Una pipeline di Retrieval-Augmented Generation (RAG) è un flusso di lavoro che consente ai sistemi di intelligenza artificiale di cercare, classificare e citare fonti esterne durante la generazione delle risposte. Combina il recupero di documenti, il ranking semantico e la generazione tramite LLM per fornire risposte accurate e contestualmente rilevanti, basate su dati reali. I sistemi RAG riducono le allucinazioni consultando basi di conoscenza esterne prima di produrre risposte, diventando così essenziali per applicazioni che richiedono accuratezza fattuale e attribuzione delle fonti.
Pipeline RAG
Una pipeline di Retrieval-Augmented Generation (RAG) è un flusso di lavoro che consente ai sistemi di intelligenza artificiale di cercare, classificare e citare fonti esterne durante la generazione delle risposte. Combina il recupero di documenti, il ranking semantico e la generazione tramite LLM per fornire risposte accurate e contestualmente rilevanti, basate su dati reali. I sistemi RAG riducono le allucinazioni consultando basi di conoscenza esterne prima di produrre risposte, diventando così essenziali per applicazioni che richiedono accuratezza fattuale e attribuzione delle fonti.
Cos’è una Pipeline RAG?
Una pipeline di Retrieval-Augmented Generation (RAG) è un’architettura AI che combina il recupero delle informazioni con la generazione tramite large language model (LLM) per produrre risposte più accurate, contestualmente rilevanti e verificabili. Invece di affidarsi solo ai dati di addestramento di un LLM, i sistemi RAG recuperano dinamicamente documenti o dati rilevanti da basi di conoscenza esterne prima di generare le risposte, riducendo significativamente le allucinazioni e migliorando la precisione fattuale. La pipeline funge da ponte tra dati di addestramento statici e informazioni in tempo reale, consentendo ai sistemi AI di fare riferimento a contenuti attuali, specifici di dominio o proprietari. Questo approccio è diventato essenziale per le organizzazioni che richiedono risposte con citazioni, conformità agli standard di accuratezza e trasparenza nei contenuti generati dall’intelligenza artificiale. Le pipeline RAG sono particolarmente preziose nel monitoraggio dei sistemi AI, dove tracciabilità e attribuzione delle fonti sono requisiti critici.
Componenti Principali
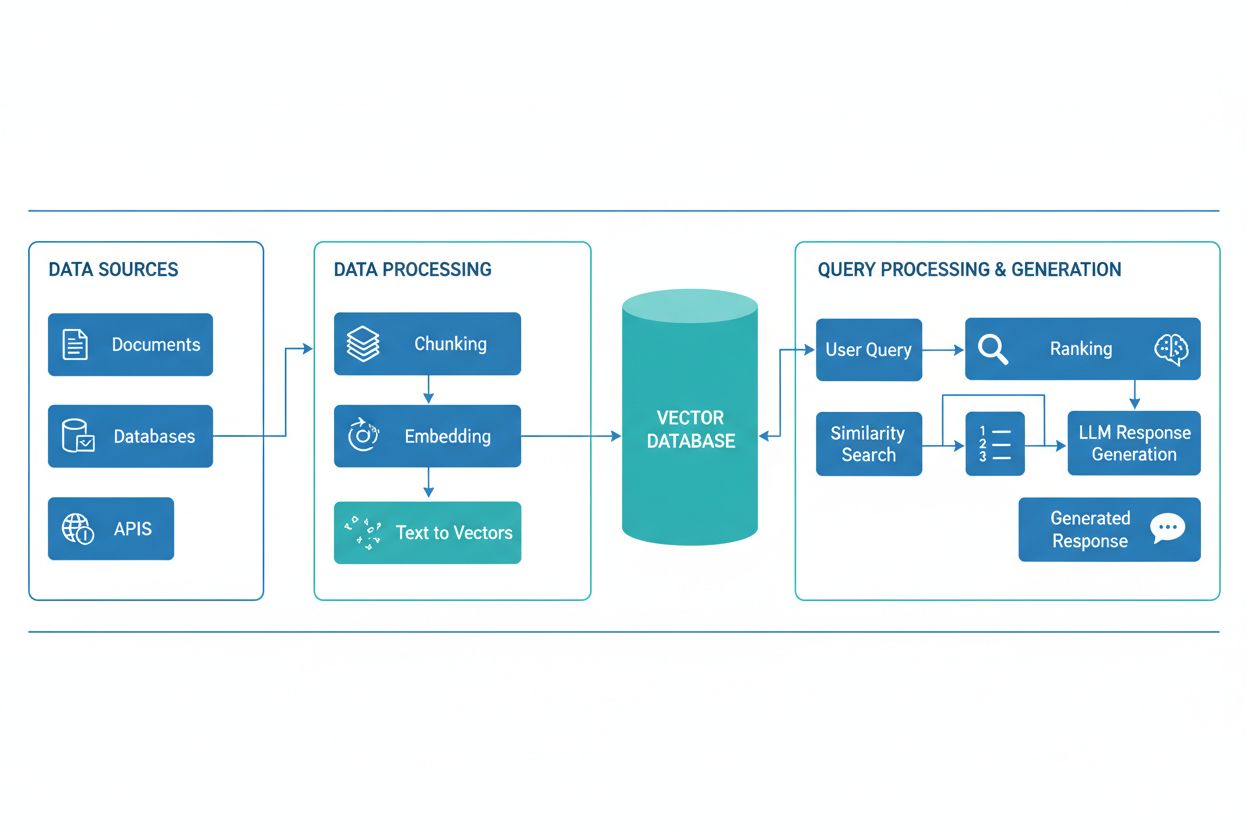
Una pipeline RAG è composta da diversi componenti interconnessi che collaborano per recuperare informazioni rilevanti e generare risposte fondate. L’architettura include tipicamente uno strato di ingestione documentale che elabora e prepara i dati grezzi, un database vettoriale o base di conoscenza che memorizza gli embedding e i contenuti indicizzati, un meccanismo di recupero che identifica i documenti rilevanti sulla base delle query degli utenti, un sistema di ranking che dà priorità ai risultati più pertinenti e un modulo di generazione alimentato da un LLM che sintetizza le informazioni recuperate in risposte coerenti. Componenti aggiuntivi includono moduli di elaborazione e pre-elaborazione delle query che normalizzano l’input dell’utente, modelli di embedding che convertono il testo in rappresentazioni numeriche e un ciclo di feedback che migliora continuamente la precisione del recupero. L’orchestrazione di questi componenti determina l’efficacia e l’efficienza complessiva del sistema RAG.
La pipeline RAG opera tramite due fasi distinte: la fase di recupero e la fase di generazione. Durante la fase di recupero, il sistema converte la query dell’utente in un embedding utilizzando lo stesso modello di embedding che ha processato i documenti della knowledge base, quindi effettua la ricerca nel database vettoriale per identificare i documenti o passaggi semanticamente più simili. Di solito questa fase restituisce una lista ordinata di documenti candidati, che possono essere ulteriormente raffinati tramite algoritmi di reranking che utilizzano cross-encoders o punteggi basati su LLM per garantire la pertinenza. Nella fase di generazione, i documenti recuperati con il punteggio più alto vengono formattati in una finestra di contesto e passati all’LLM insieme alla query originale, consentendo al modello di generare risposte fondate su materiale di origine reale. Questo approccio a due fasi assicura che le risposte siano sia contestualmente appropriate sia tracciabili a fonti specifiche, rendendolo ideale per applicazioni che richiedono citazione e responsabilità. La qualità dell’output finale dipende criticamente sia dalla rilevanza dei documenti recuperati sia dalla capacità dell’LLM di sintetizzare le informazioni in modo coerente.
Tecnologie e Strumenti Chiave
L’ecosistema RAG comprende un’ampia gamma di strumenti e framework specializzati progettati per semplificare la costruzione e l’implementazione delle pipeline. Le implementazioni moderne RAG sfruttano diverse categorie di tecnologia:
Framework di orchestrazione: LangChain, LlamaIndex (precedentemente GPT Index) e Haystack forniscono livelli di astrazione per costruire workflow RAG senza dover gestire ogni componente singolarmente
Database vettoriali: Pinecone, Weaviate, Milvus, Qdrant e Chroma offrono archiviazione e recupero scalabili di embedding ad alta dimensionalità con latenze di query sotto il millisecondo
Modelli di embedding: text-embedding-3 di OpenAI, Embed API di Cohere e modelli open-source come all-MiniLM-L6-v2 convertono il testo in rappresentazioni semantiche
Provider LLM: OpenAI (GPT-4), Anthropic (Claude), Meta (Llama) e Mistral offrono modelli di varie dimensioni e capacità per i task di generazione
Soluzioni di reranking: Rerank API di Cohere, modelli cross-encoder da Hugging Face e reranker proprietari basati su LLM migliorano la precisione del recupero
Strumenti di preparazione dati: Unstructured, Apache Kafka e pipeline ETL personalizzate gestiscono ingestione documentale, suddivisione e pre-elaborazione
Monitoraggio e valutazione: strumenti come Ragas, TruLens e framework di valutazione personalizzati misurano le prestazioni del sistema RAG e identificano i casi di errore
Questi strumenti possono essere combinati in modo modulare, consentendo alle organizzazioni di costruire sistemi RAG su misura per le proprie esigenze e vincoli infrastrutturali.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Meccanismi di Recupero
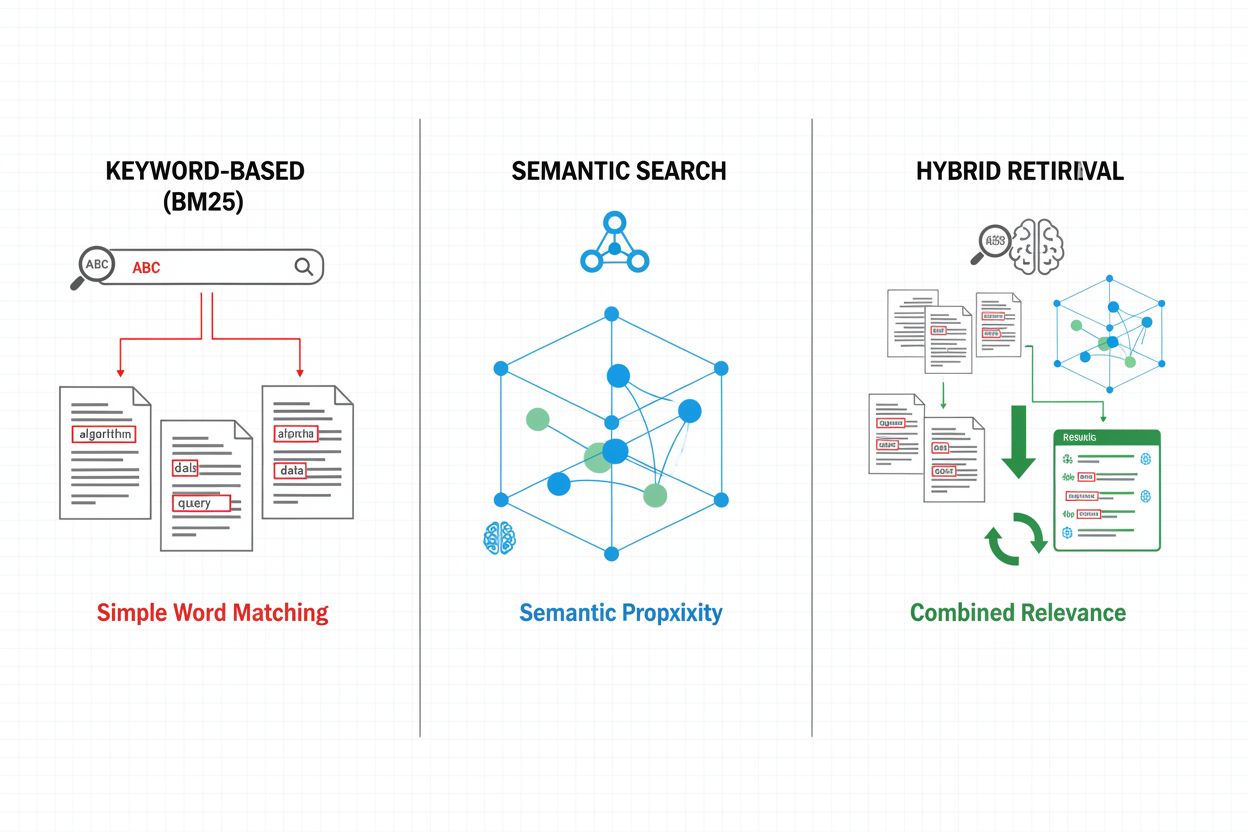
I meccanismi di recupero costituiscono la base dell’efficacia di una pipeline RAG, evolvendosi da semplici approcci basati su parole chiave a sofisticati metodi di ricerca semantica. Il recupero tradizionale basato su parole chiave tramite algoritmi BM25 rimane efficiente dal punto di vista computazionale ed efficace per scenari di corrispondenza esatta, ma fatica a comprendere la semantica e la sinonimia. Dense Passage Retrieval (DPR) e altri metodi neurali di recupero superano questi limiti codificando sia le query sia i documenti in embedding vettoriali densi, consentendo un matching semantico che cattura il significato oltre le parole chiave superficiali. Gli approcci di recupero ibridi combinano ricerca basata su parole chiave e ricerca semantica, sfruttando i punti di forza di entrambi i metodi per migliorare richiamo e precisione su query di tipo diverso. I meccanismi avanzati di recupero incorporano l’espansione delle query, in cui la query originale viene ampliata con termini correlati o riformulazioni per recuperare più documenti rilevanti. Strati di reranking raffinano ulteriormente i risultati applicando modelli più costosi computazionalmente che valutano i documenti candidati sulla base di una comprensione semantica più profonda o di criteri di rilevanza specifici per il task. La scelta del meccanismo di recupero incide significativamente sia sull’accuratezza del contesto recuperato sia sui costi computazionali della pipeline RAG, richiedendo un’attenta valutazione dei compromessi tra velocità e qualità.
Vantaggi delle Pipeline RAG
Le pipeline RAG offrono vantaggi sostanziali rispetto agli approcci basati solo su LLM, in particolare per applicazioni che richiedono accuratezza, aggiornamento e tracciabilità. Ancorando le risposte a documenti recuperati, i sistemi RAG riducono drasticamente le allucinazioni—casi in cui gli LLM generano informazioni plausibili ma errate—rendendoli adatti a settori critici come sanità, diritto e servizi finanziari. La capacità di fare riferimento a basi di conoscenza esterne consente ai sistemi RAG di fornire informazioni aggiornate senza dover riaddestrare i modelli, permettendo alle organizzazioni di mantenere risposte sempre attuali man mano che emergono nuove informazioni. Le pipeline RAG supportano la personalizzazione specifica di dominio incorporando documenti proprietari, basi di conoscenza interne e terminologia specializzata, consentendo risposte più pertinenti e contestuali. La componente di recupero garantisce trasparenza e auditabilità mostrando esplicitamente le fonti che hanno informato ciascuna risposta, elemento cruciale per conformità normativa e fiducia dell’utente. L’efficienza dei costi migliora tramite l’impiego di LLM più piccoli e performanti che possono generare risposte di alta qualità se forniti di contesto rilevante, riducendo l’onere computazionale rispetto a modelli di dimensioni maggiori. Questi vantaggi rendono RAG particolarmente prezioso per le organizzazioni che implementano sistemi di monitoraggio AI dove accuratezza delle citazioni e visibilità dei contenuti sono fondamentali.
Sfide e Limitazioni
Nonostante i loro vantaggi, le pipeline RAG affrontano diverse sfide tecniche e operative che richiedono un’attenta gestione. La qualità dei documenti recuperati determina direttamente la qualità della risposta, rendendo difficili da correggere gli errori di recupero—un fenomeno noto come “garbage in, garbage out” in cui documenti irrilevanti o obsoleti nella knowledge base si propagano fino alle risposte finali. I modelli di embedding possono avere difficoltà con terminologia di dominio, lingue rare o contenuti altamente tecnici, portando a scarsa corrispondenza semantica e documenti rilevanti mancanti. Il costo computazionale di recupero, generazione di embedding e reranking può essere elevato su larga scala, soprattutto nel trattamento di knowledge base estese o volumi elevati di query. I limiti della finestra di contesto degli LLM vincolano la quantità di informazioni recuperate che possono essere inserite nei prompt, richiedendo un’attenta selezione e sintesi dei passaggi più rilevanti. Mantenere freschezza e coerenza della knowledge base presenta sfide operative, in particolare in ambienti dinamici dove le informazioni cambiano frequentemente o provengono da più fonti. La valutazione delle prestazioni di un sistema RAG richiede metriche più complete rispetto alla semplice accuratezza, tra cui la precisione del recupero, la pertinenza delle risposte e la correttezza delle citazioni, che spesso sono difficili da valutare automaticamente.
RAG vs. Altri Approcci
RAG rappresenta un approccio tra le varie strategie per migliorare accuratezza e rilevanza degli LLM, ciascuna con precisi compromessi. Il fine-tuning comporta il riaddestramento degli LLM su dati specifici di dominio, offrendo una profonda personalizzazione del modello ma richiedendo grandi risorse computazionali, dati di addestramento etichettati e manutenzione continua al variare delle informazioni. Il prompt engineering ottimizza le istruzioni e il contesto forniti agli LLM senza modificarne i pesi, offrendo flessibilità e basso costo ma limitato dai dati di addestramento del modello e dalla dimensione della finestra di contesto. L’in-context learning utilizza esempi few-shot nei prompt per guidare il comportamento del modello, offrendo adattamento rapido ma consumando token di contesto preziosi e richiedendo una selezione attenta degli esempi. Rispetto a questi approcci, RAG offre una via di mezzo: consente accesso dinamico a informazioni aggiornate senza riaddestramento, mantiene trasparenza tramite attribuzione esplicita delle fonti e scala efficientemente su domini di conoscenza diversi. Tuttavia, RAG introduce maggiore complessità a livello di infrastruttura di recupero e potenziali errori di recupero, mentre il fine-tuning offre un’integrazione più stretta della conoscenza di dominio nel comportamento del modello. L’approccio ottimale spesso prevede la combinazione di più strategie—ad esempio, utilizzando RAG con modelli fine-tuned e prompt accuratamente ingegnerizzati—per massimizzare accuratezza e rilevanza su casi d’uso specifici.
Costruzione e Implementazione di RAG
Implementare una pipeline RAG in produzione richiede pianificazione sistematica in termini di preparazione dei dati, progettazione dell’architettura e considerazioni operative. Il processo inizia con la preparazione della knowledge base: raccolta dei documenti rilevanti, pulizia e standardizzazione dei formati, suddivisione dei contenuti in chunk di dimensione appropriata che bilanciano la conservazione del contesto con la precisione del recupero. Successivamente, le organizzazioni selezionano modelli di embedding e database vettoriali in base ai requisiti di performance, vincoli di latenza ed esigenze di scalabilità, considerando fattori come dimensionalità degli embedding, throughput delle query e capacità di archiviazione. Il sistema di recupero viene quindi configurato, includendo scelte su algoritmi di recupero (keyword, semantico o ibrido), strategie di reranking e criteri di filtraggio dei risultati. Segue l’integrazione con i provider LLM, stabilendo connessioni ai modelli di generazione e definendo template di prompt che incorporano efficacemente il contesto recuperato. Test e valutazione sono critici, richiedendo metriche per la qualità del recupero (precision, recall, MRR), qualità della generazione (rilevanza, coerenza, factualità) e performance end-to-end del sistema. Le considerazioni di deployment includono la configurazione di sistemi di monitoraggio per la precisione del recupero e la qualità della generazione, l’implementazione di cicli di feedback per identificare e risolvere i casi di errore e l’istituzione di processi per aggiornamenti e manutenzione della knowledge base. Infine, l’ottimizzazione continua comporta l’analisi delle interazioni degli utenti, l’identificazione dei pattern di errore comuni e il miglioramento iterativo dei meccanismi di recupero, delle strategie di reranking e dell’ingegneria dei prompt per aumentare le prestazioni complessive del sistema.
RAG nel Monitoraggio AI e nelle Citazioni
Le pipeline RAG sono fondamentali per le moderne piattaforme di monitoraggio AI come AmICited.com, dove tracciare le fonti e l’accuratezza dei contenuti generati dall’AI è essenziale. Recuperando e citando esplicitamente i documenti di origine, i sistemi RAG creano una traccia auditabile che consente alle piattaforme di monitoraggio di verificare le affermazioni, valutare la precisione fattuale e identificare potenziali allucinazioni o attribuzioni errate. Questa capacità di citazione colma una lacuna critica nella trasparenza AI: utenti e auditor possono rintracciare le risposte fino alle fonti originali, consentendo la verifica indipendente e costruendo fiducia nei contenuti generati dall’intelligenza artificiale. Per creatori di contenuti e organizzazioni che utilizzano strumenti AI, il monitoraggio abilitato da RAG fornisce visibilità su quali fonti hanno informato risposte specifiche, supportando la conformità ai requisiti di attribuzione e alle policy di governance dei contenuti. La componente di recupero delle pipeline RAG genera ricchi metadati—including punteggi di rilevanza, ranking dei documenti e metriche di confidenza del recupero—che i sistemi di monitoraggio possono analizzare per valutare l’affidabilità delle risposte e identificare quando i sistemi AI operano fuori dal loro dominio di conoscenza. L’integrazione di RAG con le piattaforme di monitoraggio consente la rilevazione del drift delle citazioni, ovvero quando i sistemi AI si allontanano progressivamente da fonti autorevoli verso altre meno affidabili, e supporta l’applicazione di policy sui contenuti relativamente a qualità e diversità delle fonti. Man mano che i sistemi AI si integrano sempre più nei flussi di lavoro critici, la combinazione tra pipeline RAG e monitoraggio completo crea meccanismi di responsabilità che proteggono utenti, organizzazioni e l’intero ecosistema informativo dalla disinformazione generata dall’intelligenza artificiale.
Domande frequenti
Qual è la differenza tra RAG e fine-tuning?
RAG e fine-tuning sono approcci complementari per migliorare le prestazioni degli LLM. RAG recupera documenti esterni al momento della richiesta senza modificare il modello, consentendo accesso ai dati in tempo reale e aggiornamenti semplici. Il fine-tuning riaddestra il modello su dati specifici di dominio, offrendo una personalizzazione più profonda ma richiedendo notevoli risorse computazionali e aggiornamenti manuali quando le informazioni cambiano. Molte organizzazioni usano entrambe le tecniche insieme per risultati ottimali.
Come riduce RAG le allucinazioni nelle risposte AI?
RAG riduce le allucinazioni ancorando le risposte degli LLM a documenti fattuali recuperati. Invece di affidarsi solo ai dati di addestramento, il sistema recupera fonti rilevanti prima della generazione, fornendo al modello prove concrete a cui fare riferimento. Questo approccio assicura che le risposte siano basate su informazioni reali e non su schemi appresi dal modello, migliorando notevolmente la precisione fattuale e riducendo affermazioni false o fuorvianti.
Cosa sono gli embedding vettoriali e perché sono importanti in RAG?
Gli embedding vettoriali sono rappresentazioni numeriche del testo che catturano il significato semantico in uno spazio multidimensionale. Consentono ai sistemi RAG di effettuare ricerche semantiche, trovando documenti con significato simile anche se utilizzano parole diverse. Gli embedding sono cruciali perché permettono a RAG di andare oltre la semplice corrispondenza di parole chiave per comprendere le relazioni concettuali, migliorando la rilevanza del recupero e consentendo una generazione di risposte più accurata.
Le pipeline RAG possono funzionare con dati in tempo reale?
Sì, le pipeline RAG possono incorporare dati in tempo reale tramite processi di ingestione e indicizzazione continui. Le organizzazioni possono impostare pipeline automatiche che aggiornano regolarmente il database vettoriale con nuovi documenti, garantendo che la base di conoscenza resti aggiornata. Questa capacità rende RAG ideale per applicazioni che richiedono informazioni sempre aggiornate come analisi di notizie, intelligence sui prezzi e monitoraggio del mercato senza dover riaddestrare l’LLM sottostante.
Qual è la differenza tra ricerca semantica e RAG?
La ricerca semantica è una tecnica di recupero che trova documenti in base alla similarità di significato utilizzando embedding vettoriali. RAG è una pipeline completa che combina la ricerca semantica con la generazione tramite LLM per produrre risposte basate sui documenti recuperati. Mentre la ricerca semantica si concentra sul trovare informazioni rilevanti, RAG aggiunge la componente generativa che sintetizza il contenuto recuperato in risposte coerenti con citazioni.
Come decidono i sistemi RAG quali fonti citare?
I sistemi RAG utilizzano diversi meccanismi per selezionare le fonti da citare. Impiegano algoritmi di recupero per trovare documenti rilevanti, modelli di reranking per dare priorità ai risultati più pertinenti e processi di verifica per assicurare che le citazioni supportino effettivamente le affermazioni fatte. Alcuni sistemi usano approcci 'cite-while-writing' in cui le affermazioni vengono fatte solo se supportate da fonti recuperate, mentre altri verificano le citazioni dopo la generazione e rimuovono quelle non supportate.
Quali sono le principali sfide nella costruzione di pipeline RAG?
Le sfide principali includono il mantenimento dell’aggiornamento e della qualità della base di conoscenza, l’ottimizzazione della precisione del recupero su contenuti eterogenei, la gestione dei costi computazionali su larga scala, la gestione della terminologia specifica di dominio che i modelli di embedding potrebbero non comprendere bene e la valutazione delle prestazioni del sistema con metriche complete. Le organizzazioni devono anche affrontare i limiti della finestra di contesto degli LLM e garantire che i documenti recuperati rimangano rilevanti con l’evoluzione delle informazioni.
Come monitora AmICited le citazioni RAG nei sistemi AI?
AmICited traccia come sistemi AI come ChatGPT, Perplexity e Google AI Overviews recuperano e citano contenuti tramite pipeline RAG. La piattaforma monitora quali fonti vengono selezionate per la citazione, con quale frequenza il tuo brand appare nelle risposte AI e se le citazioni sono accurate. Questa visibilità aiuta le organizzazioni a comprendere la loro presenza nella ricerca mediata dall’AI e ad assicurare la corretta attribuzione dei loro contenuti.
Monitora il Tuo Brand nelle Risposte AI
Tieni traccia di come sistemi AI come ChatGPT, Perplexity e Google AI Overviews fanno riferimento ai tuoi contenuti. Ottieni visibilità sulle citazioni RAG e il monitoraggio delle risposte AI.
Che cos'è il RAG nella Ricerca AI: Guida Completa alla Retrieval-Augmented Generation
Scopri cos'è il RAG (Retrieval-Augmented Generation) nella ricerca AI. Scopri come il RAG migliora l'accuratezza, riduce le allucinazioni e alimenta ChatGPT, Pe...
Come funziona la Retrieval-Augmented Generation: Architettura e Processo
Scopri come RAG combina LLM e fonti di dati esterne per generare risposte AI accurate. Comprendi il processo in cinque fasi, i componenti e perché è importante ...
Scopri cos'è la Generazione Aumentata dal Recupero (RAG), come funziona e perché è essenziale per risposte AI accurate. Esplora l’architettura RAG, i vantaggi e...
13 min di lettura
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.