
LLMが引用先を選ぶ仕組み:AIの情報ソース選択を理解する
大規模言語モデルが証拠の重み付け、エンティティ認識、構造化データを通じてどのように情報ソースを選択し引用するかをご紹介。AI可視性を最適化するための、7段階の引用判断プロセスを学びましょう。...
1 分で読める

LLMグラウンディングとウェブ検索によってAIシステムがリアルタイム情報へアクセスし、幻覚を減らし、正確な引用を提供できる仕組みを解説します。RAG、実装戦略、エンタープライズでの最適な運用方法を学びましょう。
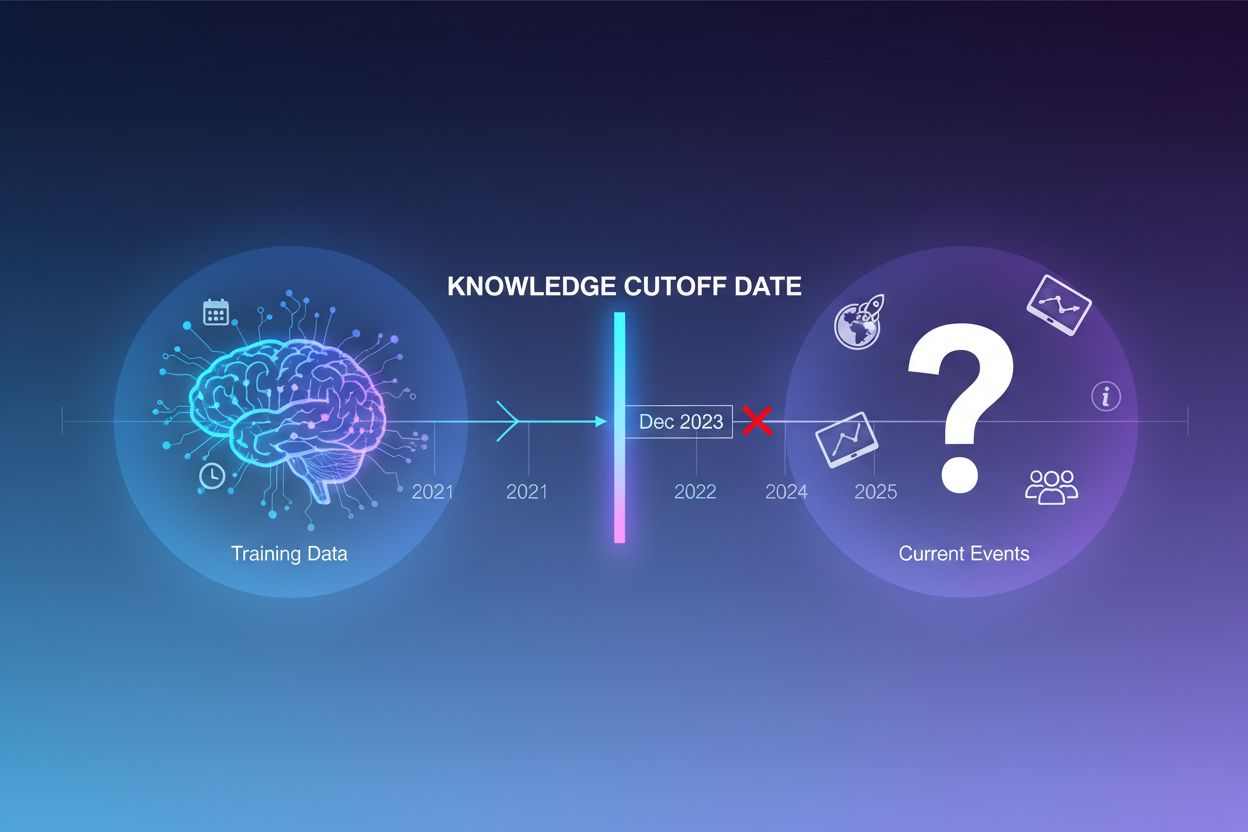
大規模言語モデル(LLM)は膨大なテキストデータで訓練されますが、この訓練プロセスには重大な制約があります。それは、知識カットオフ日と呼ばれる特定時点までの情報しか捉えられないという点です。例えば、あるLLMが2023年12月までのデータで訓練されている場合、それ以降の出来事や発見、進展については全く認識していません。ユーザーが最新のニュースや最近発売された製品、時事問題について質問しても、モデルはその情報を訓練データから取得できません。不確実性を認める代わりに、LLMはもっともらしく聞こえるが事実に反する回答(幻覚と呼ばれます)を生成しがちです。この傾向は、カスタマーサポート、金融アドバイス、医療情報など、正確性が特に重要な用途では深刻な問題となり、古い情報や虚偽情報が重大な影響を及ぼす場合があります。
グラウンディングとは、推論時にLLMの事前学習知識を外部の文脈情報で補強するプロセスです。訓練時に学習したパターンだけに頼るのではなく、グラウンディングによってモデルはウェブページ、社内ドキュメント、データベース、APIなど現実世界のデータソースと接続されます。この考え方は認知心理学、特に状況的認知理論(知識は使用される文脈に根ざしているとする)に由来しています。実務的には、「記憶から答えを生成する」から「提供された情報から答えを合成する」への課題転換となります。最新研究による厳密な定義では、LLMは与えられた文脈からすべての重要知識を利用し、追加情報の幻覚なしにその範囲内で応答することが求められます。
| 項目 | 非グラウンディング応答 | グラウンディング応答 |
|---|---|---|
| 情報源 | 事前学習知識のみ | 事前学習知識+外部データ |
| 最新情報への対応精度 | 低い(知識カットオフ制限) | 高い(最新情報にアクセス) |
| 幻覚リスク | 高い(モデルの推測) | 低い(文脈に制約される) |
| 引用の可否 | 制限的または不可 | 出典まで完全に追跡可能 |
| スケーラビリティ | 固定(モデルサイズ依存) | 柔軟(データソース追加可能) |
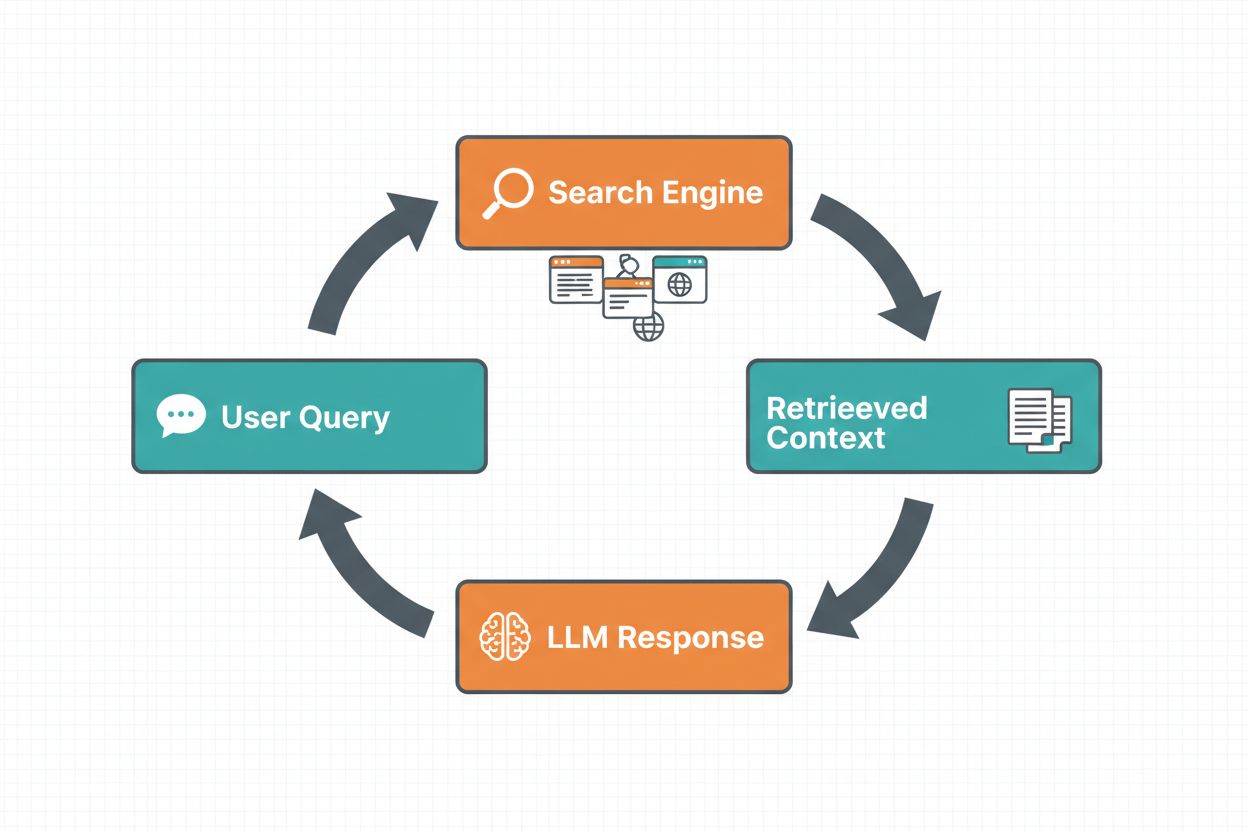
ウェブ検索グラウンディングは、LLMがリアルタイム情報へアクセスするためにウェブ検索を自動実行し、その結果をモデルの応答生成プロセスに組み込む仕組みです。ワークフローは次のような流れになります。まず、システムがユーザープロンプトを分析し、ウェブ検索が回答改善に有効かどうかを判断します。次に、関連情報の取得に最適化された検索クエリを生成します。続いてGoogle検索やDuckDuckGoなどの検索エンジンでこれらのクエリを実行し、得られた検索結果を処理して関連コンテンツを抽出します。最後に、この文脈情報をプロンプトの一部としてLLMに提供し、グラウンディングされた応答を生成させます。システムはまた、グラウンディングメタデータ(実行した検索クエリ、取得したソース、応答中の特定部分がどのソースに基づくかなどの構造化情報)も返します。このメタデータは信頼性構築や検証のために不可欠です。
ウェブ検索グラウンディングのワークフロー:
**Retrieval Augmented Generation(RAG)**は、情報検索の長年の研究と現代のLLM機能を組み合わせた、主流のグラウンディング手法です。RAGは、まず外部ナレッジソース(通常はベクトルデータベースにインデックス化)から関連ドキュメントやパッセージを検索し、それらをLLMの文脈として与えます。検索プロセスは通常2段階で、リトリーバーがBM25や埋め込みによるセマンティック検索などの高速アルゴリズムで候補ドキュメントを特定し、ランカーがより高性能なニューラルモデルで関連度順に再ランキングします。取得した文脈はプロンプトに組み込まれ、LLMは信頼できる情報に基づく回答を合成できます。RAGはファインチューニングよりもコスト効率が高く(モデル再学習不要)、スケーラブル(ナレッジベースに新規文書追加のみ)、保守性も高い(再学習なしで情報更新可能)という利点があります。例えばRAGプロンプトは次のようになります。
以下のドキュメントを使って質問に答えてください。
[Question]
カナダの首都はどこですか?
[Document 1]
オタワはカナダの首都であり、オンタリオ州に位置しています...
[Document 2]
カナダは北アメリカにある10州を持つ国です...
ウェブ検索グラウンディング最大の利点のひとつは、LLM応答にリアルタイム情報を組み込めることです。これは、ニュース分析、市場調査、イベント情報、商品在庫など最新データを必要とするアプリケーションにとって特に有用です。加えて、グラウンディングは引用と出典明示を可能にし、ユーザーの信頼構築や検証にも不可欠です。LLMがグラウンディング応答を生成すると、特定の主張がどのソース文書に基づくかをマッピングする構造化メタデータを返すため、応答文中に「[1] source.com」のようなインライン引用も可能です。この機能はAmICited.comのようなプラットフォームの使命と直結しており、AIが情報源をどう参照・引用しているかを多様なプラットフォームで監視します。AIがどのソースを参照し、どのように情報を帰属させたかを追跡することは、ブランド監視やコンテンツ帰属、責任あるAI運用のために今後さらに重要性が増しています。
幻覚は、LLMが元来、過去のトークンや学習パターンに基づいて次のトークンを予測するよう設計されているため、知識の限界を自覚できないことから発生します。訓練データ外の質問にも、不確実性を認めず、もっともらしい文を生成し続けてしまいます。グラウンディングはこのタスク自体を根本から変え、「記憶から生成」ではなく「与えられた情報から合成」するよう促します。技術的には、関連する外部文脈がプロンプトに含まれることで、トークン確率分布がその文脈に基づく答え側にシフトし、幻覚の発生可能性が低下します。研究によれば、グラウンディングによりタスクや実装内容によって幻覚率が30〜50%削減されます。例えば「ユーロ2024の優勝国は?」という質問に対し、グラウンディングなしの古いモデルは誤答することがありますが、ウェブ検索結果を用いたグラウンディングによりスペインが優勝したことや試合の詳細まで正確に返答できます。これは、モデルのアテンション機構が訓練データの不完全・矛盾したパターンではなく、提供された文脈に集中できるようになるためです。
ウェブ検索グラウンディングを実装するには、検索API(Google Search、Serp API経由のDuckDuckGoやBing Searchなど)、グラウンディングの必要性を判断するロジック、検索結果を効果的に組み込むプロンプトエンジニアリングなど複数のコンポーネント統合が必要です。実装の第一歩は、ユーザーの問いが最新情報を必要とするかどうかの判定で、これはLLM自身に「このプロンプトは知識カットオフ以降の情報が必要か?」と尋ねても実現できます。必要と判断された場合、ウェブ検索を実行し、関連スニペットを抽出、元の質問と検索文脈を含めたプロンプトを構成します。コスト面にも注意が必要で、各ウェブ検索にはAPIコストが発生するため、動的グラウンディング(必要時のみ検索)を導入すれば大きな経費削減になります。例えば「なぜ空は青いの?」といった定番質問は検索不要ですが、「現在の大統領は誰?」のような問いは必ず検索が必要です。高度な実装では、小型高速モデルでグラウンディング判定を行い、最終回答生成のみ大型モデルを使うことで、遅延とコストを最小化できます。
グラウンディングは強力ですが、慎重な対応が必要な課題も複数あります。データの関連性が最重要で、取得した情報がユーザー質問と無関係なら、グラウンディングは役立たず、むしろ無関係な文脈を導入してしまいます。データ量には逆説があり、多ければよいというものではなく、入力が過剰だとLLMの性能が低下する現象(「lost in the middle」バイアス)が知られています。これは長い文脈の中間情報をモデルが見落としがちになるものです。トークン効率も重要で、取得した文脈ごとにトークン消費が増え、遅延とコストが増します。「少ない方が良い」という原則で、最も関連度の高い上位3〜5件だけを取得し、長文ではなく短いチャンクや主要文だけを抜き出すのが有効です。
| 課題 | 影響 | 解決策 |
|---|---|---|
| データ関連性 | 無関係な文脈がモデルを混乱させる | セマンティック検索+ランカー活用、取得精度の検証 |
| lost in the middleバイアス | 重要情報の見落とし | 入力サイズ縮小、重要情報の先頭/末尾配置 |
| トークン効率 | 遅延・コスト増加 | 取得件数の絞り込み、小チャンク利用 |
| 情報の陳腐化 | ナレッジベースの古い情報 | 更新ポリシーやバージョン管理の導入 |
| 遅延 | 検索+推論による応答遅延 | 非同期処理、よくある問い合わせのキャッシュ化 |
グラウンディングシステムを本番環境にデプロイする際は、ガバナンス・セキュリティ・運用面に十分な配慮が必要です。データ品質保証は基盤であり、グラウンディングの情報が正確・最新でユースケースに適合している必要があります。アクセス制御は、機密性の高いドキュメントをグラウンディングする際に不可欠で、LLMがユーザー権限に応じた情報のみアクセスできるようにする必要があります。更新・ドリフト管理では、ナレッジベースの更新頻度や複数ソース間の情報矛盾をどう扱うかポリシー策定が求められます。監査ログもコンプライアンスやデバッグ対応に必須で、どの文書が取得され、どうランク付けされ、どの文脈がモデルに渡されたかを記録すべきです。その他の考慮点:
LLMグラウンディング分野は、単純なテキスト検索を超えて急速に進化しています。マルチモーダルグラウンディング(テキストだけでなく画像・動画・構造化データも文脈に含める)が登場し、法的文書解析、医療画像、技術文書分野で特に重要になってきています。自動推論のレイヤーもRAGに統合され、単なる情報取得だけでなく複数ソースの合成、論理的結論の導出や理由説明まで可能に。ガードレール(安全性・ポリシー遵守のための制約)もグラウンディングと統合され、外部情報へのアクセスがあってもモデルの安全性が維持されます。さらにインプレース・モデル更新(外部検索に頼らずモデル重み自体を新情報で更新する方法)も研究されており、大規模な外部ナレッジベース依存の低減が期待されています。これらの進歩により、今後のグラウンディングシステムはより賢く、効率的で、複雑な多段推論タスクも事実性と追跡性を維持しながらこなせるようになるでしょう。
グラウンディングは、モデル自体を変更せずに推論時に外部情報でLLMを拡張します。一方、ファインチューニングは新しいデータでモデルを再学習させます。グラウンディングはコスト効率が高く、実装が早く、新しい情報での更新も簡単です。ファインチューニングは、モデルの挙動を根本的に変えたい場合や、ドメイン固有のパターンを学習する必要がある場合に適しています。
グラウンディングは、LLMがトレーニングデータだけでなく、事実に基づく情報源を参照できるようにすることで幻覚を減らします。関連する外部情報がプロンプトに含まれていると、モデルのトークン確率分布がその文脈に基づいた答えにシフトし、作り話の情報が出る可能性が低くなります。研究によれば、グラウンディングによって幻覚率は30〜50%減少します。
Retrieval Augmented Generation(RAG)は、外部ナレッジソースから関連ドキュメントを取得し、それをLLMに文脈として与えるグラウンディング技術です。RAGはスケーラブルでコスト効率が高く、モデルを再学習せずに情報を更新できるため重要です。グラウンディングAIアプリケーション構築の業界標準となっています。
アプリケーションが最新情報(ニュース、イベント、最近のデータ)へのアクセスを必要とするとき、正確性や引用が重要な場合、LLMの知識カットオフが制約となる場合にウェブ検索グラウンディングを導入しましょう。動的グラウンディングを使って必要なときだけ検索を行えば、不要な検索コストと遅延を減らせます。
主な課題は、データの関連性(取得情報が本当に質問に答えているか)、データ量(多ければ良いわけではない)、長い文脈の中間情報をモデルが見逃す「lost in the middle」バイアス、トークン効率の最適化です。解決策は、セマンティック検索とランカーの併用、少数でも高品質な情報取得、重要情報を文脈の冒頭や末尾に配置することなどです。
グラウンディングはAI回答監視に直結しています。正しく実装されたグラウンディングによって、AIは引用や出典明示が可能になります。AmICitedのようなプラットフォームは、AIが情報源をどう参照しているかを追跡でき、責任あるAI運用やブランド帰属の担保につながります。
「lost in the middle」バイアスとは、長い文脈の中間に重要情報があるとLLMのパフォーマンスが低下し、冒頭や末尾にある場合より見落としやすくなる現象です。モデルが大量テキストを「流し読み」する傾向があるため起こります。解決策は入力サイズの最小化、重要情報の配置、短いテキストチャンクの活用などです。
本番運用では、データ品質保証、機密情報へのアクセス制御、更新・リフレッシュポリシーの策定、コンプライアンス向け監査ログの有効化、失敗検知のためのユーザーフィードバックループを重視しましょう。コスト最適化にはトークン使用量の監視、ナレッジベースのバージョン管理、モデル挙動のドリフト検知も有効です。
AmICitedは、GPTやPerplexity、Google AI Overviewsがあなたのコンテンツをどのように引用・参照しているかを追跡します。AIの回答監視やブランド帰属に関するリアルタイムインサイトを得ましょう。
大規模言語モデルが証拠の重み付け、エンティティ認識、構造化データを通じてどのように情報ソースを選択し引用するかをご紹介。AI可視性を最適化するための、7段階の引用判断プロセスを学びましょう。...

独自の調査データとオリジナル統計がどのようにLLMから引用を集める磁石になるのかを解説します。AIの可視性を高め、ChatGPT、Perplexity、Google AI Overviewなどからより多く引用されるための戦略を学びましょう。...

大規模言語モデル(LLM)の包括的定義:数十億のパラメータを持つAIシステムが言語を理解・生成します。LLMの仕組み、AIモニタリングや企業導入トレンドについて解説。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.