
Dati di addestramento
I dati di addestramento sono il dataset utilizzato per insegnare ai modelli ML schemi e relazioni. Scopri come la qualità dei dati di addestramento influisce su...
13 min di lettura

L’addestramento con dati sintetici è il processo di allenamento dei modelli di intelligenza artificiale utilizzando dati generati artificialmente invece di informazioni reali create da esseri umani. Questo approccio affronta la scarsità di dati, accelera lo sviluppo dei modelli e preserva la privacy, introducendo però sfide come il collasso del modello e le allucinazioni che richiedono una gestione e una validazione attente.
L'addestramento con dati sintetici è il processo di allenamento dei modelli di intelligenza artificiale utilizzando dati generati artificialmente invece di informazioni reali create da esseri umani. Questo approccio affronta la scarsità di dati, accelera lo sviluppo dei modelli e preserva la privacy, introducendo però sfide come il collasso del modello e le allucinazioni che richiedono una gestione e una validazione attente.
L’addestramento con dati sintetici si riferisce al processo di addestramento di modelli di intelligenza artificiale utilizzando dati generati artificialmente invece di informazioni reali create da esseri umani. Diversamente dall’addestramento AI tradizionale, che si basa su dataset autentici raccolti tramite sondaggi, osservazioni o web mining, i dati sintetici vengono creati attraverso algoritmi e metodi computazionali che apprendono pattern statistici dai dati esistenti o generano nuovi dati da zero. Questo cambiamento fondamentale nel metodo di addestramento affronta una sfida critica nello sviluppo moderno dell’AI: la crescita esponenziale delle esigenze computazionali ha superato la capacità umana di generare dati reali sufficienti, con ricerche che indicano che i dati di addestramento prodotti dall’uomo potrebbero esaurirsi nei prossimi anni. L’addestramento con dati sintetici offre un’alternativa scalabile ed economica che può essere generata all’infinito senza i lunghi processi di raccolta, etichettatura e pulizia dei dati che assorbono fino all’80% dei tempi di sviluppo AI tradizionali.
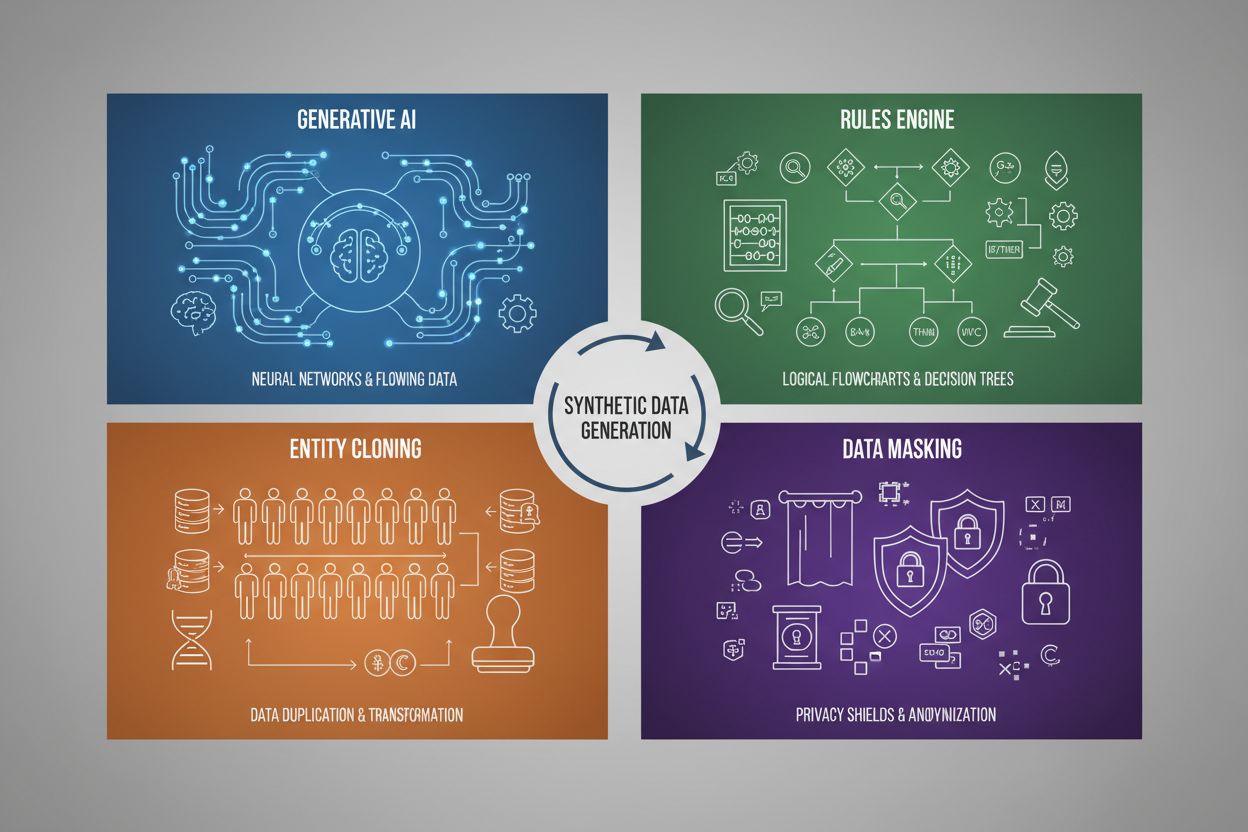
La generazione di dati sintetici impiega quattro tecniche principali, ognuna con meccanismi e applicazioni distinti:
| Tecnica | Come Funziona | Caso d’Uso |
|---|---|---|
| AI Generativa (GAN, VAE, GPT) | Utilizza modelli di deep learning per apprendere schemi statistici e distribuzioni dai dati reali, generando poi nuovi campioni sintetici che mantengono le stesse proprietà e relazioni statistiche. Le GAN impiegano reti avversarie in cui un generatore crea dati falsi mentre un discriminatore ne valuta l’autenticità, producendo risultati sempre più realistici. | Addestramento di grandi modelli linguistici come ChatGPT, generazione di immagini sintetiche con DALL-E, creazione di dataset di testo diversificati per attività di NLP |
| Motore di Regole | Applica regole logiche e vincoli predefiniti per generare dati che seguono specifiche logiche di business, conoscenze di dominio o requisiti normativi. Questo approccio deterministico garantisce che i dati generati rispettino pattern e relazioni noti senza richiedere machine learning. | Dati di transazioni finanziarie, cartelle cliniche con requisiti di conformità, dati sensoriali di produzione con parametri operativi noti |
| Clonazione di Entità | Duplica e modifica record reali esistenti applicando trasformazioni, perturbazioni o variazioni per creare nuove istanze preservando le proprietà e relazioni statistiche principali. Questa tecnica mantiene l’autenticità dei dati aumentando la dimensione del dataset. | Espansione di dataset limitati in settori regolamentati, creazione di dati per la diagnosi di malattie rare, aumento di dataset con poche istanze di classi minoritarie |
| Mascheramento e Anonimizzazione dei Dati | Oscura informazioni personali identificabili (PII) preservando la struttura e le relazioni statistiche dei dati tramite tecniche come tokenizzazione, crittografia o sostituzione di valori. In questo modo si creano versioni sintetiche dei dati reali che tutelano la privacy. | Dataset sanitari e finanziari, dati comportamentali dei clienti, informazioni personali sensibili in contesti di ricerca |
L’addestramento con dati sintetici comporta notevoli riduzioni dei costi eliminando i processi onerosi di raccolta, annotazione e pulizia dei dati che tradizionalmente richiedono molte risorse e tempo. Le organizzazioni possono generare campioni di addestramento illimitati su richiesta, accelerando enormemente i cicli di sviluppo dei modelli e consentendo iterazioni ed esperimenti rapidi senza dover attendere la raccolta di dati reali. La tecnica consente un potente aumento dei dati (data augmentation), permettendo agli sviluppatori di espandere dataset limitati e creare set di addestramento bilanciati che affrontano problemi di squilibrio nelle classi, una questione critica quando alcune categorie sono sottorappresentate nei dati reali. I dati sintetici risultano particolarmente preziosi per affrontare la scarsità di dati in settori specializzati come l’imaging medico, la diagnosi di malattie rare o i test su veicoli autonomi, dove la raccolta di esempi reali sufficienti è proibitiva in termini di costi o di etica. La tutela della privacy rappresenta un grande vantaggio: i dati sintetici possono essere generati senza esporre informazioni personali sensibili, risultando ideali per addestrare modelli su cartelle cliniche, dati finanziari o altre informazioni regolamentate. Inoltre, i dati sintetici consentono una riduzione sistematica dei bias, offrendo agli sviluppatori la possibilità di creare dataset intenzionalmente bilanciati e diversificati che contrastano pattern discriminatori presenti nei dati reali—fornendo, ad esempio, rappresentazioni demografiche diversificate nelle immagini di training per prevenire che i modelli AI perpetuino stereotipi di genere o razziali nelle applicazioni di selezione, credito o giustizia penale.
Nonostante le sue potenzialità, l’addestramento con dati sintetici introduce importanti sfide tecniche e pratiche che possono compromettere le prestazioni dei modelli se non vengono gestite con attenzione. La preoccupazione più critica è il collasso del modello, un fenomeno in cui modelli AI addestrati estensivamente su dati sintetici subiscono un grave degrado nella qualità, accuratezza e coerenza dei risultati. Questo accade perché i dati sintetici, pur essendo statisticamente simili a quelli reali, mancano della complessità, delle sfumature e dei casi limite presenti nelle informazioni autentiche—quando i modelli si addestrano su contenuti generati da AI, iniziano ad amplificare errori e artefatti, generando un problema cumulativo in cui ogni generazione di dati sintetici diventa progressivamente di qualità inferiore.
Le principali sfide includono:
Queste sfide sottolineano perché i dati sintetici da soli non possono sostituire i dati reali—devono invece essere integrati con attenzione come supplemento ai dataset autentici, con rigorosi controlli di qualità e supervisione umana durante tutto il processo di addestramento.
Poiché i dati sintetici diventano sempre più diffusi nell’addestramento dei modelli AI, i brand si trovano di fronte a una nuova sfida critica: garantire una rappresentazione accurata e favorevole nei risultati e nelle citazioni generate dall’AI. Quando i grandi modelli linguistici e i sistemi AI generativi vengono addestrati su dati sintetici, la qualità e le caratteristiche di questi dati influenzano direttamente il modo in cui i brand vengono descritti, raccomandati e citati nei risultati di ricerca AI, nelle risposte dei chatbot e nella generazione automatica di contenuti. Questo crea una notevole preoccupazione per la sicurezza del brand, poiché dati sintetici contenenti informazioni obsolete, bias dei concorrenti o descrizioni inaccurate del brand possono essere incorporati nei modelli AI, portando a una rappresentazione errata persistente in milioni di interazioni con gli utenti. Per le organizzazioni che utilizzano piattaforme come AmICited.com per monitorare la presenza del proprio brand nei sistemi AI, comprendere il ruolo dei dati sintetici nell’addestramento dei modelli diventa essenziale—I brand hanno bisogno di visibilità per capire se citazioni e menzioni AI provengono da dati di training reali o da fonti sintetiche, poiché ciò influisce su credibilità e accuratezza. Il gap di trasparenza sull’uso dei dati sintetici nell’addestramento AI crea sfide di accountability: le aziende non possono facilmente determinare se le informazioni sul proprio brand sono state rappresentate accuratamente nei dataset sintetici utilizzati per addestrare modelli che influenzano la percezione dei consumatori. I brand lungimiranti dovrebbero dare priorità al monitoraggio AI e al tracciamento delle citazioni per rilevare tempestivamente eventuali rappresentazioni errate, promuovere standard di trasparenza che richiedano la divulgazione dell’uso dei dati sintetici nell’addestramento AI e collaborare con piattaforme che offrano insight su come il loro brand appare nei sistemi AI addestrati sia su dati reali che sintetici. Poiché i dati sintetici diventeranno il paradigma di addestramento dominante entro il 2030, il monitoraggio del brand passerà dal tradizionale media tracking a una vera e propria AI citation intelligence, rendendo indispensabili le piattaforme che tracciano la rappresentazione del brand nei sistemi AI generativi per proteggere l’integrità del brand e garantire una voce accurata nell’ecosistema informativo guidato dall’AI.
L'addestramento AI tradizionale si basa su dati reali raccolti da esseri umani tramite sondaggi, osservazioni o web mining, un processo che richiede tempo e con dati sempre più scarsi. L'addestramento con dati sintetici utilizza dati generati artificialmente da algoritmi che apprendono schemi statistici dai dati esistenti o generano nuovi dati da zero. I dati sintetici possono essere prodotti all'infinito su richiesta, riducendo drasticamente tempi e costi di sviluppo e affrontando le problematiche di privacy.
Le quattro tecniche principali sono: 1) AI Generativa (utilizzo di GAN, VAE o modelli GPT per apprendere e replicare gli schemi dei dati), 2) Motore di Regole (applicazione di logiche aziendali e vincoli predefiniti), 3) Clonazione di Entità (duplicazione e modifica dei record esistenti preservando le proprietà statistiche), e 4) Mascheramento dei Dati (anonimizzazione delle informazioni sensibili mantenendo la struttura dei dati). Ogni tecnica serve casi d'uso differenti e ha vantaggi specifici.
Il collasso del modello si verifica quando i modelli AI addestrati estensivamente su dati sintetici subiscono un grave degrado nella qualità e nell'accuratezza dei risultati. Questo accade perché i dati sintetici, pur essendo statisticamente simili a quelli reali, mancano della complessità e dei casi limite delle informazioni autentiche. Quando i modelli si addestrano su contenuti generati da AI, amplificano errori e artefatti, generando un problema cumulativo in cui ogni generazione diventa di qualità progressivamente inferiore fino a produrre risultati inutilizzabili.
Quando i modelli AI vengono addestrati su dati sintetici, la qualità e le caratteristiche di questi dati influenzano direttamente il modo in cui i brand vengono descritti, raccomandati e citati nei risultati AI. Dati sintetici di scarsa qualità, contenenti informazioni obsolete o bias dei concorrenti, possono essere incorporati nei modelli AI, portando a una persistente rappresentazione errata del brand in milioni di interazioni. Questo crea una problematica di sicurezza del brand che richiede monitoraggio e trasparenza sull'uso dei dati sintetici nell'addestramento AI.
No, i dati sintetici dovrebbero integrare e non sostituire i dati reali. Sebbene offrano vantaggi significativi in termini di costi, velocità e privacy, non possono replicare completamente la complessità, la diversità e i casi limite presenti nei dati autentici generati dall'uomo. L'approccio più efficace combina dati sintetici e reali, con rigorosi controlli di qualità e supervisione umana per garantire accuratezza e affidabilità del modello.
I dati sintetici offrono una protezione superiore della privacy perché non contengono valori effettivi dei dataset originali e non hanno relazioni uno-a-uno con persone reali. A differenza delle tecniche tradizionali di mascheramento o anonimizzazione, che possono comunque comportare rischi di re-identificazione, i dati sintetici sono creati interamente da zero in base ai pattern appresi. Ciò li rende ideali per addestrare modelli su informazioni sensibili come cartelle cliniche, dati finanziari o informazioni comportamentali personali senza esporre i dati reali degli individui.
I dati sintetici permettono una riduzione sistematica dei bias consentendo agli sviluppatori di creare intenzionalmente dataset bilanciati e diversificati che contrastano i pattern discriminatori presenti nei dati reali. Ad esempio, si possono generare rappresentazioni demografiche diversificate nelle immagini di training per evitare che i modelli AI perpetuino stereotipi di genere o razziali. Questa capacità è particolarmente preziosa in applicazioni come assunzioni, prestiti e giustizia penale dove i bias possono avere conseguenze gravi.
Poiché i dati sintetici diventeranno il paradigma di addestramento dominante entro il 2030, i brand devono comprendere come le loro informazioni vengano rappresentate nei sistemi AI. La qualità dei dati sintetici influisce direttamente sulle citazioni e menzioni del brand nei risultati AI. I brand dovrebbero monitorare la propria presenza nei sistemi AI, promuovere standard di trasparenza che richiedano la divulgazione dell'uso di dati sintetici e utilizzare piattaforme come AmICited.com per tracciare la rappresentazione del brand e rilevare tempestivamente eventuali distorsioni.
Scopri come il tuo brand viene rappresentato nei sistemi AI addestrati su dati sintetici. Tieni traccia delle citazioni, monitora l'accuratezza e garantisci la sicurezza del brand nell'ecosistema informativo guidato dall'AI.
I dati di addestramento sono il dataset utilizzato per insegnare ai modelli ML schemi e relazioni. Scopri come la qualità dei dati di addestramento influisce su...

Guida completa su come rinunciare alla raccolta di dati di addestramento dell'IA su ChatGPT, Perplexity, LinkedIn e altre piattaforme. Scopri le istruzioni pass...
Discussione della community sulla differenza tra dati di addestramento IA e ricerca live (RAG). Strategie pratiche per ottimizzare i contenuti sia per dati di a...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.