Content Grounding
Leer wat content grounding is, hoe het AI-hallucinaties voorkomt en waarom het essentieel is voor betrouwbare AI-systemen. Ontdek technieken, tools en best prac...
8 min lezen

Ontdek hoe LLM grounding en webzoekopdrachten AI-systemen in staat stellen realtime informatie te benutten, hallucinaties te verminderen en nauwkeurige bronvermeldingen te bieden. Leer RAG, implementatiestrategieën en best practices voor bedrijven.
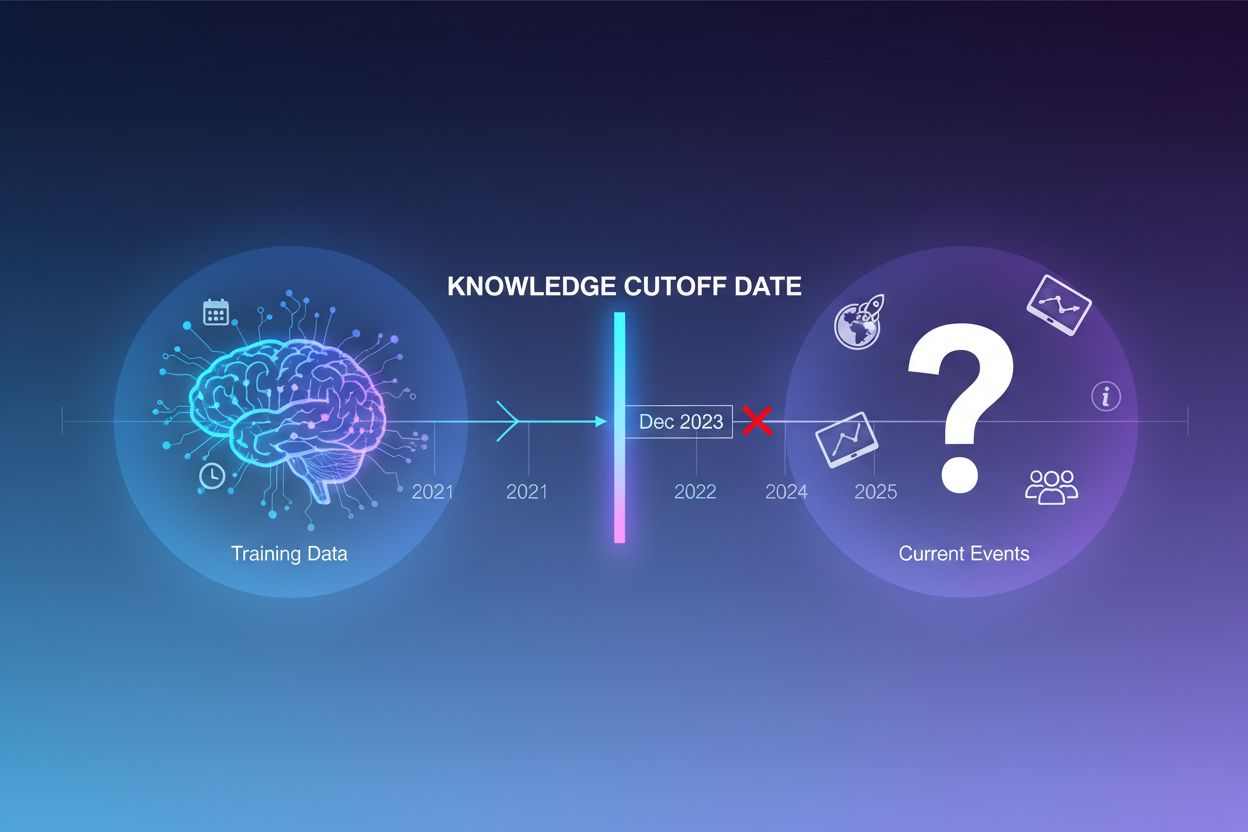
Grote taalmodellen worden getraind op enorme hoeveelheden tekstdata, maar dit trainingsproces kent een belangrijke beperking: het legt alleen informatie vast tot een bepaald moment, bekend als de knowledge cutoff datum. Als een LLM bijvoorbeeld is getraind op data tot december 2023, heeft het geen kennis van gebeurtenissen, ontdekkingen of ontwikkelingen die daarna plaatsvonden. Wanneer gebruikers vragen stellen over actuele gebeurtenissen, recente productlanceringen of het laatste nieuws, kan het model deze informatie niet uit zijn trainingsdata halen. In plaats van onzekerheid toe te geven, genereren LLM’s vaak geloofwaardig klinkende maar feitelijk onjuiste antwoorden—een fenomeen dat bekendstaat als hallucinatie. Deze neiging wordt vooral problematisch in toepassingen waar nauwkeurigheid cruciaal is, zoals klantenservice, financieel advies of medische informatie, waar verouderde of verzonnen informatie ernstige gevolgen kan hebben.
Grounding is het proces waarbij de vooraf getrainde kennis van een LLM wordt aangevuld met externe, contextuele informatie tijdens het infereren. In plaats van alleen te vertrouwen op patronen uit de training, verbindt grounding het model met echte gegevensbronnen—zoals webpagina’s, interne documenten, databases of API’s. Dit idee is ontleend aan de cognitieve psychologie, met name de theorie van situated cognition, die stelt dat kennis het meest effectief wordt toegepast wanneer deze is gegrond in de context waarin ze wordt gebruikt. Praktisch gezien verandert grounding het probleem van “genereer een antwoord uit het geheugen” naar “syntheseer een antwoord op basis van aangeleverde informatie”. Een strikte definitie uit recent onderzoek vereist dat de LLM alle essentiële kennis uit de geboden context gebruikt en zich aan de reikwijdte ervan houdt, zonder extra informatie te hallucineren.
| Aspect | Niet-gegrond antwoord | Gegrond antwoord |
|---|---|---|
| Informatiebron | Alleen vooraf getrainde kennis | Vooraf getrainde kennis + externe data |
| Nauwkeurigheid bij recente gebeurtenissen | Laag (knowledge cutoff beperkingen) | Hoog (toegang tot actuele informatie) |
| Hallucinatie-risico | Hoog (model gokt) | Laag (beperkt tot geboden context) |
| Mogelijkheid tot bronvermelding | Beperkt of onmogelijk | Volledig traceerbaar naar bronnen |
| Schaalbaarheid | Vast (modelgrootte) | Flexibel (nieuwe databronnen mogelijk) |
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
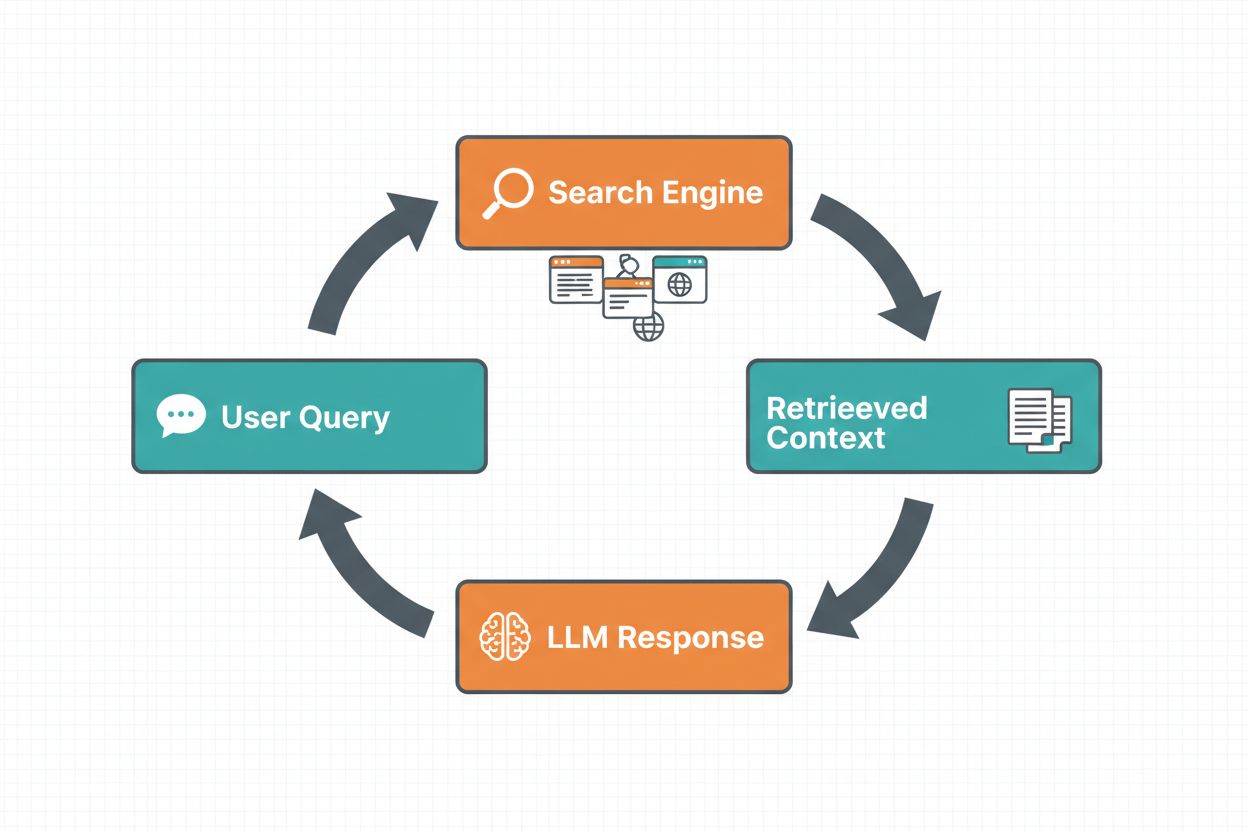
Webzoekopdracht grounding stelt LLM’s in staat om realtime informatie op te halen door automatisch het web te doorzoeken en de resultaten op te nemen in het antwoordgeneratieproces van het model. De workflow volgt een gestructureerde volgorde: eerst analyseert het systeem de prompt van de gebruiker om te bepalen of een webzoekopdracht het antwoord verbetert; vervolgens genereert het geoptimaliseerde zoekopdrachten voor relevante informatie; daarna voert het deze zoekopdrachten uit op een zoekmachine (zoals Google Search of DuckDuckGo); vervolgens verwerkt het de zoekresultaten en extraheert relevante content; tot slot biedt het deze context aan de LLM als onderdeel van de prompt, zodat het model een gegrond antwoord kan genereren. Het systeem retourneert ook grounding metadata—gestructureerde gegevens over welke zoekopdrachten zijn uitgevoerd, welke bronnen zijn opgehaald en hoe specifieke delen van het antwoord door deze bronnen worden ondersteund. Deze metadata is essentieel voor vertrouwen en stelt gebruikers in staat beweringen te verifiëren.
Webzoekopdracht Grounding Workflow:
Retrieval Augmented Generation (RAG) is uitgegroeid tot de dominante groundingtechniek, waarbij decennia van informatieopslag-onderzoek worden gecombineerd met moderne LLM-capaciteiten. RAG werkt door eerst relevante documenten of passages uit een externe kennisbron op te halen (meestal geïndexeerd in een vector database), en deze opgehaalde items als context aan de LLM te leveren. Het ophalen gebeurt doorgaans in twee stappen: een retriever gebruikt efficiënte algoritmen (zoals BM25 of semantisch zoeken met embeddings) om kandidaat-documenten te vinden, en een ranker gebruikt geavanceerdere neurale modellen om deze kandidaten op relevantie te rangschikken. De opgehaalde context wordt vervolgens in de prompt opgenomen, zodat de LLM antwoorden kan syntheseeren op basis van gezaghebbende informatie. RAG biedt aanzienlijke voordelen ten opzichte van fine-tuning: het is kostenefficiënter (geen hertraining nodig), schaalbaarder (voeg gewoon nieuwe documenten toe aan de kennisbank) en beter te onderhouden (informatie updaten zonder retraining). Een voorbeeld van een RAG-prompt:
Gebruik de volgende documenten om de vraag te beantwoorden.
[Vraag]
Wat is de hoofdstad van Canada?
[Document 1]
Ottawa is de hoofdstad van Canada, gelegen in Ontario...
[Document 2]
Canada is een land in Noord-Amerika met tien provincies...
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Een van de grootste voordelen van webzoekopdracht grounding is de mogelijkheid om realtime informatie in LLM-antwoorden op te nemen. Dit is vooral waardevol voor toepassingen die actuele data vereisen—zoals nieuwsanalyses, marktonderzoek, evenementen- of productinformatie. Naast toegang tot verse informatie biedt grounding bronvermeldingen en attributie, wat essentieel is voor gebruikersvertrouwen en verificatie. Wanneer een LLM een gegrond antwoord genereert, levert het gestructureerde metadata die specifieke beweringen koppelt aan hun brondocumenten, waardoor inline-verwijzingen als “[1] source.com” direct in de tekst mogelijk zijn. Deze mogelijkheid sluit aan bij de missie van platforms als AmICited.com, dat monitort hoe AI-systemen bronnen vermelden en citeren op verschillende platforms. Het kunnen volgen welke bronnen een AI-systeem heeft geraadpleegd en hoe het informatie heeft toegeschreven wordt steeds belangrijker voor merkmonitoring, contentattributie en verantwoord AI-gebruik.
Hallucinaties ontstaan omdat LLM’s in essentie zijn ontworpen om het volgende token te voorspellen op basis van voorgaande tokens en geleerde patronen, zonder te begrijpen waar hun kennis ophoudt. Bij vragen buiten hun trainingsdata blijven ze plausibel klinkende tekst genereren in plaats van onzekerheid te tonen. Grounding pakt dit fundamenteel aan: in plaats van te genereren uit het geheugen, syntheseert het model nu uit aangeleverde informatie. Vanuit technisch perspectief verschuift, als relevante externe context wordt toegevoegd aan de prompt, de tokenverdeling naar antwoorden die in die context zijn gegrond, waardoor hallucinaties minder waarschijnlijk worden. Onderzoek toont aan dat grounding hallucinatiepercentages met 30-50% kan verlagen, afhankelijk van taak en implementatie. Zo kan een ouder model op de vraag “Wie won het EK 2024?” zonder grounding een fout antwoord geven; met grounding via webzoekresultaten noemt het correct Spanje als winnaar met specifieke wedstrijddetails. Dit mechanisme werkt doordat de aandachtmechanismen van het model zich nu kunnen richten op de aangeleverde context in plaats van op mogelijk onvolledige of conflicterende patronen uit de training.
Het implementeren van webzoekopdracht grounding vereist de integratie van verschillende componenten: een zoek-API (zoals Google Search, DuckDuckGo via Serp API, of Bing Search), logica om te bepalen wanneer grounding nodig is, en prompt engineering om zoekresultaten effectief te verwerken. Een praktische implementatie begint meestal met het inschatten of de gebruikersvraag actuele informatie vereist—dit kan worden gedaan door de LLM zelf te laten bepalen of de prompt informatie vraagt die nieuwer is dan zijn knowledge cutoff. Als grounding nodig is, voert het systeem een webzoekopdracht uit, verwerkt de resultaten om relevante fragmenten te extraheren, en bouwt een prompt die zowel de oorspronkelijke vraag als de zoekcontext bevat. Kosten zijn belangrijk: elke webzoekopdracht brengt API-kosten met zich mee, dus dynamische grounding (alleen zoeken wanneer nodig) kan de kosten aanzienlijk verlagen. Een vraag als “Waarom is de lucht blauw?” heeft waarschijnlijk geen webzoekopdracht nodig, terwijl “Wie is de huidige president?” dat wel heeft. Geavanceerde implementaties gebruiken kleinere, snellere modellen om de groundingbeslissing te nemen, zodat de vertraging en kosten dalen en grotere modellen alleen voor het uiteindelijke antwoord worden gebruikt.
Hoewel grounding krachtig is, brengt het verschillende uitdagingen met zich mee die zorgvuldig moeten worden beheerd. Relevantie van data is cruciaal—als de opgehaalde informatie het antwoord niet daadwerkelijk ondersteunt, helpt grounding niet en kan het zelfs irrelevante context toevoegen. Hoeveelheid data vormt een paradox: hoewel meer informatie gunstig lijkt, laat onderzoek zien dat LLM-prestaties vaak verslechteren bij te veel input, een fenomeen genaamd de “lost in the middle”-bias waarbij modellen moeite hebben informatie te vinden en te gebruiken die midden in lange contexten staat. Token-efficiëntie wordt belangrijk, want elk stukje opgehaalde context kost tokens, wat vertraging en kosten verhoogt. Het principe “less is more” geldt: haal alleen de top-k meest relevante resultaten op (doorgaans 3-5), werk met kleinere tekstfragmenten in plaats van hele documenten, en overweeg het extraheren van kerntzinnen uit lange passages.
| Uitdaging | Impact | Oplossing |
|---|---|---|
| Datarelevantie | Irrelevante context verwart model | Gebruik semantisch zoeken + rankers; test retrievalkwaliteit |
| Lost in Middle Bias | Model mist belangrijke info in midden | Minimaliseer inputgrootte; plaats kritieke info aan begin/einde |
| Token-efficiëntie | Hoge vertraging en kosten | Haal minder resultaten op; gebruik kleinere fragmenten |
| Verouderde informatie | Verouderde context in kennisbank | Implementeer verversingsbeleid; versiebeheer |
| Vertraging | Trage antwoorden door zoeken + inferentie | Gebruik asynchrone processen; cache veelvoorkomende vragen |
Het inzetten van grounding-systemen in productieomgevingen vereist aandacht voor governance, beveiliging en operationele aspecten. Kwaliteitscontrole van data is fundamenteel—de informatie waarop je grondt, moet accuraat, actueel en relevant zijn voor je usecases. Toegangsbeheer wordt essentieel bij grounding op propriëtaire of gevoelige documenten; het model mag alleen informatie tonen die past bij de rechten van een gebruiker. Update- en driftbeheer betekent beleid opstellen voor hoe vaak kennisbanken worden vernieuwd en hoe je omgaat met conflicterende informatie tussen bronnen. Auditlogging is onmisbaar voor compliance en debuggen—je moet vastleggen welke documenten zijn opgehaald, hoe ze zijn gerangschikt en welke context aan het model is geleverd. Andere aandachtspunten zijn:
Het veld van LLM grounding ontwikkelt zich snel verder dan alleen tekstuele retrieval. Multimodale grounding komt op, waarbij systemen hun antwoorden kunnen gronden in afbeeldingen, video’s en gestructureerde data naast tekst—vooral belangrijk in domeinen als juridische analyse, medische beeldvorming en technische documentatie. Geautomatiseerd redeneren wordt bovenop RAG gebouwd, waardoor agenten niet alleen informatie ophalen maar ook kunnen combineren, logisch concluderen en hun redenatie uitleggen. Guardrails worden geïntegreerd met grounding om te zorgen dat modellen, zelfs met toegang tot externe informatie, aan veiligheidsnormen en beleid blijven voldoen. In-place model updates vormen een frontier: in plaats van volledig te vertrouwen op externe retrieval, verkennen onderzoekers hoe modelgewichten direct met nieuwe informatie kunnen worden geüpdatet, wat de noodzaak voor uitgebreide externe kennisbanken mogelijk vermindert. Deze ontwikkelingen suggereren dat toekomstige groundingsystemen intelligenter, efficiënter en beter in staat zullen zijn tot complexe, meerstaps redenering, met behoud van feitelijke nauwkeurigheid en traceerbaarheid.
AmICited volgt hoe GPT's, Perplexity en Google AI Overviews jouw content citeren en vermelden. Krijg realtime inzichten in het monitoren van AI-antwoorden en merkvermelding.
Leer wat content grounding is, hoe het AI-hallucinaties voorkomt en waarom het essentieel is voor betrouwbare AI-systemen. Ontdek technieken, tools en best prac...
Ontdek hoe contextuele bracketing AI-hallucinatie voorkomt door duidelijke informatiegrenzen aan te brengen. Ontdek implementatietechnieken, best practices en t...

Ontdek hoe Retrieval-Augmented Generation AI-verwijzingen transformeert, waardoor nauwkeurige bronvermelding en onderbouwde antwoorden mogelijk zijn in ChatGPT,...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.