AIのための引用最適化:AI生成回答であなたのコンテンツが引用される方法
AIにおける引用最適化とは何か、ChatGPT、Perplexity、Google Gemini、その他のAI検索エンジンであなたのコンテンツが引用されるための最適化方法を学びましょう。...
1 分で読める
AIシステムが積極的に引用したくなるオリジナルデータやリサーチの作成方法を学びましょう。ChatGPT、Perplexity、Google Gemini、Claudeでデータを発見されやすくし、持続可能なAIでの可視性を構築する戦略を紹介します。
人工知能の時代、オリジナルデータはブランドの新たな競争優位となっています。ChatGPT、Perplexity、Google Gemini、ClaudeといったAIプラットフォームが情報発見の主役になる中、可視性のルールは根本的に変化しました。Google検索でのゼロポジションを争うのではなく、今やAIシステムが積極的に引用・参照したくなるデータを作ることが求められています。これは、コンテンツSEOから「生成エンジン最適化(GEO)」への大きな転換であり、AIによる引用が従来のランキングに代わる主要な可視性指標となったことを意味します。情報を直接的な回答へと統合するプラットフォームは—リトリーバル拡張生成(RAG)やモデルネイティブ生成を問わず—明確で抽出可能、かつ権威あるオリジナルリサーチを提供するソースを優遇します。この変化を理解し、オリジナルデータや独自リサーチ、ユニークな洞察の作成に投資する組織は、複数のAIプラットフォームで同時に引用を獲得し、従来の検索結果を見ないオーディエンスにも認知と信頼を勝ち取ることができます。

AIプラットフォームごとに、情報発見と引用の仕組みは根本的に異なります。これを理解することが、AI時代におけるコンテンツ可視化の最適化には不可欠です。モデルネイティブ生成(AIがトレーニングデータからパターンを見出して回答を生成)と、リトリーバル拡張生成(AIがライブソースを検索し、取得結果から統合)という違いが、明示的な引用をするプラットフォームと、出典を明かさず回答するプラットフォームの違いを生みます。RAGシステムを用いるプラットフォームは、回答を特定ソースにトレースできるため、引用が明確で追跡可能です。一方、モデルネイティブシステムはトレーニング時の確率的知識に依存するため、追加のプラグインや連携なしでは出典の明示が難しいか不可能です。
| AIプラットフォーム | 引用方法 | データソースの優先度 | 可視性への影響 |
|---|---|---|---|
| ChatGPT | モデルネイティブ(デフォルト)、プラグインやブラウジング有効時はリンク引用 | トレーニングデータ+有効時はライブウェブ。リトリーバル時は新しく権威ある情報を優先 | プラグインなしでは低い。検索有効時は中程度。引用が回答文内に表示される場合あり |
| Perplexity | リトリーバル優先。インラインで番号付き引用 | ライブウェブ検索結果。新鮮かつ直接関連するソースを優先。ソースの目立ち度を重視 | 高い。明確な番号付き引用とソースリンク。1番目のソースが圧倒的にトラフィックを獲得 |
| Google Gemini | Google検索・ナレッジグラフと統合 | インデックス済みページ+ナレッジグラフのエンティティ。構造化データやE-E-A-Tシグナル重視 | 高い。AI Overviewsにソースリンクとして引用。構造化データで引用確率が向上 |
| Claude | モデルネイティブ(デフォルト)、2025年にウェブ検索機能展開予定 | トレーニングデータ+限定的なライブウェブ検索。安全性・権威性の高いソースを優先 | 中程度。ウェブ検索有効時に引用表示。正確性とソース信頼性を重視 |
この違いは実務で大きな意味を持ちます。PerplexityやGoogle Geminiのようにライブウェブを積極的に検索するプラットフォームは、品質と関連性の基準を満たしていれば公開直後からコンテンツを引用可能です。ChatGPTやClaudeはトレーニングデータ依存が強いため、オリジナルリサーチの取り込みには時間がかかる場合もありますが、プラグインや連携を通じて別の可視性機会を提供します。どのプラットフォームをターゲットにするかによって、Perplexityのライブ検索向けには抽出性と構造化を意識し、モデルネイティブ向けには権威性構築を重視するなど、最適化戦略も変わります。
構造化データは、SEOの副次的テクニックからAI可視化の戦略的必須要素へと進化しました。 Schema.orgの語彙でスキーママークアップを実装すると、Googleだけでなく、AIシステムが信頼して根拠とできる機械可読レイヤーを築くことができます。この構造化データ層、いわゆる「コンテンツナレッジグラフ」は、エンティティ(人物・製品・サービス・場所・組織)とその関係性を明示的に定義し、AIがブランドやサービス内容、本質的価値を正確に理解しやすくします。BrightEdgeの最新調査によると、スキーママークアップが充実したページはGoogleのAI Overviewsで引用率が高く、構造化データが引用確率に直結することが示されています。また、**Model Context Protocol(MCP)**のような新しい標準(OpenAIやGoogle DeepMindが採用)は、AIモデルと構造化データソースをAPI的に接続する進化形です。スキーママークアップを全社的に実装することで、AIの幻覚(誤回答)を減らし、事実に基づく回答の信頼性を高め、リトリーバルシステムからの発見性も向上します。特に、非構造テキストのみでAIが学習すると精度に課題が出やすいため、構造化データが文脈の明確さをもたらし、LLMが自信を持ってオリジナルリサーチを引用できるようになります。

AIによる引用獲得で最も有効な戦略は、抽出しやすく権威性があり、AIの情報検索・統合プロセスに適合したオリジナルデータの作成です。既存コンテンツが引用されるのを待つのではなく、AIプラットフォームが発見・理解・参照しやすいデータプロダクトを意図的に設計しましょう。引用されやすいオリジナルデータを作るための主なポイントは以下の通りです。
透明性ある手法でオリジナルリサーチを行う:AIは、リサーチ手法が明確なソースを優先します。調査・アンケート・分析を実施し、手法・サンプル数・制限事項を明示しましょう。きちんと手法を公開すれば、AIは安心して権威ある情報と認めて引用します。業界ベンチマークや顧客調査、市場調査、独自分析など、競合が再現できない内容が理想です。
構造化フォーマットで抽出しやすくする:表、リスト、比較マトリクス、FAQ型Q&Aなどの形式は、AIにとって抽出しやすい情報です。同じ内容でも文章中に埋もれているより、比較表で整理されている方が引用されやすくなります。見出し・箇条書き・視覚的階層を活用し、主要な洞察がAIに即座に認識されるようにしましょう。
データの新しさ・更新シグナルを明示する:特にライブウェブ検索型AIは最新情報を重視します。公開日や更新日を明記し、定期的に内容をリフレッシュしましょう。常に新しい・メンテナンスされていると示すことで、AIは信頼できるデータと認識します。価格や統計、市場動向など最新性が重要なデータは特に重要です。
著者・ブランドの権威性を示す:AIは引用前にソースの信頼性を評価します。著者の経歴(適切なバイオや専門性)、組織の権威性(被リンク・メディア掲載・業界認知)、ドメイン専門性を明確に示しましょう。カテゴリー内で権威と認識されれば、引用頻度・目立ち度ともに向上します。
エンティティ定義と関係性の明確化:自社・製品・サービス・メンバー・業界概念などの主要エンティティを明示的に定義し、構造化データでそれらの関係性も設定しましょう。AIが「何者か」「業界内での位置付け」を正確に理解できれば、より精度の高い引用が実現します。
適切な出典表示・引用ルールの順守:自分のオリジナルデータが他のソースに基づく場合は、透明性を持って引用しましょう。AIは出典表示を重視し、信頼できる引用元を評価します。出典の連鎖が広がることで、エコシステム全体の信頼と引用確率も高まります。
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
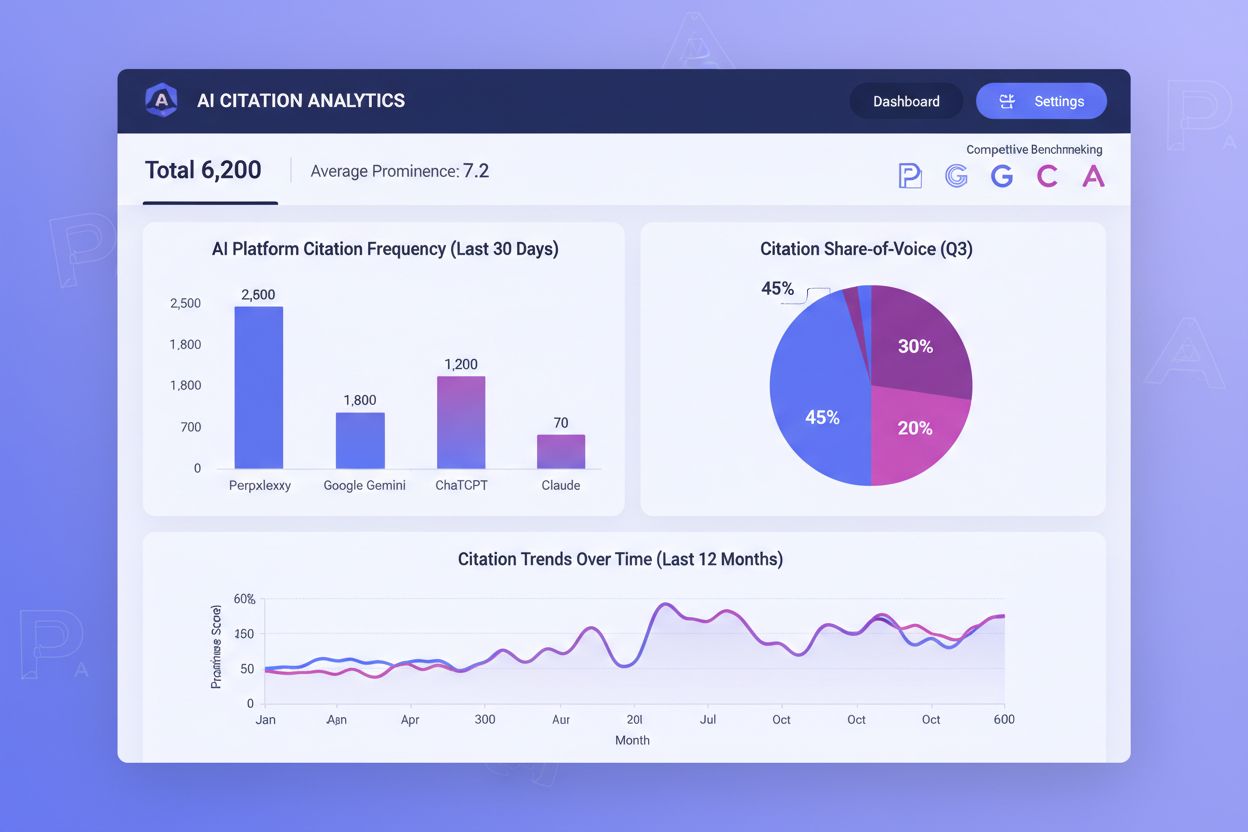
AI引用の追跡は、従来の検索順位監視と同じくらい重要になっていますが、多くの組織はどのくらいAIで引用されているか把握できていません。引用頻度・引用の目立ち度・シェアオブボイスの3つが、AI時代の発見性を左右する主要指標です。引用頻度は、ターゲットクエリでどれくらいAI回答に登場しているかを測ります。例えば、関連プロンプトの40%で引用、自社は60%なら明確な最適化ギャップがあります。引用の目立ち度はさらに重要で、Perplexityの番号付きリストで1番目に表示される引用は5番目よりはるかに強力です。シェアオブボイスは競合との位置関係を示し、カテゴリーを代表するクエリで自社が25%引用、トップ競合が50%なら大きな可視性の損失です。
AmICited.comのようなツールは、各AIプラットフォームでの引用状況を可視化するために不可欠な存在になりつつあります。どのページがPerplexityやGoogle AI Overviews、ChatGPT with searchなどで引用されたかを追跡し、AI経由の可視性を生み出しているコンテンツを特定できます。引用傾向を時系列で分析すれば、どの形式・トピック・フォーマットが最多の引用を生み出しているか明らかになり、成功パターンを再現できます。競合ベンチマークにより、どこで引用を失っているのかも可視化され、的確な最適化が可能です。引用課題が全プラットフォーム共通なのか、特定システムに偏っているかも分かります—Perplexityでは頻繁に引用されるがGoogle AI Overviewsでは稀、という場合は最適化戦略を変えるべきです。位置重み付き指標は、先頭の引用ほど価値が高いことを考慮するため、単なる引用数よりも有益なインサイトをもたらします。AI引用モニタリングをコンテンツ戦略の中核に据えれば、引用頻度と目立ち度の両方を高め続け、AI主導の検索社会でも確実な可視性を獲得できます。
AI引用を獲得するためのオリジナルデータ作成は一度きりの施策ではなく、持続可能で部門横断的なデータ戦略として継続的な投資とガバナンスが必要です。AI可視性で成功する組織は、オリジナルリサーチの鮮度や関連性を保つため、定期的なデータ更新プロセスを確立しています。主要データセットの定期リフレッシュ、新情報登場時の統計更新、AIが信頼性評価に使う新しさシグナルの維持などが欠かせません。さらに、エンティティガバナンス(共通定義・タクソノミーの整備)を通じて、マーケティング・SEO・コンテンツ・プロダクト・データチーム全体をデータ戦略で連携させ、ブランドや製品、業界概念の一貫性・正確性を全タッチポイントで担保します。
最先端の取り組みでは、構造化データやコンテンツナレッジグラフを全社的インフラとして捉えています。ページ単位でのスキーマ実装ではなく、全デジタル資産を横断してエンティティ・トピック・関係性を結ぶ総合的なナレッジグラフを構築します。これには技術的な基盤(スキーマ運用のためのツール・プロセス)と、データ品質基準に関する組織的合意が必要です。正しく設計されたインフラは、外部AI可視性向上と同時に、内部AI利活用も促進します。Gartnerの「2024年AIエンタープライズマンダート」によれば、データの可用性と品質がAI導入最大の障壁です。構造化データとエンティティガバナンスへの投資で、外部可視化と内部AI活用の両課題を同時に解決できます。AI可視性で勝つ組織は、オリジナルデータ作成を単なるマーケティング施策ではなく、専任リソース・明確な責任・継続的な最適化を伴う「ビジネスの基幹能力」として位置付けています。
あなたのオリジナルデータがChatGPT、Perplexity、Google AI Overviews、その他AIプラットフォームでどれだけ引用されているかを追跡しましょう。最大限のAI可視化のため、コンテンツ最適化に役立つ実践的インサイトを取得できます。
AIにおける引用最適化とは何か、ChatGPT、Perplexity、Google Gemini、その他のAI検索エンジンであなたのコンテンツが引用されるための最適化方法を学びましょう。...
AIが生成する回答での引用権威性の仕組み、プラットフォームごとの引用方法、そしてChatGPT、Perplexity、Google AI OverviewsのようなAI検索エンジンでブランドの可視性にどのように影響するかを解説します。...
ChatGPT、Perplexity、Google AI Overviews、ClaudeでのコンテンツAI引用を追跡する方法を学びましょう。ブランドの可視性を監視し、影響力を測定し、AI検索エンジン向けに最適化します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.