
De Complete Gids voor het Blokkeren (of Toestaan) van AI Crawlers
Leer hoe je AI-crawlers zoals GPTBot en ClaudeBot kunt blokkeren of toestaan met robots.txt, server-side blokkades en geavanceerde beschermingsmethoden. Volledi...
6 min lezen

Leer hoe je een audit uitvoert op AI-crawler toegang tot je website. Ontdek welke bots jouw content kunnen zien en los blokkades op die AI-zichtbaarheid in ChatGPT, Perplexity en andere AI-zoekmachines verhinderen.
Het landschap van zoeken en contentontdekking verandert drastisch. Met AI-aangedreven zoektools zoals ChatGPT, Perplexity en Google AI Overviews die exponentieel groeien, is de zichtbaarheid van je content voor AI-crawlers net zo belangrijk geworden als traditionele zoekmachine-optimalisatie. Als AI-bots je content niet kunnen bereiken, wordt je site onzichtbaar voor miljoenen gebruikers die op deze platforms vertrouwen voor antwoorden. De inzet is hoger dan ooit: terwijl Google je site opnieuw kan bezoeken als er iets misgaat, werken AI-crawlers volgens een ander paradigma—en het missen van die eerste cruciale crawl kan maanden aan verloren zichtbaarheid en gemiste kansen op citaties, verkeer en merkautoriteit betekenen.
AI-crawlers werken volgens fundamenteel andere regels dan de Google- en Bing-bots waar je jarenlang voor hebt geoptimaliseerd. Het belangrijkste verschil: AI-crawlers renderen geen JavaScript, wat betekent dat dynamische content die via client-side scripts wordt geladen voor hen onzichtbaar is—een scherp contrast met de geavanceerde renderingmogelijkheden van Google. Bovendien bezoeken AI-crawlers sites met een veel hogere frequentie, soms wel 100 keer vaker dan traditionele zoekmachines, wat zowel kansen als uitdagingen voor serverbronnen oplevert. In tegenstelling tot het indexeringsmodel van Google, onderhouden AI-crawlers geen blijvende index die wordt vernieuwd; ze crawlen op aanvraag wanneer gebruikers hun systemen bevragen. Dit betekent: geen herindexeringswachtrij, geen Search Console om opnieuw crawlen aan te vragen en geen tweede kansen als je site die eerste indruk mist. Deze verschillen begrijpen is essentieel voor het optimaliseren van je contentstrategie.
| Kenmerk | AI-crawlers | Traditionele bots |
|---|---|---|
| JavaScript-rendering | Nee (alleen statische HTML) | Ja (volledige rendering) |
| Crawl-frequentie | Zeer hoog (100x+ vaker) | Gemiddeld (wekelijks/maandelijks) |
| Herindexeringsmogelijkheid | Geen (alleen on-demand) | Ja (doorlopende updates) |
| Contentvereisten | Platte HTML, schema markup | Flexibel (kan dynamische content aan) |
| User-Agent blokkeren | Specifiek per bot (GPTBot, ClaudeBot, etc.) | Generiek (Googlebot, Bingbot) |
| Caching-strategie | Korte termijn snapshots | Lange termijn indexonderhoud |
Je content kan onzichtbaar zijn voor AI-crawlers om redenen waar je misschien nooit aan hebt gedacht. Dit zijn de belangrijkste obstakels die AI-bots verhinderen om je content te bereiken en te begrijpen:
Je robots.txt-bestand is het primaire middel om te bepalen welke AI-bots toegang krijgen tot je content, en werkt via specifieke User-Agent regels die individuele crawlers aansturen. Elk AI-platform gebruikt unieke user-agent strings—OpenAI’s GPTBot, Anthropic’s ClaudeBot, Perplexity’s PerplexityBot—en je kunt ze allemaal afzonderlijk toestaan of blokkeren. Deze gedetailleerde controle stelt je in staat te bepalen welke AI-systemen jouw content mogen trainen of citeren, wat cruciaal is voor het beschermen van eigendomsinformatie of het beheren van concurrentiegevoeligheid. Veel sites blokkeren echter onbewust AI-crawlers via te brede regels die voor oudere bots bedoeld waren, of hebben helemaal geen goede regels ingesteld.
Hier is een voorbeeld van hoe je robots.txt inricht voor verschillende AI-bots:
# OpenAI's GPTBot toestaan
User-agent: GPTBot
Allow: /
# Anthropic's ClaudeBot blokkeren
User-agent: ClaudeBot
Disallow: /
# Perplexity toestaan maar bepaalde mappen beperken
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# Standaardregel voor alle andere bots
User-agent: *
Allow: /
In tegenstelling tot Google, die je site continu crawlt en herindexeert, werken AI-crawlers op basis van eenmalige bezoeken—ze komen wanneer een gebruiker hun systeem bevragen, en als je content op dat moment niet bereikbaar is, ben je de kans kwijt. Dit fundamentele verschil betekent dat je site technisch vanaf dag één op orde moet zijn; er is geen respijtperiode, geen tweede kans om fouten te herstellen voordat je zichtbaarheid daalt. Een slechte eerste crawl—door JavaScript-problemen, ontbrekende schema markup of serverfouten—kan ervoor zorgen dat je content weken- of maandenlang wordt uitgesloten van AI-gegenereerde antwoorden. Er is geen handmatige herindexering, geen ‘Indexering aanvragen’-knop in een console, waardoor proactieve monitoring en optimalisatie onmisbaar zijn. De druk om het in één keer goed te doen is nog nooit zo groot geweest.
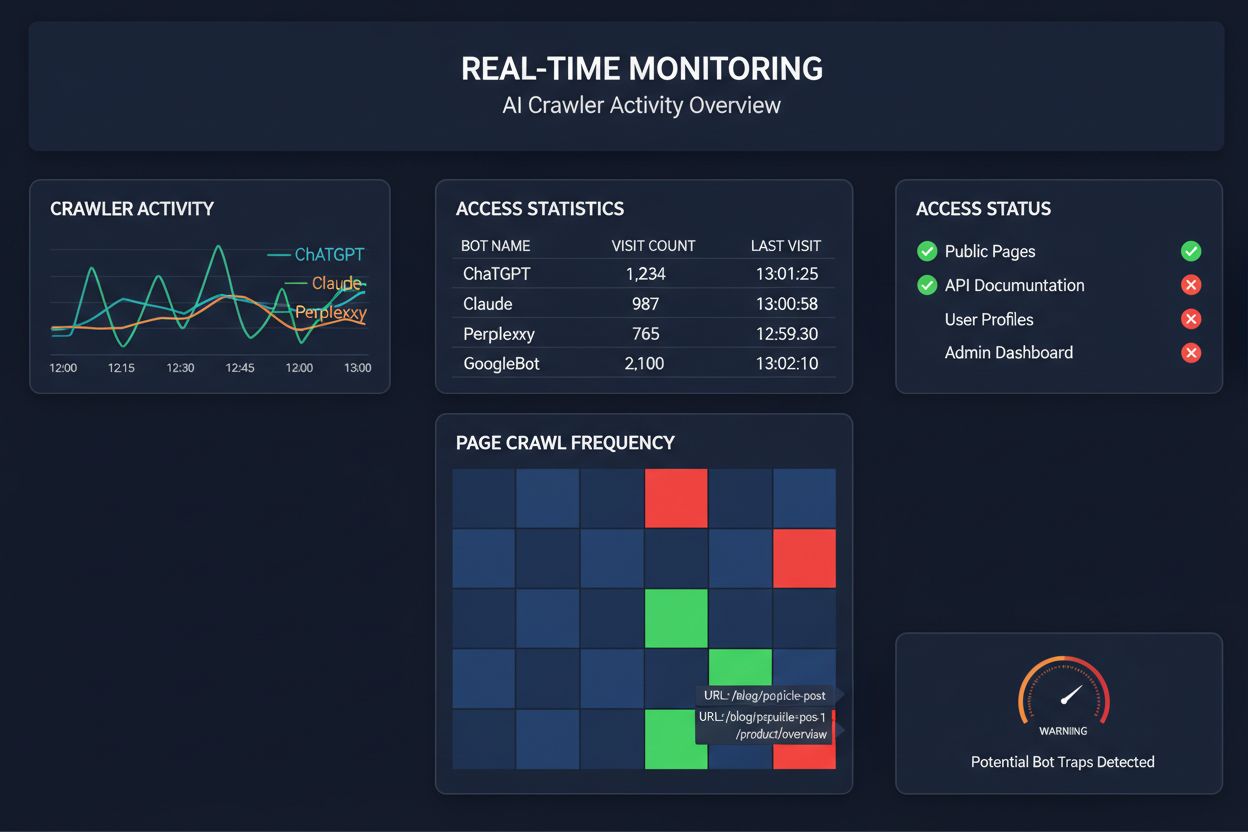
Vertrouwen op geplande crawls om AI-crawler toegang te monitoren is alsof je eens per maand je huis controleert op brand—je mist de kritieke momenten waarop problemen ontstaan. Realtime monitoring signaleert direct problemen zodra ze zich voordoen, zodat je kunt ingrijpen voordat je content onzichtbaar wordt voor AI-systemen. Geplande audits, die meestal wekelijks of maandelijks worden uitgevoerd, creëren gevaarlijke blinde vlekken waarin je site dagenlang kan falen voor AI-crawlers zonder dat je het merkt. Realtime oplossingen volgen het gedrag van crawlers continu, en waarschuwen je direct bij JavaScript-fouten, schema markup problemen, firewallblokkades of serverproblemen. Deze proactieve aanpak verandert je audit van een reactieve compliance-check in actief zichtbaarheidsbeheer. Met AI-crawler verkeer dat mogelijk 100 keer hoger ligt dan bij traditionele zoekmachines, kan het missen van zelfs enkele uren toegankelijkheid grote gevolgen hebben.
Er zijn inmiddels diverse platforms die gespecialiseerde tools bieden voor het monitoren en optimaliseren van AI-crawler toegang. Cloudflare AI Crawl Control biedt infrastructuurniveau beheer van AI-bot verkeer, waarmee je limieten en toegangsbeleid kunt instellen. Conductor biedt uitgebreide monitoringdashboards die tonen hoe verschillende AI-crawlers met je content omgaan. Elementive richt zich op technische SEO-audits met specifieke aandacht voor AI-crawler vereisten. AdAmigo en MRS Digital leveren gespecialiseerde consultancy en monitoring voor AI-zichtbaarheid. Voor continue, realtime monitoring die specifiek is ontworpen om AI-crawler gedrag te volgen en je te waarschuwen voor problemen voordat ze je zichtbaarheid schaden, springt AmICited eruit als een toegewijde oplossing. AmICited richt zich op het monitoren van welke AI-systemen je content bezoeken, hoe vaak ze crawlen en of ze technische barrières tegenkomen. Deze focus op AI-crawler gedrag—in plaats van traditionele SEO-metrics—maakt het een essentieel hulpmiddel voor organisaties die serieus zijn over AI-zichtbaarheid.
Het uitvoeren van een grondige AI-crawler audit vereist een systematische aanpak. Stap 1: Bepaal een nulmeting door je huidige robots.txt te controleren en te inventariseren welke AI-bots je nu toestaat of blokkeert. Stap 2: Audit je technische infrastructuur door de toegankelijkheid van je site te testen met crawlers zonder JavaScript, te controleren op serverreactietijden en te verifiëren dat essentiële content in statische HTML wordt aangeboden. Stap 3: Implementeer en valideer schema markup in je content, zodat auteurschap, publicatiedata, contenttype en andere metadata goed gestructureerd zijn in JSON-LD. Stap 4: Monitor crawler gedrag met tools zoals AmICited om te volgen welke AI-bots je site bezoeken, hoe vaak en of ze fouten tegenkomen. Stap 5: Analyseer de resultaten door crawllogs te beoordelen, patronen van fouten te identificeren en herstelacties te prioriteren op basis van impact. Stap 6: Implementeer oplossingen te beginnen met de belangrijkste problemen zoals JavaScript-rendering of ontbrekende schema, gevolgd door secundaire optimalisaties. Stap 7: Zorg voor doorlopende monitoring om nieuwe problemen tijdig te signaleren, en stel waarschuwingen in voor crawl-fouten of toegangsblokkades.
Je hoeft geen volledige herbouw te doen om AI-crawler toegang te verbeteren—er zijn verschillende effectieve aanpassingen die je snel kunt doorvoeren. Zorg dat essentiële content in platte HTML wordt aangeboden en niet alleen via JavaScript; als je JavaScript gebruikt, zorg dan dat belangrijke tekst en metadata ook in de initiële HTML staan. Voeg uitgebreide schema markup toe met JSON-LD, inclusief artikel-schema, auteursinformatie, publicatiedata en contentrelaties—dit helpt AI-crawlers om context te begrijpen en content correct toe te schrijven. Zorg voor duidelijke auteursinformatie via schema en bylines, want AI-systemen geven steeds vaker prioriteit aan betrouwbare bronnen. Monitor en optimaliseer Core Web Vitals (Largest Contentful Paint, First Input Delay, Cumulative Layout Shift), omdat traag ladende pagina’s door crawlers kunnen worden verlaten voor ze klaar zijn met verwerken. Controleer en actualiseer je robots.txt om te zorgen dat je niet per ongeluk AI-bots blokkeert die je juist wilt toelaten. Los technische problemen op zoals redirect-ketens, gebroken links en serverfouten die kunnen leiden tot voortijdige crawler-afbreking.
Niet alle AI-crawlers hebben hetzelfde doel, en door deze verschillen te begrijpen kun je beter bepalen wie je toegang geeft. GPTBot (OpenAI) wordt vooral gebruikt voor het verzamelen van trainingsdata en het verbeteren van modelmogelijkheden—relevant als je wilt dat je content ChatGPT’s antwoorden beïnvloedt. OAI-SearchBot (OpenAI) crawlt specifiek voor zoekcitatie, dus deze bot zorgt ervoor dat je content wordt opgenomen in de zoekresultaten van ChatGPT. ClaudeBot (Anthropic) vervult vergelijkbare functies voor Claude, de AI-assistent van Anthropic. PerplexityBot (Perplexity) crawlt voor citatie in de AI-zoekmachine van Perplexity, die voor veel uitgevers een belangrijke verkeersbron is geworden. Elke bot heeft andere crawlpatronen, frequentie en doelen—de een richt zich op trainingsdata, de ander op realtime zoekcitatie. Bepalen welke bots je toestaat of blokkeert, moet aansluiten bij je contentstrategie: wil je citatie in AI-zoekresultaten, sta dan de zoekbots toe; ben je bezorgd over trainingsdata, blokkeer dan dataverzamelbots en laat zoekbots toe. Deze genuanceerde aanpak is veel geavanceerder dan de traditionele “alles toestaan” of “alles blokkeren”-mentaliteit.
Een AI-crawler audit is een uitgebreide beoordeling van de toegankelijkheid van je website voor AI-bots zoals ChatGPT, Claude en Perplexity. Het identificeert technische blokkades, problemen met JavaScript-rendering, ontbrekende schema markup en andere factoren die AI-crawlers verhinderen om je content te bereiken en te begrijpen. De audit geeft concrete aanbevelingen om je zichtbaarheid in door AI aangedreven zoek- en antwoordmachines te verbeteren.
We raden aan om ten minste elk kwartaal een uitgebreide audit uit te voeren, of telkens wanneer je belangrijke wijzigingen aanbrengt aan de technische infrastructuur, contentstructuur of robots.txt van je website. Toch is continue realtime monitoring ideaal om problemen direct te signaleren zodra ze zich voordoen. Veel organisaties gebruiken geautomatiseerde monitoringtools die hen direct waarschuwen bij crawl-fouten, aangevuld met diepgaande kwartaalcontroles.
AI-crawlers toestaan betekent dat je content toegankelijk, analyseerbaar en mogelijk citeerbaar wordt door AI-systemen, wat je zichtbaarheid in door AI gegenereerde antwoorden en aanbevelingen kan vergroten. AI-crawlers blokkeren voorkomt dat ze toegang krijgen tot je content, waardoor je eigendomsinformatie beschermt maar mogelijk je zichtbaarheid in AI-zoekresultaten vermindert. De juiste keuze hangt af van je bedrijfsdoelen, gevoeligheid van de content en concurrentiepositie.
Ja, absoluut. Je robots.txt-bestand biedt gedetailleerde controle via User-Agent regels. Je kunt GPTBot blokkeren terwijl je PerplexityBot toestaat, of zoekgerichte bots (zoals OAI-SearchBot) toestaan en dataverzamelbots (zoals GPTBot) blokkeren. Met deze genuanceerde aanpak optimaliseer je je contentstrategie op basis van welke AI-platforms voor jouw organisatie het belangrijkst zijn.
Als AI-crawlers je content niet kunnen bereiken, is je site in feite onzichtbaar voor door AI aangedreven zoekmachines en antwoordplatformen. Je content wordt niet geciteerd, aanbevolen of opgenomen in AI-gegenereerde antwoorden, zelfs niet als het zeer relevant is. Dit kan leiden tot gemiste bezoekers, verminderde merkzichtbaarheid en gemiste kansen om autoriteit op te bouwen in AI-zoekresultaten.
Je kunt je serverlogs controleren op User-Agent strings van bekende AI-crawlers (GPTBot, ClaudeBot, PerplexityBot, enz.), of gespecialiseerde monitoringtools gebruiken zoals AmICited die AI-crawler activiteit realtime bijhouden. Deze tools tonen welke bots je site bezoeken, hoe vaak ze crawlen, welke pagina’s ze bezoeken en of ze fouten of blokkades tegenkomen.
Dit hangt af van je specifieke situatie. Als je content eigendomsrechtelijk, gevoelig is of je je zorgen maakt over het gebruik van je data voor training, kan blokkeren passend zijn. Als je echter zichtbaar wilt zijn in AI-zoekresultaten en geciteerd wilt worden door AI-systemen, is toestaan essentieel. Veel organisaties kiezen een middenweg: zoekgerichte bots toestaan die citeren stimuleren, terwijl dataverzamelbots worden geblokkeerd.
AI-crawlers renderen geen JavaScript, wat betekent dat alle content die via client-side scripts dynamisch wordt geladen, voor hen onzichtbaar is. Als je site sterk afhankelijk is van JavaScript voor essentiële content, navigatie of gestructureerde data, zien AI-crawlers alleen de ruwe HTML en missen ze belangrijke informatie. Dit kan grote invloed hebben op hoe je content wordt begrepen en weergegeven in AI-antwoorden. Het serveren van essentiële content in statische HTML is cruciaal voor AI-crawlbaarheid.
Krijg realtime inzicht in welke AI-bots jouw content bezoeken en hoe ze jouw website zien. Start vandaag je gratis audit en zorg dat je merk zichtbaar is op alle AI-zoekplatformen.
Leer hoe je AI-crawlers zoals GPTBot en ClaudeBot kunt blokkeren of toestaan met robots.txt, server-side blokkades en geavanceerde beschermingsmethoden. Volledi...

Leer hoe je AI-crawlers zoals GPTBot, ClaudeBot en PerplexityBot in je serverlogs kunt herkennen en monitoren. Volledige gids met user-agent strings, IP-verific...

Leer hoe je AI-crawleractiviteit op je website volgt en monitort met behulp van serverlogs, tools en best practices. Identificeer GPTBot, ClaudeBot en andere AI...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.