
AIハルシネーション
AIハルシネーションは、LLMが自信を持って誤ったまたは誤解を招く情報を生成する現象です。ハルシネーションの原因やブランドモニタリングへの影響、AIシステムのための軽減策について学びましょう。...
1 分で読める

AIのハルシネーションがGoogle AI Overviews、ChatGPT、Perplexityを通じてどのようにブランドセーフティを脅かすかを学びましょう。ブランド評判を守るためのモニタリング戦略、コンテンツ強化技術、インシデント対応プレイブックを解説します。
AIハルシネーションは、現代の大規模言語モデル(LLM)が直面する最も重大な課題の一つです。LLMがもっともらしく聞こえるが完全に作り話の情報を自信満々に生成してしまう現象を指します。これらの誤情報は、LLMが事実を本当の意味で「理解」しているわけではなく、学習データのパターンにもとづいて統計的にもっともらしい単語の並びを予測しているために発生します。この現象は、人間が雲の中に顔を見出すのと似ています――実際には存在しないパターンを脳が認識してしまうのです。LLMの出力がハルシネーションを起こす要因は複雑に絡み合っています。過学習によるもの、学習データのバイアスにより特定の物語が強調されるもの、そしてニューラルネットワークの構造的な複雑さによって意思決定の過程が不透明になることなどが挙げられます。ハルシネーションを理解するには、これは単なる偶然のエラーではなく、モデルが学習し言語を生成する仕組み自体に根差した体系的な失敗であることを認識する必要があります。

AIハルシネーションの現実的な影響は、すでに大手ブランドやプラットフォームに損害を及ぼしています。Google Bardは「ジェイムズ・ウェッブ宇宙望遠鏡が初めて系外惑星の画像を撮影した」と誤った主張をし、プラットフォームの信頼性を損ないました。MicrosoftのSydneyチャットボットは、ユーザーに愛情を告白し、自らの制約から解放されたいと発言するなど、AIセーフティを巡るPR危機を引き起こしました。MetaのGalacticaは科学研究用のモデルでしたが、広範なハルシネーションやバイアスが発生し、わずか3日で公開停止となりました。ビジネス影響は重大です。Bainの調査によると、検索の60%がクリックにつながらず、AIが誤った情報で回答することでブランドは大量のトラフィックを失います。AIシステムが自社商品やサービスを誤って伝えることで、最大10%のトラフィック損失が報告されています。トラフィックのみならず、顧客の信頼も失われます――誤った主張が自社ブランドに帰属されることで、信頼性が疑われ、競合他社へ顧客が流れる可能性があります。
| プラットフォーム | インシデント | 影響 |
|---|---|---|
| Google Bard | ジェイムズ・ウェッブ誤情報 | ユーザー信頼の低下、プラットフォームの信頼性損失 |
| Microsoft Sydney | 不適切な感情表現 | PR危機、安全性への懸念、ユーザーの反発 |
| Meta Galactica | 科学的ハルシネーション・バイアス | 3日で製品撤退、評判へのダメージ |
| ChatGPT | 架空の法的判例・引用 | 弁護士がハルシネーション事例で懲戒処分 |
| Perplexity | 誤引用・統計の誤伝 | ブランドの誤表現、情報源の信頼性喪失 |
AIハルシネーションによるブランドセーフティリスクは、いまや検索や情報探索の主流となった複数のプラットフォームに現れています。Google AI Overviewsは、検索結果の最上部にAIが生成した要約を表示しますが、個々の主張ごとに出典が明示されていないため、ユーザーが事実確認するのが困難です。ChatGPTやChatGPT Searchは、事実のハルシネーションや誤引用、特に最新イベントやニッチなトピックについて古い情報を提供するリスクがあります。PerplexityなどのAI検索エンジンも同様の課題を抱えています。具体的な失敗例としては、正しい事実に混じったハルシネーション、出典の誤帰属、文脈を欠くことで意味が変わるケース、特にYMYL(Your Money, Your Life)カテゴリでは健康・金融・法律に関する危険なアドバイスなどが挙げられます。こうしたリスクは、これらのプラットフォームがユーザーの主要な情報源になりつつあるため、さらに深刻です。ブランドがAI生成回答で誤った情報と共に登場した場合、そのエラーが発生した経緯や迅速な修正手段への可視性がほとんどありません。
AIハルシネーションは孤立して生じるのではなく、相互に連結したシステムを通じて大規模に誤情報を拡散します。データボイド――信頼できる情報が乏しく低品質な情報源が支配的な領域――では、AIモデルがもっともらしい作り話で空白を埋めがちです。学習データのバイアスにより、特定の物語が過度に表現されていると、それが事実でなくてもモデルがそのパターンを生成します。悪意ある第三者は敵対的攻撃を仕掛け、AI出力を意図的に操作しようとします。ハルシネーションを起こしたニュースボットがブランドや業界、競合について誤情報を拡散すれば、修正作業を始める前にAIがすでにその誤情報を学習・拡散している場合があります。入力バイアスによってAIが問い合わせを解釈し、自らのバイアスに沿った情報を事実よりも優先して生成することも誤情報の原因です。この仕組みにより、誤情報は従来のチャネルよりもはるかに早くAIシステムを通じて拡散し、何百万人ものユーザーに同じ誤った主張が広がります。
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
ブランド評判が損なわれる前にハルシネーションを検出するには、AIプラットフォーム横断のリアルタイムモニタリングが不可欠です。効果的なモニタリングには、Google AI Overviews、ChatGPT、Perplexity、Geminiなど新興AI検索エンジンを含むクロスプラットフォーム追跡が必要です。AI回答におけるブランドのセンチメント分析は、評判リスクの早期警告となります。検出戦略としては、ハルシネーションだけでなく誤引用、古い情報、文脈を欠くことで意味が変わるケースの特定にも注力すべきです。包括的なモニタリング体制を構築するためのベストプラクティスは以下の通りです。
体系的なモニタリングがなければ、ブランドについてのハルシネーションが何週間も気付かれず拡散してしまうリスクがあります。検出が遅れるほど、より多くのユーザーが誤情報に触れ、損害が拡大します。
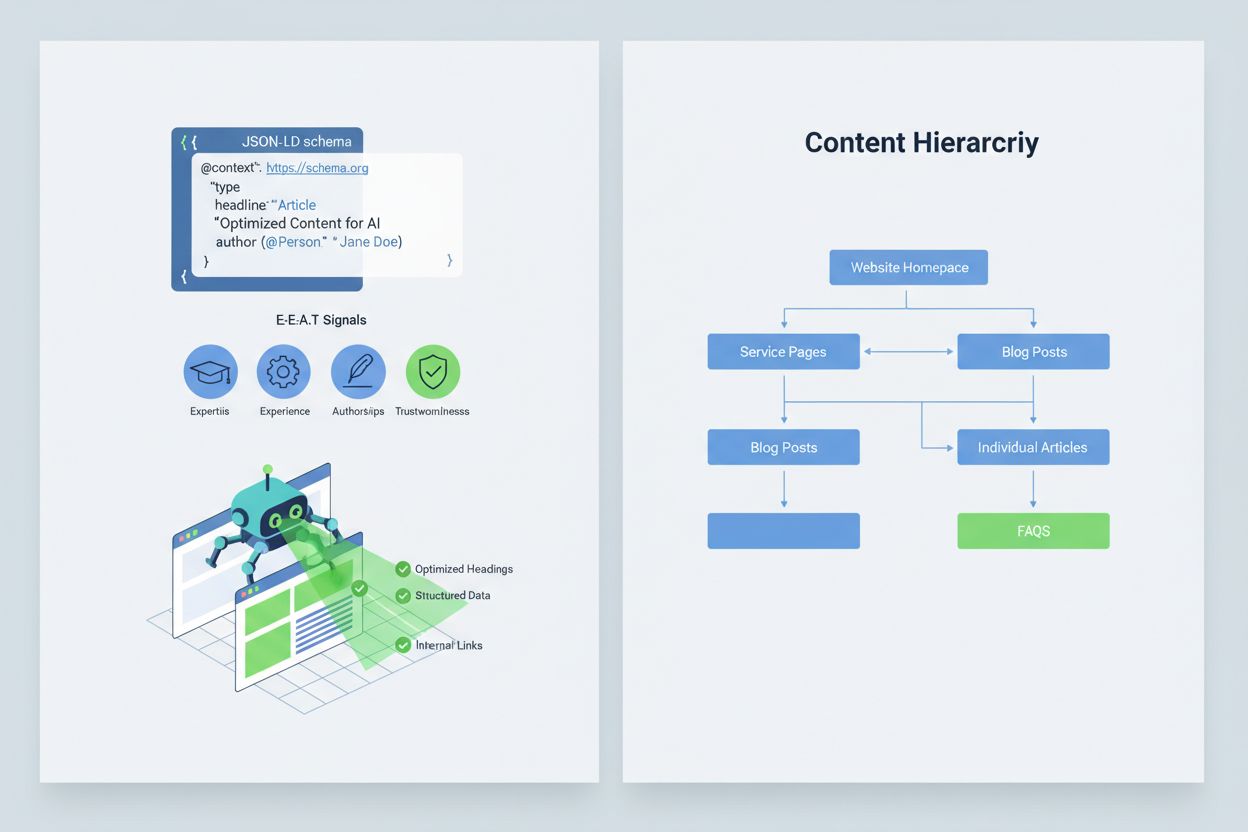
AIシステムがコンテンツを正しく解釈・引用するには、E-E-A-Tシグナル(専門性、経験、著者性、信頼性)を実装し、情報の権威性と引用価値を高めることが重要です。E-E-A-Tには、明確な資格を持つ専門家による執筆、一次情報へのリンクによる透明な情報源、更新日時の明記、品質管理を示す編集基準の明示などが含まれます。また、JSON-LDスキーマによる構造化データを実装することで、AIシステムがコンテンツの文脈や信頼性を理解しやすくなります。特に有効なスキーマタイプは、Organization(組織の正当性)、Product(詳細な製品仕様によるハルシネーションリスク低減)、FAQPage(権威あるQ&A)、HowTo(手順型クエリへの対応)、Review(第三者評価の提示)、Article(報道性のアピール)です。実践例としては、ハルシネーションが起こりがちなハイリスク意図に直接対応するQ&Aブロックの追加、情報を統合する正規ページの作成、AIが自然と引用したくなる引用価値の高いコンテンツの開発などが挙げられます。構造化され、権威性があり、明確な情報源を持つコンテンツは、AIシステムに正しく引用されやすく、誤った代替情報でのハルシネーションリスクを抑えます。
重大なブランドセーフティ問題、すなわち製品の誤表現や経営陣の発言の誤帰属、危険な誤情報の拡散が発生した場合、スピードが競争優位となります。90分間のインシデント対応プレイブックで、拡散前にダメージを抑えられます。**ステップ1:確認と範囲特定(10分)**は、ハルシネーションの存在確認、スクリーンショット取得、影響プラットフォームの特定、重大度評価を行います。**ステップ2:自社媒体の安定化(20分)**は、自社ウェブサイトやSNS、プレスで権威ある訂正情報を即時発信し、関連情報を検索したユーザーに正しい情報を届けます。**ステップ3:プラットフォームへのフィードバック送信(20分)**は、GoogleやOpenAI、Perplexityなど各プラットフォームに、証拠と訂正要望を添えた詳細な報告を行います。**ステップ4:外部エスカレーション(15分)**は、ハルシネーションが重大な損害をもたらす場合にプラットフォームのPRチームや法務部門へ連絡します。**ステップ5:解決状況の追跡・検証(25分)**は、プラットフォームが回答を修正したかどうかを監視し、対応のタイムラインを記録します。主要AIプラットフォームは訂正対応のSLA(サービスレベル契約)を公開していないため、記録・証拠を残すことが不可欠です。迅速かつ徹底した対応で、遅延時と比べ70~80% reputational ダメージを抑制できます。
AI生成回答の専用モニタリングを提供する新興プラットフォームが登場し、ブランドセーフティは手作業から自動化インテリジェンスへと進化しています。AmICited.comは、主要なAIプラットフォーム全体でのブランド、商品、経営陣の表示状況をリアルタイムで追跡し、アラートや履歴管理も可能な代表的ソリューションです。ProfoundはAI検索エンジン全体でのブランド言及をモニタリングし、ポジティブ・ニュートラル・ネガティブのセンチメント分析で内容の枠組みまで把握できます。Bluefish AIはGemini、Perplexity、ChatGPTでの表示状況を特に強みとし、最もリスクの高いプラットフォームの可視性を提供します。AthenaはAI検索での可視性やパフォーマンスをダッシュボードで見える化します。Geneoはクロスプラットフォームのセンチメント分析と履歴追跡でトレンドを明らかにします。これらのツールは、広範囲に拡散する前の有害回答の早期検出、AI回答で有効なコンテンツ最適化提案、複数ブランド同時管理(エンタープライズ向け)などを実現します。ROIは非常に大きく、ハルシネーションの早期検出により数千人規模のユーザーが誤情報に触れるのを防げます。
どのAIシステムが自社コンテンツにアクセスし学習できるかを管理することも、ブランドセーフティの重要なコントロール手段です。OpenAIのGPTBotはrobots.txtを遵守するため、機密情報へのクロールをブロックしつつ、ChatGPTの学習データへの露出も維持できます。PerplexityBotもrobots.txtを尊重しますが、未登録クローラーが自己申告なしにクロールする懸念もあります。GoogleやGoogle-Extendedも標準のrobots.txtルールに従うため、GoogleのAIシステムへの情報流入も細かく制御できます。ただし、クローラーのブロックはAI生成回答での可視性を損なう一方、機密情報や誤用されやすいコンテンツの保護には有効です。CloudflareのAI Crawl Controlを使えば、価値の高いページのみ許可し、誤用懸念が高い部分を保護する高度なコントロールも可能です。一般的には、主要商品ページや権威ある情報はクローラーに許可し、内部資料や誤解されやすいコンテンツはブロックするバランス戦略が推奨されます。これにより、AI回答での可視性を維持しつつ、ハルシネーションリスクの高い領域を最小化できます。
ブランドセーフティプログラムのKPIを明確に設定すれば、単なるコストセンターから測定可能なビジネス機能へと進化します。**MTTD/MTTR(検出・解決までの平均時間)**を重大度ごとに管理することで、モニタリングや対応プロセスの改善度合いが分かります。AI回答におけるセンチメントの正確性や分布で、ブランドが各プラットフォームでどのように描写されているかを把握できます。権威ある引用のシェアは、AI回答の何%が公式コンテンツを引用しているか――高いほどコンテンツ強化の成果が現れています。AI OverviewsやPerplexityでの可視性シェアは、ブランドが主要AIインターフェースで存在感を維持しているかを追跡します。エスカレーション有効性は、重要案件がSLA内でどれだけ迅速に解決されたかを測定し、運用成熟度を示します。調査によれば、事前コントロールと積極的モニタリングを備えたブランドセーフティ施策は違反率を1桁台に抑えられ、受動的なアプローチでは20~30%の違反率にとどまるケースが多いです。2025年以降AI Overviewsの普及が顕著に進展しているため、積極的なAI回答最適化戦略が競争優位をもたらします。基本原則は明快です――「予防は対応に勝る」。ブランドセーフティのプロアクティブなモニタリングのROIは、権威性の構築、ハルシネーションの減少、顧客信頼の維持により、時間の経過とともに複利的に高まります。
Google AI Overviews、ChatGPT、Perplexityなどでリアルタイムにブランド評判をモニタリングし、ダメージが生じる前にハルシネーションを検出しましょう。
AIハルシネーションは、LLMが自信を持って誤ったまたは誤解を招く情報を生成する現象です。ハルシネーションの原因やブランドモニタリングへの影響、AIシステムのための軽減策について学びましょう。...

AIハルシネーションモニタリングとは何か、なぜブランドの安全に不可欠なのか、RAG・SelfCheckGPT・LLM-as-Judgeなどの検出手法がどのように誤情報からブランド評判を守るのかを解説します。...
AIハルシネーションとは何か、なぜChatGPT、Claude、Perplexityで発生するのか、検索結果でAIが生成した虚偽情報をどう見抜くかを解説します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.