
Cos'è il meta tag noai e come protegge i tuoi contenuti dall'IA?
Scopri cos'è il meta tag noai, come funziona per impedire la raccolta di dati per il training AI, le sue limitazioni e come implementarlo sul tuo sito web per p...
8 min di lettura

Un tag meta HTML che segnala ai sistemi di addestramento AI e ai web crawler che i contenuti del sito web non devono essere utilizzati per l’addestramento di modelli di apprendimento automatico. Introdotto originariamente da DeviantArt, serve come meccanismo di protezione dei contenuti e segnale di opt-out per i creatori preoccupati della raccolta non autorizzata di dati da parte dell’AI.
Un tag meta HTML che segnala ai sistemi di addestramento AI e ai web crawler che i contenuti del sito web non devono essere utilizzati per l’addestramento di modelli di apprendimento automatico. Introdotto originariamente da DeviantArt, serve come meccanismo di protezione dei contenuti e segnale di opt-out per i creatori preoccupati della raccolta non autorizzata di dati da parte dell’AI.
Il tag meta NoAI è un meccanismo di protezione dei contenuti implementato come tag meta HTML che segnala ai sistemi di addestramento AI e ai web crawler che i contenuti di un sito web non devono essere utilizzati per l’addestramento di modelli di machine learning. Introdotto originariamente da DeviantArt nel settembre 2022, la direttiva NoAI è nata come risposta dal basso alle preoccupazioni riguardanti le opere degli artisti raccolte e usate per addestrare modelli AI generativi senza consenso o compenso. Il tag meta funziona aggiungendo una semplice dichiarazione HTML nell’header della pagina web, comunicando una preferenza chiara ai sistemi AI affinché i contenuti non siano usati a fini di addestramento. Sebbene non sia giuridicamente vincolante nella maggior parte delle giurisdizioni, il tag NoAI rappresenta un importante meccanismo di opt-out per i creatori che desiderano proteggere la propria proprietà intellettuale in un’epoca di raccolta dati AI sempre più aggressiva.
I web crawler (detti anche bot, spider o scraper) sono programmi software automatizzati che navigano sistematicamente in Internet, seguendo i link e scaricando contenuti da indicizzare, analizzare o raccogliere per diversi scopi. Questi crawler operano leggendo il file robots.txt situato nella directory principale di un sito, che contiene istruzioni su quali aree del sito debbano o meno essere accessibili ai visitatori automatizzati. Il file robots.txt utilizza direttive specifiche come User-agent, Disallow e Allow per comunicare i permessi ai crawler, anche se la conformità è del tutto volontaria e dipende dal fatto che lo sviluppatore del crawler scelga di rispettare queste linee guida. Oltre a robots.txt, i siti possono comunicare preferenze tramite header HTTP e meta tag, che forniscono segnali aggiuntivi sui diritti e le restrizioni d’uso dei contenuti. I diversi tipi di crawler manifestano diversi livelli di rispetto verso questi segnali:
| Tipo di Crawler | Conformità robots.txt | Rispetto Meta Tag | Uso per Addestramento AI |
|---|---|---|---|
| Motori di ricerca | Alta | Alta | Limitato |
| Bot AI Training | Media | Media | Sì |
| Scraper commerciali | Bassa | Bassa | Variabile |
| Bot accademici | Alta | Media | Solo ricerca |
| Bot malevoli | Nessuna | Nessuna | Senza restrizioni |
Le direttive noai e noimageai assolvono a scopi correlati ma distinti nella protezione dei contenuti, con la differenza principale nel loro ambito e specificità. La direttiva noai è un segnale più ampio che indica che tutti i contenuti di una pagina—including testo, immagini, codice e altri media—non devono essere utilizzati per l’addestramento AI, rendendola adatta a siti con contenuti misti o che cercano una protezione completa. La direttiva noimageai, invece, prende di mira specificamente solo i contenuti immagini, consentendo che testo e altri materiali non visivi possano essere usati per l’addestramento mentre protegge gli asset visivi dai modelli AI generativi. Questa distinzione è particolarmente importante per i siti che vogliono consentire l’indicizzazione AI sul testo (ad esempio per motori di ricerca o accessibilità) ma proteggere i contenuti visivi dall’addestramento di modelli di immagini generative. Ecco le differenze di implementazione:
<!-- Protezione completa per tutti i contenuti -->
<meta name="robots" content="noai">
<!-- Protezione specifica solo per le immagini -->
<meta name="robots" content="noimageai">
<!-- Approccio combinato per massima chiarezza -->
<meta name="robots" content="noai, noimageai">
Il tag meta NoAI può essere implementato in diversi modi, ciascuno con vantaggi diversi a seconda dell’infrastruttura tecnica e delle esigenze specifiche. Il metodo più semplice è l’aggiunta diretta del tag meta nella sezione <head> dell’HTML, che applica la direttiva alle singole pagine e può essere personalizzato pagina per pagina se necessario. Per siti con molte pagine o che cercano una soluzione a livello globale, implementare la direttiva tramite header di risposta HTTP offre un approccio più scalabile che si applica uniformemente a tutti i contenuti senza modifiche individuali. Inoltre, il file robots.txt può includere direttive specifiche per crawler AI, anche se questo metodo è meno standardizzato rispetto ai meta tag o agli header. Ecco i tre principali metodi di implementazione:
<!-- Metodo 1: Tag Meta HTML (il più comune) -->
<head>
<meta name="robots" content="noai">
</head>
# Metodo 2: direttiva robots.txt
User-agent: *
Disallow: /
X-Robots-Tag: noai
# Metodo 3: HTTP Header (tramite .htaccess o configurazione server)
X-Robots-Tag: noai
Per server Apache, aggiungi a .htaccess:
<FilesMatch "\.(html|php)$">
Header set X-Robots-Tag "noai"
</FilesMatch>
Per server Nginx, aggiungi nel blocco server:
add_header X-Robots-Tag "noai" always;
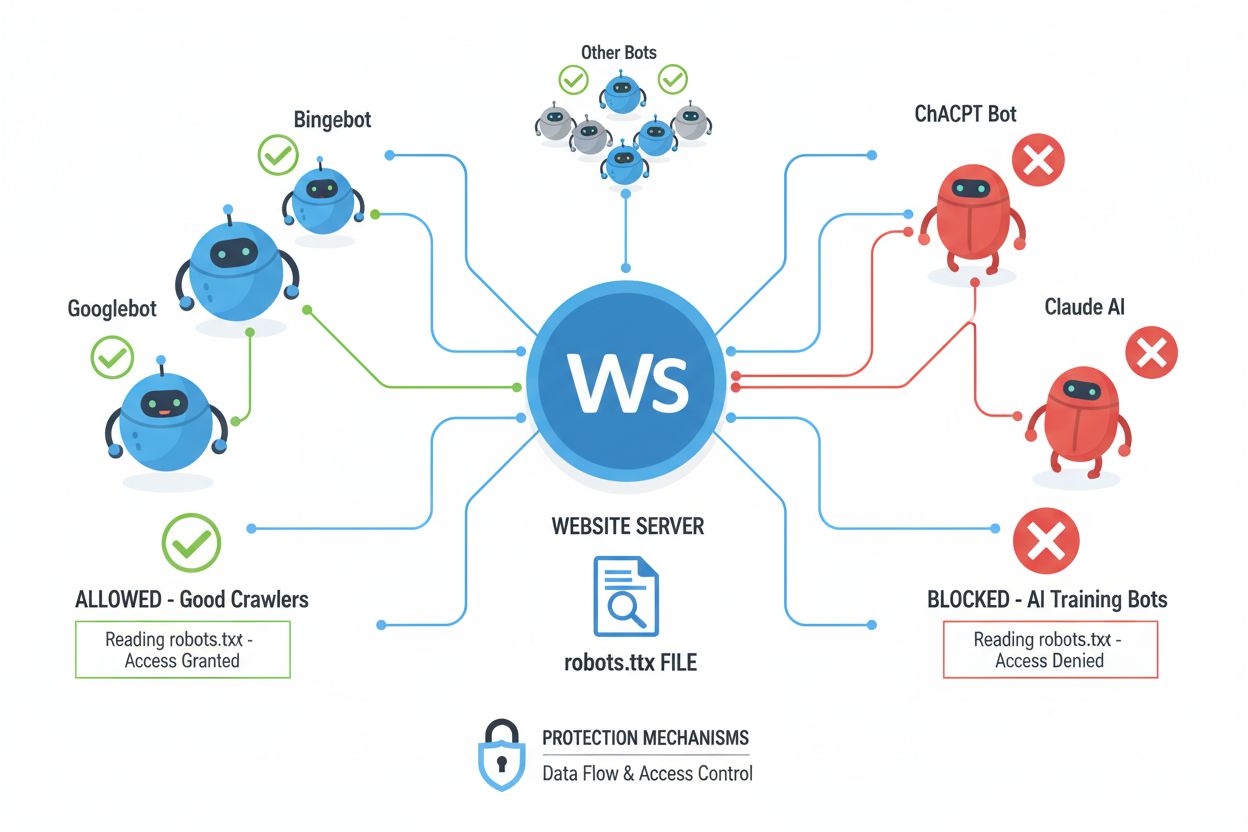
Sebbene il tag meta NoAI rappresenti un passo importante verso la protezione dei contenuti, opera su un sistema d’onore che dipende interamente dal fatto che sviluppatori AI e scraper scelgano di rispettare il segnale. Le principali aziende AI come OpenAI, Google e Anthropic hanno iniziato a rispettare le direttive NoAI nei loro crawler, ma malintenzionati e scraper non autorizzati spesso ignorano questi segnali, rendendo il tag inefficace contro chi è determinato a sottrarre dati. L’efficacia di NoAI è ulteriormente limitata dal fatto che previene solo l’addestramento futuro sui contenuti; non può rimuovere dati già raccolti e utilizzati in modelli esistenti né offre ricorso legale in caso di violazione. I tassi di conformità variano notevolmente tra i diversi sistemi AI, con alcuni che rispettano la direttiva e altri che la eludono deliberatamente, rendendo NoAI una soluzione utile ma incompleta. Il tag inoltre non protegge da download diretti, screenshot o copie manuali dei contenuti, né può impedire l’uso dei tuoi contenuti da parte di concorrenti che semplicemente ignorano la direttiva. Per questi motivi, NoAI va considerato uno strato di una strategia di protezione dei contenuti più ampia, non una soluzione completa.
Il tag meta NoAI ha raggiunto un’ampia adozione tra le principali aziende e piattaforme AI, con OpenAI, Google e Stability AI che si sono pubblicamente impegnate a rispettare la direttiva nei loro processi di addestramento. L’implementazione di NoAI da parte di DeviantArt ha influenzato le conversazioni di settore sull’etica nello sviluppo AI e sul consenso dei creatori, aumentando la consapevolezza sia tra gli sviluppatori AI sia tra i creatori di contenuti. Tuttavia, l’adozione rimane disomogenea nel settore, con aziende AI minori, ricercatori accademici e scraper commerciali che mostrano livelli di conformità variabili. L’emergere di standard concorrenti come C2PA (Coalition for Content Provenance and Authenticity) e le discussioni su diritti esprimibili in modo leggibile dalle macchine suggeriscono che il settore si stia muovendo verso meccanismi di protezione dei contenuti più sofisticati e sostenuti da basi legali rispetto ai semplici meta tag volontari. Organizzazioni di settore e enti di standardizzazione stanno lavorando per formalizzare queste protezioni, con la prospettiva che le future normative AI possano richiedere il rispetto esplicito delle preferenze dei creatori di contenuti, trasformando potenzialmente NoAI da un segnale volontario a un requisito giuridicamente vincolante.
L’implementazione della protezione NoAI dovrebbe far parte di un approccio stratificato alla sicurezza dei contenuti, e non una soluzione isolata, combinando strategie tecniche, legali e di monitoraggio per una protezione completa. Per massimizzare l’efficacia, considera queste best practice:
Inoltre, effettua audit regolari della tua implementazione di protezione dei contenuti per assicurarti che tutte le pagine includano le direttive appropriate e considera l’uso di strumenti automatici per scansionare la presenza dei tuoi contenuti nei dataset AI pubblici e nei repository di addestramento. Documenta la tua implementazione NoAI come parte della policy di governance dei contenuti e comunica queste protezioni al tuo pubblico, in modo che comprenda quali misure stai adottando per tutelare il suo lavoro se sei una piattaforma che ospita contenuti generati dagli utenti.
La direttiva noai protegge tutti i tipi di contenuto (testo, immagini, codice) dall’addestramento AI, mentre noimageai protegge specificamente solo i contenuti immagini. Usa noai per una protezione completa e noimageai quando vuoi consentire l’indicizzazione del testo ma proteggere gli asset visivi dai modelli di generazione immagini.
No, il tag meta NoAI si basa su un sistema d’onore e dipende dal fatto che gli sviluppatori AI scelgano di rispettarlo. Grandi aziende come OpenAI e Google lo rispettano, ma i malintenzionati e scraper non autorizzati spesso ignorano questi segnali, rendendolo uno strato di protezione e non una soluzione completa.
Puoi implementarlo in tre modi: aggiungendo il tag meta HTML nell’header della pagina, impostando header di risposta HTTP sul server oppure includendo direttive nel file robots.txt. Il metodo del tag meta HTML è il più comune e semplice per la maggior parte dei proprietari di siti.
Le principali aziende AI, tra cui OpenAI (ChatGPT), Google, Anthropic (Claude) e Stability AI, si sono pubblicamente impegnate a rispettare le direttive NoAI nei loro processi di addestramento. Tuttavia, la conformità varia tra aziende AI più piccole, ricercatori accademici e scraper commerciali.
Sì, puoi usare entrambi simultaneamente per la massima efficacia. Il tag meta NoAI e le direttive robots.txt lavorano insieme per comunicare le tue preferenze di protezione dei contenuti a diversi tipi di crawler e sistemi.
Combina NoAI con altri metodi di protezione, inclusi header HTTP, regole robots.txt, watermarking, controlli di accesso e termini legali di servizio. Monitora i tuoi contenuti nei dataset AI e valuta l’uso di strumenti per tracciare utilizzi non autorizzati.
Sebbene ampiamente adottato dalle principali aziende AI, NoAI non è ancora uno standard formale W3C. Tuttavia, le organizzazioni di settore stanno lavorando a standard più sofisticati come C2PA e diritti leggibili dalle macchine che potrebbero fornire una base legale in futuro.
NoAI è più efficace se combinato con altri metodi come robots.txt, header HTTP, watermarking, controlli di accesso e protezioni legali. Nessun metodo singolo offre protezione completa, quindi si consiglia un approccio stratificato per una sicurezza dei contenuti completa.
Traccia quali sistemi AI citano il tuo brand e i tuoi contenuti con la piattaforma di monitoraggio AI di AmICited. Scopri esattamente come il tuo lavoro viene utilizzato da ChatGPT, Perplexity, Google AI Overviews e altri sistemi AI.
Scopri cos'è il meta tag noai, come funziona per impedire la raccolta di dati per il training AI, le sue limitazioni e come implementarlo sul tuo sito web per p...
Discussione della community sul meta tag noai e sulla sua reale efficacia nel proteggere i contenuti dall’addestramento AI. Gli utenti condividono esperienze e ...
Scopri come i meta tag si sono evoluti per la ricerca guidata dall'IA. Scopri quali meta tag sono più importanti per l'ottimizzazione AI, la visibilità nei riep...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.