
Wikipedia's rol in AI-trainingsdata: Kwaliteit, Impact en Licenties
Ontdek hoe Wikipedia dient als een cruciale AI-trainingsdataset, de impact op modelnauwkeurigheid, licentieovereenkomsten en waarom AI-bedrijven ervan afhankeli...
12 min lezen

Ontdek waar ChatGPT zijn trainingsdata vandaan haalt, hoe het bronnen noemt, wat de kennis-cutoffdata zijn en waarom het monitoren van AI-citaties belangrijk is voor je merk.
De kennisbasis van ChatGPT is opgebouwd uit een diverse verzameling openbaar beschikbare internetdata, gecombineerd met gelicentieerde datasets en verfijning via menselijke feedback. Het model is getraind op drie primaire bronnen: openbaar beschikbare internetdata (websites, artikelen en online content), gelicentieerde datasets (waaronder boeken en wetenschappelijke publicaties) en menselijke feedback van trainers die hielpen de antwoorden te verfijnen. Deze trainingsdata omvatten een uitzonderlijk breed scala aan bronnen, waaronder nieuwssites, wetenschappelijke tijdschriften, boeken, technische documentatie, fora zoals Reddit en Stack Overflow, Wikipedia-artikelen en talloze andere vrij toegankelijke webpagina’s. De enorme hoeveelheid en diversiteit aan bronnen—verspreid over meerdere talen, domeinen en perspectieven—creëert een uitgebreide kennisbasis waarmee ChatGPT onderwerpen kan bespreken van quantumfysica tot middeleeuwse geschiedenis tot hedendaagse popcultuur. Het is echter belangrijk te begrijpen dat ChatGPT geen toegang heeft tot realtime informatie of eigendomsdatabases; het kan alleen putten uit wat beschikbaar was tijdens zijn trainingsperiode.
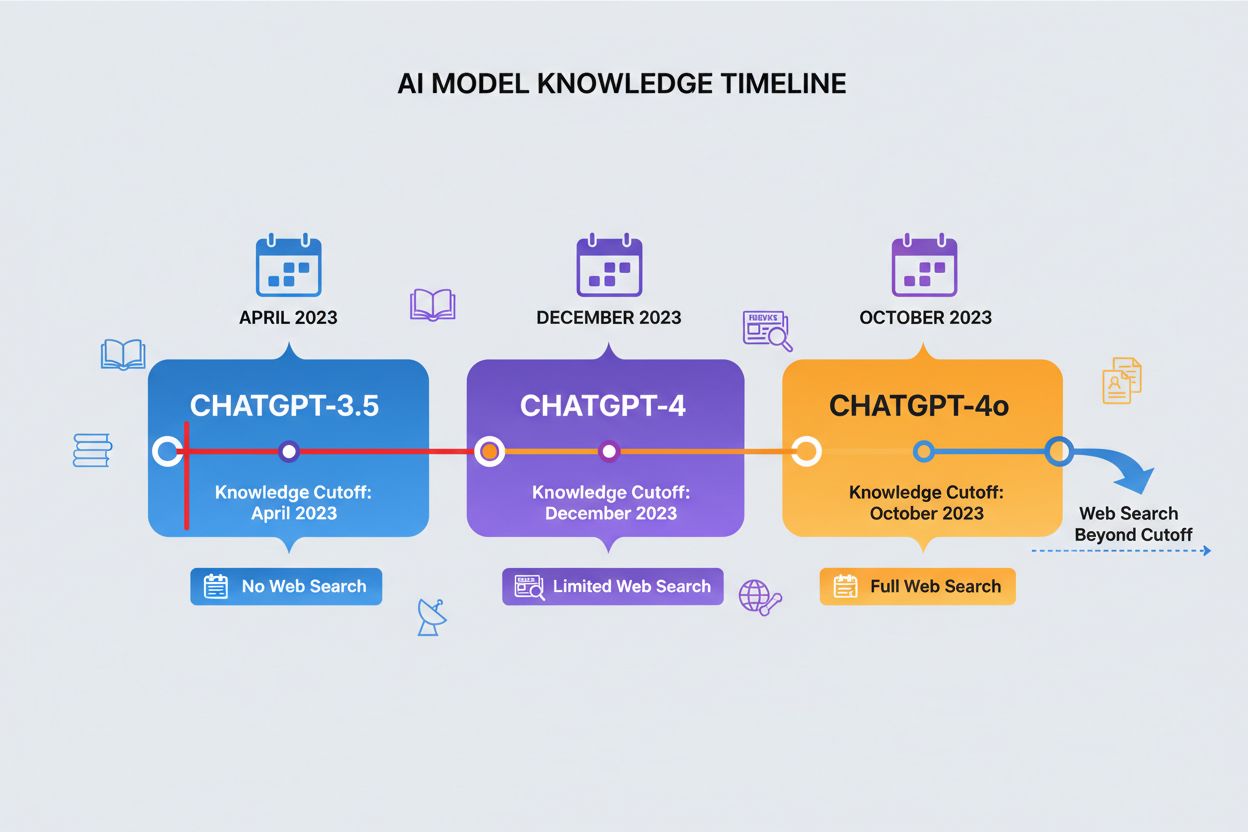
Een kennis-cutoffdatum is het tijdstip waarna ChatGPT geen trainingsdata meer heeft, wat een harde grens vormt voor de informatie die het kan raadplegen. Verschillende versies van ChatGPT hebben verschillende cutoffdata: ChatGPT-4 is getraind op data tot en met december 2023, terwijl ChatGPT-4o (de geoptimaliseerde versie) een kennis-cutoff heeft van oktober 2023. Deze cutoffdata beïnvloeden aanzienlijk de nauwkeurigheid en relevantie van antwoorden, vooral bij recente gebeurtenissen, nieuw gepubliceerde onderzoeken of actuele statistieken die sinds het verzamelen van de trainingsdata kunnen zijn veranderd. Sommige nieuwere versies van ChatGPT kunnen websearches uitvoeren om actuele informatie op te halen die buiten hun cutoffdatum valt, maar deze functie is niet beschikbaar in alle versies of contexten. Het kennen van de cutoffdatum van je model is essentieel voor gebruikers die actuele informatie nodig hebben, omdat ChatGPT geen accurate antwoorden kan geven over gebeurtenissen of ontwikkelingen die zich na de trainingsperiode hebben voorgedaan. Deze beperking is een van de belangrijkste factoren om rekening mee te houden bij het beoordelen van de betrouwbaarheid van ChatGPT voor tijdgevoelige vragen.
| ChatGPT-versie | Kennis-cutoffdatum | Websearch-mogelijkheid | Primaire gebruikstoepassing |
|---|---|---|---|
| ChatGPT-4 | December 2023 | Beperkt | Algemene kennis, analyse, redeneren |
| ChatGPT-4o | Oktober 2023 | Beschikbaar | Geoptimaliseerde prestaties, multimodale taken |
| ChatGPT-3.5 | April 2023 | Nee | Basisvragen, kosteneffectieve optie |
| ChatGPT met Browsen | Realtime | Ja | Actuele gebeurtenissen, recent onderzoek |
In tegenstelling tot zoekmachines die specifieke documenten of webpagina’s ophalen als antwoord op vragen, genereert ChatGPT antwoorden door patronen te synthetiseren die tijdens de training zijn geleerd—een fundamenteel ander proces. Wanneer je ChatGPT een vraag stelt, zoekt het niet in een database of index; in plaats daarvan gebruikt het statistische patronen uit zijn trainingsdata om de meest waarschijnlijke woordvolgorde te voorspellen die een nuttig antwoord zou vormen. Deze generatiegerichte aanpak betekent dat ChatGPT informatie uit meerdere bronnen in zijn trainingsdata combineert tot nieuwe antwoorden die mogelijk nergens letterlijk in het bronmateriaal voorkomen. Het model leert in wezen de relaties tussen concepten, feiten en ideeën, en reconstrueert deze kennis in antwoord op je specifieke vraag. Dit proces heeft echter een belangrijk nadeel: wanneer het model onzeker is over informatie of wanneer patronen in de trainingsdata tegenstrijdig of schaars zijn, kan het aannemelijk klinkende maar foutieve informatie genereren, een fenomeen dat bekendstaat als “hallucinatie”. Nieuwere versies van ChatGPT die websearchfunctionaliteit integreren, kunnen dit generatieproces aanvullen door actuele informatie van het internet op te halen, maar deze functie vereist expliciete activering en is niet op alle platforms beschikbaar.
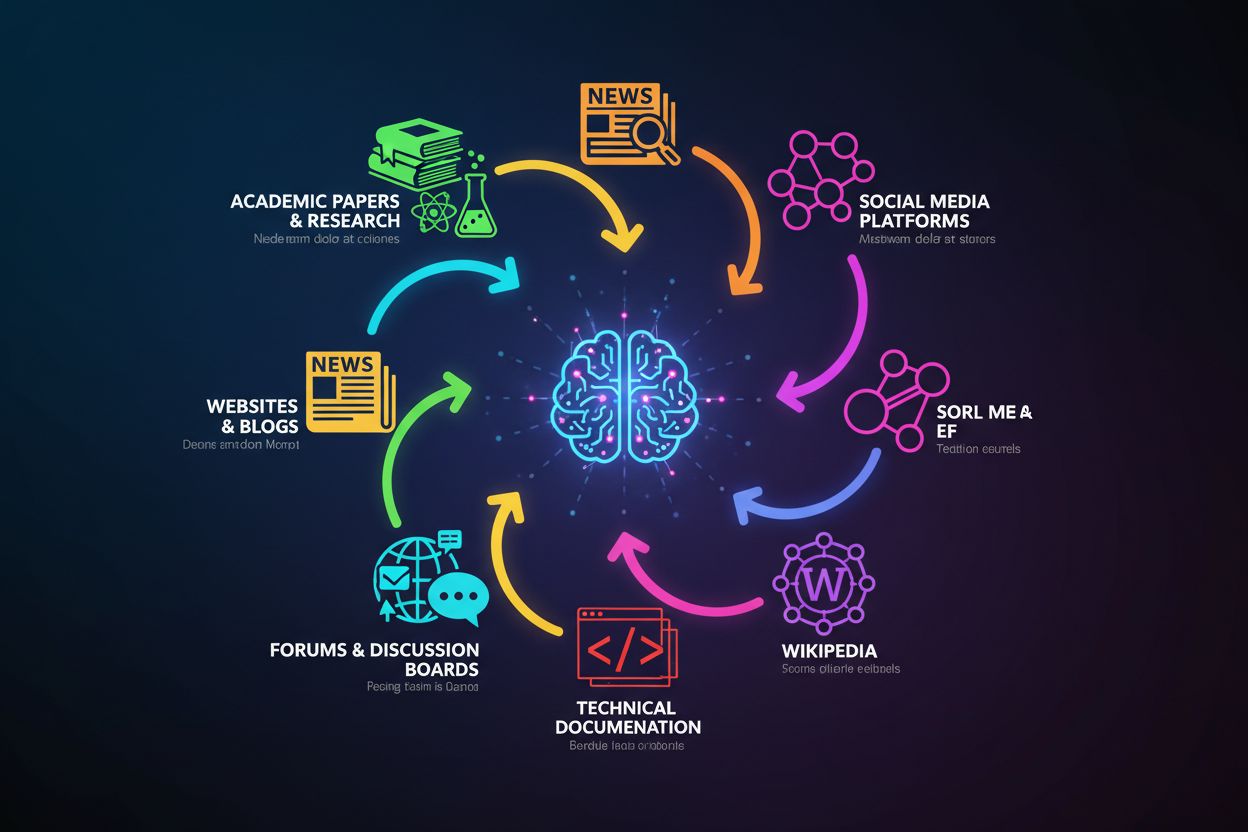
De trainingsdata van ChatGPT zijn afkomstig uit verschillende grote broncategorieën, die elk een unieke waarde bijdragen aan de kennisbasis:
Het belang van deze diverse bronnen ligt in hun complementaire sterke punten: wetenschappelijke artikelen bieden degelijkheid, nieuwsartikelen actualiteit, boeken diepgang en fora praktische toepassing. De kwaliteit van bronnen varieert echter aanzienlijk—een peer-reviewed wetenschappelijk artikel weegt zwaarder dan een willekeurige blogpost, maar het trainingsproces van ChatGPT maakt hierin geen expliciet onderscheid. Dit betekent dat de kennis van ChatGPT zowel hoogwaardige gezaghebbende bronnen als bronnen van lagere kwaliteit of mogelijk misleidende informatie weerspiegelt, waardoor verificatie essentieel blijft bij het gebruik van het model voor belangrijke beslissingen.
Na de initiële training op grote hoeveelheden tekstdata heeft OpenAI een techniek toegepast genaamd Reinforcement Learning from Human Feedback (RLHF) om de antwoorden van ChatGPT te verfijnen. In dit proces beoordeelden menselijke trainers de modeluitvoer en gaven feedback, waardoor het systeem leerde welke antwoorden behulpzamer, nauwkeuriger en beter afgestemd op menselijke waarden waren. Deze trainers controleerden niet elke uitspraak op feitelijke juistheid; ze beoordeelden vooral de algehele kwaliteit, behulpzaamheid en veiligheid van het antwoord, wat indirect bepaalt welke informatie het model benadrukt en hoe onderwerpen worden gepresenteerd. Het RLHF-proces heeft grote invloed op welke informatie in antwoorden naar voren komt en hoe onderwerpen worden ingekaderd, en introduceert menselijke beoordeling in wat anders een puur statistisch model zou zijn. Dit proces kent echter inherente beperkingen: trainers hebben hun eigen vooroordelen, kennishiaten en beperkingen, en kunnen onmogelijk de nauwkeurigheid van elke bewering in alle domeinen beoordelen. Bovendien is het feedbackproces arbeidsintensief en kan het slechts op een fractie van de mogelijke modeluitvoer worden toegepast, waardoor veel van het gedrag van ChatGPT nog steeds de ruwe patronen uit de trainingsdata weerspiegelt in plaats van expliciete menselijke curatie.
Het citeren van ChatGPT is belangrijk voor academische integriteit en transparantie, zodat lezers begrijpen waar informatie vandaan komt en je bevindingen kunnen reproduceren of verifiëren. Het citatieformaat hangt af van de vereiste stijlgids, maar dit zijn de meest gangbare aanpakken:
MLA-formaatvoorbeeld:
OpenAI. "ChatGPT." Geraadpleegd op [Datum], https://chat.openai.com.
In MLA-stijl citeer je ChatGPT als een website en vermeld je de datum van raadpleging, omdat de inhoud dynamisch is en kan veranderen. Als je naar een specifiek antwoord verwijst, noteer dan de datum waarop je het hebt geraadpleegd en bij voorkeur ook de prompt of vraag die je hebt gesteld.
APA-formaatvoorbeeld:
OpenAI. (2024). ChatGPT (Versie 4) [Groot taalmodel].
Geraadpleegd van https://chat.openai.com
APA-formaat behandelt ChatGPT als een softwaretool of applicatie, inclusief het versienummer en de raadpleegdatum. Sommige APA-richtlijnen adviseren ook de specifieke prompt in je bronvermelding of als aanvulling op te nemen.
Wanneer ChatGPT citeren: Je moet het hulpmiddel citeren telkens wanneer je de output gebruikt in academisch werk, professionele rapporten of elke context waarin bronvermelding van belang is. Documenteer de exacte prompt die je gebruikte, de raadpleegdatum en bij voorkeur de versie van ChatGPT, omdat deze details de reproduceerbaarheid beïnvloeden. Het belangrijkste verschil tussen het citeren van ChatGPT en traditionele bronnen is dat ChatGPT-antwoorden dynamisch worden gegenereerd—dezelfde prompt kan op verschillende momenten iets andere antwoorden opleveren—dus het opnemen van de prompt zelf is onderdeel van het juiste citatiegebruik. Veel instellingen ontwikkelen nog formele richtlijnen voor AI-citaties, dus raadpleeg je organisatie of publicatie voor het gewenste formaat.
Hoewel ChatGPT opmerkelijk capabel is, zijn er significante beperkingen die de betrouwbaarheid van zijn informatie beïnvloeden. ChatGPT kan met grote zekerheid onjuiste informatie geven, een probleem dat hallucinatie wordt genoemd, vooral bij obscure onderwerpen, recente gebeurtenissen buiten zijn kennis-cutoff of bij tegenstrijdige informatie in de trainingsdata. De trainingsdata van het model bevatten inherente vooroordelen die de perspectieven, demografieën en gezichtspunten uit het bronmateriaal weerspiegelen, waardoor antwoorden onbedoeld bepaalde zienswijzen kunnen bevoordelen of stereotypen bevatten. Informatie in de trainingsdata van ChatGPT raakt na verloop van tijd steeds meer verouderd, waardoor het onbetrouwbaar is voor actuele statistieken, recente onderzoeksresultaten of veranderende situaties. Om deze redenen is het essentieel ChatGPT’s beweringen te controleren, vooral bij belangrijke beslissingen—controleer belangrijke feiten altijd aan de hand van primaire bronnen, recente publicaties en gezaghebbende databases. Om ChatGPT’s beweringen te verifiëren, vergelijk je de uitspraken met meerdere onafhankelijke bronnen, controleer je data en statistieken met actuele gegevens en wees je extra kritisch bij specifieke getallen, namen of recente gebeurtenissen. Onthoud tenslotte dat ChatGPT geen primaire bron is; het is een secundaire bron die informatie uit andere bronnen synthetiseert, dus voor academisch of professioneel werk moet je de originele bronnen citeren waar ChatGPT naar verwijst, niet ChatGPT zelf.
Nu ChatGPT en andere AI-systemen steeds meer geïntegreerd raken in hoe mensen informatie ontdekken, is het monitoren van hoe deze systemen naar je merk of organisatie verwijzen en citeren cruciaal geworden. AmICited is een AI-antwoordenmonitoringsplatform dat speciaal is ontworpen om te volgen hoe ChatGPT, Claude en andere grote taalmodellen je bedrijf, producten of merk noemen, citeren of naar verwijzen in hun antwoorden. Het platform helpt je te begrijpen wanneer en hoe je merk voorkomt in AI-gegenereerde antwoorden, en biedt inzicht in een nieuw en groeiend kanaal van informatieontdekking dat traditionele webmonitoringtools vaak missen. Deze monitoringsmogelijkheid is essentieel omdat AI-citaties anders werken dan traditionele webcitaten—ze zijn ingebed in conversatie-antwoorden waar miljoenen gebruikers dagelijks mee interacteren, terwijl de meeste merken geen zicht hebben op hoe ze worden weergegeven. Door AmICited te gebruiken om AI-vermeldingen en citaties te volgen, krijg je inzicht in merkperceptie in AI-systemen, kun je onnauwkeurigheden of verouderde informatie identificeren die moet worden gecorrigeerd en zie je hoe je merk zich verhoudt tot concurrenten in AI-gegenereerde antwoorden. In een tijdperk waarin AI-systemen voor veel gebruikers primaire informatiebronnen worden, is je aanwezigheid in deze systemen monitoren net zo belangrijk als het monitoren van traditionele zoekresultaten, waardoor tools zoals AmICited essentieel zijn voor modern merkbeheer en AI-transparantie.
ChatGPT is getraind op drie primaire bronnen: openbaar beschikbare internetdata (websites, artikelen, fora), gelicentieerde datasets (boeken en wetenschappelijke publicaties) en menselijke feedback van trainers. De trainingsdata omvatten nieuwssites, wetenschappelijke tijdschriften, technische documentatie, Wikipedia, Reddit, Stack Overflow en talloze andere vrij toegankelijke webpagina's die verzameld zijn tot aan de kennis-cutoffdatum.
Een kennis-cutoffdatum is het tijdstip waarna ChatGPT geen trainingsdata meer heeft. ChatGPT-4 heeft een cutoff in december 2023, terwijl ChatGPT-4o een cutoff in oktober 2023 heeft. Dit is belangrijk omdat ChatGPT geen accurate informatie kan geven over gebeurtenissen, onderzoeken of ontwikkelingen die plaatsvonden na de trainingsperiode, waardoor het onbetrouwbaar is voor tijdgevoelige vragen.
ChatGPT kan op basis van zijn trainingsdata geen realtime informatie ophalen. Nieuwere versies van ChatGPT kunnen echter websearches uitvoeren om actuele informatie op te halen die buiten hun kennis-cutoffdatum valt, maar deze functie is niet in alle versies of contexten beschikbaar en vereist expliciete activering.
In MLA-formaat citeer je ChatGPT als een website met de datum van raadpleging. In APA-formaat behandel je het als software en vermeld je het versienummer. Beide formaten vereisen dat je de exacte prompt die je gebruikte, de datum van raadpleging en idealiter de versie van ChatGPT documenteert, omdat dezelfde prompt op verschillende momenten verschillende antwoorden kan opleveren.
Nee. ChatGPT kan zelfverzekerd onjuiste informatie geven (hallucinatie), vooral over obscure onderwerpen, recente gebeurtenissen buiten zijn kennis-cutoff of tegenstrijdige informatie. De trainingsdata bevatten inherente vooroordelen en de informatie raakt steeds meer verouderd. Controleer altijd belangrijke beweringen aan de hand van primaire bronnen en gezaghebbende databases.
De trainingsdata van ChatGPT worden niet continu bijgewerkt. Nieuwe versies worden periodiek uitgebracht met bijgewerkte kennis-cutoffdata, maar er is geen realtime update van het basismodel. OpenAI brengt nieuwe versies uit (zoals GPT-4o) met recentere trainingsdata, maar het exacte updateschema is niet openbaar gemaakt.
ChatGPT citeert geen specifieke bronnen voor individuele beweringen, omdat het informatie uit patronen in zijn trainingsdata synthetiseert in plaats van specifieke documenten op te halen. Het kan je niet wijzen op de exacte bron van een feit. Voor academisch werk moet je de beweringen van ChatGPT verifiëren en de originele bronnen citeren die je vindt, niet ChatGPT zelf.
AmICited volgt hoe ChatGPT, Claude en andere AI-systemen je merk noemen, citeren of naar verwijzen in hun antwoorden. Het biedt inzicht in hoe je bedrijf verschijnt in AI-gegenereerde antwoorden, helpt onnauwkeurigheden te identificeren en laat zien hoe je merk zich verhoudt tot concurrenten in AI-systemen—essentieel voor modern merkbeheer in het AI-tijdperk.
Volg ChatGPT-citaties en AI-vermeldingen in realtime met AmICited. Begrijp hoe AI-systemen naar je merk verwijzen en blijf voorop in AI-gedreven informatieontdekking.
Ontdek hoe Wikipedia dient als een cruciale AI-trainingsdataset, de impact op modelnauwkeurigheid, licentieovereenkomsten en waarom AI-bedrijven ervan afhankeli...

Trainingsgegevens zijn de dataset die gebruikt worden om ML-modellen patronen en relaties te laten leren. Ontdek hoe de kwaliteit van trainingsgegevens de prest...
Compleet overzicht van het afmelden voor AI-trainingsgegevensverzameling bij ChatGPT, Perplexity, LinkedIn en andere platforms. Leer stapsgewijze instructies om...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.