
Architettura Transformer
L'Architettura Transformer è una progettazione di rete neurale che utilizza meccanismi di self-attention per processare dati sequenziali in parallelo. Alimenta ...
17 min di lettura
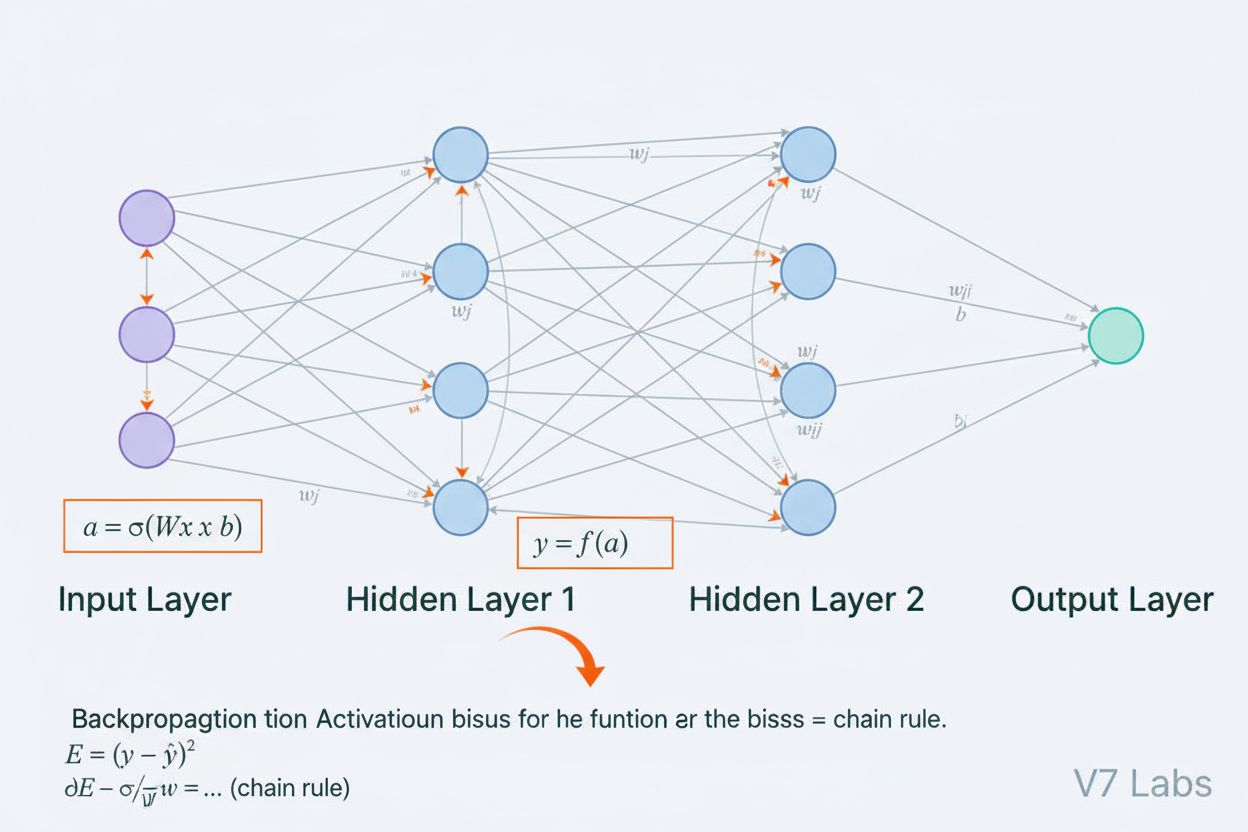
Una rete neurale è un sistema di calcolo ispirato alle reti neurali biologiche che consiste in neuroni artificiali interconnessi organizzati in strati, capaci di apprendere schemi dai dati attraverso un processo chiamato retropropagazione. Questi sistemi costituiscono la base dell’intelligenza artificiale moderna e del deep learning, alimentando applicazioni che vanno dall’elaborazione del linguaggio naturale alla visione artificiale.
Una rete neurale è un sistema di calcolo ispirato alle reti neurali biologiche che consiste in neuroni artificiali interconnessi organizzati in strati, capaci di apprendere schemi dai dati attraverso un processo chiamato retropropagazione. Questi sistemi costituiscono la base dell’intelligenza artificiale moderna e del deep learning, alimentando applicazioni che vanno dall’elaborazione del linguaggio naturale alla visione artificiale.
Una rete neurale è un sistema di calcolo fondamentalmente ispirato alla struttura e alla funzione delle reti neurali biologiche presenti nei cervelli animali. È composta da neuroni artificiali interconnessi organizzati in strati—tipicamente uno strato di input, uno o più strati nascosti e uno strato di output—che lavorano insieme per elaborare dati, riconoscere schemi e fare previsioni. Ogni neurone riceve input, applica trasformazioni matematiche tramite pesi e bias, e passa il risultato attraverso una funzione di attivazione per produrre un output. La caratteristica distintiva delle reti neurali è la loro capacità di apprendere dai dati tramite un processo iterativo chiamato retropropagazione, in cui la rete regola i propri parametri interni per minimizzare gli errori di previsione. Questa capacità di apprendimento, unita alla loro abilità di modellare relazioni complesse non lineari, ha reso le reti neurali la tecnologia fondamentale che alimenta i moderni sistemi di intelligenza artificiale, dai grandi modelli di linguaggio alle applicazioni di visione artificiale.
Il concetto di reti neurali artificiali è emerso dai primi tentativi di modellare matematicamente il modo in cui i neuroni biologici comunicano ed elaborano informazioni. Nel 1943, Warren McCulloch e Walter Pitts proposero il primo modello matematico di un neurone, dimostrando che semplici unità computazionali potevano eseguire operazioni logiche. Questa base teorica fu seguita dall’introduzione del percettrone di Frank Rosenblatt nel 1958, un algoritmo progettato per il riconoscimento di schemi che divenne l’antenato storico delle moderne architetture di reti neurali. Il percettrone era essenzialmente un modello lineare con output vincolato, capace di apprendere semplici confini decisionali. Tuttavia, il campo subì importanti battute d’arresto negli anni ’70 quando si scoprì che i percettroni a strato singolo non potevano risolvere problemi non lineari come la funzione XOR, portando alla cosiddetta “invernata dell’IA”. La svolta arrivò negli anni ’80 con la riscoperta e il perfezionamento della retropropagazione, un algoritmo che permise di addestrare reti multilivello. Questa rinascita ha subito un’accelerazione drammatica negli anni 2010 grazie alla disponibilità di enormi dataset, potenti GPU e tecniche di addestramento raffinate, portando alla rivoluzione del deep learning che ha trasformato l’intelligenza artificiale.
L’architettura di una rete neurale comprende diversi componenti essenziali che lavorano insieme. Lo strato di input riceve le caratteristiche grezze dei dati da fonti esterne, con ogni neurone di questo strato che corrisponde a una caratteristica. Gli strati nascosti svolgono il lavoro computazionale più intenso, trasformando gli input in rappresentazioni sempre più astratte tramite combinazioni pesate e funzioni di attivazione non lineari. Il numero e la dimensione degli strati nascosti determinano la capacità della rete di apprendere schemi complessi—reti più profonde possono catturare relazioni più sofisticate ma richiedono più dati e risorse computazionali. Lo strato di output produce le previsioni finali, la cui struttura dipende dal compito: un solo neurone per la regressione, più neuroni per la classificazione multiclasse o architetture specializzate per altre applicazioni. Ogni connessione tra neuroni trasporta un peso che determina l’intensità dell’influenza, mentre ogni neurone possiede un bias che ne sposta la soglia di attivazione. Questi pesi e bias sono i parametri apprendibili che la rete regola durante l’addestramento. La funzione di attivazione applicata a ciascun neurone introduce la fondamentale non-linearità, permettendo alla rete di apprendere confini decisionali e schemi complessi che i modelli lineari non possono catturare.
Le reti neurali apprendono attraverso un processo iterativo in due fasi. Durante la propagazione in avanti, i dati di input scorrono attraverso la rete dallo strato di input a quello di output. In ogni neurone viene calcolata la somma pesata degli input più il bias (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b), quindi il risultato passa attraverso una funzione di attivazione per produrre l’output del neurone. Questo processo si ripete in ciascuno strato nascosto fino a raggiungere lo strato di output, che genera la previsione della rete. Viene poi calcolato l’errore tra la previsione della rete e l’etichetta reale tramite una funzione di perdita, che quantifica quanto la previsione sia distante dalla risposta corretta. Nella retropropagazione, questo errore viene propagato all’indietro attraverso la rete utilizzando la regola della catena del calcolo differenziale. In ogni neurone, l’algoritmo calcola il gradiente della perdita rispetto a ciascun peso e bias, determinando quanto ciascun parametro ha contribuito all’errore complessivo. Questi gradienti guidano l’aggiornamento dei parametri: pesi e bias vengono regolati nella direzione opposta al gradiente, scalati da un tasso di apprendimento che controlla l’ampiezza dei passi. Questo processo si ripete per molte iterazioni sul dataset di addestramento, riducendo gradualmente la perdita e migliorando le previsioni della rete. La combinazione di propagazione in avanti, calcolo della perdita, retropropagazione e aggiornamento dei parametri costituisce il ciclo completo di addestramento che permette alle reti neurali di apprendere dai dati.
| Tipo di Architettura | Caso d’Uso Principale | Caratteristica Chiave | Punti di Forza | Limitazioni |
|---|---|---|---|---|
| Reti Feedforward | Classificazione, regressione su dati strutturati | Le informazioni scorrono solo in una direzione | Semplici, addestramento veloce, interpretabili | Non gestiscono bene dati sequenziali o spaziali |
| Reti Neurali Convoluzionali (CNN) | Riconoscimento immagini, visione artificiale | Strati convoluzionali rilevano caratteristiche spaziali | Ottime nel catturare pattern locali, efficienti nei parametri | Richiedono grandi dataset di immagini etichettate |
| Reti Neurali Ricorrenti (RNN) | Dati sequenziali, serie temporali, NLP | Lo stato nascosto mantiene la memoria tra i passi temporali | Possono processare sequenze di lunghezza variabile | Soffrono di gradiente che svanisce/esplode |
| Long Short-Term Memory (LSTM) | Dipendenze a lungo termine in sequenze | Celle di memoria con gate di input/forget/output | Gestiscono efficacemente dipendenze di lungo termine | Più complesse, addestramento più lento delle RNN |
| Reti Transformer | Elaborazione linguaggio naturale, grandi modelli linguistici | Meccanismo di attenzione multi-head, elaborazione parallela | Altamente parallelizzabili, catturano dipendenze a lungo raggio | Richiedono risorse computazionali enormi |
| Generative Adversarial Networks (GANs) | Generazione immagini, creazione dati sintetici | Generatore e discriminatore che competono | Possono generare dati sintetici realistici | Difficili da addestrare, problemi di mode collapse |
L’introduzione delle funzioni di attivazione rappresenta una delle innovazioni più cruciali nel design delle reti neurali. Senza funzioni di attivazione, una rete neurale sarebbe matematicamente equivalente a una singola trasformazione lineare, indipendentemente dal numero di strati. Questo perché la composizione di funzioni lineari è ancora una funzione lineare, limitando fortemente la capacità della rete di apprendere schemi complessi. Le funzioni di attivazione risolvono questo problema introducendo non-linearità in ogni neurone. La ReLU (Rectified Linear Unit), definita come f(x) = max(0, x), è diventata la scelta più popolare nel deep learning moderno grazie alla sua efficienza computazionale ed efficacia nell’addestramento di reti profonde. La funzione sigmoid, f(x) = 1/(1 + e^(-x)), comprime l’output tra 0 e 1, risultando utile nei compiti di classificazione binaria. La funzione tanh, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), restituisce valori tra -1 e 1 e spesso si comporta meglio della sigmoid negli strati nascosti. La scelta della funzione di attivazione influenza significativamente le dinamiche di apprendimento della rete, la velocità di convergenza e le prestazioni finali. Le architetture moderne usano spesso la ReLU negli strati nascosti per la sua efficienza computazionale e sigmoid o softmax negli strati di output per la stima delle probabilità. La non-linearità introdotta dalle funzioni di attivazione permette alle reti neurali di approssimare qualsiasi funzione continua, una proprietà nota come teorema di approssimazione universale, che ne spiega la straordinaria versatilità in applicazioni eterogenee.
Il mercato delle reti neurali ha registrato una crescita esplosiva, riflettendo il ruolo centrale di questa tecnologia nell’intelligenza artificiale moderna. Secondo recenti ricerche di mercato, il mercato globale dei software per reti neurali è stato valutato intorno a 34,76 miliardi di dollari nel 2025 e si prevede che raggiunga 139,86 miliardi di dollari entro il 2030, con un tasso di crescita annuale composto (CAGR) del 32,10%. Il mercato più ampio delle reti neurali mostra un’espansione ancora più drammatica, con stime che indicano una crescita da 34,05 miliardi di dollari nel 2024 a 385,29 miliardi di dollari entro il 2033, con un CAGR del 31,4%. Questa crescita esplosiva è trainata da diversi fattori: la crescente disponibilità di grandi set di dati, lo sviluppo di algoritmi di addestramento più efficienti, la proliferazione di GPU e hardware specializzati per l’IA, e l’adozione diffusa delle reti neurali in tutti i settori. Secondo l’AI Index Report di Stanford 2025, il 78% delle organizzazioni ha dichiarato di utilizzare l’IA nel 2024, rispetto al 55% dell’anno precedente, con le reti neurali che costituiscono la spina dorsale della maggior parte delle implementazioni aziendali di IA. L’adozione spazia dalla sanità alla finanza, dalla manifattura al retail e praticamente in ogni altro settore, poiché le organizzazioni riconoscono il vantaggio competitivo fornito dai sistemi basati su reti neurali per il riconoscimento di schemi, la previsione e il supporto decisionale.
Le reti neurali alimentano i sistemi di IA più avanzati oggi disponibili, tra cui ChatGPT, Perplexity, Google AI Overviews e Claude. Questi grandi modelli linguistici sono costruiti su architetture di reti neurali basate su transformer che sfruttano meccanismi di attenzione per elaborare e generare linguaggio umano con straordinaria sofisticazione. L’architettura transformer, introdotta nel 2017, ha rivoluzionato l’elaborazione del linguaggio naturale permettendo l’elaborazione parallela di intere sequenze invece della tradizionale elaborazione sequenziale, migliorando drasticamente l’efficienza dell’addestramento e le prestazioni dei modelli. Nel contesto del monitoraggio del brand e del tracciamento delle citazioni IA, comprendere le reti neurali è cruciale perché questi sistemi utilizzano reti neurali per comprendere il contesto, recuperare informazioni rilevanti e generare risposte che possono fare riferimento o citare il tuo brand, dominio o contenuto. AmICited sfrutta la conoscenza di come le reti neurali elaborano e recuperano informazioni per monitorare dove appare il tuo brand nelle risposte generate dalle IA su più piattaforme. Man mano che le reti neurali migliorano nella comprensione semantica e nel recupero di informazioni rilevanti, diventa sempre più fondamentale monitorare la presenza del proprio brand nelle risposte IA per mantenere la visibilità e gestire la reputazione online nell’era della ricerca e generazione di contenuti guidate dall’intelligenza artificiale.
L’addestramento efficace delle reti neurali presenta numerose sfide che ricercatori e professionisti devono affrontare. L’overfitting si verifica quando una rete apprende troppo bene i dati di addestramento, inclusi rumore e peculiarità, con conseguente scarsa performance su dati nuovi e mai visti. Questo è particolarmente problematico per le reti profonde che hanno molti parametri rispetto alla dimensione del dataset. L’underfitting rappresenta il problema opposto, dove la rete non ha capacità sufficiente o addestramento adeguato per catturare i pattern sottostanti nei dati. Il problema del gradiente che svanisce si presenta nelle reti molto profonde dove i gradienti diventano esponenzialmente piccoli nella retropropagazione, causando aggiornamenti dei pesi negli strati iniziali molto lenti o assenti. Il problema del gradiente che esplode è l’opposto, con gradienti estremamente grandi che rendono l’addestramento instabile. Le soluzioni moderne includono la batch normalization, che normalizza gli input degli strati per mantenere il flusso stabile dei gradienti; le connessioni residue (skip connection), che permettono ai gradienti di fluire direttamente attraverso gli strati; e il clipping dei gradienti, che limita la loro ampiezza. Le tecniche di regolarizzazione come L1 e L2 aggiungono penalità per pesi grandi, incoraggiando modelli più semplici e generalizzabili. Il dropout disattiva casualmente neuroni durante l’addestramento, prevenendo la co-adattazione e migliorando la generalizzazione. La scelta dell’ottimizzatore (come Adam, SGD o RMSprop) e il learning rate influenzano fortemente l’efficienza dell’addestramento e le prestazioni finali del modello. È necessario bilanciare attentamente la complessità del modello, la dimensione dei dati, la forza della regolarizzazione e i parametri di ottimizzazione per ottenere reti che apprendano efficacemente senza sovradattarsi.
L’evoluzione delle architetture di reti neurali ha seguito una traiettoria chiara verso meccanismi sempre più sofisticati per l’elaborazione delle informazioni. Le prime reti feedforward erano limitate a input di dimensione fissa e non potevano catturare dipendenze temporali o sequenziali. Le reti neurali ricorrenti (RNN) hanno introdotto loop di feedback che permettono alle informazioni di persistere tra i passi temporali, abilitando l’elaborazione di sequenze di lunghezza variabile. Tuttavia, le RNN soffrivano di problemi nella propagazione del gradiente e risultavano intrinsecamente sequenziali, impedendo la parallelizzazione su hardware moderno. Le reti LSTM hanno risolto parzialmente questi problemi tramite celle di memoria e meccanismi di gating, ma rimanevano fondamentalmente sequenziali. La svolta è arrivata con le reti transformer, che hanno sostituito completamente la ricorrenza con i meccanismi di attenzione. Il meccanismo di attenzione permette alla rete di focalizzarsi dinamicamente su diverse parti dell’input, calcolando combinazioni pesate di tutti gli elementi in parallelo. Ciò consente ai transformer di catturare dipendenze a lungo raggio in modo efficiente, mantenendo la piena parallelizzabilità su cluster GPU. L’architettura transformer, combinata con la scala massiccia (i moderni grandi modelli linguistici contengono miliardi o trilioni di parametri), si è dimostrata estremamente efficace per NLP, visione artificiale e compiti multimodali. Il successo dei transformer li ha resi lo standard per le architetture IA all’avanguardia, inclusi tutti i principali grandi modelli linguistici. Questa evoluzione dimostra come le innovazioni architetturali, unite a maggiori risorse computazionali e dataset più grandi, continuino ad ampliare i limiti di ciò che le reti neurali possono raggiungere.
Il campo delle reti neurali continua a evolversi rapidamente con diverse direzioni promettenti. Il neuromorphic computing mira a realizzare hardware che imiti più da vicino le reti neurali biologiche, con potenziale per maggiore efficienza energetica e potenza computazionale. La ricerca su few-shot e zero-shot learning punta a permettere alle reti neurali di apprendere da pochissimi esempi, avvicinandosi alle capacità di apprendimento umano. Spiegabilità e interpretabilità stanno diventando sempre più importanti, con tecniche per comprendere e visualizzare cosa apprendono le reti neurali, fondamentali per applicazioni critiche come sanità, finanza e giustizia. L’apprendimento federato consente di addestrare reti neurali su dati distribuiti senza centralizzare informazioni sensibili, affrontando le problematiche di privacy. Le reti neurali quantistiche rappresentano una frontiera dove i principi del calcolo quantistico sono combinati con le architetture neurali, potenzialmente offrendo accelerazioni esponenziali per certi problemi. Le reti neurali multimodali che integrano testo, immagini, audio e video stanno diventando sempre più sofisticate, abilitando sistemi di IA più completi. Si stanno sviluppando anche reti neurali a basso consumo energetico per ridurre i costi computazionali e ambientali dell’addestramento e deployment di grandi modelli. Con l’avanzare delle reti neurali, la loro integrazione in sistemi di monitoraggio IA come AmICited diventa sempre più importante per le organizzazioni che vogliono comprendere e gestire la presenza del proprio brand nei contenuti e nelle risposte generate dall’IA su piattaforme come ChatGPT, Perplexity, Google AI Overviews e Claude.
Le reti neurali sono ispirate dalla struttura e dalla funzione dei neuroni biologici nel cervello umano. Nel cervello, i neuroni comunicano tramite segnali elettrici attraverso le sinapsi, che possono essere rafforzate o indebolite in base all’esperienza. Le reti neurali artificiali imitano questo comportamento utilizzando modelli matematici di neuroni connessi tramite collegamenti pesati, permettendo al sistema di apprendere e adattarsi dai dati in modo analogo a come i cervelli biologici elaborano informazioni e formano ricordi.
La retropropagazione è l’algoritmo principale che permette alle reti neurali di apprendere. Durante la propagazione in avanti, i dati scorrono attraverso gli strati della rete producendo previsioni. La rete calcola quindi l’errore tra le uscite previste e quelle reali utilizzando una funzione di perdita. Nella fase inversa, questo errore viene retropropagato attraverso la rete usando la regola della catena del calcolo differenziale, calcolando quanto ciascun peso e ciascun bias abbia contribuito all’errore. I pesi vengono quindi aggiornati nella direzione che minimizza l’errore, tipicamente utilizzando l’ottimizzazione tramite discesa del gradiente.
Le principali architetture di reti neurali includono le reti feedforward (il flusso dei dati avviene in una sola direzione), le reti neurali convoluzionali o CNN (ottimizzate per l’elaborazione di immagini), le reti neurali ricorrenti o RNN (progettate per dati sequenziali), le reti LSTM (RNN migliorate con celle di memoria) e le reti transformer (che sfruttano meccanismi di attenzione per l’elaborazione parallela). Ogni architettura è specializzata per diversi tipi di dati e compiti, dal riconoscimento di immagini all’elaborazione del linguaggio naturale.
I moderni sistemi di IA come ChatGPT, Perplexity e Claude sono costruiti su reti neurali basate su architetture transformer, che utilizzano meccanismi di attenzione per elaborare il linguaggio in modo efficiente. Queste reti neurali permettono a tali sistemi di comprendere il contesto, generare testi coerenti ed eseguire compiti di ragionamento complesso. La capacità delle reti neurali di apprendere da enormi moli di dati e catturare schemi intricati nel linguaggio le rende fondamentali per costruire IA conversazionali in grado di comprendere e rispondere alle richieste umane con notevole accuratezza.
I pesi nelle reti neurali controllano l’intensità delle connessioni tra i neuroni, determinando quanto ogni input influisce sull’output. I bias sono parametri aggiuntivi che spostano la soglia di attivazione dei neuroni, permettendo loro di attivarsi anche quando gli input sono deboli. Insieme, pesi e bias costituiscono i parametri apprendibili della rete che vengono regolati durante l’addestramento per minimizzare gli errori di previsione e permettere alla rete di apprendere schemi complessi dai dati.
Le funzioni di attivazione introducono non-linearità nelle reti neurali, permettendo di apprendere relazioni complesse e non lineari nei dati. Senza funzioni di attivazione, anche impilando più strati si otterrebbero solo trasformazioni lineari, limitando fortemente la capacità di apprendimento della rete. Le funzioni di attivazione più comuni includono ReLU (Rectified Linear Unit), sigmoid e tanh, ciascuna delle quali introduce diversi tipi di non-linearità che aiutano la rete a catturare schemi intricati e a produrre previsioni più sofisticate.
Gli strati nascosti sono strati intermedi tra input e output in cui la rete svolge la maggior parte delle operazioni di calcolo. Questi strati estraggono e trasformano le caratteristiche dai dati grezzi in rappresentazioni sempre più astratte. La profondità e la larghezza degli strati nascosti determinano la capacità della rete di apprendere schemi complessi. Reti più profonde con più strati nascosti possono catturare relazioni più sofisticate nei dati, anche se richiedono maggiori risorse computazionali e un addestramento accurato per evitare l’overfitting.
Inizia a tracciare come i chatbot AI menzionano il tuo brand su ChatGPT, Perplexity e altre piattaforme. Ottieni informazioni utili per migliorare la tua presenza AI.
L'Architettura Transformer è una progettazione di rete neurale che utilizza meccanismi di self-attention per processare dati sequenziali in parallelo. Alimenta ...
Il Net Promoter Score (NPS) è una metrica di fedeltà del cliente che misura la probabilità di raccomandazione. Scopri come calcolare l'NPS, interpretare i punte...

Scopri cosa sono le Reti di Syndication dei Contenuti AI, come funzionano e perché sono essenziali per la distribuzione moderna dei contenuti. Scopri come l’ott...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.