Manuell AI-synlighetstestning: Gör-det-själv-metodik
Lär dig hur du manuellt testar ditt varumärkes synlighet i AI-sökmotorer som ChatGPT, Perplexity och Google AI Overviews. Steg-för-steg-guide för att testa AI-s...
7 min läsning

Lär dig hur du testar ditt varumärkes närvaro i AI-motorer med prompttestning. Upptäck manuella och automatiserade metoder för att övervaka AI-synlighet över ChatGPT, Perplexity och Google AI.
Prompttestning är processen att systematiskt skicka in frågor till AI-motorer för att mäta om ditt innehåll förekommer i deras svar. Till skillnad från traditionell SEO-testning, som fokuserar på sökrankning och klickfrekvens, utvärderar AI-synlighetstestning din närvaro över generativa AI-plattformar som ChatGPT, Perplexity och Google AI Overviews. Denna distinktion är avgörande eftersom AI-motorer använder andra rankningsmekanismer, hämtningstekniker och citeringsmönster än traditionella sökmotorer. Att testa din närvaro i AI-svar kräver ett fundamentalt annorlunda tillvägagångssätt—ett som tar hänsyn till hur stora språkmodeller hämtar, syntetiserar och tillskriver information från hela webben.
Manuell prompttestning förblir den mest tillgängliga ingången för att förstå din AI-synlighet, även om det kräver disciplin och dokumentation. Så här fungerar testning över de största AI-plattformarna:
| AI-motor | Testningssteg | Fördelar | Nackdelar |
|---|---|---|---|
| ChatGPT | Skicka in prompter, granska svar, notera omnämnanden/citeringar, dokumentera resultat | Direkt tillgång, detaljerade svar, citeringsspårning | Tidskrävande, inkonsekventa resultat, begränsad historik |
| Perplexity | Ange frågor, analysera källtilldelning, spåra citeringsplacering | Tydlig källtilldelning, realtidsdata, användarvänlig | Manuell dokumentation krävs, begränsad frågekapacitet |
| Google AI Overviews | Sökfrågor i Google, granska AI-genererade sammanfattningar, notera källinkludering | Integrerat med sök, hög trafikpotential, naturligt användarbeteende | Begränsad kontroll över frågevariationer, inkonsekvent förekomst |
| Google AI Mode | Tillgång via Google Labs, testa specifika frågor, spåra utvalda utdrag | Ny plattform, direkt testtillgång | Tidig plattform, begränsad tillgänglighet |
ChatGPT-testning och Perplexity-testning utgör grunden för de flesta manuella teststrategier, då dessa plattformar representerar de största användarbaserna och de mest transparenta citeringsmekanismerna.
Även om manuell testning ger värdefulla insikter blir det snabbt ohanterligt i större skala. Att testa bara 50 prompter manuellt över fyra AI-motorer kräver över 200 individuella frågor, var och en med manuell dokumentation, skärmdumpshantering och resultatanalys—en process som tar 10–15 timmar per testcykel. Manuella testningsbegränsningar handlar inte bara om tidsåtgång: mänskliga testare introducerar inkonsekvens i resultatdokumentation, har svårt att upprätthålla testfrekvensen som krävs för trendanalys och kan inte aggregera data över hundratals prompter för att identifiera mönster. Skalbarhetsproblemet blir akut när du behöver testa varumärkesvariationer, icke-varumärkesvariationer, long-tail-frågor och konkurrensjämförelser samtidigt. Dessutom ger manuell testning endast ögonblicksbilder; utan automatiserade system kan du inte följa hur din synlighet förändras vecka för vecka eller identifiera vilka innehållsuppdateringar som faktiskt förbättrat din AI-närvaro.
Automatiserade AI-synlighetsverktyg eliminerar det manuella arbetet genom att kontinuerligt skicka prompter till AI-motorer, fånga upp svar och sammanställa resultaten i dashboards. Dessa plattformar använder API:er och automatiserade arbetsflöden för att testa hundratals eller tusentals prompter enligt dina egna scheman—dagligen, veckovis eller månadsvis—utan mänsklig inblandning. Automatiserad testning fångar strukturerad data rörande omnämnanden, citeringar, attributionsnoggrannhet och sentiment över alla större AI-motorer samtidigt. Realtidsövervakning gör att du kan upptäcka synlighetsförändringar direkt, koppla dem till innehållsuppdateringar eller algoritmförändringar och agera strategiskt. Plattformarnas dataaggregationsförmåga avslöjar mönster som är osynliga för manuell testning: vilka ämnen som genererar flest citeringar, vilka innehållsformat AI-motorer föredrar, hur din share of voice står sig mot konkurrenter och om dina citeringar innehåller korrekt attribution och länkar. Detta systematiska angreppssätt förvandlar AI-synlighet från en tillfällig revision till en kontinuerlig underrättelseström som styr innehållsstrategi och konkurrenspositionering.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Framgångsrik prompttestning enligt bästa praxis kräver genomtänkt promptval och balanserade testportföljer. Tänk på dessa viktiga element:
AI-synlighetsmätvärden ger en mångdimensionell bild av din närvaro över generativa AI-plattformar. Citeringsspårning visar inte bara om du syns, utan också hur framträdande—om du är huvudkälla, en av flera, eller nämns i förbifarten. Share of voice jämför din citeringsfrekvens med konkurrenter inom samma ämnesområde, vilket visar konkurrenspositionering och innehållsauktoritet. Sentimentanalys, pionjärarbete från plattformar som Profound, utvärderar om dina citeringar presenteras positivt, neutralt eller negativt i AI-svar—en avgörande kontext som råa omnämnandemängder missar. Attributionsnoggrannhet är lika viktig: ger AI-motorn korrekt kredit till ditt innehåll med länk, eller parafraserar den utan attribution? Att förstå dessa mätvärden kräver kontextuell analys—ett enda omnämnande i en högtrafikerad fråga kan väga tyngre än tio omnämnanden i lågvolymfrågor. Konkurrensjämförelser ger nödvändig kontext: om du syns i 40% av relevanta prompter men konkurrenter i 60%, har du identifierat en synlighetslucka värd att åtgärda.
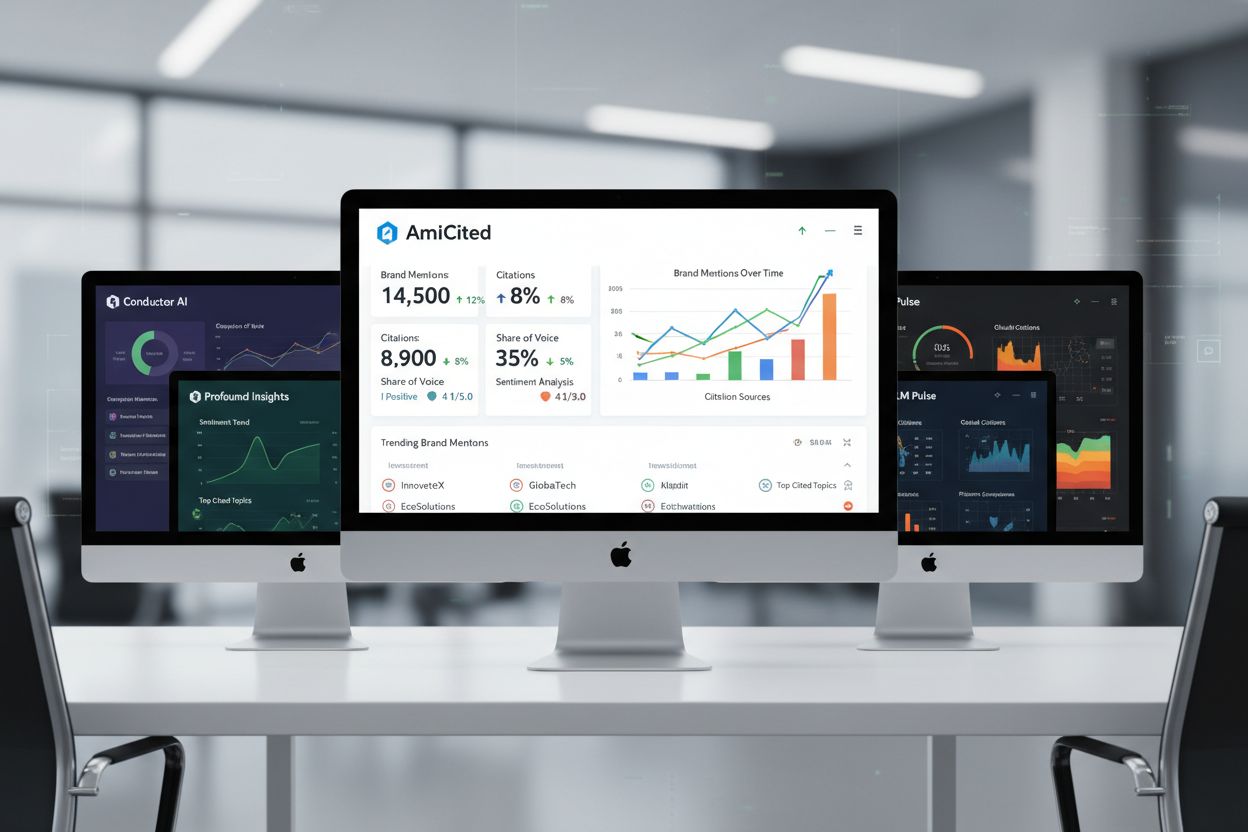
Marknaden för AI-synlighetsplattformar inkluderar flera specialiserade verktyg, alla med sina styrkor. AmICited erbjuder heltäckande citeringsspårning över ChatGPT, Perplexity och Google AI Overviews med detaljerad attributionsanalys och konkurrensjämförelser. Conductor fokuserar på promptnivåspårning och ämnesauktoritetskartering, vilket hjälper team förstå vilka ämnen som genererar mest AI-synlighet. Profound betonar sentimentanalys och källtilldelningsnoggrannhet, avgörande för att förstå hur AI-motorer presenterar ditt innehåll. LLM Pulse erbjuder vägledning för manuell testning och täckning av nya plattformar, värdefullt för team som bygger testprocesser från grunden. Valet beror på dina prioriteringar: om heltäckande automation och konkurrensanalys är viktigast är AmICited bäst; om ämnesauktoritet driver din strategi passar Conductors upplägg bättre; om det är avgörande att förstå hur AI-motorer ramar in ditt innehåll sticker Profounds sentimentfunktionalitet ut. De mest avancerade teamen använder flera plattformar för att få kompletterande insikter.
Organisationer undergräver ofta sina testinsatser genom undvikbara fel. Överdrivet fokus på varumärkespropmter skapar en falsk känsla av synlighet—du kan ranka högt för “Företagsnamn”-sökningar men vara osynlig för de branschämnen som faktiskt driver upptäckt och trafik. Inkonsekventa testningsscheman ger opålitlig data; om du testar sporadiskt går det inte att särskilja verkliga synlighetstrender från normala variationer. Att ignorera sentimentanalys leder till misstolkning av resultat—att synas i ett AI-svar som framställer ditt innehåll negativt eller gynnar konkurrenter kan faktiskt skada din positionering. Att missa sidnivådata förhindrar optimering: att veta att du syns för ett ämne är värdefullt, men att veta vilka specifika sidor som syns och hur de tillskrivs möjliggör riktade innehållsförbättringar. Ett annat kritiskt fel är att bara testa aktuellt innehåll; test av historiskt innehåll visar om äldre sidor fortfarande ger AI-synlighet eller om de ersatts av nyare källor. Slutligen, om du misslyckas med att koppla testresultat till innehållsändringar kan du inte lära dig vilka innehållsuppdateringar som faktiskt förbättrar AI-synligheten, vilket förhindrar kontinuerlig optimering.
Prompttestningsresultat ska direkt informera din innehållsstrategi och dina AI-optimeringsprioriteringar. När testning visar att konkurrenter dominerar ett högvolymämne där du har minimal synlighet blir det ämnet en prioritet för innehållsskapande—antingen via nytt innehåll eller optimering av befintliga sidor. Testresultat identifierar vilka innehållsformat AI-motorer föredrar: om konkurrenters listartiklar förekommer oftare än dina långformsguider, kan formatoptimering förbättra synligheten. Ämnesauktoritet framträder ur testdata—ämnen där du syns konsekvent över flera promptvariationer indikerar etablerad auktoritet, medan ämnen där du syns sporadiskt tyder på innehållsgap eller svag positionering. Använd testning för att validera innehållsstrategi innan du gör stora satsningar: om du planerar att rikta in dig på ett nytt ämnesområde, testa aktuell synlighet först för att förstå konkurrensnivå och realistisk potential. Testning avslöjar också attributionsmönster: om AI-motorer citerar ditt innehåll men utan länkar, bör din innehållsstrategi lyfta fram unik data, originalforskning och särskilda perspektiv som AI-motorer känner sig tvingade att tillskriva. Slutligen, integrera testning i din innehållskalender—schemalägg testcykler kring större innehållslanseringar för att mäta effekt och justera strategi baserat på verkliga AI-synlighetsresultat istället för antaganden.
Testa ditt varumärkes närvaro i ChatGPT, Perplexity, Google AI Overviews och fler med AmICiteds heltäckande AI-synlighetsövervakning.
Lär dig hur du manuellt testar ditt varumärkes synlighet i AI-sökmotorer som ChatGPT, Perplexity och Google AI Overviews. Steg-för-steg-guide för att testa AI-s...

Bemästra prediktiv AI-synlighet för att prognostisera ditt varumärkes framtida närvaro i ChatGPT, Perplexity och Google AI. Lär dig prognosstrategier, nyckelmet...

Upptäck de bästa verktygen för att övervaka AI-synlighet i sök och spåra ditt varumärke på ChatGPT, Perplexity och Google AI Overviews. Jämför funktioner, prise...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.