AIコンテンツにおけるバースティネスとは?検出への影響と重要性
AI生成コンテンツにおけるバースティネスの意味、人間の文章パターンとの違い、そしてAI検出やコンテンツの信頼性における重要性を解説します。...
1 分で読める
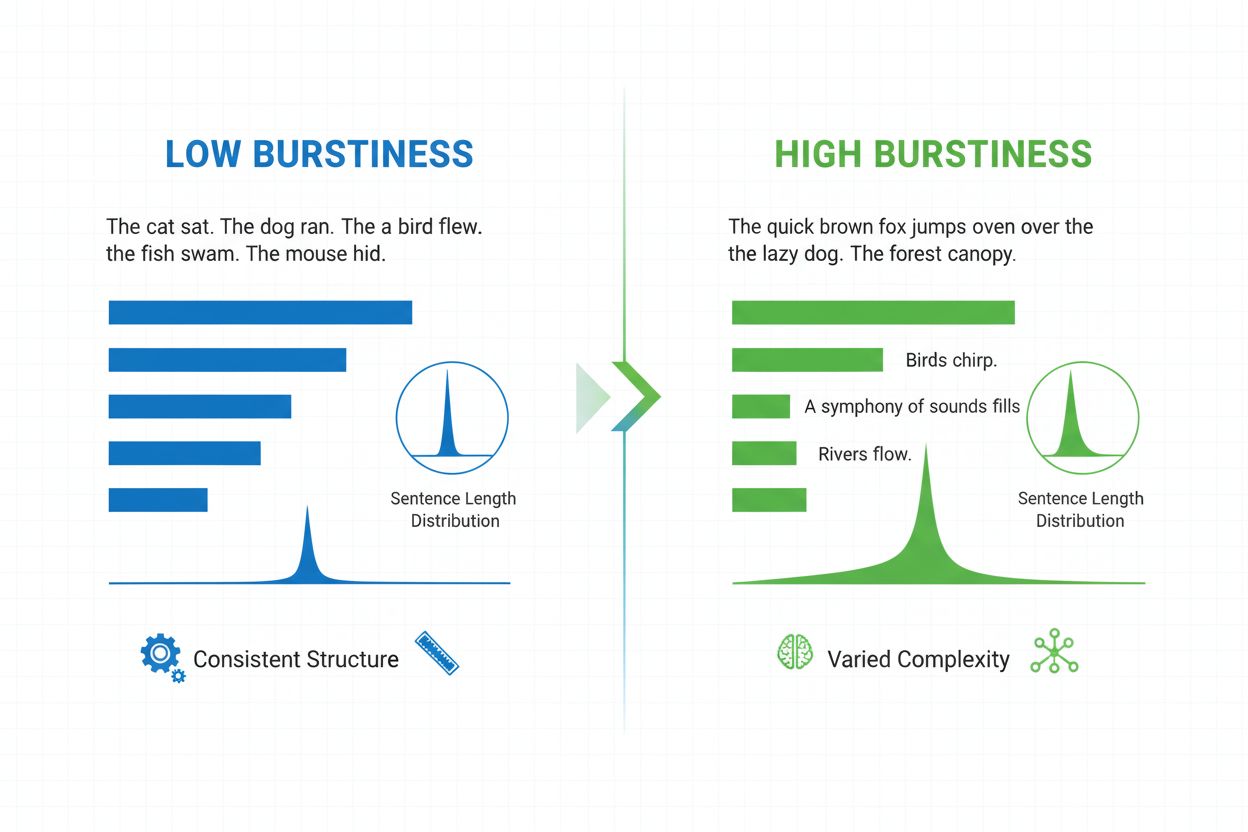
バースティネスは、文書全体にわたる文の長さ、構造、複雑さの変化を測定する言語指標です。短く印象的な文と長く複雑な文を交互に用いる度合いを定量化し、AI生成コンテンツの検出や自然言語分析の主要な指標のひとつです。
バースティネスは、文書全体にわたる文の長さ、構造、複雑さの変化を測定する言語指標です。短く印象的な文と長く複雑な文を交互に用いる度合いを定量化し、AI生成コンテンツの検出や自然言語分析の主要な指標のひとつです。
バースティネスは、文書やテキスト内の文の長さ・構造・複雑さの変動や揺らぎを定量的に測定する言語指標です。この用語は、短く簡潔な文と長く入り組んだ文が交互に現れる「バースト(爆発)」的な文パターンに由来します。自然言語処理やAIコンテンツ検出の文脈では、バースティネスはテキストが人間によって書かれたものか、AIによって生成されたものかを見分ける重要な指標です。人間のライターは強調やリズム、文体的意図に応じて文構成を無意識に変化させるため、自然にバースティネスの高いテキストを生み出します。一方、AI生成テキストは通常バースティネスが低いのが特徴で、言語モデルが一貫性や予測可能性を重視した統計パターンに基づいて訓練されているためです。バースティネスの理解は、コンテンツ制作者、教育者、研究者、ChatGPT、Perplexity、Google AI Overviews、ClaudeなどのプラットフォームでAI生成コンテンツを監視する組織にとって不可欠です。
バースティネスという概念は、自然言語の統計的特徴を定量化しようとする計算言語学や情報理論の研究から生まれました。初期のスタイロメトリー(文体統計解析)研究では、人間の文章には機械生成テキストと根本的に異なる多様性のパターンがあることが発見されました。大規模言語モデル(LLM)が2020年代初頭に高度化するにつれ、バースティネスとパープレキシティ(単語予測困難度)を組み合わせることで、AI生成コンテンツを信頼性高く判別できると認識されるようになりました。QuillBotや学術機関の調査によれば、企業の約78%がバースティネス分析を含むAIコンテンツ監視ツールを導入しています。スタンフォード大学による2023年のTOEFLエッセイ研究では、バースティネスに基づく検出法は有用である一方、特に非ネイティブ英語の誤判定という大きな制約があることが示されました。この知見を受け、バースティネスのみならず他の言語指標や意味的一貫性、文脈適合性も考慮した多層的なAI検出システムの開発が進んでいます。
バースティネスは、テキスト内の文の長さや構造パターンの統計分布を分析することで算出されます。この指標は個々の文が文書全体の平均的な文長からどれだけ逸脱しているか(分散)を定量化します。高いバースティネスの文章は、短い文(例:「See?」のような3語文)と、複数の節や従属句を含む25語程度の長文が混在します。反対に、低いバースティネスは、ほとんどの文が12〜18語程度でまとまり、単調なリズムを生みます。測定手順は、まず各文の単語数を測り、次に平均文長を算出し、その平均からの標準偏差を計算します。標準偏差が大きいほどバースティネスが高いことを示します。最新のAI検出ツールWinston AIやPangramは、単なる単語数だけでなく統語的複雑さ(節・句・文法要素の配置)も解析します。人間は単文・重文・複文・重複文など様々な文構造を予測不能なパターンで使い分けますが、AIモデルは訓練データで頻出する特定のテンプレートを好む傾向があります。
| 指標 | バースティネス | パープレキシティ | 測定の焦点 |
|---|---|---|---|
| 定義 | 文の長さ・構造の変化 | 各単語の予測困難度 | 文レベル vs. 単語レベル |
| 人間の文章 | 高い(多様な構造) | 高い(予測しにくい単語) | 自然なリズムと語彙 |
| AI生成テキスト | 低い(均一な構造) | 低い(予測しやすい単語) | 統計的な一貫性 |
| 検出への応用 | 構造の単調さを特定 | 単語選択のパターンを特定 | 補完的な検出法 |
| 誤判定リスク | ESLライターで高い | 技術・学術文で高い | いずれも限界あり |
| 算出方法 | 文長の標準偏差 | 確率分布解析 | 数学的アプローチが異なる |
| 単独での信頼性 | 決定的な検出には不十分 | 決定的な検出には不十分 | 組み合わせ時に最適 |
ChatGPT、Claude、Google Geminiなどの大規模言語モデルは、次トークン予測と呼ばれる学習で、直前の単語列に続く最も確率の高い単語を予測するよう訓練されています。この過程で、モデルは訓練データ上のパープレキシティ(予測困難度)を最小化するよう最適化され、その副産物としてバースティネスが低くなります。ある文構造が訓練データに頻出すれば、モデルはその構造を高確率で再現し、文長が一貫しやすくなります。Netus AIやWinston AIの研究によれば、AIモデルには均一な文構造、接続詞の多用(「Furthermore」「Therefore」「Additionally」など)、受動態の好みといった特徴的なスタイロメトリーが見られます。確率分布に頼るため、モデルは多様性よりも訓練データで最も一般的なパターンを再現しがちです。その結果、訓練データが多いほど一般的パターンの再生が強化され、バースティネスが低下するという逆説が生まれます。また、AIモデルは人間のような自発性や感情のバリエーションを持たず、強調や感情による文体変化が現れません。一貫した文体的平均値を保ち、訓練分布の中心を反映します。
AI検出プラットフォームは、バースティネス分析を検出アルゴリズムの中核要素として取り入れてきましたが、その洗練度はさまざまです。初期の検出システムは、バースティネスとパープレキシティに大きく依存していましたが、近年その限界も明らかになりました。Pangram Labsによれば、パープレキシティやバースティネスに基づく検出は、特に言語モデルの訓練データ由来のテキスト(例:独立宣言)が頻繁にAI生成と誤判定されることがあります。最新のWinston AIやPangramは、バースティネス分析とディープラーニングを組み合わせたハイブリッド方式を採用し、人間とAI生成テキストの多様なサンプルで学習しています。これらのシステムは、文構造の変化、語彙の多様性、句読点パターン、文脈一貫性、意味的整合性など複数の言語的側面を同時に分析します。バースティネスを広範な検出フレームワークに統合することで、Winston AIはAIと人間の文章を99.98%の精度で区別できると報告しています。ただし、バースティネスはあくまで包括的な検出戦略の一要素として有効であり、パープレキシティや文体パターン、意味的一貫性との組み合わせが重要です。
バースティネスと可読性の関係は言語研究で広く認められています。Flesch Reading EaseやFlesch-Kincaid Grade Levelなどの可読性スコアは、バースティネスパターンと強く相関します。バースティネスが高いテキストは、文の長さが変化することで読者の認知的負荷を分散し、注意力を維持しやすくなるため、可読性スコアが向上します。逆に文のリズムが均一だと、脳がパターンに慣れてしまい、注意散漫や理解度低下につながります。一方、高いバースティネスは「波のある効果」を生み、短文で素早く情報を伝え、長文で複雑な内容やニュアンスを展開することで読者を引き込めます。Metrics Mastersの研究では、バースティネスが高いと記憶保持率が15〜20%向上することが示されており、長期記憶への定着にも有効です。この原理はブログ、学術論文、マーケティングコピー、技術文書など多様なコンテンツに当てはまります。ただし、バースティネスが高すぎて文脈や明瞭性を損なうと、逆に読みにくくなります。最適なのは意味や意図に即した目的的な変化を行うことであり、単なる指標値のための変化ではありません。
AI検出で広く使われている一方で、バースティネスベースの検出には重要な限界があることを理解する必要があります。Pangram Labsの研究は主な5つの課題を指摘しています。第一に、AI訓練データ由来のテキストはパープレキシティ最適化によりAI生成と誤判定されやすい点。第二に、バースティネス値はモデルごとに相対的であり、異なるモデル間でパープレキシティプロファイルも異なる点。第三に、ChatGPTのようなクローズドソース商用モデルはトークン確率を公開せず、パープレキシティ計算ができない点。第四に、非ネイティブ英語話者が均一な文構成を使いがちなためAI生成と誤判定されやすい点。第五に、バースティネスベース検出は追加データによる自己改善ができない点です。スタンフォード大学の2023年TOEFL研究では、非ネイティブ英語の約26%がAI生成と誤判定され、ネイティブ英語では2%にとどまりました。このバイアスは教育現場でのAI検出の倫理的課題となっています。また、マーケティングや学術、技術文書などテンプレート駆動のコンテンツは、スタイル規定や構造的制約により自然にバースティネスが低くなり、これも誤判定の原因となります。こうした限界を受け、バースティネスを唯一絶対の指標とせず、複数のシグナルを組み合わせる高度な検出法が開発されています。
バースティネスのパターンは、執筆ジャンルや文脈ごとに大きく異なります。学術論文(特にSTEM分野)は、明瞭さや精度を優先し、スタイルガイドに従うためバースティネスが低くなります。法律文書や技術仕様書、科学論文も一貫性や予測可能性を重視し、低バースティネスが標準的です。一方、創作・ジャーナリズム・マーケティングコピーはリズムや感情表現、多様なペースを重視し、高いバースティネスを持ちます。文学作品では、文長の劇的な変化で強調や緊張感、物語のテンポをコントロールします。ビジネスコミュニケーションは中間に位置し、明瞭さと興味喚起のバランスを保つため適度なバースティネスを持ちます。Flesch-Kincaid Grade Levelによれば、大学レベルの学術文は長く複雑な文を使う傾向があり、一見バースティネスが低いように見えますが、節の構造や従属関係の多様性で実質的なバースティネスが生まれます。AI検出システムはこうしたジャンル特有の文体慣習も考慮する必要があります。技術マニュアルのように長文が均一な場合、低バースティネスはジャンルに適した選択でありAI生成の証拠ではありません。
バースティネス分析によるAI検出の未来は、限界を認識しつつ、その知見を活用できるより洗練された文脈認識型へ進化しています。大規模言語モデルの高度化に伴い、バースティネスの多様性を意図的に組み込む出力も増加し、バースティネス単独での検出信頼性は低下しています。研究者は、バースティネスだけでなく意味的整合性、事実性、文脈適合性なども組み合わせた適応型検出システムを開発中です。バースティネスや他の人間らしさ指標を高めるAIヒューマナイゼーションツールの登場は、検出と回避の「いたちごっこ」を加速させています。しかし、真に信頼できるAI検出は、最終的には暗号的検証方法や出自追跡に依存すると専門家は予測しています。コンテンツ制作者や企業にとっては、バースティネスを操作する指標としてではなく、人間本来の多様性ある文章スタイルの育成を重視すべきです。AmICitedのモニタリングプラットフォームは、AI生成レスポンスにおけるブランドの現れ方や言語特徴を追跡し、この分野の新境地を開拓しています。AIによるコンテンツ生成・流通が拡大する中、バースティネスや関連指標の理解はブランドの真正性維持、学術的誠実性確保、人間と機械の執筆区別にますます重要となっています。複数シグナル連携型の検出アプローチへの進化は、今後もバースティネスが包括的AI監視システムの一要素として重要であり続けることを示していますが、その役割はより精緻かつ文脈依存型へと変化していくでしょう。
バースティネスとパープレキシティは、AI検出で用いられる補完的な指標です。パープレキシティはテキスト内の個々の単語がどれだけ予測しやすいかを測定し、バースティネスは文書全体にわたる文構造や長さの変化を測定します。人間の文章は一般的にパープレキシティ(予測しにくい単語選択)とバースティネス(多様な文構造)が高く、AI生成テキストは学習データの統計パターンに依存するため、両指標が低くなる傾向があります。
高いバースティネスはリズム感を生み出し、読者の興味や理解を高めます。短く効果的な文と長く複雑な文を交互に使うことで、読者の注意を引きつけ、単調さを防ぎます。研究によれば、多様な文構造は記憶保持を高め、コンテンツをより本物で会話的に感じさせます。逆に、文の長さが均一な低バースティネスは、テキストを機械的で読みにくくし、可読性や読者のエンゲージメントを低下させます。
バースティネスは意図的に文構造を変化させて高めることができますが、不自然な文章となり、他の検出アルゴリズムに引っかかる可能性があります。最新のAI検出はバースティネスだけでなく、意味的一貫性や文脈適合性、スタイロメトリックパターンなど複数の言語的特徴を分析します。本物のバースティネスは人間の自然な文章から生まれ、書き手固有の声を反映しますが、無理な変化は人間らしさを欠きます。
非ネイティブ英語話者は語彙が限られ、単純な文構造を使う傾向があるため、バースティネスのスコアが低くなりがちです。言語学習者は習熟度が高まるまでは、複雑な節や多様な統語パターンを避け、均一で予測しやすい文を用いる傾向があります。そのため、AI生成テキストと類似したスタイロメトリープロファイルとなり、AI検出システムで誤判定が起きやすくなります。スタンフォード大学による2023年のTOEFLエッセイ研究でも、このバイアスとバースティネス検出法の限界が指摘されています。
大規模言語モデルは、大量のデータセットから統計パターンを学習し、次に来る単語を予測するよう訓練されています。この訓練過程でパープレキシティを最小化するよう最適化されるため、結果的に文の構造や長さが均一化されてしまいます。つまり、モデルはデータ内で頻出する文構造を再現しやすく、バースティネスが低くなります。確率分布に基づいた出力は多様性よりも一貫性を優先し、人間のような自発的な文構成が現れにくいのです。
AmICitedは、ChatGPT、Perplexity、Google AI Overviewsなどのプラットフォーム上で、ブランドやドメインがAI生成レスポンスにどのように現れるかを追跡します。バースティネスの理解は、AmICitedのモニタリングシステムが人間による引用とAI生成コンテンツによる引用を区別する手助けになります。他の言語指標と組み合わせてバースティネスを分析することで、ブランドが本物の人間によるコンテンツで引用されているのか、AI生成レスポンスで現れているのかを精度高く把握できます。
ライターは明確さや目的を損なわずに文構造を意識的に変化させることで、バースティネスを自然に高めることができます。方法としては、単純な平叙文と複雑な従位節を含む文を交互に使ったり、強調のために断片的な文やダッシュを用いたり、段落の長さを変えることが挙げられます。重要なのは、変化を内容の意味や意図に合わせて活用することであり、単なる数値のために変化を優先しすぎないことです。音読や多様な文体の研究、リズムに注意を払った推敲も有効です。
ChatGPT、Perplexity、その他のプラットフォームでAIチャットボットがブランドを言及する方法を追跡します。AI存在感を向上させるための実用的なインサイトを取得します。
AI生成コンテンツにおけるバースティネスの意味、人間の文章パターンとの違い、そしてAI検出やコンテンツの信頼性における重要性を解説します。...
AIコンテンツ検出におけるバースティネスについてのコミュニティディスカッション ― その意味、AIの可視性への影響、そしてコンテンツ制作者が最適化すべきかどうか。...
BERTの概要、アーキテクチャ、用途、現在の関連性について学びます。BERTと最新の代替技術を比較し、なぜNLPタスクに不可欠であり続けるのかを理解しましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.