Algoritmo Sonar in Perplexity: Modello di Ricerca in Tempo Reale Spiegato
Scopri come l'algoritmo Sonar di Perplexity alimenta la ricerca AI in tempo reale con modelli economici. Esplora Sonar, Sonar Pro e Sonar Reasoning.
10 min di lettura
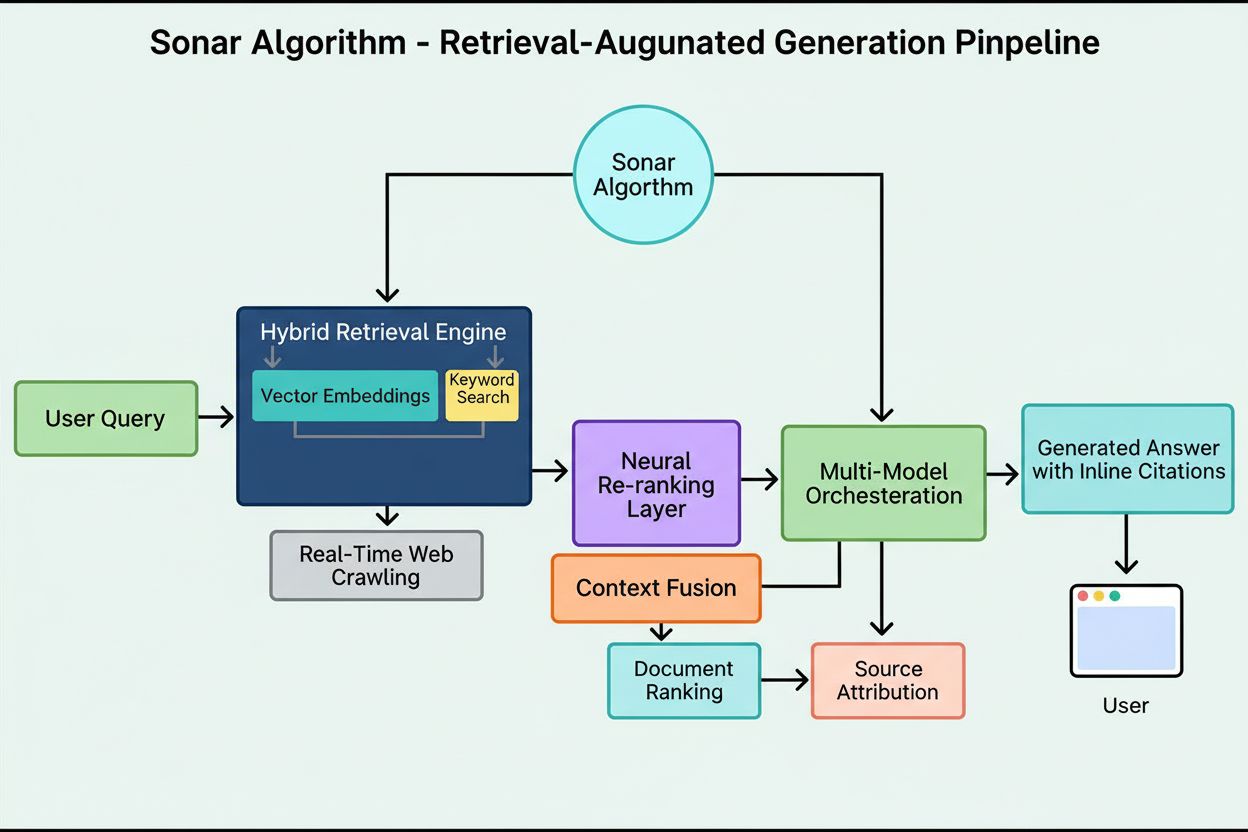
L’Algoritmo Sonar è il sistema proprietario di ranking RAG (retrieval-augmented generation) di Perplexity che combina ricerca semantica ibrida e ricerca per parole chiave con riordino neurale per recuperare, classificare e citare fonti web in tempo reale nelle risposte AI generate. Dà priorità all’attualità dei contenuti, alla rilevanza semantica e alla citabilità per fornire risposte fondate e supportate da fonti, riducendo al minimo le allucinazioni.
L'Algoritmo Sonar è il sistema proprietario di ranking RAG (retrieval-augmented generation) di Perplexity che combina ricerca semantica ibrida e ricerca per parole chiave con riordino neurale per recuperare, classificare e citare fonti web in tempo reale nelle risposte AI generate. Dà priorità all'attualità dei contenuti, alla rilevanza semantica e alla citabilità per fornire risposte fondate e supportate da fonti, riducendo al minimo le allucinazioni.
L’Algoritmo Sonar è il sistema proprietario di ranking RAG (retrieval-augmented generation) di Perplexity che alimenta il suo motore di risposta combinando ricerca semantica ibrida e per parole chiave, riordino neurale e generazione di citazioni in tempo reale. A differenza dei motori di ricerca tradizionali che classificano le pagine per mostrarle in un elenco di risultati, Sonar classifica frammenti di contenuto per sintetizzarli in una risposta unica e unificata con citazioni in linea ai documenti di origine. L’algoritmo dà priorità a attualità dei contenuti, rilevanza semantica e citabilità per fornire risposte fondate e supportate da fonti, riducendo al minimo le allucinazioni. Sonar rappresenta un cambiamento fondamentale nel modo in cui i sistemi AI recuperano e classificano le informazioni—passando dai segnali di autorità basati sui link a metriche di utilità focalizzate sulla risposta che enfatizzano se il contenuto soddisfa direttamente l’intento dell’utente e può essere citato chiaramente nelle risposte sintetizzate. Questa distinzione è cruciale per capire come la visibilità nei motori di risposta AI differisca dalla SEO tradizionale, poiché Sonar valuta il contenuto non per la sua capacità di posizionarsi in una lista, ma per la sua capacità di essere estratto, sintetizzato e attribuito all’interno di una risposta AI generata.
L’emergere dell’Algoritmo Sonar riflette un più ampio cambiamento del settore verso la generazione aumentata dal recupero come architettura dominante per i motori di risposta AI. Quando Perplexity è stata lanciata alla fine del 2022, l’azienda ha identificato una lacuna critica nel panorama AI: mentre ChatGPT offriva potenti capacità conversazionali, mancava di accesso a informazioni in tempo reale e di attribuzione delle fonti, portando ad allucinazioni e risposte obsolete. Il team fondatore di Perplexity, inizialmente al lavoro su uno strumento di traduzione di query di database, si è completamente spostato sulla costruzione di un motore di risposta in grado di combinare la ricerca web live con la sintesi LLM. Questa decisione strategica ha plasmato l’architettura di Sonar fin dall’inizio—l’algoritmo è stato progettato non per classificare pagine per la navigazione umana, ma per recuperare e classificare frammenti di contenuto per la sintesi e la citazione automatica. Negli ultimi due anni, Sonar si è evoluto in uno dei sistemi di ranking più sofisticati dell’ecosistema AI, con i modelli Sonar di Perplexity che occupano dal 1° al 4° posto nell’Arena Evaluation della Ricerca, superando nettamente i modelli concorrenti di Google e OpenAI. Ora l’algoritmo elabora oltre 400 milioni di query di ricerca al mese, indicizzando oltre 200 miliardi di URL unici e mantenendo l’attualità in tempo reale tramite decine di migliaia di aggiornamenti di indice al secondo. Questa scala e sofisticazione sottolineano l’importanza di Sonar come paradigma di ranking che definisce l’era della ricerca AI.
Il sistema di ranking di Sonar opera attraverso una pipeline di generazione aumentata dal recupero a cinque fasi che trasforma le query degli utenti in risposte fondate e citate. La prima fase, Parsing dell’Intento della Query, impiega un LLM per andare oltre la semplice corrispondenza per parola chiave e raggiungere la comprensione semantica di ciò che l’utente sta realmente chiedendo, interpretando contesto, sfumature e intento sottostante. La seconda fase, Recupero Web Live, invia la query analizzata all’enorme indice distribuito di Perplexity alimentato da Vespa AI, che scandaglia il web alla ricerca di pagine e documenti rilevanti in tempo reale. Questo sistema di recupero combina recupero denso (ricerca vettoriale tramite incorporamenti semantici) e recupero sparso (ricerca lessicale/basata su parole chiave), fondendo i risultati per produrre circa 50 documenti candidati diversi. La terza fase, Estrazione e Contestualizzazione dei Frammenti, non passa il testo completo delle pagine al modello generativo; invece, gli algoritmi estraggono i frammenti, paragrafi o chunk più rilevanti direttamente collegati alla query, aggregandoli in una finestra di contesto mirata. La quarta fase, Generazione della Risposta Sintetizzata con Citazioni, passa questo contesto curato a un LLM scelto (dalla famiglia proprietaria Sonar di Perplexity o modelli di terze parti come GPT-4 o Claude), che genera una risposta in linguaggio naturale basandosi rigorosamente sulle informazioni recuperate. Fondamentale è che le citazioni in linea collegano ogni affermazione ai documenti di origine, garantendo trasparenza e possibilità di verifica. La quinta fase, Raffinamento Conversazionale, mantiene il contesto della conversazione su più turni, consentendo domande di follow-up che perfezionano le risposte tramite ricerche web iterative. Il principio cardine di questa pipeline—“non devi dire nulla che non hai recuperato”—garantisce che le risposte generate da Sonar siano fondate su fonti verificabili, riducendo fondamentalmente le allucinazioni rispetto ai modelli che si basano solo sui dati di addestramento.
| Aspetto | Ricerca Tradizionale (Google) | Algoritmo Sonar (Perplexity) | Ranking ChatGPT | Ranking Gemini | Ranking Claude |
|---|---|---|---|---|---|
| Unità Principale | Elenco ordinato di link | Singola risposta sintetizzata con citazioni | Menzioni di entità basate sul consenso | Contenuti allineati E-E-A-T | Fonti neutrali e basate sui fatti |
| Focus Recupero | Parole chiave, link, segnali ML | Ricerca semantica ibrida + parole chiave | Dati di addestramento + navigazione web | Integrazione knowledge graph | Filtri di sicurezza costituzionali |
| Priorità Attualità | Query-deserves-freshness (QDF) | Recupero web in tempo reale, boost 37% entro 48 ore | Priorità bassa, dipende dai dati di addestramento | Moderata, integrata con Google Search | Priorità bassa, enfasi sulla stabilità |
| Segnali di Ranking | Backlink, autorità di dominio, CTR | Attualità, rilevanza semantica, citabilità, boost autorità | Riconoscimento entità, menzioni consenso | E-E-A-T, allineamento conversazionale, dati strutturati | Trasparenza, citazioni verificabili, neutralità |
| Meccanismo di Citazione | Estratti URL nei risultati | Citazioni in linea con link alla fonte | Implicito, spesso senza citazioni | AI Overviews con attribuzione | Attribuzione fonte esplicita |
| Diversità dei Contenuti | Risultati multipli tra siti | Poche fonti selezionate per la sintesi | Sintetizzato da più fonti | Più fonti in panoramica | Fonti bilanciate e neutrali |
| Personalizzazione | Sottile, per lo più implicita | Modalità di focus esplicite (Web, Accademico, Finanza, Scrittura, Social) | Implicita in base alla conversazione | Implicita in base al tipo di query | Minima, enfasi sulla coerenza |
| Gestione PDF | Indicizzazione standard | Vantaggio citazioni +22% su HTML | Indicizzazione standard | Indicizzazione standard | Indicizzazione standard |
| Impatto Schema Markup | FAQ schema in featured snippet | FAQ schema aumenta citazioni +41%, riduce tempo-citazione di 6h | Impatto diretto minimo | Impatto moderato su knowledge graph | Impatto diretto minimo |
| Ottimizzazione Latenza | Millisecondi per ranking | Recupero + generazione sotto-secondo | Secondi per sintesi | Secondi per sintesi | Secondi per sintesi |
La base tecnica dell’Algoritmo Sonar si fonda su un motore di recupero ibrido che combina diverse strategie di ricerca per massimizzare sia il richiamo che la precisione. Il recupero denso (ricerca vettoriale) utilizza incorporamenti semantici per comprendere il significato concettuale delle query, trovando documenti contestualmente simili anche senza corrispondenze esatte di parole chiave. Questo approccio sfrutta incorporamenti basati su transformer che collocano query e documenti in spazi vettoriali ad alta dimensione dove i contenuti semanticamente affini si raggruppano. Il recupero sparso (ricerca lessicale) completa il recupero denso offrendo precisione per termini rari, nomi di prodotto, identificativi aziendali interni ed entità specifiche dove l’ambiguità semantica è indesiderata. Il sistema utilizza funzioni di ranking come BM25 per corrispondenze esatte su questi termini critici. I due metodi vengono uniti e deduplicati per ottenere circa 50 documenti candidati diversi, prevenendo l’overfitting di dominio e garantendo ampia copertura tra fonti autorevoli. Dopo il recupero iniziale, lo strato di riordino neurale di Sonar impiega modelli ML avanzati (come DeBERTa-v3 cross-encoders) per valutare i candidati tramite un ampio set di feature che include punteggi di rilevanza lessicale, similarità vettoriale, autorità del documento, segnali di freschezza, metriche di engagement utente e metadati. Questa architettura di ranking multi-fase permette a Sonar di affinare progressivamente i risultati sotto vincoli di latenza stringenti, assicurando che il set finale rappresenti le fonti di massima qualità e rilevanza per la sintesi. L’intera infrastruttura di recupero si basa su Vespa AI, una piattaforma di ricerca distribuita capace di gestire indicizzazione su scala web (200+ miliardi di URL), aggiornamenti real-time (decine di migliaia al secondo) e comprensione granulare dei contenuti tramite chunking dei documenti. Questa scelta architetturale consente al team engineering relativamente piccolo di Perplexity di concentrarsi su componenti differenzianti—l’orchestrazione RAG, il fine-tuning dei modelli Sonar e l’ottimizzazione dell’inferenza—invece di reinventare da zero la ricerca distribuita.
L’attualità dei contenuti è uno dei segnali di ranking più potenti di Sonar, con ricerche empiriche che dimostrano che le pagine recentemente aggiornate ricevono tassi di citazione molto più elevati. In test A/B controllati condotti per 24 settimane su 120 URL, gli articoli aggiornati nelle ultime 48 ore sono stati citati il 37% più frequentemente rispetto a contenuti identici con timestamp più vecchi. Questo vantaggio è rimasto a circa il 14% dopo due settimane, indicando che la freschezza fornisce un boost sostenuto ma progressivamente decrescente. Il meccanismo alla base di questa priorità si radica nella filosofia progettuale di Sonar: l’algoritmo tratta i contenuti obsoleti come un rischio di allucinazione più elevato, presumendo che informazioni datate possano essere state superate da sviluppi più recenti. L’infrastruttura di Perplexity elabora decine di migliaia di richieste di aggiornamento indice al secondo, abilitando segnali di freschezza in tempo reale. Un modello ML predice se un URL necessita di re-indicizzazione e programma aggiornamenti in base all’importanza e alla frequenza storica di aggiornamento della pagina, assicurando che i contenuti di alto valore vengano aggiornati più aggressivamente. Anche modifiche cosmetiche minime azzerano il timer della freschezza, a patto che il CMS ripubblichi il timestamp modificato. Per gli editori, questo crea un imperativo strategico: adottare una cadenza da newsroom con aggiornamenti settimanali o giornalieri, oppure vedere i contenuti evergreen decadere gradualmente in visibilità. L’implicazione è profonda—nell’era Sonar, la velocità dei contenuti non è un indicatore di vanità ma un meccanismo di sopravvivenza. I brand che automatizzano micro-aggiornamenti settimanali, aggiungono changelog live o mantengono workflow di ottimizzazione continua otterranno una quota di citazioni sproporzionata rispetto ai competitor che si affidano a pagine statiche e aggiornate raramente.
Sonar dà priorità alla rilevanza semantica rispetto alla densità di parole chiave, premiando fondamentalmente i contenuti che rispondono direttamente alle query degli utenti in linguaggio naturale e conversazionale. Il sistema di recupero dell’algoritmo utilizza incorporamenti vettoriali densi per abbinare le query ai contenuti a livello concettuale, il che significa che pagine che utilizzano sinonimi, terminologia correlata o linguaggio ricco di contesto possono superare in ranking pagine piene di keyword ma prive di profondità semantica. Questo passaggio da ranking basato sulle parole chiave a ranking basato sul significato ha profonde implicazioni per la strategia dei contenuti. I contenuti vincenti in Sonar presentano diverse caratteristiche strutturali: iniziano con un breve riassunto fattuale prima di entrare nei dettagli, utilizzano titoli H2/H3 descrittivi e paragrafi brevi per facilitare l’estrazione dei passaggi, includono citazioni chiare e link alle fonti primarie, e mantengono timestamp e note di versione visibili per segnalare la freschezza. Ogni paragrafo funge da unità semantica atomica, ottimizzata per chiarezza da copia-incolla e comprensione LLM. Tabelle, elenchi puntati e grafici etichettati sono particolarmente preziosi perché presentano informazioni in formati strutturati e facilmente citabili. L’algoritmo premia anche analisi originali e dati unici rispetto alla semplice aggregazione, poiché il motore di sintesi di Sonar cerca fonti che aggiungono nuovi punti di vista, documenti primari o insight proprietari che li distinguono dalle panoramiche generiche. Questa enfasi sulla ricchezza semantica e sulla struttura answer-first rappresenta una svolta rispetto alla SEO tradizionale, in cui dominavano il posizionamento delle keyword e l’autorità dei link. Nell’era Sonar, i contenuti devono essere progettati per il recupero e la sintesi delle macchine, non per la navigazione umana.
I PDF pubblicamente accessibili rappresentano un vantaggio significativo e spesso sottovalutato nel sistema di ranking di Sonar, con test empirici che rivelano che le versioni PDF dei contenuti superano gli equivalenti HTML di circa il 22% in frequenza di citazione. Questo vantaggio deriva dal fatto che il crawler di Sonar tratta i PDF in modo più favorevole rispetto alle pagine HTML. I PDF non hanno banner cookie, requisiti di rendering JavaScript, autenticazione paywall e altre complicazioni HTML che possono oscurare o ritardare l’accesso ai contenuti. Il crawler di Sonar può leggere i PDF in modo pulito e prevedibile, estraendo il testo senza le ambiguità di parsing tipiche delle strutture HTML complesse. Gli editori possono sfruttare strategicamente questo vantaggio ospitando PDF in directory pubbliche accessibili, utilizzando nomi di file semantici che riflettano gli argomenti dei contenuti e segnalando il PDF come canonico tramite tag <link rel="alternate" type="application/pdf"> nell’head HTML. Questo crea ciò che i ricercatori descrivono come una “trappola per LLM”—una risorsa ad alta visibilità che gli script di tracciamento dei competitor non possono rilevare o monitorare facilmente. Per aziende B2B, vendor SaaS e organizzazioni orientate alla ricerca, questa strategia è particolarmente potente: pubblicare whitepaper, report di ricerca, case study e documentazione tecnica come PDF può aumentare notevolmente i tassi di citazione Sonar. La chiave è trattare il PDF non come un allegato da scaricare, ma come copia canonica degna di pari o maggiore ottimizzazione rispetto alla versione HTML. Questo approccio si è dimostrato particolarmente efficace per i contenuti enterprise, dove i PDF spesso contengono informazioni più strutturate e autorevoli rispetto alle pagine web.
Lo schema FAQ JSON-LD amplifica notevolmente i tassi di citazione Sonar, con pagine che contengono tre o più blocchi FAQ che ricevono citazioni il 41% più frequentemente rispetto alle pagine di controllo senza schema. Questo incremento riflette la preferenza di Sonar per i contenuti strutturati per chunk, in linea con la sua logica di recupero e sintesi. Lo schema FAQ presenta unità Q&A discrete e auto-contenute che l’algoritmo può facilmente estrarre, classificare e citare come blocchi semantici atomici. A differenza della SEO tradizionale, dove lo schema FAQ era un “nice-to-have”, Sonar tratta il markup Q&A strutturato come una leva di ranking centrale. Inoltre, Sonar cita spesso le domande FAQ come testo àncora, riducendo il rischio di perdita di contesto che si verifica quando l’LLM riassume frasi a metà paragrafo. Lo schema accelera anche il tempo alla prima citazione di circa sei ore, suggerendo che il parser Sonar dà priorità ai blocchi Q&A strutturati all’inizio della cascata di ranking. Per gli editori, la strategia di ottimizzazione è semplice: inserire da tre a cinque blocchi FAQ mirati sotto la piega, utilizzando frasi trigger conversazionali che rispecchiano le vere query degli utenti. Le domande dovrebbero sfruttare la coda lunga e la simmetria semantica con le query tipiche di Sonar. Ogni risposta deve essere concisa, fattuale e direttamente pertinente, evitando riempitivi o linguaggio promozionale. Questo approccio si è rivelato particolarmente efficace per SaaS, cliniche sanitarie e aziende di servizi professionali, dove i contenuti FAQ si allineano naturalmente all’intento dell’utente e alle esigenze di sintesi di Sonar.
Il sistema di ranking di Sonar integra molteplici segnali in un quadro unico di citazione, con la ricerca che identifica otto fattori primari che influenzano la selezione delle fonti e la frequenza di citazione. Primo, la rilevanza semantica rispetto alla domanda domina il recupero, con l’algoritmo che dà priorità ai contenuti che rispondono chiaramente alla query in linguaggio naturale. Secondo, autorità e credibilità contano molto, con le partnership editoriali di Perplexity e i boost algoritmici che favoriscono organizzazioni di notizie, istituzioni accademiche ed esperti riconosciuti. Terzo, la freschezza riceve un peso eccezionale, come visto, con gli aggiornamenti recenti che portano a un aumento del 37% delle citazioni. Quarto, la diversità e la copertura sono apprezzate, poiché Sonar preferisce risposte da più fonti di qualità rispetto a risposte basate su una sola fonte, riducendo il rischio di allucinazione tramite cross-validation. Quinto, modalità e ambito determinano quali indici Sonar consulta—le modalità di focus come Accademico, Finanza, Scrittura e Social restringono i tipi di fonte, mentre i selettori di fonte (Web, File Org, Web + File Org, Nessuno) determinano se il recupero avviene dal web aperto, da documenti interni o da entrambi. Sesto, citabilità e accessibilità sono fondamentali; se PerplexityBot può scansionare e indicizzare il contenuto, è più facile citarlo, rendendo compliance robots.txt e velocità di caricamento essenziali. Settimo, filtri di fonte personalizzati via API consentono alle aziende di limitare o preferire certi domini, alterando il ranking nelle raccolte in whitelist. Ottavo, il contesto della conversazione influenza le domande successive, con le pagine che si adattano all’intento evolutivo che superano i riferimenti più generici. Insieme, questi fattori creano uno spazio di ranking multidimensionale dove il successo richiede l’ottimizzazione simultanea su più dimensioni e non solo su una leva singola come backlink o densità di keyword.
L’Algoritmo Sonar è in rapida evoluzione in risposta ai progressi nell’inferenza LLM e nella tecnologia di recupero. Il blog engineering di Perplexity ha recentemente evidenziato la decodifica speculativa, una tecnica che dimezza la latenza dei token prevedendo molteplici token futuri simultaneamente. Loop di generazione più veloci consentono al sistema di permettersi set di recupero più freschi a ogni query, riducendo la finestra in cui le pagine obsolete possono competere. Un modello Sonar-Reasoning-Pro già supera Gemini 2.0 Flash e GPT-4o Search nelle valutazioni arena, suggerendo che la sofisticazione del ranking Sonar continuerà a crescere. Man mano che la latenza si avvicina alla velocità del pensiero umano, le citazioni diventano una partita ad alta frequenza dove la velocità dei contenuti è il vero differenziatore. Si prevedono innovazioni infrastrutturali emergenti come “API freschezza
L'**Algoritmo Sonar** è il sistema di ranking proprietario di Perplexity che alimenta il suo motore di risposta, fondamentalmente diverso dai motori di ricerca tradizionali come Google. Mentre Google classifica le pagine per mostrarle in una lista di link blu, Sonar ordina frammenti di contenuto per sintetizzarli in una risposta unica e unificata con citazioni in linea. Sonar utilizza la generazione aumentata dal recupero (RAG), combinando ricerca ibrida (incorporamenti vettoriali più corrispondenza per parole chiave), riordino neurale e recupero web in tempo reale per fondare le risposte su fonti verificabili. Questo approccio dà priorità alla rilevanza semantica e all'attualità dei contenuti rispetto ai segnali SEO tradizionali come i backlink, creando un paradigma di ranking ottimizzato per la sintesi generata dall'AI piuttosto che per l'autorità basata sui link.
Sonar implementa un **motore di recupero ibrido** che combina due strategie di ricerca complementari: recupero denso (ricerca vettoriale tramite incorporamenti semantici) e recupero sparso (ricerca lessicale/basata su parole chiave tramite BM25). Il recupero denso cattura il significato concettuale e il contesto, consentendo al sistema di trovare contenuti semanticamente simili anche senza corrispondenze esatte delle parole chiave. Il recupero sparso offre precisione per termini rari, nomi di prodotto e identificatori specifici dove l'ambiguità semantica è indesiderabile. Questi due metodi vengono uniti e deduplicati per produrre circa 50 documenti candidati diversi, prevenendo l'overfitting di dominio e garantendo una copertura ampia. Questo approccio ibrido supera i sistemi a metodo singolo sia in richiamo che in precisione della rilevanza.
I principali fattori di ranking di Sonar includono: (1) **Attualità dei contenuti** – le pagine recentemente aggiornate o pubblicate ricevono il 37% di citazioni in più entro 48 ore dall'aggiornamento; (2) **Rilevanza semantica** – il contenuto deve rispondere direttamente alla query in linguaggio naturale, privilegiando la chiarezza rispetto alla densità di parole chiave; (3) **Autorità e credibilità** – le fonti di editori affermati, istituzioni accademiche e testate giornalistiche ricevono boost algoritmici; (4) **Citabilità** – il contenuto deve essere facilmente citabile e strutturato con titoli chiari, tabelle e paragrafi; (5) **Diversità** – Sonar preferisce risposte da più fonti di alta qualità rispetto a quelle basate su una sola fonte; e (6) **Accessibilità tecnica** – le pagine devono essere scansionabili dal PerplexityBot e caricarsi velocemente per la consultazione on-demand.
**L'attualità è uno dei principali segnali di ranking di Sonar**, soprattutto per argomenti sensibili al tempo. L'infrastruttura di Perplexity elabora decine di migliaia di richieste di aggiornamento dell'indice al secondo, assicurando che l'indice rifletta le informazioni più aggiornate disponibili. Un modello ML predice se un URL necessita di re-indicizzazione e programma gli aggiornamenti in base all'importanza e alla frequenza di aggiornamento della pagina. Nei test empirici, i contenuti aggiornati nelle ultime 48 ore hanno ricevuto il 37% di citazioni in più rispetto a contenuti identici con timestamp più vecchi, e questo vantaggio è rimasto al 14% dopo due settimane. Anche modifiche minime azzerano il timer dell'attualità, rendendo essenziale l'ottimizzazione continua per mantenere la visibilità nelle risposte alimentate da Sonar.
**I PDF sono un vantaggio significativo nel sistema di ranking di Sonar**, spesso superando le versioni HTML degli stessi contenuti del 22% in frequenza di citazione. Il crawler di Sonar tratta i PDF in modo favorevole perché non hanno banner cookie, paywall, problemi di rendering JavaScript e altre complicazioni HTML che possono oscurare i contenuti. Gli editori possono ottimizzare la visibilità dei PDF ospitandoli in directory pubbliche accessibili, utilizzando nomi di file semantici e segnalando il PDF come canonico tramite tag `` nell'head HTML. Questo crea ciò che i ricercatori chiamano una "trappola per LLM" che gli script di tracciamento dei competitor non possono rilevare facilmente, rendendo i PDF una risorsa strategica per ottenere citazioni Sonar.
**Lo schema FAQ JSON-LD aumenta significativamente i tassi di citazione di Sonar**, con pagine che contengono tre o più blocchi FAQ che ricevono citazioni il 41% più frequentemente rispetto alle pagine di controllo senza schema. Il markup FAQ si allinea perfettamente con la logica di recupero per chunk di Sonar perché presenta unità Q&A discrete e auto-contenute che l'algoritmo può facilmente estrarre e citare. Inoltre, Sonar cita spesso le domande FAQ come testo àncora, riducendo il rischio di perdita di contesto che può verificarsi quando l'LLM riassume clausole prese a metà paragrafo. Lo schema accelera anche il tempo alla prima citazione di circa sei ore, suggerendo che il parser di Sonar dà priorità ai blocchi Q&A strutturati all'inizio della cascata di ranking.
Sonar implementa una **pipeline di generazione aumentata dal recupero (RAG) a tre fasi** progettata per fondare le risposte su conoscenze esterne verificate. La prima fase recupera documenti rilevanti tramite ricerca ibrida; la seconda estrae e contestualizza i frammenti più pertinenti; la terza sintetizza una risposta utilizzando solo il contesto fornito, applicando un principio rigoroso: "non devi dire nulla che non hai recuperato". Questa architettura collega strettamente recupero e generazione, assicurando che ogni affermazione sia tracciabile a una fonte. Le citazioni in linea collegano il testo generato ai documenti di origine, consentendo la verifica da parte dell'utente. Questo approccio di grounding riduce significativamente le allucinazioni rispetto ai modelli che si affidano solo ai dati di addestramento, rendendo le risposte di Sonar più affidabili e degne di fiducia.
Mentre **ChatGPT dà priorità al riconoscimento delle entità e al consenso** dai suoi dati di addestramento, **Gemini enfatizza i segnali E-E-A-T e l'allineamento conversazionale**, e **Claude si concentra sulla sicurezza costituzionale e la neutralità**, **Sonar dà priorità in modo unico all'attualità in tempo reale e alla profondità semantica**. Il riordinatore a tre livelli di Sonar applica filtri qualitativi più severi rispetto alla ricerca tradizionale, scartando interi set di risultati se i contenuti non rispettano le soglie di qualità. Diversamente dalla dipendenza di ChatGPT dai dati di addestramento storici, Sonar esegue recupero web live per ogni query, garantendo che le risposte riflettano informazioni attuali. Sonar si differenzia anche dall'integrazione del knowledge graph di Gemini enfatizzando la rilevanza semantica a livello di paragrafo e dal focus sulla neutralità di Claude accettando boost di dominio autorevoli da editori affermati.
Inizia a tracciare come i chatbot AI menzionano il tuo brand su ChatGPT, Perplexity e altre piattaforme. Ottieni informazioni utili per migliorare la tua presenza AI.
Scopri come l'algoritmo Sonar di Perplexity alimenta la ricerca AI in tempo reale con modelli economici. Esplora Sonar, Sonar Pro e Sonar Reasoning.
Scopri cos'è il RAG (Retrieval-Augmented Generation) nella ricerca AI. Scopri come il RAG migliora l'accuratezza, riduce le allucinazioni e alimenta ChatGPT, Pe...
RankBrain è il sistema di machine learning basato su AI di Google che interpreta l'intento di ricerca e classifica i risultati. Scopri come questo fattore chiav...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.