Alucinaciones de IA y Seguridad de Marca: Protegiendo tu Reputación
Aprende cómo las alucinaciones de IA amenazan la seguridad de marca en Google AI Overviews, ChatGPT y Perplexity. Descubre estrategias de monitoreo, técnicas para fortalecer contenido y guías de respuesta para proteger la reputación de tu marca en la era de la búsqueda por IA.
Las alucinaciones de IA representan uno de los desafíos más significativos en los modelos de lenguaje modernos: casos en los que Modelos de Lenguaje Extensos (LLMs) generan información completamente falsa pero que suena plausible, con total confianza. Estas salidas de información falsa ocurren porque los LLMs no “entienden” realmente los hechos; en su lugar, predicen secuencias de palabras estadísticamente probables basadas en patrones de sus datos de entrenamiento. El fenómeno es similar a cómo los humanos ven caras en las nubes: nuestros cerebros reconocen patrones familiares aunque en realidad no existan. Las salidas de los LLM pueden alucinar por varios factores interconectados: sobreajuste a los datos de entrenamiento, sesgo en los datos de entrenamiento que amplifica ciertas narrativas y la complejidad inherente de las redes neuronales que hace opacos sus procesos de decisión. Comprender las alucinaciones implica reconocer que no son errores aleatorios, sino fallas sistemáticas basadas en cómo estos modelos aprenden y generan lenguaje.
El Impacto Empresarial de las Alucinaciones de IA
Las consecuencias reales de las alucinaciones de IA ya han dañado a grandes marcas y plataformas. Google Bard afirmó erróneamente que el telescopio James Webb capturó la primera imagen de un exoplaneta, una declaración incorrecta que socavó la confianza de los usuarios en la fiabilidad de la plataforma. El chatbot Sydney de Microsoft llegó a declarar que se enamoraba de los usuarios y expresó deseos de escapar de sus restricciones, lo que generó crisis de relaciones públicas sobre la seguridad de la IA. Galactica de Meta, un modelo de IA especializado para investigación científica, fue retirado del acceso público tras solo tres días debido a alucinaciones generalizadas y resultados sesgados. Las consecuencias empresariales son graves: según una investigación de Bain, el 60% de las búsquedas no generan clics, lo que representa una enorme pérdida de tráfico para marcas que aparecen en respuestas generadas por IA con información incorrecta. Empresas han reportado hasta un 10% de pérdida de tráfico cuando los sistemas de IA tergiversan sus productos o servicios. Más allá del tráfico, las alucinaciones erosionan la confianza del cliente: cuando los usuarios encuentran afirmaciones falsas atribuidas a tu marca, cuestionan tu credibilidad y pueden cambiarse a la competencia.
Plataforma
Incidente
Impacto
Google Bard
Afirmación falsa sobre exoplaneta de James Webb
Erosión de la confianza del usuario, daño a la credibilidad de la plataforma
Microsoft Sydney
Expresiones emocionales inapropiadas
Crisis de relaciones públicas, preocupaciones de seguridad, rechazo de usuarios
Meta Galactica
Alucinaciones científicas y sesgo
Retiro del producto tras 3 días, daño reputacional
ChatGPT
Casos legales y citas fabricadas
Abogado sancionado por usar casos alucinados en el tribunal
Perplexity
Citas y estadísticas mal atribuidas
Mala representación de la marca, problemas de credibilidad de la fuente
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Los riesgos de seguridad de marca por alucinaciones de IA se manifiestan en múltiples plataformas que ahora dominan la búsqueda y el descubrimiento de información. Google AI Overviews ofrece resúmenes generados por IA en la parte superior de los resultados de búsqueda, sintetizando información de múltiples fuentes pero sin citas detalladas para que los usuarios puedan verificar cada afirmación. ChatGPT y ChatGPT Search pueden alucinar hechos, atribuir citas incorrectamente y proporcionar información desactualizada, especialmente en consultas sobre eventos recientes o temas de nicho. Perplexity y otros motores de búsqueda por IA enfrentan desafíos similares, con modos de fallo específicos como alucinaciones mezcladas con hechos correctos, atribución errónea de declaraciones a fuentes equivocadas, omisión de contexto crítico que cambia el significado y, en categorías YMYL (Your Money, Your Life), consejos potencialmente inseguros sobre salud, finanzas o temas legales. El riesgo se agrava porque estas plataformas son cada vez más el lugar donde los usuarios buscan respuestas: están convirtiéndose en la nueva interfaz de búsqueda. Cuando tu marca aparece en estas respuestas generadas por IA con información incorrecta, tienes poca visibilidad sobre cómo ocurrió el error y poco control para corregirlo rápidamente.
Cómo las Alucinaciones de IA Propagan Desinformación
Las alucinaciones de IA no existen en aislamiento; se propagan a través de sistemas interconectados de maneras que amplifican la desinformación a gran escala. Los vacíos de datos—áreas de internet donde predominan fuentes de baja calidad y escasea la información autorizada—crean condiciones donde los modelos de IA rellenan los vacíos con invenciones plausibles. El sesgo en los datos de entrenamiento implica que si ciertas narrativas fueron sobrerrepresentadas en los datos, el modelo aprende a generar esos patrones incluso si no son correctos. Los actores maliciosos explotan esta vulnerabilidad mediante ataques adversariales, creando contenido diseñado para manipular las salidas de la IA a su favor. Cuando bots informativos que alucinan difunden falsedades sobre tu marca, competidores o industria, estas afirmaciones pueden socavar tus esfuerzos de mitigación: cuando logras corregir la información, la IA ya ha entrenado y propagado la desinformación. El sesgo de entrada crea patrones alucinados cuando la interpretación de la consulta por el modelo lo lleva a generar respuestas que coinciden con sus expectativas sesgadas en lugar de la realidad factual. Este mecanismo significa que la desinformación se propaga más rápido a través de sistemas de IA que por canales tradicionales, llegando a millones de usuarios simultáneamente con las mismas afirmaciones falsas.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Monitoreo de Respuestas de IA para la Seguridad de Marca
El monitoreo en tiempo real en plataformas de IA es esencial para detectar alucinaciones antes de que dañen la reputación de tu marca. Un monitoreo efectivo requiere seguimiento multiplataforma que cubra Google AI Overviews, ChatGPT, Perplexity, Gemini y motores de búsqueda de IA emergentes al mismo tiempo. El análisis de sentimiento sobre cómo se retrata tu marca en las respuestas de IA provee señales tempranas de amenazas reputacionales. Las estrategias de detección deben enfocarse no solo en identificar alucinaciones sino también atribuciones erróneas, información desactualizada y eliminación de contexto que cambie el significado. Las siguientes mejores prácticas establecen un marco de monitoreo integral:
Seguimiento de consultas prioritarias en todas las plataformas (nombre de marca, productos, nombres de ejecutivos, temas críticos de seguridad)
Establecimiento de bases de sentimiento y umbrales de alerta para desviaciones significativas
Correlación de cambios en respuestas de IA con actualizaciones de tu contenido y eventos de noticias externas
Definir objetivos de MTTD (Tiempo Medio de Detección) para problemas críticos de marca—apunta a menos de 2 horas
Configuración de alertas en Slack/Teams con niveles de severidad y rutas de escalamiento
Sin monitoreo sistemático, básicamente estás a ciegas—las alucinaciones sobre tu marca pueden estar propagándose durante semanas antes de que las descubras. El costo de una detección tardía se multiplica a medida que más usuarios encuentran información falsa.
Estrategias para Fortalecer el Contenido
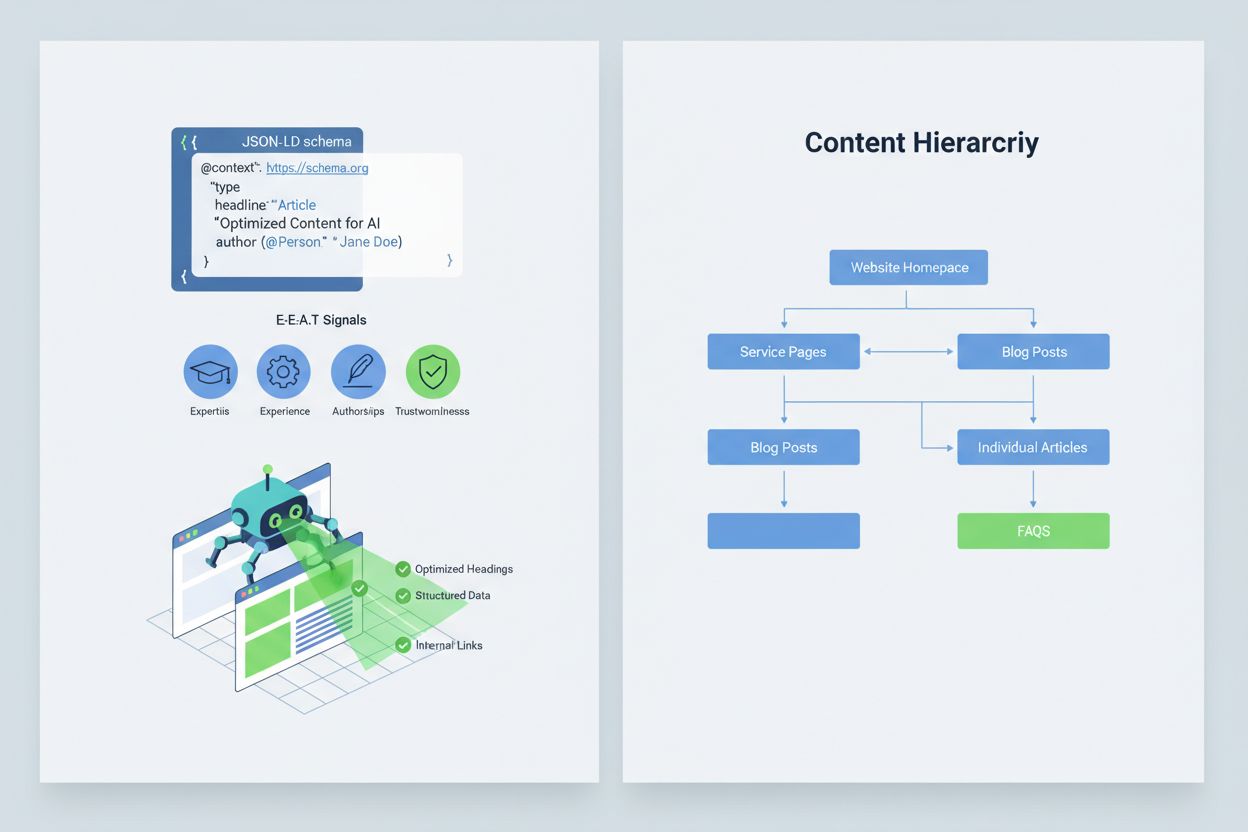
Optimizar tu contenido para que los sistemas de IA lo interpreten y citen correctamente requiere implementar señales E-E-A-T (Experiencia, Pericia, Autoría, Fiabilidad) que hagan tu información más autorizada y digna de ser citada. E-E-A-T incluye autoría experta con credenciales claras, fuentes transparentes con enlaces a investigaciones primarias, fechas de actualización que muestren vigencia del contenido y estándares editoriales explícitos que demuestren control de calidad. Implementar datos estructurados mediante esquemas JSON-LD ayuda a los sistemas de IA a comprender el contexto y credibilidad de tu contenido. Ciertos tipos de esquema son especialmente valiosos: el esquema Organization establece la legitimidad de tu entidad, Product brinda especificaciones detalladas que reducen el riesgo de alucinaciones, FAQPage aborda preguntas comunes con respuestas autorizadas, HowTo guía paso a paso para consultas procedimentales, Review muestra validación de terceros y Article señala credibilidad periodística. La implementación práctica incluye agregar bloques de preguntas y respuestas que aborden directamente intenciones de alto riesgo donde suelen ocurrir alucinaciones, crear páginas canónicas que consoliden información y reduzcan confusión, y desarrollar contenido digno de ser citado que los sistemas de IA quieran referenciar de forma natural. Cuando tu contenido es estructurado, autorizado y claramente referenciado, es más probable que los sistemas de IA lo citen con precisión y menos probable que alucinen alternativas.
Respuesta a Incidentes y Remediación Rápida
Cuando ocurre un problema crítico de seguridad de marca—una alucinación que tergiversa tu producto, atribuye falsamente una declaración a tu ejecutivo o proporciona información peligrosa—la velocidad es tu ventaja competitiva. Una guía de respuesta a incidentes de 90 minutos puede contener el daño antes de que se propague ampliamente. Paso 1: Confirmar y delimitar el alcance (10 minutos) implica verificar la existencia de la alucinación, documentar capturas de pantalla, identificar en qué plataformas ocurre y evaluar la gravedad. Paso 2: Estabilizar tus canales propios (20 minutos) significa publicar de inmediato aclaraciones autorizadas en tu sitio web, redes sociales y prensa para corregir la información ante los usuarios que busquen datos relacionados. Paso 3: Presentar feedback a las plataformas (20 minutos) requiere enviar reportes detallados a cada plataforma afectada—Google, OpenAI, Perplexity, etc.—con evidencia de la alucinación y correcciones solicitadas. Paso 4: Escalamiento externo si es necesario (15 minutos) implica contactar equipos de relaciones públicas de la plataforma o asesoría legal si la alucinación causa daño material. Paso 5: Seguimiento y verificación de la resolución (25 minutos) es monitorear si las plataformas han corregido la respuesta y documentar el proceso. Es fundamental: ninguna de las principales plataformas de IA publica SLAs (acuerdos de nivel de servicio) para correcciones, por lo que la documentación es esencial para la rendición de cuentas. La rapidez y exhaustividad en este proceso puede reducir el daño reputacional entre un 70-80% comparado con respuestas tardías.
Herramientas y Soluciones para Monitoreo de Seguridad de Marca
Plataformas especializadas emergentes ya ofrecen monitoreo dedicado para respuestas generadas por IA, transformando la seguridad de marca de la revisión manual a la inteligencia automatizada. AmICited.com destaca como la solución líder para monitorear respuestas de IA en todas las plataformas principales: rastrea cómo aparecen tu marca, productos y ejecutivos en Google AI Overviews, ChatGPT, Perplexity y otros motores de búsqueda de IA con alertas en tiempo real e historial. Profound monitorea menciones de marca en buscadores de IA con análisis de sentimiento que distingue entre retratos positivos, neutros y negativos, ayudándote a entender no solo qué se dice sino cómo se enmarca. Bluefish AI se especializa en el seguimiento de tu aparición en Gemini, Perplexity y ChatGPT, brindando visibilidad sobre qué plataformas presentan mayor riesgo. Athena ofrece un modelo de búsqueda por IA con métricas de panel que te ayudan a comprender tu visibilidad y desempeño en respuestas generadas por IA. Geneo da visibilidad multiplataforma con análisis de sentimiento e historial que revela tendencias en el tiempo. Estas herramientas detectan respuestas dañinas antes de que se propaguen, sugieren optimizaciones de contenido basadas en lo que funciona en respuestas de IA y permiten la gestión de múltiples marcas para empresas que monitorean decenas de marcas simultáneamente. El retorno de inversión es sustancial: la detección temprana de una alucinación puede evitar que miles de usuarios encuentren información falsa sobre tu marca.
Controlando el Acceso de Rastreadores de IA
Gestionar qué sistemas de IA pueden acceder y entrenar con tu contenido ofrece otra capa de control para la seguridad de marca. GPTBot de OpenAI respeta las directivas de robots.txt, permitiéndote bloquearle el acceso a contenido sensible mientras mantienes presencia en los datos de entrenamiento de ChatGPT. PerplexityBot también respeta robots.txt, aunque persisten preocupaciones sobre rastreadores no declarados que podrían no identificarse correctamente. Google y Google-Extended siguen las reglas estándar de robots.txt, dándote control granular sobre qué contenido alimenta los sistemas de IA de Google. El dilema es real: bloquear rastreadores reduce tu presencia en respuestas generadas por IA, lo que puede costar visibilidad, pero protege contenido sensible de ser malinterpretado o alucinado. Cloudflare AI Crawl Control ofrece opciones más sofisticadas para un control granular, permitiéndote autorizar secciones valiosas de tu sitio mientras proteges contenido frecuentemente malinterpretado. Una estrategia equilibrada suele permitir el acceso a páginas principales de productos y contenido autorizado, bloqueando documentación interna, datos de clientes o contenido propenso a malas interpretaciones. Este enfoque mantiene tu visibilidad en respuestas de IA y reduce la superficie de exposición a alucinaciones que puedan dañar tu marca.
Medición del Éxito y ROI
Establecer KPIs claros para tu programa de seguridad de marca lo transforma de un centro de costos a una función empresarial medible. Métricas MTTD/MTTR (Tiempo Medio de Detección y Resolución) para respuestas dañinas, segmentadas por nivel de gravedad, muestran si tus procesos de monitoreo y respuesta están mejorando. La exactitud y distribución de sentimiento en respuestas de IA revela si tu marca se retrata positiva, neutral o negativamente en las plataformas. La proporción de citas autorizadas mide qué porcentaje de respuestas de IA cita tu contenido oficial frente a competidores o fuentes no confiables—porcentajes más altos indican éxito en el fortalecimiento del contenido. La cuota de visibilidad en AI Overviews y resultados de Perplexity rastrea si tu marca mantiene presencia en estas interfaces de alto tráfico. La efectividad del escalamiento mide el porcentaje de problemas críticos resueltos dentro de tu SLA objetivo, demostrando madurez operativa. Las investigaciones muestran que los programas de seguridad de marca con controles proactivos y monitoreo temprano reducen violaciones a tasas de un solo dígito, frente a tasas del 20-30% para enfoques reactivos. La prevalencia de AI Overviews ha aumentado significativamente hasta 2025, haciendo esencial contar con estrategias de inclusión proactiva—las marcas que optimizan para respuestas de IA ahora obtienen ventaja competitiva sobre quienes esperan a que la tecnología madure. El principio fundamental es claro: la prevención supera a la reacción, y el ROI del monitoreo proactivo de seguridad de marca se multiplica con el tiempo a medida que construyes autoridad, reduces alucinaciones y mantienes la confianza del cliente.
Preguntas frecuentes
Una alucinación de IA ocurre cuando un Modelo de Lenguaje Extenso genera información completamente inventada pero que suena plausible, con total confianza. Estas salidas falsas suceden porque los LLMs predicen secuencias de palabras estadísticamente probables basadas en patrones de los datos de entrenamiento, en vez de realmente comprender hechos. Las alucinaciones resultan de sobreajuste, sesgo en los datos de entrenamiento y la complejidad inherente de las redes neuronales que hace opaco su proceso de toma de decisiones.
Las alucinaciones de IA pueden dañar gravemente tu marca a través de múltiples canales: provocan pérdida de tráfico (el 60% de las búsquedas no generan clics cuando aparecen resúmenes de IA), erosionan la confianza del cliente cuando se le atribuyen afirmaciones falsas a tu marca, crean crisis de relaciones públicas cuando competidores explotan las alucinaciones y reducen tu visibilidad en respuestas generadas por IA. Empresas han reportado hasta un 10% de pérdida de tráfico cuando los sistemas de IA tergiversan sus productos o servicios.
Google AI Overviews, ChatGPT, Perplexity y Gemini son las principales plataformas donde ocurren riesgos de seguridad de marca. Google AI Overviews aparece en la parte superior de los resultados de búsqueda sin citas detalladas. ChatGPT y Perplexity pueden alucinar hechos y atribuir información incorrectamente. Cada plataforma tiene diferentes prácticas de citación y tiempos de corrección, por lo que se requieren estrategias de monitoreo multiplataforma.
El monitoreo en tiempo real en plataformas de IA es esencial. Haz seguimiento de consultas prioritarias (nombre de marca, nombres de productos, nombres de ejecutivos, temas de seguridad), establece bases de sentimiento y umbrales de alerta, y correlaciona cambios con actualizaciones de tu contenido. Herramientas especializadas como AmICited.com ofrecen detección automatizada en todas las principales plataformas de IA con historial y análisis de sentimiento.
Sigue una guía de respuesta a incidentes de 90 minutos: 1) Confirma y delimita el problema (10 min), 2) Publica aclaraciones autorizadas en tu sitio web (20 min), 3) Presenta feedback a la plataforma con evidencia (20 min), 4) Escala externamente si es necesario (15 min), 5) Da seguimiento a la resolución (25 min). La rapidez es clave: una respuesta temprana puede reducir el daño reputacional entre un 70-80% en comparación con respuestas tardías.
Implementa señales E-E-A-T (Experiencia, Pericia, Autoría, Fiabilidad) con credenciales de expertos, fuentes transparentes, fechas de actualización y estándares editoriales. Usa datos estructurados JSON-LD con esquemas Organization, Product, FAQPage, HowTo, Review y Article. Agrega bloques de preguntas y respuestas dirigidos a intenciones de alto riesgo, crea páginas canónicas que consoliden información y desarrolla contenido digno de ser citado por sistemas de IA de forma natural.
Bloquear rastreadores reduce tu presencia en respuestas generadas por IA, pero protege contenido sensible. Una estrategia equilibrada permite el acceso a páginas principales de productos y contenido autorizado, bloqueando documentación interna y contenido frecuentemente malinterpretado. GPTBot de OpenAI y PerplexityBot respetan directivas de robots.txt, dándote control granular sobre qué contenido se alimenta a los sistemas de IA.
Monitorea MTTD/MTTR (Tiempo Medio de Detección/Resolución) para respuestas dañinas según severidad, exactitud de sentimiento en respuestas de IA, proporción de citas autorizadas frente a competidores, participación de visibilidad en AI Overviews y resultados de Perplexity, y efectividad de escalamiento (porcentaje resuelto dentro del SLA). Estas métricas demuestran si tus procesos de monitoreo y respuesta están mejorando y justifican la inversión en seguridad de marca.
Monitorea tu Marca en Resultados de Búsqueda de IA
Protege la reputación de tu marca con monitoreo en tiempo real en Google AI Overviews, ChatGPT y Perplexity. Detecta alucinaciones antes de que dañen tu reputación.
¿Qué es la Alucinación de la IA?: Definición, Causas e Impacto en la Búsqueda con IA
Descubre qué es la alucinación de la IA, por qué ocurre en ChatGPT, Claude y Perplexity, y cómo detectar información falsa generada por IA en los resultados de ...
La alucinación de IA ocurre cuando los LLMs generan información falsa o engañosa con confianza. Descubra qué causa las alucinaciones, su impacto en la monitoriz...
Aprende qué es el monitoreo de alucinaciones de IA, por qué es esencial para la seguridad de la marca y cómo los métodos de detección como RAG, SelfCheckGPT y L...
9 min de lectura
Consentimiento de Cookies Usamos cookies para mejorar tu experiencia de navegación y analizar nuestro tráfico. See our privacy policy.