Vad är Burstiness i AI-innehåll och Hur Påverkar Det Upptäckt
Lär dig vad burstiness innebär i AI-genererat innehåll, hur det skiljer sig från mänskliga skrivmönster och varför det är viktigt för AI-upptäckt och innehållet...
8 min läsning
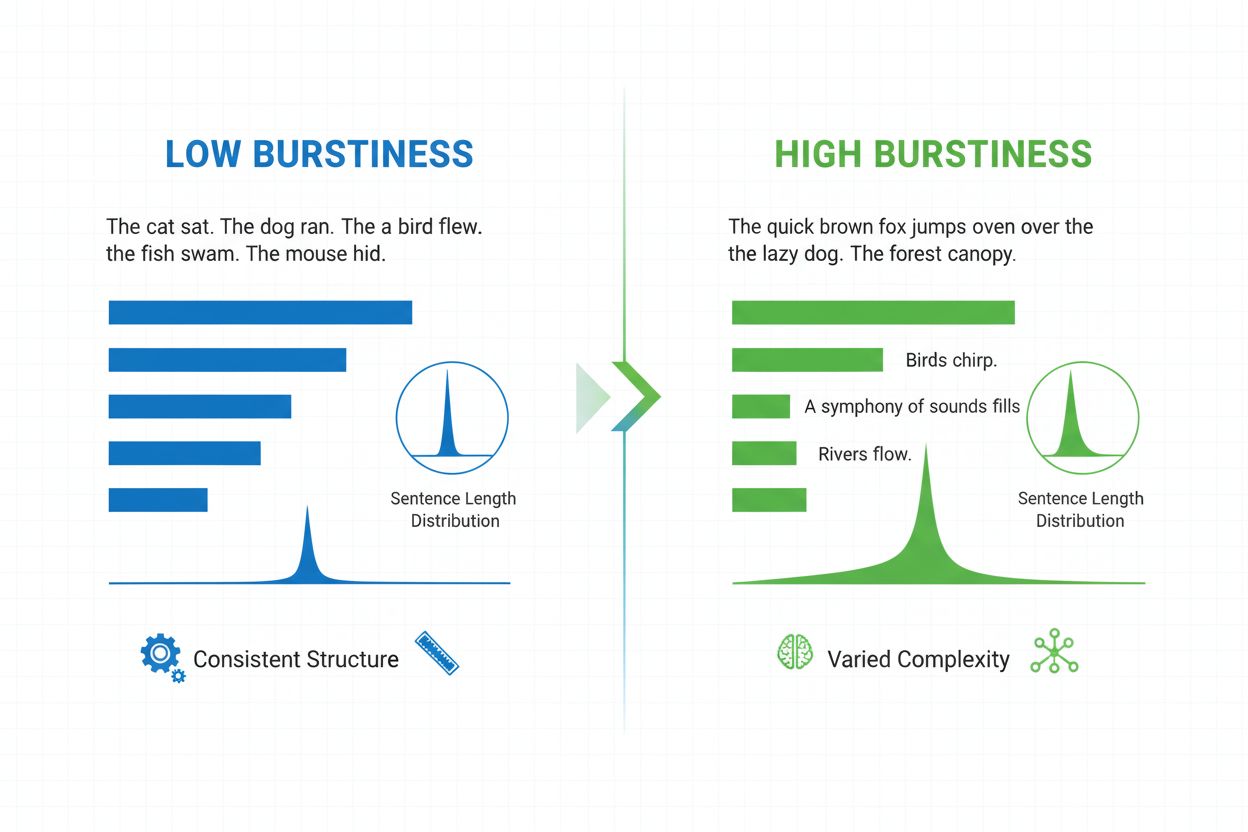
Burstiness är en lingvistisk måttstock som mäter variationen i meningslängd, struktur och komplexitet genom ett dokument. Det kvantifierar hur mycket en skribent växlar mellan korta, slagkraftiga meningar och längre, mer komplexa, och fungerar som en viktig indikator vid AI-genererat innehållsdetektion och analys av naturligt språk.
Burstiness är en lingvistisk måttstock som mäter variationen i meningslängd, struktur och komplexitet genom ett dokument. Det kvantifierar hur mycket en skribent växlar mellan korta, slagkraftiga meningar och längre, mer komplexa, och fungerar som en viktig indikator vid AI-genererat innehållsdetektion och analys av naturligt språk.
Burstiness är ett kvantifierbart lingvistiskt mått som mäter variationen och fluktuationen i meningslängd, struktur och komplexitet genom ett skrivet dokument eller textstycke. Begreppet härstammar från idén om “burst” av varierande meningsmönster—växling mellan korta, koncisa meningar och längre, mer intrikata. I sammanhanget av naturlig språkbehandling och AI-innehållsdetektion fungerar burstiness som en kritisk indikator på om texten är skriven av en människa eller genererad av ett artificiellt intelligenssystem. Mänskliga skribenter producerar naturligt text med hög burstiness eftersom de instinktivt varierar sin meningsuppbyggnad baserat på betoning, tempo och stilistisk avsikt. Däremot uppvisar AI-genererad text typiskt låg burstiness eftersom språkmodeller tränas på statistiska mönster som gynnar konsekvens och förutsägbarhet. Att förstå burstiness är avgörande för innehållsskapare, utbildare, forskare och organisationer som övervakar AI-genererat innehåll på plattformar som ChatGPT, Perplexity, Google AI Overviews och Claude.
Begreppet burstiness uppstod ur forskning inom datalingvistik och informationsteori, där forskare försökte kvantifiera de statistiska egenskaperna hos naturligt språk. Tidigt arbete inom stilometri—statistisk analys av skrivstil—identifierade att mänskligt skrivande uppvisar karakteristiska variationsmönster som fundamentalt skiljer sig från maskingenererad text. När stora språkmodeller (LLM) blev allt mer sofistikerade under tidiga 2020-talet, insåg forskare att burstiness tillsammans med perplexity (ett mått på ordförutsägbarhet) kunde fungera som en tillförlitlig indikator på AI-genererat innehåll. Enligt forskning från QuillBot och akademiska institutioner använder nu cirka 78 % av företagen AI-drivna verktyg för innehållsövervakning som inkluderar burstiness-analys som en del av sina detekteringsalgoritmer. Stanford Universitys studie 2023 om TOEFL-uppsatser visade att burstiness-baserade detektionsmetoder, även om de är användbara, har betydande begränsningar—särskilt vad gäller falska positiva för icke-infödda engelsktalande. Denna forskning har drivit utvecklingen av mer sofistikerade, flerlagerbaserade AI-detekteringssystem som tar hänsyn till burstiness tillsammans med andra lingvistiska markörer, semantisk koherens och kontextuell lämplighet.
Burstiness beräknas genom att analysera den statistiska fördelningen av meningslängder och strukturella mönster i en text. Måttet kvantifierar variansen—mäter alltså hur mycket enskilda meningar avviker från den genomsnittliga meningslängden i ett dokument. Ett dokument med hög burstiness innehåller meningar som varierar kraftigt i längd; till exempel kan en skribent följa upp en treordsmening (“Ser du?”) med en tjugofem ord lång mening med flera satser och bisatser. Däremot indikerar låg burstiness att de flesta meningar grupperar sig kring liknande längd, oftast mellan tolv och arton ord, vilket skapar en monoton rytm. Beräkningen sker i flera steg: först mäts varje menings längd i ord; därefter beräknas medelvärdet (genomsnittlig meningslängd); sedan beräknas standardavvikelsen för att avgöra hur mycket enskilda meningar avviker från medelvärdet. En högre standardavvikelse indikerar större variation och därmed högre burstiness. Moderna AI-detektorer som Winston AI och Pangram använder sofistikerade algoritmer som inte bara räknar ord utan även analyserar syntaktisk komplexitet—den strukturella arrangeringen av satser, fraser och grammatiska element. Denna djupanalys visar att mänskliga skribenter använder olika meningsstrukturer (enkla, sammansatta, komplexa och sammansatt-komplexa meningar) i oförutsägbara mönster, medan AI-modeller tenderar att föredra särskilda strukturella mallar som ofta förekommer i deras träningsdata.
| Mått | Burstiness | Perplexity | Mätfokus |
|---|---|---|---|
| Definition | Variation i meningslängd och struktur | Förutsägbarhet för enskilda ord | Meningsnivå kontra ordnivå |
| Mänskligt skrivande | Hög (varierade strukturer) | Hög (oförutsägbara ord) | Naturlig rytm och ordförråd |
| AI-genererad text | Låg (enhetliga strukturer) | Låg (förutsägbara ord) | Statistisk konsekvens |
| Detektionsanvändning | Identifierar strukturell monotoni | Identifierar ordvalsmönster | Kompletterande detektionsmetoder |
| Risk för falska positiva | Högre för ESL-skribenter | Högre för tekniskt/akademiskt skrivande | Båda har begränsningar |
| Beräkningsmetod | Standardavvikelse för meningslängder | Sannolikhetsfördelningsanalys | Olika matematiska metoder |
| Tillförlitlighet ensam | Otillräcklig för definitiv detektion | Otillräcklig för definitiv detektion | Mest effektivt i kombination |
Stora språkmodeller som ChatGPT, Claude och Google Gemini tränas genom en process som kallas nästa-token-prediktion, där modellen lär sig förutsäga det mest statistiskt sannolika ordet som följer på en given sekvens. Under träningen optimeras dessa modeller uttryckligen för att minimera perplexity på sina träningsdata, vilket oavsiktligt ger upphov till låg burstiness som biprodukt. När en modell stöter på en viss meningsstruktur upprepade gånger i sin träningsdata, lär den sig att återskapa den strukturen med hög sannolikhet, vilket leder till konsekvent, förutsägbar meningslängd. Forskning från Netus AI och Winston AI visar att AI-modeller uppvisar ett karakteristiskt stilometriskt fingeravtryck kännetecknat av enhetlig meningsuppbyggnad, överanvändning av övergångsfraser (såsom “Furthermore”, “Therefore”, “Additionally”) och en preferens för passiv framför aktiv röst. Modellernas beroende av sannolikhetsfördelningar innebär att de dras mot de vanligaste mönstren i träningsdata snarare än att utforska hela spektrumet av möjliga meningskonstruktioner. Detta skapar en paradox: ju mer data en modell tränas på, desto mer lär den sig att återskapa vanliga mönster, och därmed blir burstinessen lägre. Dessutom saknar AI-modeller spontanitet och känslomässig variation som kännetecknar mänskligt skrivande—de skriver inte annorlunda när de är entusiastiska, frustrerade eller vill betona något särskilt. Istället bibehåller de en konsekvent stilistisk baslinje som speglar den statistiska mittpunkten av sin träningsfördelning.
AI-detekteringsplattformar har införlivat burstiness-analys som en kärnkomponent i sina detekteringsalgoritmer, dock med varierande sofistikationsgrad. Tidiga detekteringssystem förlitade sig i hög grad på burstiness och perplexity som primära mått, men forskning har visat på betydande begränsningar med denna metod. Enligt Pangram Labs genererar perplexity- och burstiness-baserade detektorer falska positiva vid analys av text från språkmodellernas träningsdata—främst flaggas självständighetsförklaringen ofta som AI-genererad eftersom den förekommer så ofta i träningsdata att modellen tilldelar den konsekvent låg perplexity. Moderna detekteringssystem som Winston AI och Pangram använder nu hybridmetoder som kombinerar burstiness-analys med djupinlärningsmodeller tränade på olika mänskliga och AI-genererade textprover. Dessa system analyserar flera lingvistiska dimensioner samtidigt: variation i meningsstruktur, lexikal diversitet (ordrikedom), skiljeteckensmönster, kontextuell koherens och semantisk överensstämmelse. Integreringen av burstiness i bredare detektionsramverk har förbättrat noggrannheten avsevärt—Winston AI rapporterar 99,98 % noggrannhet i att skilja AI-genererat från mänskligt skrivet innehåll genom att analysera flera markörer istället för att enbart förlita sig på burstiness. Dock förblir måttet värdefullt som en komponent i en övergripande detektionsstrategi, särskilt i kombination med analys av perplexity, stilometriska mönster och semantisk konsekvens.
Sambandet mellan burstiness och läsbarhet är väl etablerat inom lingvistisk forskning. Flesch Reading Ease och Flesch-Kincaid Grade Level, som mäter textens tillgänglighet, korrelerar starkt med burstiness-mönster. Text med högre burstiness tenderar att uppnå bättre läsbarhet eftersom varierad meningslängd förhindrar mental utmattning och bibehåller läsarens uppmärksamhet. När läsare möter ett konsekvent tempo av likartade meningar anpassar sig hjärnan till ett förutsägbart mönster, vilket kan leda till ointresse och försämrad förståelse. Däremot skapar hög burstiness en ebb-och-flod-effekt som håller läsaren mentalt engagerad genom att variera den kognitiva belastningen—korta meningar ger snabb, lättsmält information, medan längre meningar möjliggör utveckling av komplexa idéer och nyanser. Forskning från Metrics Masters visar att hög burstiness genererar cirka 15–20 % bättre minnesretention jämfört med låg-burstiness-text, eftersom den varierade rytmen hjälper till att effektivt lagra information i långtidsminnet. Denna princip gäller alla innehållstyper: blogginlägg, akademiska artiklar, marknadsföringstexter och teknisk dokumentation tjänar alla på strategisk burstiness. Sambandet är dock inte linjärt—överdriven burstiness som prioriterar variation framför tydlighet kan göra texten hackig och svår att följa. Den optimala strategin innebär avsiktlig variation där val av meningsstruktur stöder innehållets mening och skribentens kommunikativa syfte snarare än existerar enbart för att höja ett mått.
Trots dess utbredda användning i AI-detekteringssystem har burstiness-baserad detektion betydande begränsningar som forskare och praktiker måste förstå. Pangram Labs publicerade omfattande forskning som visar fem huvudsakliga brister: för det första klassificeras text från AI-träningsdata felaktigt som AI-genererad eftersom modellerna optimeras för att minimera perplexity på träningsdata; för det andra är burstiness-värden relativa till specifika språkmodeller, så olika modeller ger olika perplexity-profiler; för det tredje exponerar slutna kommersiella modeller som ChatGPT inte token-sannolikheter, vilket gör perplexity-beräkning omöjlig; för det fjärde flaggas icke-infödda engelsktalande oproportionerligt ofta som AI-genererade på grund av deras mer enhetliga meningsstruktur; och för det femte kan burstiness-baserade detektorer inte iterativt förbättras med mer data. Stanford 2023-studien om TOEFL-uppsatser fann att cirka 26 % av icke-infödda engelska texter felaktigt flaggades som AI-genererade av perplexity- och burstiness-baserade detektorer, jämfört med endast 2 % falska positiva för inhemsk engelska. Denna bias väcker allvarliga etiska frågor i utbildningssammanhang där AI-detektion används för att utvärdera studentarbete. Dessutom uppvisar mallbaserat innehåll inom marknadsföring, akademiskt skrivande och teknisk dokumentation naturligt lägre burstiness på grund av stilguidekrav och strukturella konventioner, vilket leder till falska positiva i dessa domäner. Dessa begränsningar har lett till utvecklingen av mer sofistikerade detektionsmetoder där burstiness behandlas som en signal bland många snarare än som en avgörande indikator på AI-generering.
Burstiness-mönster varierar avsevärt mellan olika genrer och skrivsammanhang, vilket speglar de särskilda kommunikativa syftena och publikens förväntningar i varje domän. Akademiskt skrivande, särskilt inom STEM-ämnen, tenderar att uppvisa lägre burstiness eftersom författare följer strikt stilguide och använder konsekventa strukturella mallar för tydlighet och precision. Juridiska dokument, tekniska specifikationer och vetenskapliga artiklar prioriterar alla konsekvens och förutsägbarhet framför stilistisk variation, vilket resulterar i naturligt lägre burstiness-värden. Däremot uppvisar kreativt skrivande, journalistik och marknadsföringstexter ofta hög burstiness eftersom dessa genrer sätter läsarengagemang och emotionell påverkan i centrum, bland annat genom varierat tempo och rytm. Skönlitteratur använder särskilt dramatiska förändringar i meningslängd för att skapa emfas, bygga upp spänning och styra berättartempot. Affärskommunikation hamnar mitt emellan—professionella mejl och rapporter håller måttlig burstiness för att balansera tydlighet och engagemang. Flesch-Kincaid Grade Level visar att akademiskt skrivande för högskoleutbildad publik ofta använder längre, mer komplexa meningar, vilket kan se ut att minska burstiness; dock skapar variationen i satsstruktur och underordning ändå meningsfull burstiness. Att förstå dessa kontextuella variationer är avgörande för AI-detekteringssystem, eftersom de måste ta hänsyn till genrespecifika skrivkonventioner för att undvika falska positiva. En teknisk manual med enhetligt långa meningar bör inte flaggas som AI-genererad enbart för att den uppvisar låg burstiness—den låga burstinessen speglar lämpliga stilistiska val för genren snarare än maskininnehåll.
Framtiden för burstiness-analys vid AI-detektion utvecklas mot mer sofistikerade, kontextmedvetna metoder som erkänner måttets begränsningar men samtidigt utnyttjar dess insikter. Allt eftersom stora språkmodeller blir mer avancerade börjar de införliva burstiness-variation i sina utdata, vilket gör det mindre tillförlitligt att enbart använda detta mått för detektion. Forskare utvecklar adaptiva detekteringssystem som analyserar burstiness i kombination med semantisk koherens, faktuell korrekthet och kontextuell lämplighet. Framväxten av AI-humaniseringsverktyg som avsiktligt ökar burstiness och andra mänskliga drag representerar en pågående kapplöpning mellan detektion och undvikandeteknik. Experter förutspår dock att verkligt tillförlitlig AI-detektion i slutändan kommer att bero på kryptografisk verifiering och ursprungsspårning snarare än enbart lingvistisk analys. För innehållsskapare och organisationer är den strategiska implikationen tydlig: istället för att se burstiness som ett mått att manipulera eller utnyttja bör skribenter fokusera på att utveckla autentiska, varierade skrivstilar som naturligt speglar mänsklig kommunikation. AmICiteds övervakningsplattform representerar en ny front i detta område, genom att spåra hur varumärken syns i AI-genererade svar och analysera de lingvistiska egenskaperna hos dessa omnämnanden. När AI-system blir allt vanligare inom innehållsgenerering och distribution blir förståelsen för burstiness och relaterade mått allt viktigare för att bibehålla varumärkesautenticitet, säkerställa akademisk integritet och upprätthålla skillnaden mellan mänskligt och maskinellt innehåll. Utvecklingen mot flersignaldetektering antyder att burstiness kommer att förbli relevant som en komponent i omfattande AI-övervakningssystem, även om dess roll blir mer nyanserad och kontextberoende.
Börja spåra hur AI-chatbotar nämner ditt varumärke på ChatGPT, Perplexity och andra plattformar. Få handlingsbara insikter för att förbättra din AI-närvaro.
Lär dig vad burstiness innebär i AI-genererat innehåll, hur det skiljer sig från mänskliga skrivmönster och varför det är viktigt för AI-upptäckt och innehållet...
Diskussion i communityn om burstiness i AI-innehållsdetektering – vad det betyder, hur det påverkar AI-synlighet och om innehållsskapare bör optimera för det....
Lär dig vad läsbarhetspoäng betyder för AI-sök-synlighet. Upptäck hur Flesch-Kincaid, meningsstruktur och innehållsformatering påverkar AI-citeringar i ChatGPT,...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.