
手動AI可視性テストのためのプロンプトライブラリ
手動AI可視性テストのためのプロンプトライブラリの構築と活用方法を学びましょう。ChatGPT、Perplexity、Google AIなどで自社ブランドがAIシステムでどのように参照されるかをテストするDIYガイド。...
1 分で読める

AIエンジンにおいて自社ブランドのプレゼンスをプロンプトテストで検証する方法を学びましょう。ChatGPT、Perplexity、Google AIなど、さまざまなAIでの可視性を監視する手動・自動の手法を紹介します。
プロンプトテストは、AIエンジンに体系的にクエリを送信し、自社コンテンツが回答に現れるかどうかを測定するプロセスです。従来のSEOテストが検索順位やクリック率に重点を置くのに対し、AI可視性テストはChatGPT、Perplexity、Google AI Overviewsなどの生成AIプラットフォーム全体でのプレゼンスを評価します。この違いは非常に重要です。なぜなら、AIエンジンは従来の検索エンジンとは異なるランキングや検索・引用方法を持つからです。AIの回答に自社プレゼンスをテストするには、巨大言語モデルがWeb上の情報をどのように取得・統合し・出典を示すかという、本質的に異なるアプローチが必要です。
手動プロンプトテストは、AI可視性を理解するうえで最も手軽な方法ですが、継続的な記録と運用が求められます。主要AIプラットフォームでのテスト手順は以下の通りです。
| AIエンジン | テスト手順 | メリット | デメリット |
|---|---|---|---|
| ChatGPT | プロンプト入力→回答確認→言及/引用チェック→結果記録 | 直接アクセス可能・詳細な応答・引用追跡可 | 時間がかかる・結果の一貫性が低い・履歴データが限定的 |
| Perplexity | クエリ入力→出典表示分析→引用位置の追跡 | 出典が明確・リアルタイムデータ・操作が簡単 | 手動記録が必要・クエリ数に上限 |
| Google AI Overviews | Googleで検索→AI生成要約確認→出典含有を記録 | 検索と一体化・高トラフィックの可能性・自然なユーザー行動 | クエリバリエーションの制御が困難・表示が安定しない |
| Google AIモード | Google Labs経由でアクセス→特定クエリをテスト→強調スニペットを追跡 | 新興プラットフォーム・直接テスト可能 | 初期段階のため機能制限・利用可能性が限定的 |
ChatGPTテストやPerplexityテストは、最大のユーザー基盤と透明性の高い引用メカニズムのため、ほとんどの手動テスト戦略の基盤となっています。
手動テストは貴重な知見をもたらしますが、規模が大きくなるとすぐに非現実的となります。4つのAIエンジンで50プロンプトをテストするだけでも、200件以上の個別クエリを手作業で記録・スクリーンショット撮影・結果分析する必要があり、1サイクルで10~15時間かかります。手動テストの限界は時間だけではありません。人が手動で記録するため一貫性がなく、トレンド追跡に十分な頻度を保てず、数百のプロンプトのデータを集約してパターンを発見することも困難です。スケーラビリティの課題は、ブランド・ノンブランド・ロングテール・競合比較など多様なバリエーションを同時にテストする場合に特に顕著です。さらに、手動テストでは単なる時点のスナップショットしか得られません。自動化がなければ、週ごとの可視性変化や、どのコンテンツ更新がAIプレゼンス向上に寄与したかを追跡できません。
自動化されたAI可視性ツールは、プロンプト送信・回答取得・結果集約を継続的に自動で実施し、手動作業の負担を解消します。これらのプラットフォームはAPIや自動ワークフローを利用し、定義したスケジュール(毎日・週次・月次など)で数百~数千のプロンプトを各AIエンジンにテストします。自動テストは、言及・引用・アトリビューション精度・センチメントなどの構造化データを主要AIエンジン横断で一度に取得します。リアルタイムモニタリングにより、可視性変化を即座に検知し、コンテンツ更新やアルゴリズム変更と関連付けて戦略的に対応できます。これらのプラットフォームのデータ集約機能により、手動テストでは見えないパターン――どのトピックが最も引用されるか・AIが好むコンテンツ形式・競合とのシェア・オブ・ボイス・引用時の適切なリンク付与――まで可視化されます。この体系的アプローチによって、AI可視性の管理は単なる監査から、コンテンツ戦略や競争力強化のための継続的インテリジェンスへと進化します。
成果を出すプロンプトテストのベストプラクティスには、慎重なプロンプト選定とバランスの取れたテストポートフォリオが不可欠です。次のポイントを考慮しましょう。
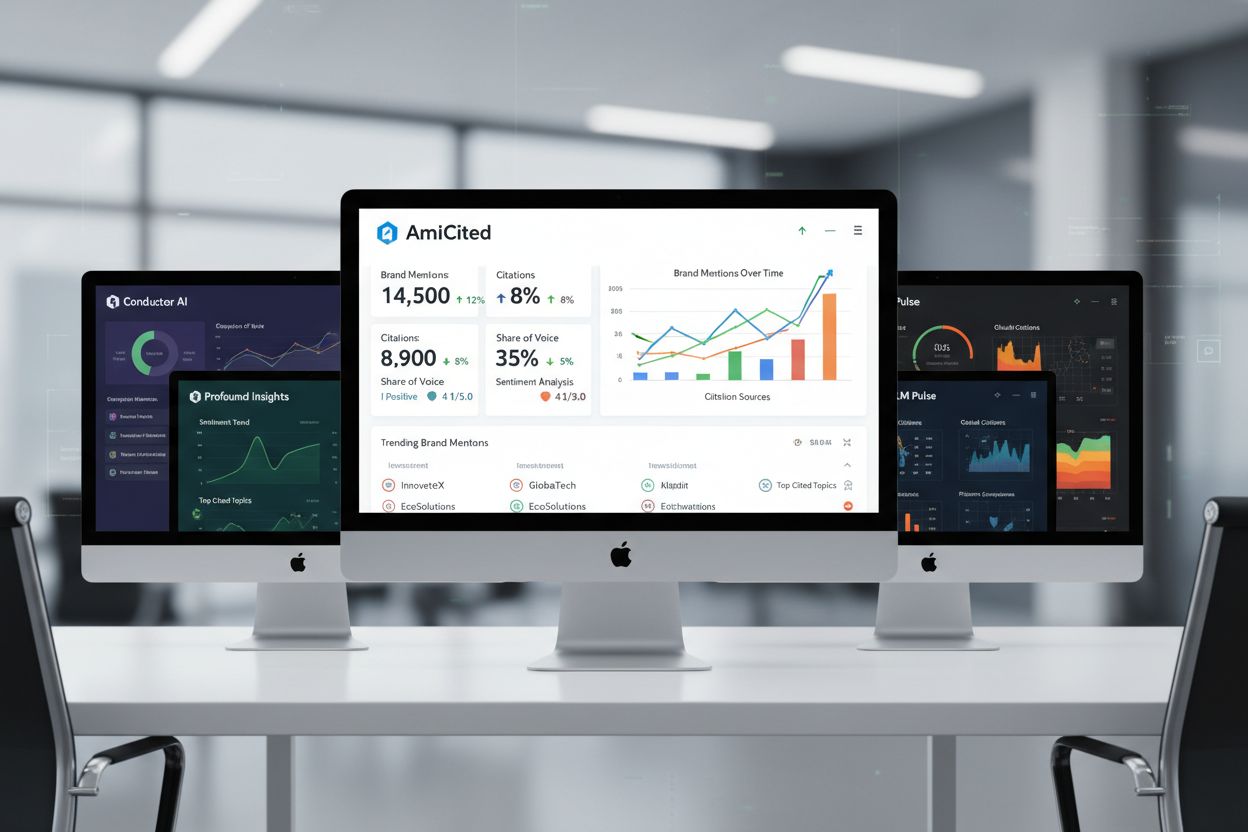
AI可視性指標は、生成AIプラットフォーム横断でのプレゼンスを多角的に把握します。引用追跡は、単に登場するか否かにとどまらず、主要出典なのか・複数出典の1つか・一言だけの言及かなど、目立ち度も明らかにします。シェア・オブ・ボイスは、同一トピック領域での競合と比べた引用頻度から、競争ポジションやコンテンツ権威性を示します。Profoundのようなプラットフォームが牽引するセンチメント分析は、引用が肯定的・中立的・否定的のどれで登場するかを評価し、単なる言及数では分からない重要な文脈を提供します。アトリビューション精度も同様に重要です。AIがきちんとリンク付きで出典表記しているか、それとも出典なしの要約に終始しているかを見極めます。これらの指標の解釈には文脈理解が不可欠です。例えば、低トラフィックのクエリ10件での登場より、高トラフィックの1件での登場の方が価値が高い場合もあります。競合同士のベンチマークも不可欠です。もし自社が関連プロンプトの40%で登場し、競合が60%なら、埋めるべき可視性ギャップが特定できます。
AI可視性プラットフォームには、それぞれ強みの異なる特化型ツールが存在します。AmICitedはChatGPT・Perplexity・Google AI Overviewsでの引用追跡・詳細なアトリビューション分析・競合ベンチマークに強みがあります。Conductorはプロンプト単位の追跡やトピック権威マッピングに特化し、どのトピックでAI可視性が得られるかの理解を深めます。Profoundはセンチメント分析と出典精度が得意で、AIが自社コンテンツをどう提示するかを把握するのに役立ちます。LLM Pulseは手動テストのガイドや新興プラットフォームのカバーに強みがあり、ゼロからテスト体制を作るチームに価値があります。選択は目的次第です。自動化・競合分析重視ならAmICited、トピック権威重視ならConductor、AIがどう自社を描写するかの理解重視ならProfoundのセンチメント機能が有効です。多くの高度なチームは複数プラットフォームを併用し、相互補完的な知見を得ています。
多くの組織が防げるミスでテスト効果を損なっています。ブランドプロンプトへの依存が強すぎると「自社名検索では強いが、実は発見型トピックでは全く表示されていない」など、誤った可視性認識を招きます。不定期なテストはデータの信頼性を損ね、継続的な変化と通常の変動を区別できません。センチメント分析を無視すると、AIが自社内容を否定的に扱ったり、競合を好意的に扱った場合に結果を誤解してしまいます。ページ単位のデータを見落とすと、どのページが表示され、どう引用されているかが分からず、的確なコンテンツ改善につながりません。現行コンテンツだけをテストするのも見落としがちです。過去のページもテストすれば、古いページが今もAIに引用されるか、新しい情報に置き換えられたかを確認できます。最後に、テスト結果とコンテンツ変更を関連付けないと、何がAI可視性向上に効いたのか学べず、継続的最適化ができません。
プロンプトテストの結果は、コンテンツ戦略やAI最適化の優先順位に直結させましょう。テストで「競合が多く登場し、自社はほぼ表示されていない高トラフィック領域」が判明した場合、そのトピックは新規作成や既存ページの最適化が最優先となります。テスト結果からAIが好むコンテンツ形式も判明します。たとえば、競合のリスト記事が多く表示され、自社の長文ガイドが表示されない場合は、形式の最適化が効果的です。トピック権威性は、複数プロンプトで一貫して登場することで可視化され、逆に出現頻度が低ければコンテンツギャップやポジションの弱さが示唆されます。新規領域を攻める前に、まずテストで現状の可視性や競争状況を把握し、実現可能性を見極めましょう。引用はされてもリンクが付かない場合は、独自データ・オリジナル調査・独特な見解を強化し、AIが出典表記したくなるコンテンツを目指します。最後に、テストをコンテンツカレンダーに組み込み、大型コンテンツ公開の前後で可視性を計測し、仮説ではなく実際のAI可視性データに基づいて戦略を調整しましょう。
手動テストはAIエンジンに個別にプロンプトを入力し、結果を手作業で記録する方法です。時間がかかり、大規模には難しいです。自動テストはプラットフォームを使い、複数AIエンジンに数百のプロンプトを定期的に送り、構造化データを収集し、ダッシュボードで結果を集約して傾向分析や競合ベンチマークを行います。
意味のある傾向を追跡し、可視性の変化をコンテンツ更新やアルゴリズム変更と関連付けるため、最低でも週1回または隔週の定期的なテストを設定しましょう。重要度が高いトピックや競合性が高い分野では毎日テストが有効ですが、安定した成熟領域では月1回程度でも十分です。
75/25ルールを推奨します:およそ75%をノンブランド(業界トピックや課題、情報検索)、25%をブランド(自社名、商品名、ブランドキーワード)にします。これにより、発見型とブランド指向の両方の可視性を測れ、既に強い分野だけに偏ることを防げます。
初回サイクルからすぐにシグナルは見え始めますが、意味のあるパターンは通常4〜6週間の継続的な追跡後に表れます。これによりベースラインを作り、AIの自然な変動を考慮しつつ、可視性の変化と具体的なコンテンツ更新や最適化施策を関連付けられます。
はい。ChatGPT、Perplexity、Google AI Overviews、Google AIモードに直接アクセスすれば手動テストは無料で行えます。ただし無料の手動テストは規模や継続性に限界があります。AmICitedなどの自動化プラットフォームは無料トライアルやフリーミアムもあり、有料プラン導入前に試すことが可能です。
最も重要なのは引用(AIがあなたのコンテンツにリンクする場合)、言及(ブランド名が登場する場合)、シェア・オブ・ボイス(競合と比べた可視性)、そしてセンチメント(引用が肯定的かどうか)です。AIが正しく出典を表記するか(アトリビューション精度)も、真の可視性を理解する上で不可欠です。
有効なプロンプトは、ビジネス目標と相関する、一貫性のある行動可能なデータを生み出します。検索クエリデータや顧客インタビュー、営業会話と照らし合わせ、実際のユーザー行動を反映しているかを確認しましょう。コンテンツ更新後に可視性変化が見られるプロンプトは、テスト戦略の検証に特に有効です。
まずは主要なエンジン(ChatGPT、Perplexity、Google AI Overviews)から始めましょう。これらはユーザー数やトラフィックのポテンシャルが最大です。プログラムが成熟したら、GeminiやClaudeなど、オーディエンスに関連する新興エンジンにも拡大を検討しましょう。最終的には、顧客が実際に利用しているエンジンや、最もサイト流入に貢献しているものが基準となります。
AmICitedの包括的なAI可視性監視で、ChatGPT、Perplexity、Google AI Overviewsなど、さまざまなAIで自社ブランドのプレゼンスをテストしましょう。
手動AI可視性テストのためのプロンプトライブラリの構築と活用方法を学びましょう。ChatGPT、Perplexity、Google AIなどで自社ブランドがAIシステムでどのように参照されるかをテストするDIYガイド。...

AI可視性のための効果的なプロンプトリサーチの方法を学びましょう。LLMにおけるユーザーのクエリ理解や、ChatGPT、Perplexity、Google AI Overviewsでのブランド追跡の手法を解説します。...

ChatGPT、Perplexity、Google AI Overviewsでのブランド言及を監視できる、ベストな無料AI可視性テストツールを紹介。機能を比較し、今日から始めましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.