richiedano grandi dataset di addestramento, fanno fatica con contesti nuovi e non possono adattarsi a nuovi significati senza aggiornare manualmente le regole.
Approcci di machine learning: I modelli di apprendimento supervisionato imparano da dati di addestramento annotati a prevedere l’entità corretta in base alle caratteristiche contestuali. Questi sistemi estraggono feature dal testo circostante e utilizzano algoritmi come Support Vector Machines o Random Forest per classificare l’entità più probabile. Gli approcci di machine learning sono più flessibili di quelli basati su regole, ma richiedono molti dati etichettati e possono non generalizzare bene a entità mai viste in addestramento.
Deep learning e modelli basati su Transformer: La moderna disambiguazione delle entità si basa sempre più su architetture Transformer come BERT, RoBERTa e modelli specializzati come GENRE e BLINK. Questi modelli utilizzano reti neurali per comprendere il contesto in modo più profondo, cogliendo relazioni semantiche e sfumature linguistiche. I Transformer raggiungono prestazioni superiori nei benchmark standard e sanno gestire meglio scenari di disambiguazione complessi. Ad esempio, il sistema CEEL (Common English Entity Linking) di Ontotext utilizza un’architettura basata su Transformer ottimizzata per l’efficienza su CPU mantenendo un’alta accuratezza: 96% nell’entità recognition e 76% nell’entità linking nei benchmark standard.
Integrazione dei knowledge graph: I sistemi moderni combinano sempre più spesso machine learning e knowledge graph—database strutturati che rappresentano entità e le loro relazioni. I knowledge graph forniscono informazioni contestuali ricche su entità, proprietà e relazioni. Interrogando i knowledge graph durante la disambiguazione, i sistemi possono accedere a metadati, descrizioni e relazioni che aiutano a risolvere l’ambiguità in modo più accurato.
La disambiguazione delle entità è diventata essenziale in numerosi settori e applicazioni, ognuno dei quali trae vantaggio da un’identificazione e una citazione accurate delle entità.
Motori di ricerca: Google, Bing e altri motori di ricerca si basano fortemente sulla disambiguazione delle entità per restituire risultati pertinenti. Quando un utente cerca “Apple”, il motore deve capire se interessa Apple Inc., il frutto o un’altra entità con quel nome. I motori utilizzano il contesto della query, la cronologia utente e i knowledge graph per disambiguare e restituire i risultati più rilevanti. Ecco perché nelle ricerche “Apple” appare generalmente prima l’azienda tecnologica—il sistema ha imparato che è l’entità più comunemente cercata.
Media e editoria: Organizzazioni di news e piattaforme di contenuti utilizzano la disambiguazione delle entità per migliorare la scoperta dei contenuti e collegare articoli correlati. Quando un articolo menziona “Apple”, il sistema può collegare automaticamente alla voce di Apple Inc. nella knowledge base, fornendo ai lettori contesto aggiuntivo e articoli correlati. Questo aumenta l’engagement e aiuta i lettori a comprendere il contesto più ampio delle notizie.
Sanità: Le istituzioni mediche usano la disambiguazione delle entità per identificare accuratamente farmaci, malattie e procedure nei record clinici e nella letteratura scientifica. Disambiguare i nomi dei farmaci è particolarmente critico—“aspirina” può riferirsi a un farmaco generico, a un marchio specifico o a una variante di dosaggio. Una disambiguazione accurata assicura che i professionisti sanitari accedano alle informazioni corrette e che le cartelle siano organizzate in modo appropriato.
Servizi finanziari: Società d’investimento e analisti finanziari utilizzano la disambiguazione delle entità per tracciare le menzioni di aziende su news, report finanziari e dati di mercato. Analizzando l’esposizione di mercato, un’azienda deve identificare con precisione tutte le menzioni di una specifica società tra fonti diverse. La disambiguazione garantisce che i riferimenti a “Apple” siano attribuiti correttamente ad Apple Inc. e non ad altre entità, consentendo una valutazione accurata dei rischi e delle analisi di portafoglio.
E-commerce: I rivenditori online usano la disambiguazione delle entità per associare le menzioni dei prodotti agli articoli reali nei loro cataloghi. Quando un cliente cerca “Apple laptop”, il sistema deve disambiguare “Apple” come azienda e associarla ai prodotti pertinenti. Questo migliora la precisione della ricerca e aiuta i clienti a trovare più facilmente ciò che cercano.
AmICited.com applica i principi della disambiguazione delle entità per monitorare come sistemi AI come ChatGPT, Perplexity e Google AI Overviews gestiscono le menzioni dei brand. Tracciando se questi sistemi disambiguano correttamente le entità e le citano accuratamente, AmICited aiuta i brand a comprendere la loro visibilità e rappresentazione nei contenuti generati dalle AI.
I knowledge graph sono diventati fondamentali nei sistemi moderni di disambiguazione delle entità, offrendo rappresentazioni strutturate delle entità e delle loro relazioni. Un knowledge graph è essenzialmente un database di entità (nodi) e delle relazioni tra loro (archi). Ogni nodo-entità contiene metadati come nome, descrizione, tipo e proprietà dell’entità. Ad esempio, in un knowledge graph, l’entità “Apple Inc.” può avere proprietà come “fondata nel 1976”, “sede a Cupertino”, “settore: tecnologia” e relazioni come “fondata da Steve Jobs” e “produce iPhone”.
Quando un sistema di disambiguazione delle entità incontra una menzione ambigua, può interrogare il knowledge graph per accedere a informazioni contestuali sulle entità candidate. Queste informazioni aiutano il sistema a prendere decisioni di disambiguazione più informate. Se, ad esempio, il sistema deve disambiguare “Apple” e il testo circostante menziona “Steve Jobs”, può interrogare il knowledge graph per scoprire che Steve Jobs è fortemente associato ad Apple Inc., rendendo quest’ultima l’entità corretta. Knowledge graph come Wikidata e Wikipedia forniscono informazioni pubblicamente disponibili che molte AI utilizzano durante l’inferenza. Knowledge graph proprietari realizzati da organizzazioni come Google, Microsoft e altri forniscono informazioni di dominio ancora più specifiche. L’integrazione dei knowledge graph con i modelli di machine learning ha notevolmente migliorato l’accuratezza della disambiguazione, poiché i sistemi possono ora combinare pattern appresi e informazioni strutturate di fatto.
Nonostante i notevoli progressi, i sistemi di disambiguazione delle entità affrontano ancora diverse sfide che ne limitano l’accuratezza e l’applicabilità.
Polisemia e ambiguità: Molti nomi di entità hanno più significati legittimi e il solo contesto può non bastare a disambiguarli. “Bank” può riferirsi a una banca o alla riva di un fiume. “Crane” può essere un uccello o una gru da costruzione. Alcuni nomi sono così ambigui che anche gli umani faticano a determinarne il significato senza contesto aggiuntivo. I sistemi AI devono imparare a riconoscere quando il contesto è insufficiente e gestire questi casi con attenzione.
Nuove entità emergenti: Knowledge base e dati di addestramento diventano obsoleti man mano che emergono nuove entità. Quando nasce una nuova azienda o viene lanciato un nuovo prodotto, i sistemi di disambiguazione potrebbero non avere informazioni aggiornate. Lo zero-shot entity linking—la capacità di disambiguare entità mai viste in addestramento—resta una sfida. I sistemi devono riconoscere quando un’entità è nuova e gestirla correttamente invece di associarla erroneamente a un’entità esistente.
Variazioni di nome ed errori di ortografia: Le entità hanno spesso nomi, abbreviazioni e varianti diversi. “Stati Uniti”, “USA”, “U.S.” e “America” si riferiscono alla stessa entità. Errori di ortografia complicano ulteriormente la disambiguazione. I sistemi devono riconoscere queste varianti e mapparle correttamente all’entità canonica. Questo è particolarmente difficile nei contenuti generati dagli utenti, dove gli errori sono frequenti.
Dati incompleti o obsoleti: Le knowledge base possono contenere informazioni incomplete o diventare obsolete con il tempo. Una sede aziendale può cambiare, la leadership può variare o una società può essere acquisita. Se la knowledge base non viene aggiornata tempestivamente, i sistemi di disambiguazione potrebbero prendere decisioni basate su dati superati.
Scalabilità e performance: Elaborare grandi quantità di testo con disambiguazione delle entità ad alta precisione richiede risorse computazionali considerevoli. La disambiguazione in tempo reale per applicazioni su vasta scala è costosa. I sistemi devono bilanciare accuratezza, velocità e costi, spesso con compromessi che riducono la qualità della disambiguazione.
Per brand e creatori di contenuti, comprendere la disambiguazione delle entità è essenziale per garantire una rappresentazione corretta nei contenuti generati dalle AI. Con l’influenza crescente dei sistemi AI nella scoperta e nel consumo delle informazioni, i brand devono adottare misure proattive per assicurarsi di essere disambiguati e citati correttamente.
Strategie di pre-disambiguazione: I brand possono adottare strategie per rendere le proprie entità più facili da disambiguare per i sistemi AI. Questo prevede la creazione di segnali digitali chiari e distintivi che aiutino le AI a identificare il brand in modo univoco. Una strategia chiave è l’implementazione di dati strutturati tramite marcatura Schema.org e formato JSON-LD sui siti web del brand. Questi dati strutturati comunicano esplicitamente alle AI l’identità del brand, incluso nome ufficiale, descrizione, logo, sede e altre caratteristiche distintive. Quando le AI incontrano il nome del brand, possono fare riferimento a questi dati per confermare l’entità corretta.
Ottimizzazione per knowledge graph: I brand dovrebbero assicurarsi una forte presenza nei principali knowledge graph come Wikidata e Wikipedia. Questo implica creare o mantenere voci accurate su Wikipedia, assicurarsi che le entry su Wikidata siano complete e aggiornate, e costruire relazioni tra l’entità del brand e quelle correlate. Più la presenza nei knowledge graph è completa e accurata, più informazioni avranno le AI per la disambiguazione.
Strategia di contenuto contestuale: I brand possono creare contenuti che forniscano un contesto chiaro sulla propria identità e li differenzino da altre entità con nomi simili. Contenuti che menzionano esplicitamente settore, prodotti, fondatori e proposta di valore aiutano le AI a cogliere le caratteristiche distintive. Questo contenuto contestuale diventa parte dei dati di addestramento e del contesto usato dalle AI per la disambiguazione.
Monitoraggio delle citazioni: Strumenti come AmICited.com consentono ai brand di monitorare come le AI disambiguano e citano il proprio brand sulle diverse piattaforme. Tracciando se ChatGPT, Perplexity, Google AI Overviews e altri sistemi identificano e citano correttamente il brand, è possibile individuare errori di disambiguazione e intervenire. Questo monitoraggio è fondamentale per comprendere la visibilità del brand nell’era della generazione AI.
Ottimizzazione per i motori generativi (GEO): Poiché la disambiguazione delle entità diventa sempre più importante per la visibilità AI, i brand dovrebbero integrare l’ottimizzazione dell’entità nella propria strategia complessiva di Generative Engine Optimization. Ciò significa assicurarsi che l’entità sia chiaramente definita, ben documentata e facilmente distinguibile da entità concorrenti. La GEO comprende non solo la SEO tradizionale, ma anche l’ottimizzazione di come le AI comprendono e rappresentano i brand.
La disambiguazione delle entità continua ad evolversi con l’avanzare della tecnologia AI e l’emergere di nuove sfide. Diversi trend stanno plasmando il futuro di questa capacità fondamentale.
Disambiguazione multilingue: Con la globalizzazione delle AI, la capacità di disambiguare entità in più lingue è sempre più importante. Un nome può essere scritto in modo diverso nelle varie lingue, e la stessa entità può essere indicata con nomi diversi in contesti linguistici differenti. Si stanno sviluppando modelli multilingue avanzati per gestire la disambiguazione cross-lingua, consentendo sistemi AI veramente globali.
Disambiguazione in tempo reale nei Large Language Model: I moderni LLM come GPT-4 e Claude stanno integrando sempre più la disambiguazione delle entità in tempo reale durante la generazione del testo. Invece di basarsi solo sui dati di addestramento, questi modelli possono interrogare knowledge graph e database esterni in fase di inferenza per verificare le informazioni e garantire la disambiguazione accurata. Questa funzione migliora l’accuratezza delle citazioni e riduce le allucinazioni.
Miglioramento dello zero-shot learning: I futuri sistemi di disambiguazione delle entità avranno probabilmente prestazioni migliori sulle entità mai viste in addestramento. I progressi nelle tecniche few-shot e zero-shot learning consentiranno di disambiguare nuove entità in modo più efficace, riducendo la necessità di riaddestramenti frequenti e rendendo i sistemi più adattabili.
Integrazione con la Retrieval-Augmented Generation (RAG): I sistemi RAG che combinano language model e information retrieval stanno diventando sempre più popolari. Questi sistemi possono recuperare informazioni pertinenti sulle entità dai knowledge base durante la generazione del testo, migliorando l’accuratezza della disambiguazione e delle citazioni. Questa integrazione rappresenta un passo avanti nell’assicurare che le AI citino le fonti correttamente.
Standardizzazione e interoperabilità: Con la crescente importanza della disambiguazione delle entità, è probabile che emergano standard industriali per la rappresentazione e la disambiguazione delle entità. Questi standard consentiranno una migliore interoperabilità tra sistemi e knowledge base differenti, facilitando l’accesso e l’uso coerente delle informazioni sulle entità tra piattaforme.
La disambiguazione delle entità si è evoluta da compito di nicchia NLP a capacità fondamentale per assicurare che le AI comprendano e rappresentino accuratamente le informazioni. Con l’aumentare dell’influenza delle AI sulla scoperta e il consumo delle informazioni, l’importanza di una disambiguazione accurata crescerà ulteriormente. Per brand, creatori di contenuti e organizzazioni, comprendere e ottimizzare la disambiguazione delle entità è essenziale per mantenere la visibilità e garantire una rappresentazione corretta nell’era dell’AI generativa.
Il riconoscimento di entità nominate identifica che esiste un’entità in un testo e la classifica in categorie come persona, organizzazione o luogo. La disambiguazione delle entità va oltre determinando quale entità specifica viene richiamata quando più entità condividono lo stesso nome. Ad esempio, il NER identifica 'Apple' come un’organizzazione, mentre la disambiguazione delle entità determina se si tratta di Apple Inc., Apple Bank o un’altra entità.
La disambiguazione delle entità garantisce che i sistemi AI comprendano accuratamente quale entità viene discussa e la citino correttamente. Secondo lo Stanford AI Index 2024, oltre il 18% delle uscite di LLM che coinvolgono entità di brand contengono allucinazioni o attribuzioni errate. Una disambiguazione accurata delle entità impedisce ai sistemi AI di confondere un’entità con un’altra, fondamentale per mantenere la reputazione del brand e l’accuratezza delle citazioni.
I knowledge graph forniscono informazioni strutturate sulle entità e le loro relazioni. Quando un sistema AI incontra una menzione ambigua di entità, può interrogare il knowledge graph per accedere a metadati, descrizioni e informazioni sulle relazioni delle entità candidate. Queste informazioni contestuali aiutano il sistema a prendere decisioni di disambiguazione più informate e a selezionare l’entità corretta.
Sì, tramite approcci di entity linking zero-shot. I sistemi moderni possono riconoscere quando un’entità è nuova e gestirla correttamente invece di associarla in modo errato a un’entità esistente. Tuttavia, questo rimane un problema complesso, e i sistemi funzionano meglio quando le nuove entità presentano segnali contestuali chiari che le distinguono da quelle già esistenti.
Una disambiguazione accurata delle entità garantisce che il tuo brand sia identificato e citato correttamente nelle risposte generate dalle AI. Quando i sistemi AI disambiguano correttamente il tuo brand, gli utenti ricevono informazioni accurate sulla tua organizzazione, migliorando visibilità e reputazione. Una disambiguazione errata può portare a confondere il tuo brand con concorrenti o altre entità, riducendo la visibilità e potenzialmente danneggiando la reputazione.
Le sfide principali includono la polisemia (più significati per lo stesso nome), nuove entità non presenti nei dati di addestramento, variazioni dei nomi ed errori di ortografia, knowledge base incomplete o obsolete e problemi di scalabilità. Inoltre, alcuni nomi di entità sono intrinsecamente ambigui e il solo contesto potrebbe non bastare per determinare l’entità corretta.
I brand possono implementare dati strutturati tramite marcatura Schema.org, mantenere voci accurate su Wikipedia e Wikidata, creare contenuti contestuali che distinguano chiaramente il brand e monitorare come i sistemi AI disambiguano il proprio brand con strumenti come AmICited. Queste strategie aiutano i sistemi AI a identificare e citare correttamente il tuo brand.
Il contesto è fondamentale per la disambiguazione delle entità. Il testo circostante, le entità correlate e le relazioni semantiche forniscono segnali che aiutano i sistemi AI a determinare quale entità viene richiamata. Ad esempio, se 'Apple' compare vicino a 'Steve Jobs' e 'tecnologia', il sistema può usare questo contesto per disambiguare correttamente come Apple Inc. invece che il frutto.
Traccia l’accuratezza della disambiguazione delle entità sulle piattaforme AI e assicurati che il tuo brand sia identificato e citato correttamente nelle risposte generate dalle AI.
Il Riconoscimento delle Entità è una capacità di NLP dell'IA che identifica e categorizza le entità nominate nel testo. Scopri come funziona, le sue applicazion...

Scopri come costruire la visibilità delle entità nella ricerca AI. Padroneggia l’ottimizzazione dei knowledge graph, lo schema markup e le strategie di entity S...

Scopri come rafforzare l'entità del tuo brand per la visibilità nella ricerca AI. Ottimizza per ChatGPT, Perplexity, Google AI Overviews e Claude con strategie ...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.