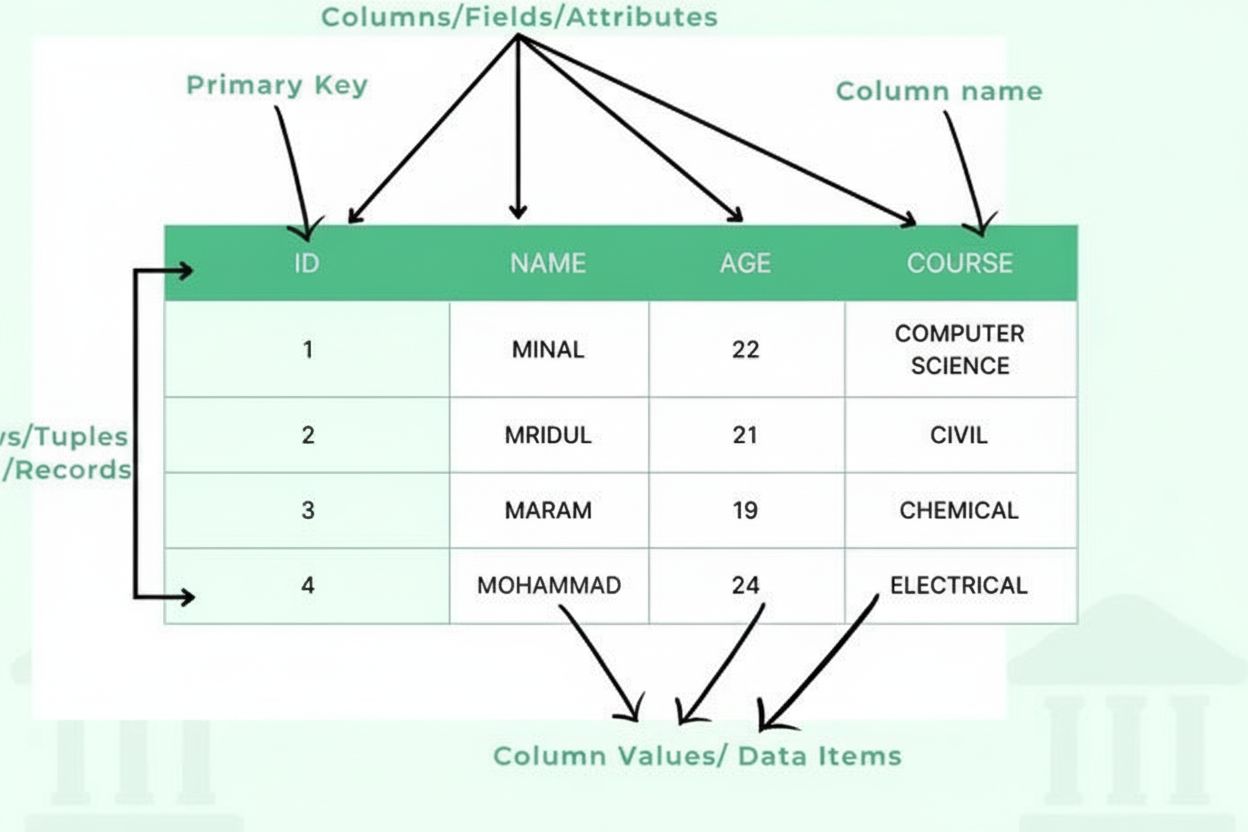
Definizione di Tabella: dati organizzati in righe e colonne
Una tabella è una struttura dati fondamentale che organizza le informazioni in un formato a griglia bidimensionale composto da righe orizzontali e colonne verticali. Nella sua forma più semplice, una tabella rappresenta una raccolta di dati correlati disposti in modo strutturato, in cui ogni incrocio tra una riga e una colonna contiene un singolo elemento di dato o cella. Le tabelle costituiscono la pietra angolare dei database relazionali, dei fogli di calcolo, dei data warehouse e praticamente di ogni sistema che necessita di memorizzazione e recupero di informazioni organizzate. Il punto di forza delle tabelle risiede nella loro capacità di permettere una rapida scansione visiva, un confronto logico dei dati su più dimensioni e un accesso programmatico a informazioni specifiche tramite linguaggi di interrogazione standardizzati. Che vengano utilizzate in analisi aziendali, ricerca scientifica o piattaforme di monitoraggio AI, le tabelle forniscono un formato universalmente compreso per presentare dati strutturati che possono essere facilmente interpretati sia da esseri umani che da macchine.
Contesto storico ed evoluzione dell’organizzazione dei dati tabellari
Il concetto di organizzare le informazioni in righe e colonne precede di secoli l’informatica moderna. Le civiltà antiche usavano formati tabellari per registrare inventari, transazioni finanziarie e osservazioni astronomiche. Tuttavia, la formalizzazione delle strutture tabellari nell’informatica è emersa con lo sviluppo della teoria dei database relazionali da parte di Edgar F. Codd nel 1970, rivoluzionando il modo in cui i dati potevano essere archiviati e interrogati. Il modello relazionale stabiliva che i dati dovessero essere organizzati in tabelle con relazioni chiaramente definite, cambiando radicalmente i principi di progettazione dei database. Negli anni ‘80 e ‘90, applicazioni di fogli di calcolo come Lotus 1-2-3 e Microsoft Excel hanno democratizzato l’uso delle tabelle, rendendo l’organizzazione tabellare dei dati accessibile anche agli utenti non tecnici. Oggi, circa il 97% delle organizzazioni utilizza applicazioni di fogli di calcolo per la gestione e l’analisi dei dati, a dimostrazione dell’importanza duratura dell’organizzazione dei dati basata sulle tabelle. L’evoluzione prosegue con gli sviluppi moderni dei database colonnari, dei sistemi NoSQL e dei data lake, che mettono in discussione gli approcci tradizionali orientati alle righe pur mantenendo strutture fondamentali simili a tabelle per l’organizzazione delle informazioni.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Componenti principali e struttura delle tabelle
Una tabella è composta da diversi componenti strutturali essenziali che collaborano per creare un quadro dati organizzato. Le colonne (dette anche campi o attributi) scorrono verticalmente e rappresentano categorie di informazioni, come “Nome cliente”, “Indirizzo email” o “Data acquisto”. Ogni colonna ha un tipo di dato definito che specifica quale tipo di informazione può contenere: numeri interi, stringhe di testo, date, decimali o strutture più complesse. Le righe (dette anche record o tuple) scorrono orizzontalmente e rappresentano singole voci di dati o entità, con ogni riga che contiene un record completo. L’incrocio tra una riga e una colonna crea una cella o elemento di dato, che contiene una singola informazione. Le intestazioni di colonna identificano ciascuna colonna e compaiono nella parte superiore della tabella, fornendo contesto ai dati sottostanti. Le chiavi primarie sono colonne speciali che identificano in modo univoco ogni riga, assicurando che non esistano record duplicati. Le chiavi esterne stabiliscono relazioni tra tabelle facendo riferimento a chiavi primarie in altre tabelle. Questa organizzazione gerarchica consente ai database di mantenere l’integrità dei dati, prevenire la ridondanza e supportare query complesse che recuperano informazioni in base a criteri multipli.
Confronto tra metodi di organizzazione delle tabelle
| Aspetto | Tabelle orientate alle righe | Tabelle orientate alle colonne | Approcci ibridi |
|---|
| Metodo di archiviazione | Dati archiviati e accessibili per record completi | Dati archiviati e accessibili per singole colonne | Combina i vantaggi di entrambi gli approcci |
| Prestazioni delle query | Ottimizzate per query transazionali che recuperano record completi | Ottimizzate per query analitiche su colonne specifiche | Prestazioni bilanciate per carichi di lavoro misti |
| Casi d’uso | OLTP (Online Transaction Processing), operazioni aziendali | OLAP (Online Analytical Processing), data warehousing | Analisi in tempo reale, operational intelligence |
| Esempi di database | MySQL, PostgreSQL, Oracle, SQL Server | Vertica, Cassandra, HBase, Parquet | Snowflake, BigQuery, Apache Iceberg |
| Efficienza della compressione | Tassi di compressione inferiori per la diversità dei dati | Tassi di compressione superiori per valori simili nelle colonne | Compressione ottimizzata per pattern specifici |
| Prestazioni in scrittura | Scritture veloci per record completi | Scritture più lente che richiedono aggiornamenti sulle colonne | Prestazioni di scrittura bilanciate |
| Scalabilità | Scala bene per il volume delle transazioni | Scala bene per il volume dei dati e la complessità delle query | Scala su entrambe le dimensioni |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Implementazione tecnica e architettura dei database
Nei sistemi di gestione di database relazionali (RDBMS), le tabelle sono implementate come raccolte strutturate di righe in cui ogni riga rispetta uno schema predefinito. Lo schema definisce la struttura della tabella, specificando nomi delle colonne, tipi di dati, vincoli e relazioni. Quando i dati vengono inseriti in una tabella, il sistema di gestione del database verifica che ogni valore corrisponda al tipo di dato della rispettiva colonna e soddisfi eventuali vincoli definiti. Ad esempio, una colonna definita come INTEGER rifiuterà valori testuali, e una colonna marcata come NOT NULL rifiuterà voci vuote. Gli indici vengono creati sulle colonne interrogate frequentemente per accelerare il recupero dei dati, funzionando come riferimenti organizzati che consentono al database di localizzare righe specifiche senza dover analizzare l’intera tabella. La normalizzazione è un principio di progettazione che organizza le tabelle per minimizzare la ridondanza dei dati e migliorare l’integrità suddividendo le informazioni in tabelle correlate collegate tramite chiavi. I database moderni supportano le transazioni, che assicurano che più operazioni sulle tabelle vadano tutte a buon fine o tutte falliscano insieme, mantenendo la coerenza anche in caso di guasti di sistema. L’ottimizzatore di query nei motori di database analizza le query SQL e determina il modo più efficiente per accedere ai dati delle tabelle, tenendo conto degli indici disponibili e delle statistiche sulle tabelle.
Presentazione e visualizzazione dei dati nelle tabelle
Le tabelle rappresentano il meccanismo principale per presentare dati strutturati agli utenti sia in formato digitale che cartaceo. Nelle applicazioni di business intelligence e analisi, le tabelle visualizzano metriche aggregate, indicatori di prestazione e dettagli delle transazioni che consentono ai decisori di comprendere rapidamente set di dati complessi. Ricerche indicano che l’83% dei professionisti aziendali si affida alle tabelle dati come strumento principale per analizzare le informazioni, poiché le tabelle permettono confronti puntuali e il riconoscimento di pattern. Le tabelle HTML sui siti web utilizzano markup semantico con gli elementi <table>, <tr> (riga di tabella), <td> (dato di tabella) e <th> (intestazione di tabella) per strutturare i dati sia per la visualizzazione sia per l’interpretazione programmatica. Le applicazioni di fogli di calcolo come Microsoft Excel, Google Sheets e LibreOffice Calc estendono le funzionalità delle tabelle di base con formule, formattazione condizionale e tabelle pivot che permettono agli utenti di eseguire calcoli e riorganizzare dinamicamente i dati. Le best practice di visualizzazione dei dati raccomandano di utilizzare le tabelle quando i valori precisi sono più importanti dei pattern visivi, quando si confrontano più attributi di singoli record o quando gli utenti devono eseguire ricerche o calcoli. L’Iniziativa per l’accessibilità del web del W3C sottolinea che tabelle strutturate correttamente, con intestazioni chiare e markup adeguato, sono essenziali per rendere i dati accessibili agli utenti con disabilità, in particolare a chi utilizza screen reader.
Tabelle nel monitoraggio AI e nel tracciamento dei contenuti
Nel contesto delle piattaforme di monitoraggio AI come AmICited, le tabelle svolgono un ruolo critico nell’organizzazione e presentazione dei dati su come i contenuti appaiono su diversi sistemi AI. Le tabelle di monitoraggio tracciano metriche come frequenza delle citazioni, date di comparsa, fonti delle piattaforme AI (ChatGPT, Perplexity, Google AI Overviews, Claude) e informazioni contestuali su come domini e URL sono referenziati. Queste tabelle permettono alle organizzazioni di comprendere la propria visibilità del brand nelle risposte AI e identificare le tendenze su come i diversi sistemi AI citano o fanno riferimento ai loro contenuti. La natura strutturata delle tabelle di monitoraggio consente di filtrare, ordinare e aggregare i dati delle citazioni, permettendo di rispondere a domande come “Quali dei nostri URL compaiono più frequentemente nelle risposte di Perplexity?” o “Come è cambiato il nostro tasso di citazione nell’ultimo mese?”. Le tabelle dati nei sistemi di monitoraggio facilitano inoltre il confronto su più dimensioni: confrontando i pattern di citazione tra diverse piattaforme AI, analizzando la crescita delle citazioni nel tempo o identificando quali tipologie di contenuto ricevono più riferimenti AI. La possibilità di esportare i dati di monitoraggio dalle tabelle in report, dashboard e strumenti di analisi ulteriori rende le tabelle indispensabili per le organizzazioni che vogliono comprendere e ottimizzare la propria presenza nei contenuti generati dall’AI.
Best practice per la progettazione e l’organizzazione delle tabelle
Una progettazione efficace delle tabelle richiede un’attenta considerazione della struttura, delle convenzioni di denominazione e dei principi di organizzazione dei dati. La denominazione delle colonne dovrebbe usare identificatori chiari e descrittivi che riflettano accuratamente i dati contenuti, evitando abbreviazioni che possano confondere utenti o sviluppatori. La scelta dei tipi di dati è fondamentale: selezionare tipi adeguati impedisce l’inserimento di dati non validi e permette ordinamenti e confronti corretti. La definizione della chiave primaria assicura che ogni riga sia identificabile in modo univoco, essenziale per l’integrità dei dati e la creazione di relazioni con altre tabelle. La normalizzazione riduce la ridondanza dei dati organizzando le informazioni in tabelle correlate invece di duplicarle in più posizioni. La strategia di indicizzazione deve bilanciare le prestazioni delle query con il sovraccarico di mantenimento degli indici durante le modifiche ai dati. La documentazione della struttura delle tabelle, incluse definizioni delle colonne, tipi di dati, vincoli e relazioni, è essenziale per la mantenibilità a lungo termine. Il controllo degli accessi va implementato per proteggere i dati sensibili nelle tabelle da accessi non autorizzati. L’ottimizzazione delle prestazioni comporta il monitoraggio dei tempi di esecuzione delle query e l’adeguamento di strutture, indici o query per migliorarne l’efficienza. Le procedure di backup e ripristino devono essere stabilite per proteggere i dati delle tabelle da perdite o corruzioni.
Aspetti essenziali dell’organizzazione e della gestione delle tabelle
- Componenti strutturali: Le tabelle sono composte da colonne (campi), righe (record), intestazioni, elementi di dati (celle), tipi di dati, chiavi primarie e chiavi esterne che collaborano per creare strutture dati organizzate
- Integrità dei dati: Vincoli, regole di validazione e relazioni tra chiavi mantengono la precisione dei dati e prevengono incongruenze o duplicati
- Efficienza delle query: Un’adeguata indicizzazione, normalizzazione e ottimizzazione delle query consentono un recupero rapido di informazioni specifiche da grandi tabelle
- Accessibilità: Markup HTML semantico, intestazioni chiare e struttura appropriata rendono le tabelle accessibili agli utenti con disabilità e alle tecnologie assistive
- Scalabilità: Tabelle ben progettate gestiscono efficientemente crescenti volumi di dati tramite indicizzazione adeguata, partizionamento e tecniche di ottimizzazione dei database
- Gestione delle relazioni: Le chiavi esterne stabiliscono connessioni tra tabelle, consentendo query complesse che combinano informazioni da più fonti
- Vincolo sui tipi di dati: I tipi di dati definiti assicurano che solo informazioni valide siano archiviate in ogni colonna, prevenendo errori e consentendo un corretto ordinamento
- Documentazione e manutenzione: Una chiara documentazione della struttura delle tabelle e una manutenzione regolare ne garantiscono l’usabilità e le prestazioni nel tempo
Evoluzione e futuro dell’organizzazione dei dati basata sulle tabelle
Il futuro dell’organizzazione dei dati basata sulle tabelle si sta evolvendo per rispondere a requisiti dati sempre più complessi, pur mantenendo i principi fondamentali che rendono efficaci le tabelle. I formati di archiviazione colonnari come Apache Parquet e ORC stanno diventando lo standard negli ambienti big data, ottimizzando le tabelle per carichi di lavoro analitici pur mantenendo la struttura tabellare. I dati semi-strutturati in formato JSON e XML sono sempre più spesso archiviati all’interno delle colonne delle tabelle, consentendo alle tabelle di gestire sia dati strutturati che flessibili. L’integrazione del machine learning permette ai database di ottimizzare automaticamente le strutture delle tabelle e l’esecuzione delle query in base ai pattern di utilizzo. Le piattaforme di analisi in tempo reale stanno estendendo le tabelle per supportare dati in streaming e aggiornamenti continui, superando le operazioni tabellari tradizionalmente batch-oriented. I database cloud-native stanno riprogettando l’implementazione delle tabelle per sfruttare il calcolo distribuito, consentendo alle tabelle di scalare su più server e regioni geografiche. I framework di data governance pongono maggiore enfasi sui metadati delle tabelle, sul tracciamento della lineage e sulle metriche di qualità per garantire l’affidabilità dei dati. L’emergere di piattaforme dati potenziate dall’AI crea nuove opportunità per le tabelle come fonti strutturate per l’addestramento dei modelli di machine learning, sollevando anche interrogativi su come progettarle per fornire dati di alta qualità ai fini dell’addestramento. Mentre le organizzazioni continuano a generare una quantità di dati in crescita esponenziale, le tabelle rimangono la struttura fondamentale per organizzare, interrogare e analizzare le informazioni, con innovazioni che puntano a migliorarne prestazioni, scalabilità e integrazione con le tecnologie dati moderne.