
Hoe AI-crawlers identificeren in serverlogs: Complete detectiegids
Leer hoe je AI-crawlers zoals GPTBot, PerplexityBot en ClaudeBot kunt identificeren en monitoren in je serverlogs. Ontdek user-agent strings, IP-verificatiemeth...
8 min lezen

Begrijp hoe AI-crawlers zoals GPTBot en ClaudeBot werken, hun verschillen met traditionele zoekmachine-crawlers en hoe je je site optimaliseert voor AI-zoekzichtbaarheid.
AI-crawlers zijn geautomatiseerde programma’s die zijn ontworpen om systematisch het internet te doorzoeken en gegevens van websites te verzamelen, specifiek om kunstmatige intelligentiemodellen te trainen en te verbeteren. In tegenstelling tot traditionele zoekmachine-crawlers zoals Googlebot, die inhoud indexeren voor zoekresultaten, verzamelen AI-crawlers ruwe webdata om grote taalmodellen (LLM’s) zoals ChatGPT, Claude en andere AI-systemen te voeden. Deze bots zijn continu actief op miljoenen websites, downloaden pagina’s, analyseren content en halen informatie op die AI-platforms helpt taalpatronen, feitelijke informatie en diverse schrijfstijlen te begrijpen. De belangrijkste spelers in deze sector zijn GPTBot van OpenAI, ClaudeBot van Anthropic, Meta-ExternalAgent van Meta, Amazonbot van Amazon en PerplexityBot van Perplexity.ai, elk ten behoeve van hun respectievelijke AI-platforms voor training en operationele doeleinden. Begrijpen hoe deze crawlers werken is essentieel geworden voor website-eigenaren en contentmakers, aangezien AI-zichtbaarheid nu direct bepaalt hoe jouw merk verschijnt in door AI aangedreven zoekresultaten en aanbevelingen.
Het landschap van webcrawling heeft het afgelopen jaar een enorme transformatie ondergaan, waarbij AI-crawlers explosief zijn gegroeid terwijl traditionele zoekmachine-crawlers een stabiel patroon laten zien. Tussen mei 2024 en mei 2025 groeide het totale crawlerverkeer met 18%, maar de verdeling verschoof aanzienlijk—GPTBot steeg met 305% in ruwe verzoeken, terwijl andere crawlers zoals ClaudeBot met 46% daalden en Bytespider met 85% kelderde. Deze herschikking weerspiegelt de toenemende concurrentie tussen AI-bedrijven om trainingsdata te vergaren en hun modellen te verbeteren. Hier volgt een overzicht van de belangrijkste crawlers en hun huidige marktaandeel:
| Crawlernaam | Bedrijf | Maandelijkse verzoeken | YoY-groei | Primair doel |
|---|---|---|---|---|
| Googlebot | 4,5 miljard | 96% | Zoekindexering & AI Overviews | |
| GPTBot | OpenAI | 569 miljoen | 305% | ChatGPT-modeltraining & zoeken |
| Claude | Anthropic | 370 miljoen | -46% | Claude-modeltraining & zoeken |
| Bingbot | Microsoft | ~450 miljoen | 2% | Zoekindexering |
| PerplexityBot | Perplexity.ai | 24,4 miljoen | 157.490% | AI-zoekindexering |
| Meta-ExternalAgent | Meta | ~380 miljoen | Nieuw | Meta AI-training |
| Amazonbot | Amazon | ~210 miljoen | -35% | Zoeken & AI-toepassingen |
De data laat zien dat hoewel Googlebot dominant blijft met 4,5 miljard maandelijkse verzoeken, AI-crawlers samen ongeveer 28% van het volume van Googlebot vertegenwoordigen, waarmee ze een belangrijke kracht zijn in het webverkeer. De explosieve groei van PerplexityBot (157.490% stijging) laat zien hoe snel nieuwe AI-platforms hun crawlingactiviteiten opschalen, terwijl de afname van enkele gevestigde AI-crawlers wijst op een marktconsolidatie rond de meest succesvolle AI-platforms.
GPTBot is de webcrawler van OpenAI, speciaal ontworpen voor het verzamelen van data voor het trainen en verbeteren van ChatGPT en andere OpenAI-modellen. Gestart als een relatief kleine speler met slechts 5% marktaandeel in mei 2024, is GPTBot uitgegroeid tot de dominante AI-crawler en heeft het 30% van al het AI-crawlerverkeer veroverd in mei 2025—een opmerkelijke stijging van 305% in ruwe verzoeken. Deze explosieve groei weerspiegelt de agressieve strategie van OpenAI om ChatGPT toegang te geven tot verse, diverse webcontent voor zowel modeltraining als realtime zoekmogelijkheden via ChatGPT Search. GPTBot werkt met een specifiek crawlpatroon en geeft prioriteit aan HTML-content (57,70% van de verzoeken) terwijl het ook JavaScript-bestanden en afbeeldingen downloadt, hoewel het geen JavaScript uitvoert om dynamische content te renderen. Het gedrag van de crawler laat zien dat hij vaak 404-fouten tegenkomt (34,82% van de verzoeken), wat suggereert dat hij mogelijk verouderde links volgt of probeert bronnen te benaderen die niet meer bestaan. Voor website-eigenaren betekent de dominantie van GPTBot dat het toegankelijk maken van je content voor deze crawler essentieel is geworden voor zichtbaarheid in de zoekfuncties van ChatGPT en mogelijke opname in toekomstige modeltrainingen.
ClaudeBot, ontwikkeld door Anthropic, is de primaire crawler voor het trainen en updaten van de Claude AI-assistent en ondersteunt daarnaast de zoek- en onderbouwingstaken van Claude. Ooit de op één na grootste AI-crawler met 27% marktaandeel in mei 2024, heeft ClaudeBot een duidelijke daling doorgemaakt tot 21% in mei 2025, met een afname van 46% in ruwe verzoeken op jaarbasis. Deze daling wijst niet per se op een probleem met de strategie van Anthropic, maar eerder op een bredere verschuiving naar de dominantie van OpenAI en de opkomst van nieuwe concurrenten zoals Meta-ExternalAgent. ClaudeBot vertoont vergelijkbaar gedrag als GPTBot, met prioriteit voor HTML-content maar met een hoger percentage verzoeken voor afbeeldingen (35,17% van de verzoeken), wat suggereert dat Anthropic Claude mogelijk beter wil laten begrijpen wat betreft visuele content naast tekst. Net als andere AI-crawlers rendert ClaudeBot geen JavaScript, wat betekent dat alleen de ruwe HTML zichtbaar is en niet de dynamisch geladen inhoud. Voor contentmakers blijft zichtbaarheid bij ClaudeBot belangrijk om ervoor te zorgen dat Claude toegang heeft tot en jouw content kan citeren, zeker nu Anthropic blijft werken aan de zoek- en redeneercapaciteiten van Claude.
Naast GPTBot en ClaudeBot zijn er verschillende andere belangrijke AI-crawlers die actief webdata verzamelen voor hun respectievelijke platforms:
Meta-ExternalAgent (Meta): De crawler van Meta maakte een spectaculaire intrede in de top, met 19% marktaandeel in mei 2025 als nieuwkomer. Deze bot verzamelt data voor de AI-initiatieven van Meta, waaronder mogelijke training voor Meta AI en integratie met AI-functies van Instagram en Facebook. De snelle opkomst van Meta suggereert dat het bedrijf serieus inzet op door AI aangedreven zoeken en aanbevelingen.
PerplexityBot (Perplexity.ai): Ondanks slechts 0,2% marktaandeel kende PerplexityBot de snelste groeisnelheid met 157.490% op jaarbasis. Dit weerspiegelt de snelle opschaling van Perplexity als AI-antwoordsysteem dat afhankelijk is van realtime webzoekopdrachten om zijn antwoorden te onderbouwen. Voor websites bieden bezoeken van PerplexityBot directe kansen om geciteerd te worden in AI-gegenereerde antwoorden van Perplexity.
Amazonbot (Amazon): De crawler van Amazon daalde van 21% naar 11% marktaandeel, met een daling van 35% in ruwe verzoeken op jaarbasis. Amazonbot verzamelt data voor Amazons zoekfunctionaliteit en AI-toepassingen, hoewel de dalende cijfers suggereren dat Amazon mogelijk zijn AI-strategie aanpast of zijn crawlingactiviteiten consolideert.
Applebot (Apple): Apple’s crawler kende een daling van 26% in verzoeken, van 1,9% naar 1,2% marktaandeel. Applebot ondersteunt vooral Siri en Spotlight Search, maar kan ook bijdragen aan opkomende AI-initiatieven van Apple. In tegenstelling tot de meeste andere AI-crawlers kan Applebot wél JavaScript uitvoeren, waarmee het vergelijkbare mogelijkheden heeft als Googlebot.
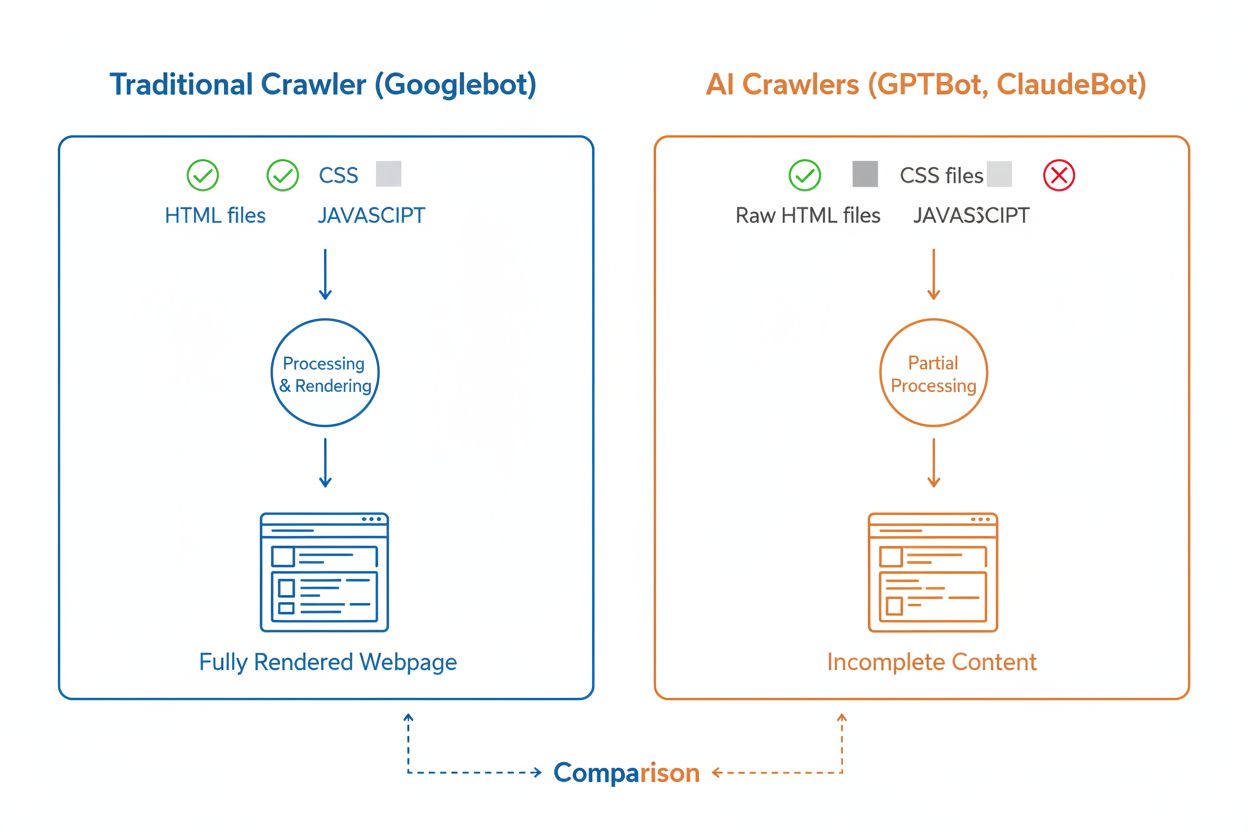
Hoewel AI-crawlers en traditionele zoekmachine-crawlers zoals Googlebot beide systematisch het web doorzoeken, verschillen hun technische mogelijkheden en gedrag aanzienlijk, wat direct invloed heeft op hoe jouw content wordt ontdekt en begrepen. Het belangrijkste verschil is JavaScript-rendering: Googlebot kan JavaScript uitvoeren nadat een pagina is gedownload, waardoor ook dynamisch geladen content zichtbaar is, terwijl de meeste AI-crawlers (GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider) alleen de ruwe HTML lezen en JavaScript-afhankelijke content negeren. Dit betekent dat als jouw website afhankelijk is van client-side rendering om essentiële informatie te tonen, AI-crawlers een onvolledige versie van je pagina’s te zien krijgen. Bovendien tonen AI-crawlers minder voorspelbare crawlpatronen dan de systematische aanpak van Googlebot—ze besteden 34,82% van de verzoeken aan 404-pagina’s en 14,36% aan het volgen van redirects, tegenover Googlebot met slechts 8,22% aan 404’s en 1,49% aan redirects. Ook de crawlfrequentie verschilt: waar Googlebot bezoekt op basis van een geavanceerd crawlbudget-systeem, crawlen AI-crawlers vaker maar minder systematisch, waarbij sommige onderzoeken laten zien dat AI-crawlers pagina’s meer dan 100 keer vaker bezoeken dan Google in bepaalde gevallen. Deze verschillen betekenen dat traditionele SEO-optimalisaties niet altijd voldoende zijn voor AI-crawlbaarheid, waardoor een aparte aanpak vereist is met focus op server-side rendering en een schone URL-structuur.
Een van de grootste technische uitdagingen voor AI-crawlers is hun onvermogen om JavaScript te renderen, een beperking die voortkomt uit de hoge rekencapaciteit die nodig is om JavaScript op grote schaal uit te voeren voor de training van grote taalmodellen. Wanneer een crawler je webpagina downloadt, ontvangt hij alleen de initiële HTML-respons, maar alle content die door JavaScript wordt geladen of aangepast—zoals productdetails, prijsinformatie, gebruikersrecensies of dynamische navigatie—blijft voor AI-crawlers onzichtbaar. Dit vormt een groot probleem voor moderne websites die sterk afhankelijk zijn van client-side rendering-frameworks zoals React, Vue of Angular zonder server-side rendering (SSR) of statische sitegeneratie (SSG). Een voorbeeld: een e-commercesite die productinformatie via JavaScript laadt, zal voor AI-crawlers verschijnen als een lege pagina zonder productdetails, waardoor AI-systemen de inhoud niet kunnen begrijpen of citeren. De oplossing is ervoor zorgen dat alle essentiële content in de initiële HTML-respons wordt opgenomen via server-side rendering, waarbij de complete HTML op de server wordt gegenereerd voordat deze naar de browser wordt gestuurd. Zo krijgen zowel menselijke bezoekers als AI-crawlers dezelfde inhoudrijke ervaring. Websites die moderne frameworks zoals Next.js met SSR gebruiken, statische site generators zoals Hugo of Gatsby, of traditionele server-rendered platforms als WordPress, zijn van nature AI-crawler-vriendelijk, terwijl sites die uitsluitend op client-side rendering vertrouwen grote zichtbaarheidsproblemen ondervinden in AI-zoekresultaten.
AI-crawlers tonen duidelijke verschillen in crawlfrequentie en -patronen ten opzichte van het gedrag van Googlebot, met belangrijke gevolgen voor hoe snel jouw content wordt opgepikt door AI-systemen. Onderzoek laat zien dat AI-crawlers zoals ChatGPT en Perplexity na publicatie vaak sneller pagina’s bezoeken dan Googlebot—in sommige gevallen bezoeken ze pagina’s 8 keer vaker dan Googlebot binnen de eerste paar dagen. Deze snelle initiële crawl suggereert dat AI-platforms prioriteit geven aan het snel ontdekken en indexeren van nieuwe content, waarschijnlijk om hun modellen en zoekfuncties van de meest actuele informatie te voorzien. Na deze agressieve eerste crawl volgt echter een patroon waarbij AI-crawlers mogelijk niet terugkeren als de content niet aan hun kwaliteitsnormen voldoet, waardoor die eerste indruk extra belangrijk wordt. In tegenstelling tot Googlebot, die werkt met een geavanceerd crawlbudget en regelmatig terugkomt afhankelijk van updatefrequentie en relevantie, lijken AI-crawlers een snelle afweging te maken of content het waard is om terug te keren. Dit betekent dat als een AI-crawler je pagina bezoekt en dunne content, technische fouten of slechte gebruikerservaring signaleert, het veel langer kan duren voordat hij terugkomt—of helemaal niet. De implicatie voor contentmakers is duidelijk: je kunt niet rekenen op een tweede kans om content voor AI-crawlers te optimaliseren, zoals dat bij traditionele zoekmachines soms het geval is. Kwaliteitscontrole vóór publicatie is dus essentieel.
Website-eigenaren kunnen het robots.txt-bestand gebruiken om voorkeuren voor AI-crawlertoegang aan te geven, hoewel de effectiviteit en handhaving van deze regels per crawler sterk uiteenloopt. Volgens recente gegevens heeft ongeveer 14% van de top 10.000 websites specifieke allow- of disallow-regels voor AI-bots in hun robots.txt-bestand opgenomen. GPTBot is de meest geblokkeerde crawler, met 312 domeinen (250 volledig, 62 gedeeltelijk) die deze expliciet weigeren, maar het is ook de meest expliciet toegestane crawler met 61 domeinen die toegang verlenen. Andere vaak geblokkeerde crawlers zijn onder meer CCBot (Common Crawl) en Google-Extended (Google’s AI-trainings-token). De uitdaging bij robots.txt is dat naleving vrijwillig is—crawlers volgen deze regels alleen als hun beheerders die functionaliteit daadwerkelijk implementeren, en sommige nieuwe of minder transparante crawlers respecteren robots.txt helemaal niet. Bovendien komen robots.txt-tokens zoals “Google-Extended” niet direct overeen met user-agent strings in HTTP-verzoeken; ze geven eerder het doel van het crawlen aan, waardoor je naleving niet altijd via serverlogs kunt verifiëren. Voor sterkere handhaving schakelen website-eigenaren steeds vaker over op firewallregels en Web Application Firewalls (WAF’s) waarmee specifieke crawler user-agents actief geblokkeerd kunnen worden, wat betrouwbaardere controle biedt dan alleen robots.txt. Deze verschuiving naar actieve blokkeringsmechanismen weerspiegelt groeiende bezorgdheid over contentrechten en de wens om afdwingbare controle te houden over AI-crawlertoegang.
Het volgen van AI-crawleractiviteit op je website is essentieel om je zichtbaarheid in AI-zoekresultaten te begrijpen, maar het brengt unieke uitdagingen met zich mee in vergelijking met het monitoren van traditionele zoekmachine-crawlers. Traditionele analysetools zoals Google Analytics zijn afhankelijk van JavaScript-tracking, wat AI-crawlers niet uitvoeren, waardoor deze tools geen inzicht geven in bezoeken van AI-bots. Ook trackingpixels werken niet omdat de meeste AI-crawlers alleen tekst verwerken en afbeeldingen negeren. De enige betrouwbare manier om AI-crawleractiviteit te volgen is via server-side monitoring—het analyseren van HTTP-verzoekheaders en serverlogs om crawler user-agents te herkennen voordat de pagina wordt verzonden. Dit vereist handmatige loganalyse of gespecialiseerde tools die specifiek zijn ontwikkeld om AI-crawlerverkeer te identificeren en te volgen. Realtime monitoring is daarbij cruciaal, omdat AI-crawlers op onvoorspelbare momenten werken en mogelijk niet terugkeren naar pagina’s als ze problemen tegenkomen, waardoor een wekelijkse of maandelijkse crawlaudit belangrijke problemen kan missen. Als een AI-crawler je site bezoekt en een technische fout of matige contentkwaliteit tegenkomt, krijg je mogelijk geen kans om een betere indruk te maken. Door 24/7 monitoringoplossingen in te zetten die je direct waarschuwen als AI-crawlers problemen tegenkomen—zoals 404-fouten, trage laadtijden of ontbrekende schema markup—kun je problemen aanpakken voordat ze je AI-zoekzichtbaarheid beïnvloeden. Deze realtime aanpak is een fundamentele verandering ten opzichte van traditionele SEO-monitoring en sluit aan bij de snelheid en onvoorspelbaarheid van AI-crawlergedrag.
Je website optimaliseren voor AI-crawlers vereist een andere aanpak dan traditionele SEO, met focus op technische factoren die direct bepalen hoe AI-systemen jouw content kunnen benaderen en begrijpen. De eerste prioriteit is server-side rendering: zorg dat alle essentiële content—koppen, hoofdtekst, metadata, gestructureerde data—in de initiële HTML-respons zit en niet dynamisch via JavaScript wordt geladen. Dit geldt voor je homepage, belangrijke landingspagina’s en alle content die je door AI wilt laten citeren of refereren. Ten tweede: implementeer gestructureerde data (Schema.org) op je belangrijkste pagina’s, bijvoorbeeld article schema voor blogs, product schema voor e-commerce en auteur schema voor het tonen van expertise en autoriteit. AI-crawlers gebruiken gestructureerde data om snel de inhoudshiërarchie en context te begrijpen, waardoor het veel makkelijker wordt om jouw informatie te verwerken en te citeren. Ten derde: houd de kwaliteitsstandaard van je content overal hoog, want AI-crawlers lijken snel te beoordelen of content het waard is om te indexeren en te citeren. Zorg dus voor originele, goed onderbouwde, feitelijk correcte content die èchte waarde biedt voor lezers. Ten vierde: monitor en optimaliseer Core Web Vitals en algemene paginasnelheid, want trage pagina’s signaleren een slechte gebruikerservaring en kunnen AI-crawlers ontmoedigen om terug te keren. Tot slot: houd je URL-structuur schoon en consistent, zorg voor een actuele XML-sitemap en een correct geconfigureerde robots.txt die crawlers naar je belangrijkste content leidt. Deze technische optimalisaties vormen de basis waardoor AI-systemen je content kunnen vinden, begrijpen en citeren.
Het landschap van AI-crawlers zal zich snel blijven ontwikkelen naarmate de concurrentie tussen AI-bedrijven toeneemt en de technologie volwassen wordt. Een duidelijke trend is de consolidatie van marktaandeel rond de meest succesvolle platforms—GPTBot van OpenAI is uitgegroeid tot de dominante kracht, terwijl nieuwkomers als Meta-ExternalAgent agressief opschalen, wat suggereert dat de markt zich zal stabiliseren rond een handvol grote spelers. Naarmate AI-crawlers volwassener worden, mogen we verbeteringen verwachten in hun technische mogelijkheden, met name op het gebied van JavaScript-rendering en efficiëntere crawlpatronen die het aantal verspilde verzoeken aan 404-pagina’s en verouderde content verminderen. De sector beweegt bovendien richting meer gestandaardiseerde communicatieprotocollen, zoals de opkomende llms.txt-specificatie, waarmee websites expliciet hun contentstructuur en crawlvoorkeuren aan AI-systemen kunnen doorgeven. Ook de handhavingsmechanismen voor AI-crawlercontrole worden geavanceerder, met platforms zoals Cloudflare die nu standaard automatische blokkering van AI-trainingsbots bieden—website-eigenaren krijgen zo meer gedetailleerde controle over hun content. Voor contentmakers en website-eigenaren betekent dit dat je AI-crawleractiviteit voortdurend moet monitoren, je technische infrastructuur optimaal moet houden voor AI-toegankelijkheid en je contentstrategie moet aanpassen aan het feit dat AI-systemen nu een aanzienlijk deel van je websiteverkeer vertegenwoordigen en een essentieel kanaal zijn voor merkzichtbaarheid. De toekomst is aan degenen die dit nieuwe crawler-ecosysteem begrijpen en daarop optimaliseren.
AI-crawlers zijn geautomatiseerde programma's die webdata verzamelen, specifiek om kunstmatige intelligentiemodellen zoals ChatGPT en Claude te trainen en te verbeteren. In tegenstelling tot traditionele zoekmachine-crawlers zoals Googlebot, die inhoud indexeren voor zoekresultaten, verzamelen AI-crawlers ruwe webdata om grote taalmodellen te voeden. Beide soorten crawlers browsen systematisch het internet, maar ze hebben verschillende doelen en technische mogelijkheden.
AI-crawlers bezoeken je website om data te verzamelen voor het trainen van AI-modellen, het verbeteren van zoekfuncties en het onderbouwen van AI-antwoorden met actuele informatie. Wanneer AI-systemen zoals ChatGPT of Perplexity gebruikersvragen beantwoorden, moeten ze vaak jouw content in realtime ophalen om nauwkeurige, geciteerde informatie te bieden. Door AI-crawlers toegang te geven tot je site, vergroot je de kans dat je merk wordt genoemd en geciteerd in AI-gegenereerde antwoorden.
Ja, je kunt je robots.txt-bestand gebruiken om specifieke AI-crawlers te weigeren door hun user-agent-namen op te geven. De naleving van robots.txt is echter vrijwillig en niet alle crawlers respecteren deze regels. Voor sterkere handhaving kun je firewallregels en Web Application Firewalls (WAF's) inzetten om specifieke crawler user-agents actief te blokkeren. Zo heb je betrouwbaardere controle over welke AI-crawlers toegang hebben tot je content.
Nee, de meeste AI-crawlers (GPTBot, ClaudeBot, Meta-ExternalAgent) voeren geen JavaScript uit. Ze lezen alleen de ruwe HTML van je pagina's, wat betekent dat alle content die dynamisch via JavaScript wordt geladen voor hen onzichtbaar is. Daarom is server-side rendering cruciaal voor AI-crawlbaarheid. Als je site afhankelijk is van client-side rendering, zien AI-crawlers een onvolledige versie van je pagina's.
AI-crawlers bezoeken websites op korte termijn na publicatie vaker dan traditionele zoekmachines. Onderzoek toont aan dat ze pagina's 8-100 keer vaker kunnen bezoeken dan Google binnen de eerste paar dagen. Als content echter niet aan kwaliteitsnormen voldoet, komen ze mogelijk niet terug. De eerste indruk is dus cruciaal: je krijgt misschien geen tweede kans om content voor AI-crawlers te optimaliseren.
De belangrijkste optimalisaties zijn: (1) Gebruik server-side rendering zodat kritieke content in de initiële HTML staat, (2) Voeg gestructureerde data (Schema) toe om AI te helpen je content te begrijpen, (3) Houd de kwaliteit en actualiteit van je content hoog, (4) Monitor Core Web Vitals voor een goede gebruikerservaring, en (5) Zorg voor een schone URL-structuur en een actuele sitemap. Deze technische optimalisaties vormen de basis voor het vindbaar en citeerbaar maken van je content door AI-systemen.
GPTBot van OpenAI is momenteel de dominante AI-crawler, verantwoordelijk voor 30% van al het AI-crawlerverkeer en groeit met 305% jaar-op-jaar. Toch moet je optimaliseren voor alle grote crawlers, waaronder ClaudeBot (Anthropic), Meta-ExternalAgent (Meta), PerplexityBot (Perplexity) en anderen. Verschillende AI-platforms hebben verschillende gebruikersgroepen, dus zichtbaarheid bij meerdere crawlers maximaliseert de aanwezigheid van je merk in AI-zoekopdrachten.
Traditionele analysetools zoals Google Analytics registreren geen AI-crawleractiviteit omdat ze afhankelijk zijn van JavaScript-tracking. Je hebt in plaats daarvan server-side monitoring nodig die HTTP-verzoekheaders en serverlogs analyseert om crawler user-agents te identificeren. Gespecialiseerde tools voor AI-crawlertracking bieden realtime inzicht in welke pagina's worden gecrawld, hoe vaak, en of crawlers technische problemen tegenkomen.
Volg hoe AI-crawlers zoals GPTBot en ClaudeBot jouw content benaderen en citeren. Krijg realtime inzicht in jouw AI-zoekzichtbaarheid met AmICited.
Leer hoe je AI-crawlers zoals GPTBot, PerplexityBot en ClaudeBot kunt identificeren en monitoren in je serverlogs. Ontdek user-agent strings, IP-verificatiemeth...

Ontdek hoe je strategische beslissingen neemt over het blokkeren van AI-crawlers. Evalueer inhoudstype, verkeersbronnen, verdienmodellen en concurrentiepositie ...
Leer hoe je AI-bots zoals GPTBot, PerplexityBot en ClaudeBot toestaat om je site te crawlen. Configureer robots.txt, stel llms.txt in en optimaliseer voor AI-zi...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.