
AIにおすすめされる商品を獲得するには?
AIによる商品推薦の仕組み、背後にあるアルゴリズム、そしてChatGPTやPerplexityなどのAI搭載推薦システムで自社商品の可視性を最適化する方法について解説します。...
1 分で読める
ユーザーの行動や嗜好を分析し、個別に最適化された商品やコンテンツの提案を行う機械学習システム。これらのシステムは協調フィルタリングやコンテンツベースフィルタリングなどのアルゴリズムを使用して、ユーザーが興味を持ちそうなものを予測し、企業がエンゲージメント、売上、顧客満足度を向上させるためにパーソナライズされたレコメンデーションを実現します。
ユーザーの行動や嗜好を分析し、個別に最適化された商品やコンテンツの提案を行う機械学習システム。これらのシステムは協調フィルタリングやコンテンツベースフィルタリングなどのアルゴリズムを使用して、ユーザーが興味を持ちそうなものを予測し、企業がエンゲージメント、売上、顧客満足度を向上させるためにパーソナライズされたレコメンデーションを実現します。
AIによるレコメンデーションは、機械学習アルゴリズムを用いてユーザーの行動や嗜好を分析し、個人ごとのニーズや関心に合わせたパーソナライズ提案を実現する高度な技術です。レコメンデーションエンジンはこの仕組みの中核であり、膨大な商品カタログと個々のユーザーを知的に仲介する役割を果たし、かつてない規模での個別最適化を可能にします。グローバルなレコメンデーションエンジン市場は急成長を遂げており、2023年には約28億ドル、2030年には85億ドル規模に達すると予想されるなど、デジタル経済における本技術の重要性が浮き彫りになっています。こうしたAIレコメンデーションは、AmazonやeBayなどのEC、NetflixやSpotifyなどのストリーミングサービス、SNS、コンテンツプラットフォームなど様々な業界で不可欠な存在となっています。これらのシステムの根底には、機械学習アルゴリズムが人間には捉えにくいユーザー行動のパターンを発見し、ユーザー自身も気づかないうちにニーズを先回りして提案できるという原理があります。膨大なデータセットと計算能力を活用することで、レコメンデーションシステムは消費者の新たな商品・コンテンツ・サービス発見のあり方を変革し、業界全体の顧客エンゲージメント戦略を根底から再構築しています。

AIレコメンデーションシステムは、生のユーザーデータを実用的なパーソナライズ提案へと変換する洗練された5段階プロセスで動作します。最初の段階は包括的なデータ収集であり、システムはユーザーの各種インタラクション、閲覧履歴、購入記録、明示的なフィードバックなど多様なタッチポイントから情報を集めます。分析段階では、収集したデータを機械学習アルゴリズム(協調フィルタリング、コンテンツベースフィルタリング、ニューラルネットワーク等)で処理し、複雑なデータセットから有意なパターンや関係性を抽出します。パターン認識段階はシステムの計算的中核であり、アルゴリズムがユーザー同士やアイテム間、またはその両方の類似性を特定し、嗜好やアイテム特性の数学的表現を生成します。予測段階では、こうしたパターンを活用して、ユーザーが最も関心を持つ可能性が高いアイテムを予測し、それぞれに信頼度スコアを割り当てます。最終段階の提案提示では、パーソナライズされたインターフェースを通じて最適なタイミングでこれらの予測をユーザーに提示します。近年はリアルタイム処理能力が重要性を増しており、最新のシステムは新たなユーザー行動データが到着するたび即座にレコメンドを更新し、嗜好変化に動的に適応するパーソナライズを実現しています。高度なレコメンデーションシステムでは複数アルゴリズムを組み合わせるアンサンブル法も用いられ、各アルゴリズムの予測を合成することで、単独手法よりも頑健で高精度なレコメンドを生み出します。
レコメンデーションシステムは、嗜好や行動パターンを把握するために、以下2種類のユーザーデータを活用します。
明示的データ:
暗黙的データ:
明示的データはユーザー嗜好を直接・明確に反映しますが、ほとんどのユーザーは全アイテムのごく一部しか評価しないためデータが希薄です。一方、暗黙的データは通常の利用行動から大量に蓄積されますが、閲覧が必ずしも興味を意味するとは限らないため高度な解釈が必要です。最も効果的なレコメンデーションシステムは両データタイプを統合し、明示的フィードバックで暗黙的シグナルを検証・補正しながら、ユーザーの「表明嗜好」と「行動嗜好」の両面を網羅するプロファイルを構築します。
協調フィルタリングは、レコメンデーションシステムの基礎的アプローチのひとつであり、「過去に似た嗜好を持つユーザーは将来的にも似たものを好む」という原理に基づいています。この手法は全ユーザー集団のパターンを分析し、個々のアイテム特性ではなく、嗜好傾向の共通性に着目します。ユーザーベース協調フィルタリングは、ターゲットユーザーと過去の嗜好履歴が似ている他のユーザーを特定し、その類似ユーザーが高評価したがターゲットユーザーが未体験のアイテムを推薦します。アイテムベース協調フィルタリングは、他のユーザーによる評価の傾向からアイテム同士の類似性を計算し、ユーザーが過去に高評価したアイテムに似た商品を提案します。両手法ではコサイン類似度、ピアソン相関、ユークリッド距離などの類似度指標を用いて、嗜好空間におけるユーザーやアイテムの近接性を定量化します。協調フィルタリングは、アイテムのメタデータがなくてもレコメンドできる、想定外の偶発的発見を促せるといった強みを持ちますが、「コールドスタート問題」(新規ユーザーや新アイテムに十分な履歴がなく類似性計算ができない)や、多数のアイテムが未評価のまま残る「データスパース問題」などの課題も抱えています。
コンテンツベースフィルタリングは、アイテム自体の特性や特徴を分析し、ユーザーが過去に好んだ商品と類似するアイテムを属性情報に基づいて推薦するアプローチです。集団的なユーザー行動ではなく、各アイテムのジャンル、監督・出演者(映画の場合)、著者や題材・発行日(書籍の場合)、カテゴリやブランド・仕様(ECの場合)など、対象アイテムの特徴から詳細なプロファイルを構築します。システムは、アイテムの特徴ベクトル同士をコサイン類似度やユークリッド距離などの数理手法で比較し、特徴空間におけるアイテム間の近接性を数値化します。ユーザーがアイテムを評価・利用した際、その特徴に類似した他のアイテムを抽出し、属性重視のパーソナライズ提案を実現します。コンテンツベースフィルタリングは、アイテムのメタデータが豊富で構造化されていれば特に効果を発揮し、新規アイテムにも履歴依存せず対応できます。一方、「偶発的発見」や「新分野開拓」に弱く、過去の嗜好に近いものばかりを推薦しがちなため、フィルターバブル化しやすいという弱点もあります。協調フィルタリングと比べて特徴設計が必要で、曖昧なカテゴリの商品には不向きですが、推薦理由をアイテム属性で説明しやすいという透明性の高さが特徴です。
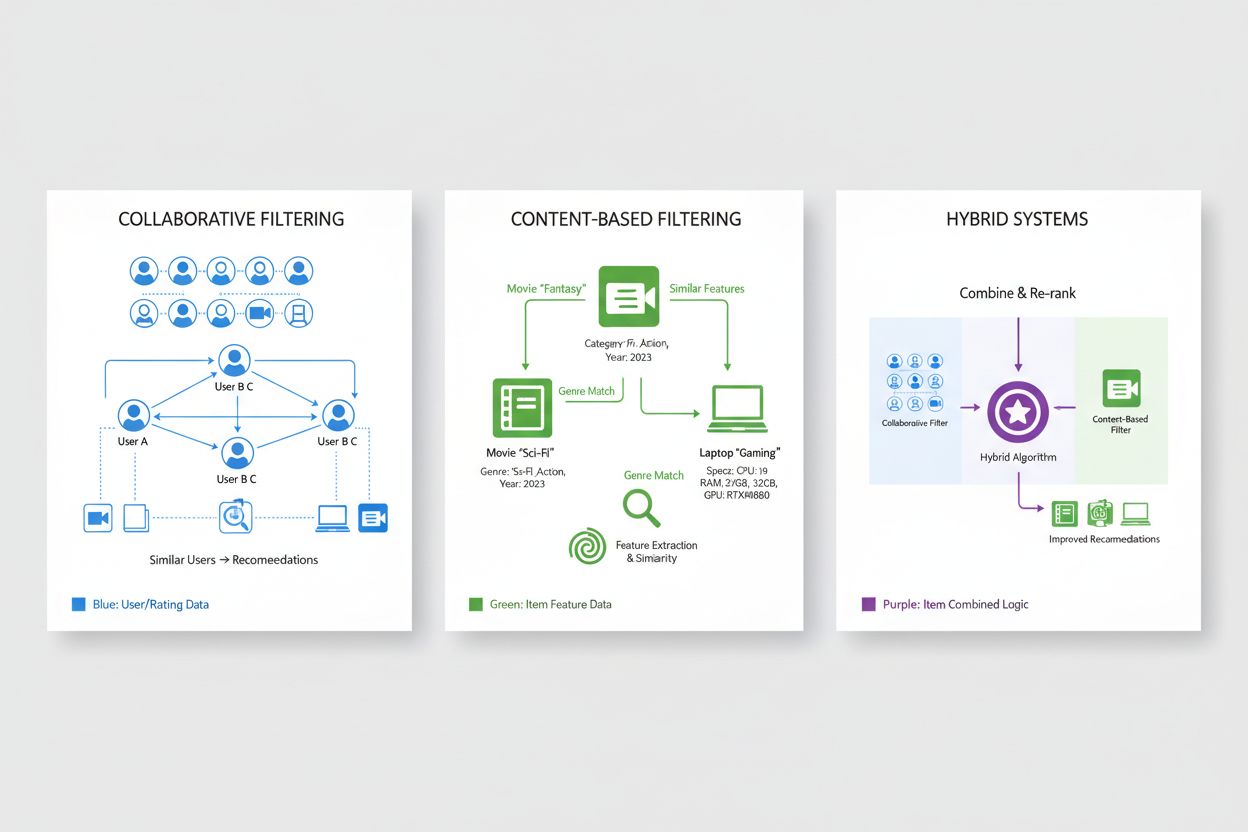
ハイブリッドレコメンデーションシステムは、協調フィルタリングとコンテンツベースフィルタリングの長所を組み合わせ、それぞれの弱点を補いながら高精度なレコメンドを実現する戦略的アプローチです。加重合成(複数アルゴリズムの予測を重み付きで統合)、状況によるアルゴリズム切替、片方の出力を他方に入力するカスケード方式など、様々な統合戦略が用いられます。協調フィルタリングの偶発的発見力・複雑な嗜好パターン把握力と、コンテンツベースフィルタリングの新規アイテム対応力・説明性を両立させることで、多様な状況で頑健な性能を発揮します。Netflixは協調・コンテンツベース・文脈情報を組み合わせ、人気・個人最適・新規性のバランスを取ったレコメンドを実現しています。Spotifyも、リスニングパターンに基づく協調フィルタリング、音響特徴分析やメタデータによるコンテンツベース、さらにはユーザー生成プレイリストやレビューの自然言語処理をハイブリッドで利用しています。ハイブリッド方式は精度向上にとどまらず、アイテムカタログの広範なカバー、スパースデータやコールドスタートへの対応力強化、堅牢性向上など多面的な利点をもたらします。現在、エンタープライズ規模のレコメンデーションプラットフォームの多くは、進化し続けるハイブリッドアーキテクチャを採用し、業界最先端のパーソナライズ技術の中核となっています。
AIレコメンデーションは、主要テクノロジー企業や小売大手のビジネスモデルの中核となり、顧客の商品発見・購買行動を根本的に変革しています。Amazonは売上の約35%をレコメンデーションドリブンで生み出しており、閲覧履歴や購入パターン、評価、類似顧客の行動を分析し、ショッピング体験の重要な場面で最適な商品提案を行っています。Netflixは視聴履歴、評価、検索、時間帯パターン等を処理し、パーソナライズされたレコメンドが全再生時間の約80%を占めるほどユーザーエンゲージメントとリテンションに直結しています。Spotifyは「Discover Weekly」などのプレイリスト機能をはじめとした複数の面でAIレコメンデーションを活用し、協調フィルタリングと音響特徴分析・文脈情報を組み合わせたパーソナライズ音楽提案により、ユーザーの継続利用やサブスクリプション維持に大きく貢献しています。急成長中のECサイトTemuも、行動パターンや検索・購入履歴の高度な分析で個人ごとに最適な商品を提示し、爆発的な成長・エンゲージメント向上を実現しています。これらの導入例は、レコメンデーションシステムが顧客生涯価値、リピート率、滞在時間などの主要指標に直結し、競争激化するデジタル市場での差別化要素として莫大な投資がなされていることを示しています。
AIレコメンデーションは、企業とユーザー双方に大きな価値をもたらし、エンゲージメントと満足度を高める好循環を生み出します。
ビジネス側のメリット:
ユーザー側のメリット:
こうしたメリットの累積効果により、レコメンデーションシステムはデジタルコマースやコンテンツプラットフォームの不可欠なインフラとなり、ユーザーはパーソナライズ体験をもはや特別なものではなく当然の機能として求めるようになっています。
AIレコメンデーションは広く成功を収めている一方で、研究・実務の現場では多くの課題が残されています。GDPRやCCPAといった規制強化に伴い、データ収集・利用に関するプライバシー問題が深刻化しており、パーソナライズの効果とユーザープライバシー・データ保護の両立が不可欠となっています。新規ユーザーや新規アイテムに履歴がない「コールドスタート問題」も依然として大きな課題であり、ハイブリッド手法や代替戦略での突破口が模索されています。また、アルゴリズムバイアスも重大な問題であり、レコメンデーションシステムが学習データに潜む偏りを再生産・増幅することで、特定ユーザー層への不公平や、多様な視点・コンテンツへの接触機会の制限(フィルターバブル化)を引き起こすリスクも指摘されています。
昨今は、エッジコンピューティングやストリーミングデータ処理によるリアルタイムパーソナライズの高度化が進み、ユーザー行動への即時適応が可能となっています。さらに、従来の行動データを超え、ビジュアル・音声・テキスト・文脈などのマルチモーダルデータ統合も進展し、より豊かで精緻な嗜好理解が実現されています。感情コンテキストやセンチメント解析を取り入れた「感情駆動型レコメンデーション」も最先端領域であり、過去の嗜好だけでなく、現在の気分や心理状態にも寄り添う提案が模索されています。今後は、なぜこの提案が表示されたのかを説明し、ユーザー自身がレコメンドプロファイルを操作できる「説明性」や「透明性」の強化も重視されるでしょう。こうしたトレンドが集約されることで、次世代のレコメンデーションシステムは、よりプライバシー重視・透明性重視・感情知能を備え、ユーザーの自律性とデータ権利を尊重しつつ、これまでにないパーソナライズ体験を提供する存在へと進化していくと考えられます。
AIによるレコメンデーションは、ユーザーの行動や嗜好データに基づいて積極的にアイテムを提案し、ユーザーが明示的に検索を行わなくても興味を持ちそうなものを提示します。一方、従来の検索はユーザーが自らキーワードで商品を探す必要があります。レコメンデーションは機械学習で興味を予測しますが、検索はキーワードマッチングに依存します。また、レコメンデーションは個人ごとに最適化されますが、検索結果は一般的な傾向が強いです。近年は両者を組み合わせて最適な体験を提供するシステムが増えています。
新規ユーザーには十分な履歴データがないため「コールドスタート問題」が発生します。主な解決策としては、ユーザー属性情報の利用、人気アイテムの表示、アイテムの特徴に基づくコンテンツベースフィルタリングの適用、ユーザーに明示的な好みを入力してもらうなどがあります。ハイブリッドシステムはこれら複数の手法を組み合わせて新規ユーザーのレコメンドを立ち上げます。また、協調フィルタリングでは似たプロフィールのユーザーや、デバイスや位置情報などの文脈データを活用して初期提案を行う場合もあります。
レコメンデーションシステムは、評価やレビュー、ユーザーからのフィードバックなどの明示的データに加え、閲覧履歴、購入履歴、アイテムに費やした時間、検索クエリ、クリックパターンなどの暗黙的データを収集します。また、デバイス種別、位置情報、時間帯、季節要因などの文脈情報も取得します。高度なシステムでは、属性情報やソーシャルグラフ、行動シグナルも統合します。すべてのデータ収集はGDPRやCCPAなどのプライバシー規制に準拠し、ユーザーの同意や透明な利用方針が求められます。
はい。レコメンデーションシステムは、学習データに含まれる偏りを引き継いだり増幅したりすることがあり、特定のユーザー層に不利に働いたり、多様なコンテンツへの接触機会を狭めてしまう場合があります。アルゴリズムバイアスは、偏った履歴データや少数派の過小評価、既存パターンの強化フィードバックループなどから生じます。バイアス対策には、多様なデータの利用、定期的な監査、公平性指標、透明なアルゴリズム設計などが必要です。企業は全ユーザー向けに公平なレコメンドを実現するため積極的な監視と対策が求められます。
ハイブリッドシステムは、協調フィルタリングの偶発的な発見力と、コンテンツベースフィルタリングの新規アイテム対応力・説明性を組み合わせることで、それぞれの弱点を補います。協調フィルタリングは新規アイテムに弱いですが、コンテンツベースは偶発性に乏しいため、加重結合や切替、カスケードなどの手法で両者の強みを活かします。その結果、精度向上、アイテムカタログの広範なカバー、スパースデータへの対応力強化、多様な状況下での堅牢性向上などを実現します。
正確なレコメンドのために広範なデータ収集が必要となること、未承認のデータ利用や漏洩リスク、GDPRやCCPAなど法規制への対応などが主な懸念点です。パーソナライズのための行動追跡レベルに不安を感じるユーザーもいます。企業は強固なセキュリティ、明示的な同意取得、データ利用の透明性、ユーザーによるデータ管理などを徹底しなければなりません。パーソナライズの効果とプライバシー保護の両立は今後も重要課題です。
リアルタイムレコメンデーションは、ユーザーの行動データを発生と同時に処理し、現在の操作内容に基づいて即座に提案を更新します。システムはストリーミングデータ処理やエッジコンピューティングを活用し、クリックや閲覧、購入などの行動をミリ秒単位で分析します。これにより、セッション中の嗜好変化にダイナミックに適応するパーソナライズが可能です。リアルタイム対応には堅牢なインフラ、高速アルゴリズム、低遅延のデータパイプラインが不可欠です。例として、Netflixが閲覧中にレコメンドを即時更新したり、Amazonがカート追加ごとに新提案を表示する仕組みなどが挙げられます。
今後は、ユーザーの感情状態を考慮した感情駆動型レコメンド、視覚・音声・テキストなどマルチモーダルデータの統合、プライバシー保護技術の進化、説明性・透明性の強化、大規模リアルタイムパーソナライズなどが主なトレンドです。フェデレーテッドラーニングのような新技術により、ユーザーデータを集中管理せずにレコメンドが可能になります。システムはより文脈認識型となり、時間的要素や状況情報も取り入れるようになります。これらのトレンドの融合により、より洗練され透明性が高く、ユーザーの自律性やデータ権利を尊重したパーソナライズが実現されていきます。
AmICitedは、ChatGPT、Perplexity、Google AI Overviews などのAIシステムが、パーソナライズされたレコメンデーションやAI生成コンテンツであなたのブランドをどのように言及しているかを追跡します。AIによるブランドの可視性をいち早く把握しましょう。
AIによる商品推薦の仕組み、背後にあるアルゴリズム、そしてChatGPTやPerplexityなどのAI搭載推薦システムで自社商品の可視性を最適化する方法について解説します。...
ChatGPT、Perplexity、Google AI OverviewsなどのAI検索エンジンで、ブランド言及やウェブサイト引用を継続的に自動追跡する方法を学びましょう。...

旅行ブランドがAIによる検索結果で可視性を高める方法を学びましょう。ChatGPT、Google AIモード、Perplexityでの目的地と予約のレコメンデーション最適化戦略をご紹介します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.