主要プラットフォームでAIトレーニングをオプトアウトする方法
ChatGPT、Perplexity、LinkedInなどの主要プラットフォームでAIトレーニングデータ収集をオプトアウトするための完全ガイド。AIモデルのトレーニングから自分のデータを守るための手順を学びましょう。...
1 分で読める
コンテンツクリエイターや著作権者が自分の作品を大規模言語モデルのトレーニングデータセットで使用されることを防ぐための技術的および法的メカニズム。robots.txtディレクティブ、法的オプトアウト声明、EU AI法などの規制に基づく契約上の保護が含まれます。
コンテンツクリエイターや著作権者が自分の作品を大規模言語モデルのトレーニングデータセットで使用されることを防ぐための技術的および法的メカニズム。robots.txtディレクティブ、法的オプトアウト声明、EU AI法などの規制に基づく契約上の保護が含まれます。
AIトレーニングオプトアウトとは、コンテンツクリエイター、著作権者、ウェブサイト所有者が自分の作品を大規模言語モデル(LLM)のトレーニングデータセットで使用されることを防ぐための技術的および法的メカニズムを指します。AI企業がますます高度なモデルをトレーニングするためにインターネットから膨大な量のデータをスクレイピングするにつれて、コンテンツがこのプロセスに参加するかどうかを制御する能力は、知的財産を保護し創造的なコントロールを維持するために不可欠になりました。これらのオプトアウトメカニズムは2つのレベルで機能します:AIクローラーにコンテンツをスキップするよう指示する技術的ディレクティブと、トレーニングデータセットから作品を除外する契約上の権利を確立する法的フレームワークです。両方の次元を理解することは、AI時代に自分のコンテンツがどのように使用されるかを懸念するすべての人にとって重要です。

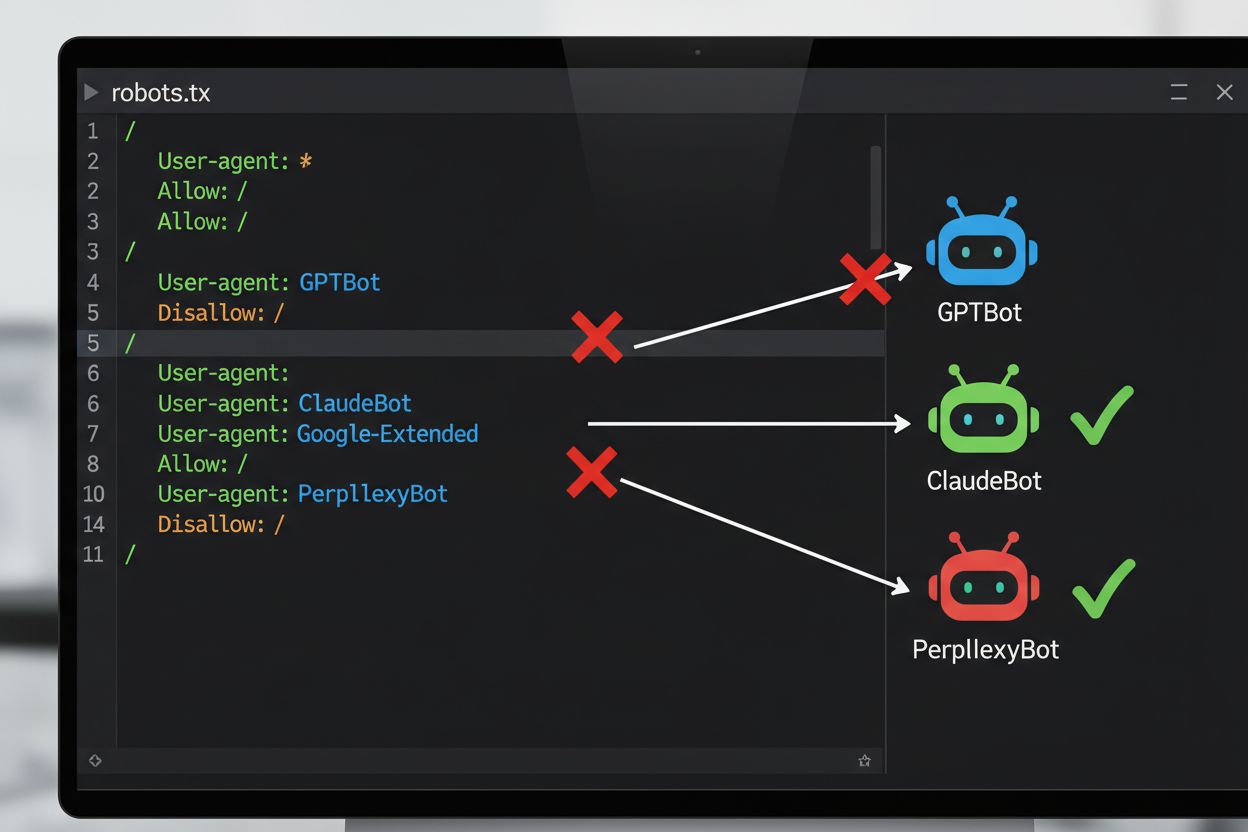
AIトレーニングをオプトアウトするための最も一般的な技術的方法は、ウェブサイトのルートディレクトリに配置され、自動化されたボットにクローラーの権限を伝達する単純なテキストファイルであるrobots.txtファイルを通じてです。AIクローラーがサイトを訪問すると、まずrobots.txtをチェックしてコンテンツへのアクセスが許可されているかどうかを確認します。特定のクローラーユーザーエージェントに対する特定のdisallowディレクティブを追加することで、AIボットにサイト全体をスキップするよう指示できます。各AI企業は、リクエストを行う際にボットが自身を識別するために使用する「名前」である、異なるユーザーエージェント識別子を持つ複数のクローラーを運用しています。例えば、OpenAIのGPTBotはユーザーエージェント文字列「GPTBot」で自身を識別し、AnthropicのClaudeは「ClaudeBot」を使用します。構文は簡単です:ユーザーエージェント名を指定し、サイト全体をブロックするための「Disallow: /」などの禁止パスを宣言します。
| AI企業 | クローラー名 | ユーザーエージェントトークン | 目的 |
|---|---|---|---|
| OpenAI | GPTBot | GPTBot | モデルトレーニングデータ収集 |
| OpenAI | OAI-SearchBot | OAI-SearchBot | ChatGPT検索インデックス |
| Anthropic | ClaudeBot | ClaudeBot | チャット引用フェッチ |
| Google-Extended | Google-Extended | Gemini AIトレーニングデータ | |
| Perplexity | PerplexityBot | PerplexityBot | AI検索インデックス |
| Meta | Meta-ExternalAgent | Meta-ExternalAgent | AIモデルトレーニング |
| Common Crawl | CCBot | CCBot | LLMトレーニング用オープンデータセット |
AIトレーニングオプトアウトの法的環境は、2024年に発効しテキストおよびデータマイニング(TDM)指令の規定を組み込んだEU AI法の導入により大幅に進化しました。これらの規制の下では、AI開発者はコンテンツへの合法的なアクセスを持ち、著作権者がテキストおよびデータマイニングから作品を除外する権利を明示的に留保していない場合にのみ、機械学習目的で著作権保護された作品を使用することが許可されます。これは、オプトアウトの正式な法的メカニズムを作成します:著作権者は作品とともにオプトアウト予約を提出でき、明示的な許可なしにAIトレーニングでの使用を効果的に防止できます。EU AI法は、以前の「動きながら壊す」アプローチからの重要な転換を表し、AIモデルをトレーニングする企業は権利者がコンテンツを留保しているかどうかを確認し、オプトアウトされた作品の不注意な使用を防ぐための技術的および組織的な保護措置を実施しなければならないことを確立しています。この法的フレームワークは欧州連合全体に適用され、グローバルなAI企業がデータ収集とトレーニング慣行にどのようにアプローチするかに影響を与えています。
オプトアウトメカニズムの実装には、技術的設定と法的文書の両方が含まれます。技術面では、ウェブサイト所有者は特定のAIクローラーユーザーエージェントに対するdisallowディレクティブをrobots.txtファイルに追加し、準拠するクローラーはサイトを訪問する際にこれを尊重します。法的面では、著作権者は収集団体や権利管理組織にオプトアウト声明を提出できます—例えば、オランダの収集団体Pictorightとフランスの音楽団体SACEMは、クリエイターがAIトレーニング使用に対する権利を留保できる正式なオプトアウト手続きを確立しています。多くのウェブサイトやコンテンツクリエイターは現在、利用規約やメタデータに明示的なオプトアウト声明を含め、コンテンツがAIモデルトレーニングに使用されるべきではないことを宣言しています。ただし、これらのメカニズムの有効性はクローラーのコンプライアンスに依存します:OpenAI、Google、Anthropicなどの主要企業はrobots.txtディレクティブとオプトアウト予約を尊重すると公式に述べていますが、中央集権的な強制メカニズムがないため、オプトアウトリクエストが適切に尊重されているかどうかを判断するには継続的なモニタリングと検証が必要です。
オプトアウトメカニズムが利用可能であるにもかかわらず、その有効性を制限する重要な課題があります:
robots.txtだけでは提供される保護よりも強力な保護を必要とする組織向けに、いくつかの追加の技術的方法を実装できます。サーバーまたはファイアウォールレベルでのユーザーエージェントフィルタリングは、リクエストがアプリケーションに到達する前に特定のクローラー識別子からのリクエストをブロックできますが、これは偽装に対して脆弱です。IPアドレスブロッキングは主要AI企業が公開する既知のクローラーIP範囲をターゲットにできますが、決意のあるスクレイパーはプロキシネットワークを通じてこれを回避できます。レート制限とスロットリングは、秒あたりに許可されるリクエスト数を制限することでスクレイパーを遅くし、スクレイピングを経済的に実行不可能にしますが、高度なボットはこれらの制限を回避するために複数のIPにリクエストを分散できます。認証要件とペイウォールは、ログインユーザーまたは支払い顧客へのアクセスを制限することで強力な保護を提供し、自動スクレイピングを効果的に防止します。デバイスフィンガープリンティングと行動分析は、人間のユーザーとは異なるブラウザAPI、TLSハンドシェイク、インタラクションパターンなどのパターンを分析することでボットを検出できます。一部の組織は、クローラーリソースを浪費し、トレーニングデータセットをゴミデータで汚染する可能性のある、ボットだけがたどる隠しリンクや無限リンク迷路であるハニーポットとターピットも展開しています。
AI企業とコンテンツクリエイター間の緊張は、オプトアウト執行の実際の課題を示すいくつかの注目度の高い対立を生み出しました。Redditは2023年に、特にAI企業にデータ料金を請求するためにAPI アクセス価格を大幅に引き上げるという積極的な行動を取り、不正なスクレイパーを効果的に締め出し、OpenAIやAnthropicなどの企業にライセンス契約の交渉を強いました。Twitter/Xはさらに極端な措置を実施し、すべての認証されていないツイートへのアクセスを一時的にブロックし、ログインユーザーが読めるツイート数を制限し、リソースを消費するデータスクレイパーを明示的にターゲットにしました。Stack Overflowは当初、ユーザー投稿コードのライセンス懸念を理由にrobots.txtファイルでOpenAIのGPTBotをブロックしましたが、後にブロックを削除しました—おそらくOpenAIとの交渉を示しています。ニュースメディア組織は大規模に対応しました:2023年までに主要ニュースサイトの50%以上がAIクローラーをブロックし、The New York Times、CNN、Reuters、The GuardianなどのメディアがすべてdisallowリストにGPTBotを追加しました。一部のニュース組織は代わりに法的措置を追求し、The New York TimesがOpenAIに対して著作権侵害訴訟を提起し、一方でAssociated Pressなどの他の組織はコンテンツを収益化するためにライセンス契約を交渉しました。これらの例は、オプトアウトメカニズムは存在するものの、その有効性は技術的実装と違反が発生した場合に法的救済を追求する意思の両方に依存することを示しています。
オプトアウトメカニズムの実装は戦いの半分に過ぎません;それらが実際に機能しているかどうかを確認するには、継続的なモニタリングとテストが必要です。設定を検証するのに役立ついくつかのツールがあります:Google Search ConsoleにはGooglebot固有の検証用のrobots.txtテスターが含まれ、Merkleのrobots.txtテスターとTechnicalSEO.comのツールは特定のユーザーエージェントに対する個々のクローラー動作をテストします。AI企業が実際にオプトアウトディレクティブを尊重しているかどうかの包括的なモニタリングには、AmICited.comのようなプラットフォームが、GPT、Perplexity、Google AIオーバービュー、その他のAIプラットフォーム全体でAIシステムがブランドとコンテンツをどのように参照するかを追跡する専門的なモニタリングを提供します。このタイプのモニタリングは、クローラーがサイトにアクセスしているかどうかだけでなく、コンテンツが実際にAI生成回答に表示されているかどうかを明らかにするため、特に価値があります—オプトアウトが実際に効果的かどうかを示します。定期的なサーバーログ分析も、どのクローラーがサイトにアクセスしようとしているか、robots.txtディレクティブを尊重しているかどうかを明らかにできますが、これを正しく解釈するには技術的な専門知識が必要です。
不正なAIトレーニング使用からコンテンツを効果的に保護するには、技術的および法的手段を組み合わせた階層化されたアプローチを採用してください。まず、すべての主要AIトレーニングクローラー(GPTBot、ClaudeBot、Google-Extended、PerplexityBot、CCBotなど)に対するrobots.txtディレクティブを実装し、これが準拠する企業に対するベースライン防御を提供することを理解してください。次に、ウェブサイトの利用規約とメタデータに明示的なオプトアウト声明を追加し、コンテンツがAIモデルトレーニングに使用されるべきではないことを明確に宣言します—これは違反が発生した場合の法的立場を強化します。第三に、テストツールとサーバーログを使用して設定を定期的にモニタリングし、クローラーがディレクティブを尊重していることを確認し、新しいAIクローラーが常に出現するためrobots.txtを四半期ごとに更新してください。第四に、技術的リソースがある場合はユーザーエージェントフィルタリングやレート制限などの追加の技術的手段を検討し、これらがより高度なスクレイパーに対する増分的な保護を提供することを認識してください。最後に、ディレクティブを無視する企業に対して法的措置を追求する必要がある場合、この文書が重要になるため、オプトアウト努力を徹底的に文書化してください。オプトアウトは一度限りの設定ではなく、AI環境が進化し続ける中で警戒と適応を必要とする継続的なプロセスであることを覚えておいてください。
robots.txtは、クローラーにコンテンツをスキップするよう指示する技術的で任意の標準ですが、法的オプトアウトは著作権団体への正式な予約の申請や利用規約への契約条項の含めることを含みます。robots.txtは実装が簡単ですが強制力がなく、法的オプトアウトはより強力な法的保護を提供しますが、より正式な手続きが必要です。
OpenAI、Google、Anthropic、Perplexityなどの主要AI企業は、robots.txtディレクティブを尊重すると公式に述べています。ただし、robots.txtは強制メカニズムのない任意の標準であるため、非準拠のクローラーや不正なスクレイパーはディレクティブを完全に無視できます。
いいえ。GPTBotやClaudeBotなどのAIトレーニングクローラーをブロックしても、従来の検索エンジンは独立して動作する異なるクローラー(Googlebot、Bingbot)を使用するため、GoogleやBingの検索ランキングには影響しません。検索結果から完全に消えたい場合にのみ、それらをブロックしてください。
EU AI法は、AI開発者がコンテンツへの合法的なアクセスを持ち、著作権者のオプトアウト予約を尊重しなければならないことを要求しています。著作権者は作品とともにオプトアウト声明を提出でき、明示的な許可なしにAIトレーニングでの使用を効果的に防止できます。これは、不正なトレーニング使用からコンテンツを保護するための正式な法的メカニズムを作成します。
特定のメカニズムによります。すべてのAIクローラーをブロックすると、AI検索結果にコンテンツが表示されなくなりますが、AI搭載検索プラットフォームから完全に削除されることにもなります。一部のパブリッシャーは、モデルトレーニングからコンテンツを保護しながらAI検索での可視性を維持するために、トレーニング重視のクローラーをブロックしながら検索重視のクローラーを許可する選択的ブロッキングを好みます。
AI企業がオプトアウトディレクティブを無視した場合、管轄権と具体的な状況に応じて、著作権侵害請求や契約違反を通じて法的手段を取ることができます。ただし、法的措置は費用がかかり時間がかかり、裁判での結果は不確実です。これが、オプトアウト努力のモニタリングと文書化が重要な理由です。
少なくとも四半期ごとにrobots.txt設定を確認し更新してください。新しいAIクローラーは常に出現し、企業は頻繁に新しいクローラーユーザーエージェントを導入します。例えば、Anthropicは'anthropic-ai'と'Claude-Web'ボットを'ClaudeBot'に統合し、ルールを更新していなかったサイトに新しいボットに対する一時的な無制限アクセスを与えました。
オプトアウトは、robots.txtと法的フレームワークを尊重する準拠した評判の良いAI企業に対して効果的です。ただし、法的グレーゾーンで活動する不正なクローラーや非準拠のスクレイパーに対しては効果が低いです。robots.txtはAIボットの約40-60%を停止しますが、これが複数の技術的および法的手段を組み合わせた階層化されたアプローチが推奨される理由です。
ChatGPT、Perplexity、LinkedInなどの主要プラットフォームでAIトレーニングデータ収集をオプトアウトするための完全ガイド。AIモデルのトレーニングから自分のデータを守るための手順を学びましょう。...
GPTBotや他のAIクローラーの許可についてのコミュニティディスカッション。サイトオーナーが経験や可視性への影響、AIクローラーアクセスに関する戦略的考慮事項を共有します。...
AIトレーニングデータへの掲載を目指したコンテンツ最適化の方法を学びましょう。正しいコンテンツ構造、ライセンス設定、オーソリティ構築を通じて、ChatGPT・Gemini・PerplexityなどのAIシステムによるウェブサイト発見性を高めるベストプラクティスを紹介します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.