クエリファンアウト
AI検索システムにおけるクエリファンアウトの仕組みを解説。Google AIモード、ChatGPT、Perplexityなどで、AIが単一のクエリを複数のサブクエリへ拡張し、回答の精度とユーザー意図の理解をどう高めているかを紹介します。...
1 分で読める
Google AI モードや ChatGPT などの最新AIシステムが、単一のクエリをどのように複数の検索へ分解するかを解説。クエリファンアウトの仕組み、AI可視性への影響、コンテンツ戦略の最適化について学びましょう。
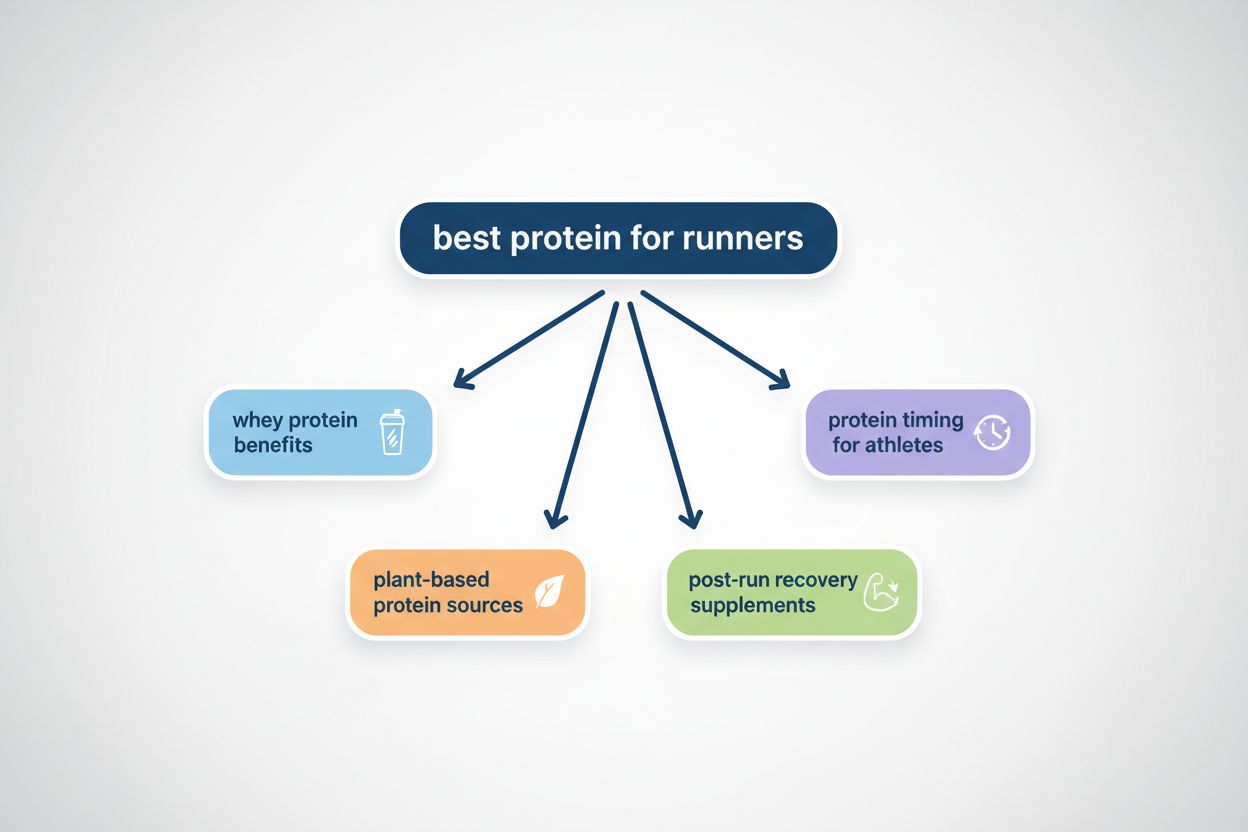
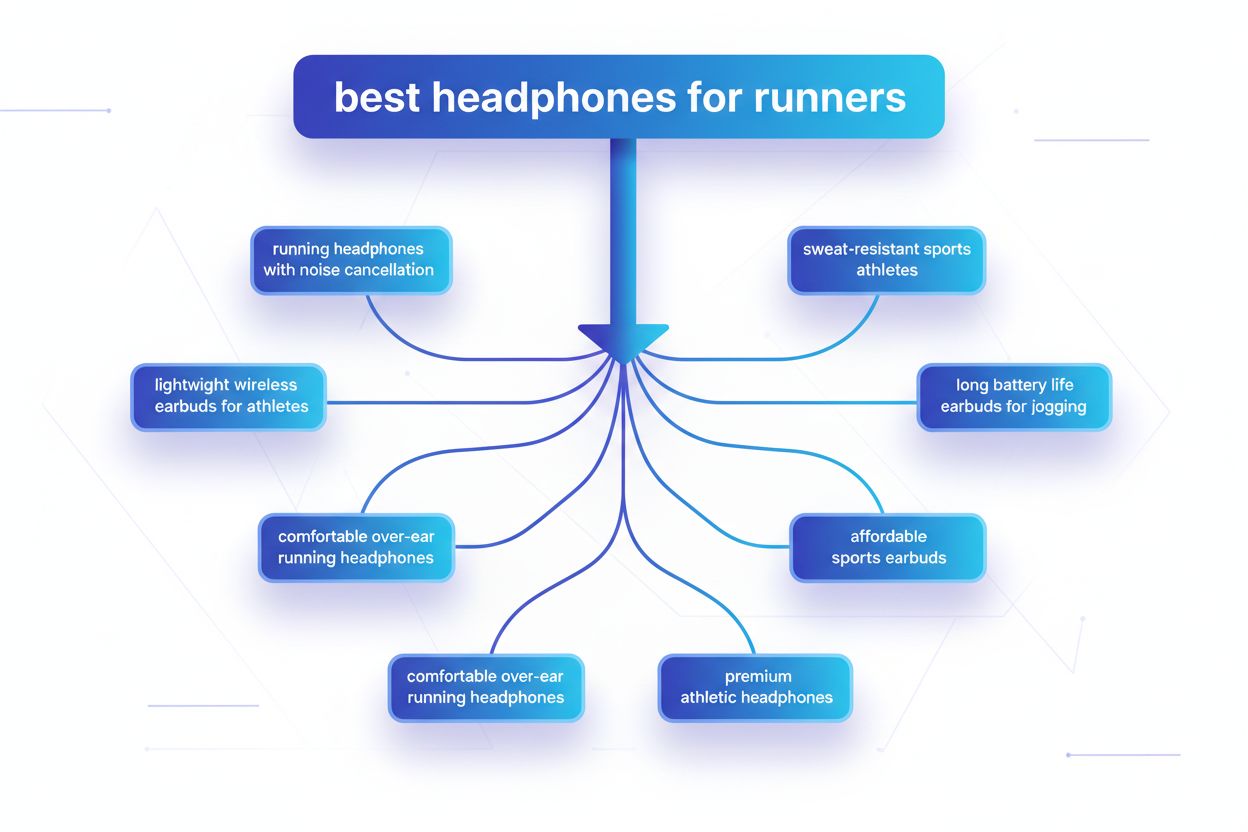
クエリファンアウトとは、大規模言語モデルが単一のユーザークエリを自動的に複数のサブクエリへ分割し、多様な情報源からより包括的な情報を収集するプロセスです。従来の単一検索とは異なり、現代のAIシステムはユーザーの意図を5~15個の関連クエリに分解し、元のリクエストのさまざまな観点や解釈、側面を捉えます。たとえばGoogleのAIモードで「ランナー向けのおすすめヘッドホン」を検索すると、「ノイズキャンセリング付きランニングヘッドホン」「アスリート向け軽量ワイヤレスイヤホン」「防汗スポーツヘッドホン」「ジョギング用長時間バッテリーイヤホン」など、約8種類のバリエーションが自動生成されます。これは、従来の「1つのクエリ文字列をインデックスと照合するだけ」の検索とは本質的に異なります。クエリファンアウトの主な特徴は以下の通りです:
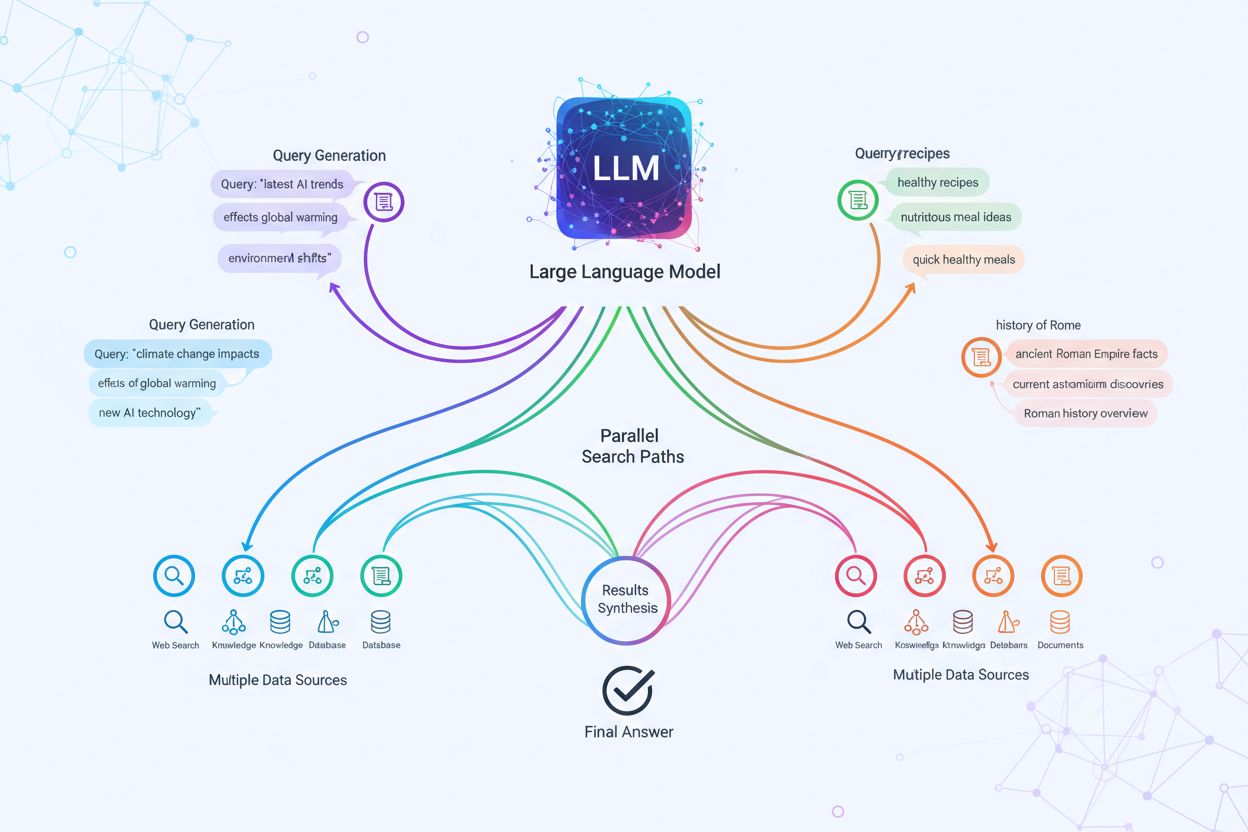
クエリファンアウトの技術実装は、高度なNLPアルゴリズムによるクエリの複雑性分析と、意味的に有効なバリエーション生成に依存しています。LLMは8つの主要なクエリバリアントを生み出します:同値クエリ(言い換え)、フォローアップクエリ(関連トピックの探索)、一般化クエリ(範囲の拡大)、特定化クエリ(焦点の絞り込み)、正規化クエリ(用語の標準化)、翻訳クエリ(ドメイン間変換)、含意クエリ(論理的含意の探索)、明確化クエリ(曖昧語句の解消)です。システムはエンティティ数・関係密度・意味的曖昧さなど複雑性を評価し、生成すべきサブクエリ数を決定します。生成されたクエリは、ウェブクローラー、ナレッジグラフ(Google Knowledge Graph 等)、構造化DB、ベクトル類似検索など複数の検索システムで並列実行されます。プラットフォームごとに透明性・洗練度は異なります:
| プラットフォーム | メカニズム | 透明性 | クエリ数 | ランキング手法 |
|---|---|---|---|---|
| Google AIモード | 明示的ファンアウト(可視クエリ) | 高 | 8~12件 | マルチステージランキング |
| Microsoft Copilot | Bing Orchestratorによる反復型 | 中 | 5~8件 | 関連性スコアリング |
| Perplexity | ハイブリッド検索+マルチステージランキング | 高 | 6~10件 | 引用ベース |
| ChatGPT | 暗黙的クエリ生成 | 低 | 不明 | 内部重み付け |
複雑なクエリは、システムによって要素エンティティ・属性・関係ごとに分割され、バリエーション生成の前処理が行われます。たとえば「ランナー向け快適なオーバーイヤー型Bluetoothヘッドホン 長時間バッテリー」というクエリを処理する際、システムは「Bluetoothヘッドホン」「ランナー」などのエンティティを特定し、「快適」「オーバーイヤー」「長時間バッテリー」といった重要属性を抽出します。分解プロセスではナレッジグラフも活用し、たとえば「オーバーイヤーヘッドホン」と「サーカムオーラルヘッドホン」が同等であることや、「長時間バッテリー」が文脈次第で8時間・24時間・複数日を意味しうることなど、意味的バリエーションも理解します。さらに「防汗」と「防水」が関連しつつ別概念であること、「ランナー」は「サイクリスト」「ジム利用者」「アウトドアアスリート」にも関心がありうることも、意味的類似度から把握。こうした分解により、単なる言い換えではなく意図の異なる側面を網羅したサブクエリ生成が可能になります。
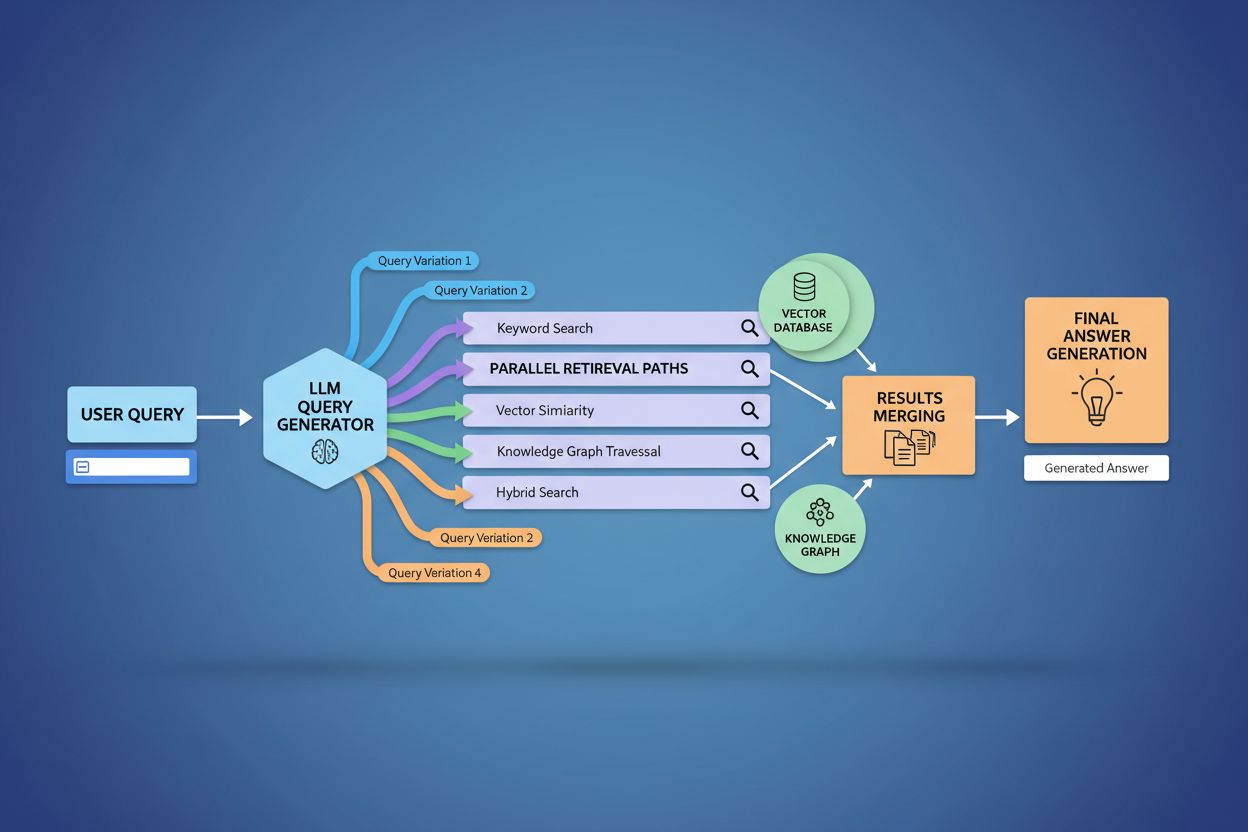
クエリファンアウトは、検索拡張生成(RAG)フレームワークの検索部分を根本的に強化します。従来のRAGパイプラインでは単一クエリをベクトルDBに埋め込み検索しますが、異なる用語や枠組みの情報を見逃すリスクがあります。クエリファンアウトはこの制限を解消し、各バリエーションごとに最適化した検索を並列で行い、さまざまな観点・情報源から証拠を収集します。この並列検索により、複数の独立した情報源に基づきLLMの回答を根拠付けることで「ハルシネーション」リスクを大幅に低減します。たとえば「オーバーイヤーヘッドホン」「サーカムオーラルデザイン」「フルサイズヘッドホン」など個別取得した情報を相互参照・検証可能です。さらに文書を意味単位で分割(セマンティックチャンク)、文書構造に依存しない最適パッセージ抽出も実現。複数サブクエリ検索の証拠を組み合わせることで、より網羅的かつ信頼性の高い回答生成を可能にします。
ユーザー文脈やパーソナライゼーションシグナルは、クエリファンアウトによるクエリ拡張パターンにも動的に影響し、ユーザーごとに大きく異なる検索経路を生みます。システムはユーザー属性(地理的位置、人口統計、職業)、検索履歴(過去クエリやクリック結果)、時間的シグナル(時間帯・季節・時事)、タスク文脈(調査、買い物、学習など)といった多次元のパーソナライズを組み込みます。たとえば「ランナー向けヘッドホン」のクエリは、ケニア在住22歳ウルトラマラソン選手とミネソタ在住45歳ジョギング愛好者とで全く異なる拡張に——前者は耐久性や耐熱性、後者は快適性やアクセス性重視が反映されます。ただしこの個別化は「ツーポイント変換」問題(現在のクエリを過去パターンの変種として扱う)を生み、探索を制限し既存の嗜好を強化しがちです。結果、クエリエキスパンションが過去の傾向に沿った情報や視点を体系的に優遇し、オルタナティブな情報や新規トピックとの出会いが減る「フィルターバブル」も発生します。これらのパーソナライゼーション機構の理解は、同じコンテンツでもユーザープロフィールや履歴次第で検索取得されるか否かが変わるため、制作者側にも極めて重要です。
主要なAIプラットフォームは、基盤インフラや設計思想に応じてクエリファンアウトのアーキテクチャ・透明性・戦略を大きく異ならせています。Google AIモードは、ユーザーが8~12個のサブクエリを明示的に閲覧できる最も可視性の高いファンアウトを採用し、Googleインデックスへ数百件の個別検索を発行し証拠を収集します。Microsoft CopilotはBing Orchestratorによる反復型アプローチで、5~8件を逐次生成・途中結果で拡張パターンを最適化して最終検索に至ります。Perplexityはウェブ・独自インデックス両方に6~10件のクエリを発行し、マルチステージランキングで最適パッセージを抽出。ChatGPTは内部処理で暗黙的にクエリ生成を行い、ユーザーからは実際のクエリ数や実行内容は見えません。こうしたアーキテクチャの違いは、透明性・再現性・制作者側の最適化手段にも大きく影響します:
| 項目 | Google AIモード | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| クエリ可視性 | 完全に可視 | 一部可視 | 引用で可視 | 不可視 |
| 実行モデル | 並列バッチ | 逐次反復型 | 並列+ランキング | 内部/暗黙的 |
| 情報源多様性 | Googleインデックスのみ | Bing+独自 | ウェブ+独自インデックス | 学習データ+プラグイン |
| 引用透明性 | 高 | 中 | 非常に高い | 低 |
| カスタマイズ性 | 限定的 | 中 | 高 | 中 |
クエリファンアウトは技術的・意味的な課題も孕み、ユーザー本来の意図から外れた情報取得につながることがあります。たとえばジェネレーティブな拡張によるセマンティックドリフト(意味の漂流)——「ランナー向けヘッドホン」→「アスレチックヘッドホン」→「スポーツ用品」→「フィットネスギア」と段階的に本来の意図から離れていく現象。システムは潜在的意図(もしユーザーがもっと知っていれば欲するであろう情報)と明示的意図(実際に尋ねたこと)を区別しなければならず、拡張が過剰だと両者が混同され、ユーザーが望まない製品情報まで取得されることもあります。反復的拡張の分岐により、各サブクエリがさらに多段階分岐し、最終的に元の意図から逸脱した情報まで検索されることも。パーソナライゼーションやフィルターバブルにより、同じ質問でもユーザーごとに体系的に異なる拡張・結果が得られ、エコーチェンバー(既存の嗜好強化)も生まれやすくなっています。実際、「手頃なヘッドホン」検索が履歴により高級ブランドへ拡張されたり、「聴覚障害者向けヘッドホン」検索が一般的アクセシビリティ製品まで拡張され、本来の意図が薄まるといった問題も報告されています。
クエリファンアウトの普及は、従来のキーワード順位最適化型SEOから、引用ベースの可視性戦略へと根本的な転換を迫ります。AI検索は特定キーワードでの順位より、多様なクエリバリエーション・文脈で権威ある情報源として引用されることを重視します。制作者は、特定エンティティ(製品・概念・人物)を中心にリッチな意味情報・構造化データ(スキーママークアップ)で整理したアトミックコンテンツ戦略を採用すべきです。トピッククラスタリングやトピカルオーソリティの構築も重要——個別記事の乱立ではなく、トピック領域を広く深くカバーすることで、ファンアウトで生成される多様なクエリにも拾われやすくなります。スキーママークアップ・構造化データ(Organization、Product、Article等)の実装はAIによる構造理解・引用抽出を促し、引用頻度の増加に直結します。成功指標もキーワード順位から、AmICited.com のようなツールでAI回答における引用頻度をモニタリングする形へと変わります。実践的な推奨事項は、1つのトピックの多角的側面を網羅した質の高いコンテンツ作成、リッチなスキーママークアップの実装、相互連携したコンテンツによるトピカルオーソリティ構築、異なるプラットフォームやユーザー層でどのようにAI回答に現れるかの定期的監査などです。
クエリファンアウトは、モバイルファーストインデックス以来の検索構造の最大変革であり、情報発見・提示の方法を根本から再構築します。意味インフラへの進化により、検索システムはキーワード中心から意味中心へと移行し、クエリファンアウトがデフォルトの情報取得手段となるでしょう。引用メトリクスは被リンクと並ぶ可視性・権威性指標となり、50のAI回答で引用されたコンテンツは単一キーワード1位よりも大きな価値を持ちます。この変化は従来のキーワード順位追跡型SEOツールの有効性を低下させ、引用頻度・情報源多様性・クエリバリエーション出現率などに基づく新たな評価軸を必要とします。一方、AI検索に特化した権威性・構造性の高いコンテンツを構築し、多様なクエリ解釈で信頼される情報源となることで、ブランドにとっては新たなチャンスも生まれます。今後は、各プラットフォームがクエリファンアウトの仕組みや推論プロセスの透明性を競い合い、制作者側も多様な検索経路での可視性最大化を目指した専門戦略を発展させる未来が予想されます。
クエリファンアウトは、AIシステムが単一のユーザークエリを自動的に複数のサブクエリへ分解し、並列実行するプロセスです。一方、従来のクエリエキスパンションは、関連語を単一クエリに追加することを指します。クエリファンアウトはより高度で、元の意図のさまざまな観点や解釈を捉える意味的に多様なバリエーションを生成します。
クエリファンアウトは可視性に大きく影響します。なぜなら、コンテンツはユーザーの入力通りのクエリだけでなく、複数のバリエーション全体で発見される必要があるからです。さまざまな観点を扱い、用語にバリエーションがあり、スキーママークアップなどで構造化されたコンテンツほど、ファンアウトで生成される多様なサブクエリでも取得・引用されやすくなります。
主要なAI検索プラットフォームはすべてクエリファンアウトを採用しています:Google AIモードは明示的で可視なファンアウト(8~12クエリ)、Microsoft CopilotはBing Orchestratorによる反復型ファンアウト、Perplexityはマルチステージランキングを備えたハイブリッド検索、ChatGPTは暗黙的なクエリ生成を行います。各プラットフォームで実装方法は異なりますが、すべて複雑なクエリを複数の検索へ分解しています。
はい。特定の概念を中心に構造化したアトミックでエンティティが豊富なコンテンツの作成、網羅的なスキーママークアップの実装、相互に関連したコンテンツによるトピカルオーソリティの構築、明確かつ多様な用語の使用、トピックの多角的な視点への対応などが最適化のポイントです。AmICited.comのようなツールを使えば、異なるクエリ分解パターンで自分のコンテンツがどう表示されるかをモニタリングできます。
クエリファンアウトは複数のクエリが並列で実行されるため、レイテンシが増加しますが、現代のシステムは並列処理によってこれを緩和しています。単一クエリなら200msで済んだものが、8つを並列に実行しても全体で300~500ms程度の追加遅延で済みます。クオリティ向上のためのトレードオフといえるでしょう。
クエリファンアウトは検索拡張生成(RAG)を強化し、より豊富な証拠収集を可能にします。従来のRAGでは単一クエリでドキュメントを取得しますが、ファンアウトでは複数のクエリバリエーションで並列取得し、多様で包括的な文脈をLLMに提供します。これにより正確な回答生成やハルシネーション(誤情報)リスクの低減が実現します。
パーソナライゼーションはユーザー属性(位置情報、履歴、デモグラフィック)、時間的シグナル、タスクコンテキストなどに基づきクエリ分解方法を変えます。同じクエリでもユーザーごとに拡張パターンが異なり、個別化された検索経路が生まれます。これにより関連性が高まる一方、フィルターバブルが生じ、プロフィールごとに体系的に異なる結果が表示されることにも繋がります。
クエリファンアウトはモバイルファーストインデックス以来、検索における最大の変化です。従来のキーワード順位指標は意味を失い、同じクエリでもユーザーごとに拡張結果が異なります。SEO担当者はキーワード順位から引用ベースの可視性、コンテンツ構造、エンティティ最適化へとシフトする必要があります。
クエリが拡張・分解された際に、あなたのブランドがAI検索プラットフォーム上でどのように表示されるかを理解しましょう。AI生成の回答における引用や言及の追跡が可能です。
AI検索システムにおけるクエリファンアウトの仕組みを解説。Google AIモード、ChatGPT、Perplexityなどで、AIが単一のクエリを複数のサブクエリへ拡張し、回答の精度とユーザー意図の理解をどう高めているかを紹介します。...

クエリリファインメントは、AI検索エンジンでより良い結果を得るために検索クエリを最適化する反復的なプロセスです。ChatGPT、Perplexity、Google AI、Claudeでどのように機能し、情報検索を向上させるかを解説します。...
クエリー予測が、フォローアップ質問に対応することで、あなたのコンテンツが拡張されたAI会話をどのように獲得できるかを学びましょう。予測されるクエリーを特定し、マルチターンAI対話向けにコンテンツを最適化する戦略もご紹介します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.