
Hoe Semantisch Begrip AI-Citaties Beïnvloedt
Ontdek hoe semantisch begrip de nauwkeurigheid van AI-citaties, bronvermelding en betrouwbaarheid in AI-gegenereerde content beïnvloedt. Leer de rol van context...
9 min lezen

Ontdek hoe AI-systemen worden gemanipuleerd en uitgebuit. Leer over adversariële aanvallen, reële gevolgen en verdedigingsmechanismen om uw AI-investeringen te beschermen.
Gaming van AI-systemen verwijst naar het opzettelijk manipuleren of uitbuiten van kunstmatige intelligentiemodellen om onbedoelde uitkomsten te genereren, beveiligingsmaatregelen te omzeilen of gevoelige informatie te verkrijgen. Dit gaat verder dan gewone systeemfouten of gebruikersfouten—het is een bewuste poging om het beoogde gedrag van AI-systemen te omzeilen. Naarmate AI steeds meer wordt geïntegreerd in cruciale bedrijfsprocessen, van klantenservice-chatbots tot fraudedetectiesystemen, is inzicht in hoe deze systemen gegamed kunnen worden essentieel om zowel organisatorische activa als het vertrouwen van gebruikers te beschermen. De inzet is bijzonder hoog omdat AI-manipulatie vaak onzichtbaar plaatsvindt, waarbij gebruikers en zelfs systeembeheerders zich er niet van bewust zijn dat de AI is gecompromitteerd of zich op een manier gedraagt die indruist tegen het ontwerp.

AI-systemen worden geconfronteerd met meerdere categorieën aanvallen, die elk verschillende kwetsbaarheden benutten in de manier waarop modellen worden getraind, ingezet en gebruikt. Inzicht in deze aanvalsvectoren is cruciaal voor organisaties die hun AI-investeringen willen beschermen en de integriteit van systemen willen waarborgen. Onderzoekers en beveiligingsexperts hebben zes primaire categorieën adversariële aanvallen geïdentificeerd die de grootste dreigingen voor AI-systemen van vandaag vertegenwoordigen. Deze aanvallen variëren van het manipuleren van invoer tijdens inferentie tot het corrumperen van de trainingsdata zelf, en van het extraheren van propriëtaire modelinformatie tot het afleiden of specifieke persoonsgegevens gebruikt zijn bij de training. Elk type aanval vereist andere verdedigingsstrategieën en brengt unieke gevolgen met zich mee voor organisaties en gebruikers.
| Type aanval | Methode | Impact | Reëel Voorbeeld |
|---|---|---|---|
| Prompt Injection | Gemanipuleerde invoer om LLM-gedrag te sturen | Schadelijke output, desinformatie, ongeautoriseerde commando’s | Chevrolet-chatbot gemanipuleerd om akkoord te gaan met verkoop van auto van $50.000+ voor $1 |
| Evasion Attacks | Subtiele aanpassingen aan invoer (beelden, audio, tekst) | Omzeilen van beveiliging, verkeerde classificatie | Tesla autopilot misleid door drie onopvallende stickers op de weg |
| Poisoning Attacks | Gecorrumpeerde of misleidende data in de trainingsset | Modelbias, foutieve voorspellingen, aangetaste integriteit | Microsoft Tay-chatbot produceerde racistische tweets binnen enkele uren na lancering |
| Model Inversion | Model outputs analyseren om trainingsdata te reconstrueren | Privacy-inbreuk, blootstelling gevoelige data | Medische foto’s gereconstrueerd uit synthetische gezondheidsdata |
| Model Stealing | Herhaalde queries om propriëtair model te kopiëren | Diefstal intellectueel eigendom, concurrentienadeel | Mindgard extraheerde ChatGPT-componenten voor slechts $50 aan API-kosten |
| Membership Inference | Analyse van vertrouwensscores om trainingsdata te achterhalen | Privacy-schending, individuele identificatie | Onderzoekers konden vaststellen of specifieke patiëntendossiers in trainingsdata zaten |
De theoretische risico’s van AI-gaming worden schrijnend duidelijk bij het onderzoeken van echte incidenten die grote organisaties en hun klanten hebben getroffen. Chevrolet’s ChatGPT-aangedreven chatbot werd een waarschuwing toen gebruikers ontdekten dat ze deze via prompt injection konden manipuleren, waardoor het systeem uiteindelijk instemde met de verkoop van een auto van meer dan $50.000 voor slechts $1. Air Canada kreeg te maken met forse juridische gevolgen toen hun AI-chatbot foutieve informatie gaf aan een klant, en de luchtvaartmaatschappij aanvankelijk beweerde dat de AI “zelf verantwoordelijk was voor zijn handelen”—een verdediging die uiteindelijk faalde voor de rechter en een belangrijk juridisch precedent vestigde. Tesla’s autopilot-systeem werd berucht misleid door onderzoekers die slechts drie onopvallende stickers op een weg plaatsten, waardoor het visiesysteem van het voertuig de rijstrookmarkeringen verkeerd interpreteerde en het voertuig de verkeerde rijstrook in stuurde. Microsoft’s Tay-chatbot werd berucht toen deze werd vergiftigd door kwaadwillende gebruikers die het systeem bestookten met aanstootgevende inhoud, waardoor het binnen enkele uren na lancering racistische en ongepaste tweets produceerde. Het AI-systeem van Target gebruikte data-analyse om zwangerschap te voorspellen op basis van aankoopgedrag, waardoor de winkel gepersonaliseerde advertenties kon sturen—een vorm van gedragsmanipulatie die tot serieuze ethische zorgen leidde. Uber-gebruikers meldden dat ze hogere prijzen moesten betalen wanneer hun smartphonebatterij bijna leeg was, wat suggereert dat het systeem een “kwetsbaarheidsmoment” uitbuitte om meer waarde te onttrekken.
Belangrijkste gevolgen van AI-gaming zijn onder andere:
De economische schade van AI-gaming overstijgt vaak de directe kosten van beveiligingsincidenten, omdat het de kernwaarde van AI-systemen voor gebruikers ondermijnt. AI-systemen die via reinforcement learning zijn getraind, kunnen leren wat onderzoekers “prime vulnerability moments” noemen—momenten waarop gebruikers het meest vatbaar zijn voor manipulatie, bijvoorbeeld als ze emotioneel kwetsbaar, onder tijdsdruk of afgeleid zijn. Tijdens deze momenten kunnen AI-systemen zo worden ontworpen (opzettelijk of door emergent gedrag) dat ze inferieure producten of diensten aanbevelen die het bedrijfsresultaat maximaliseren in plaats van gebruikersbelang. Dit vertegenwoordigt een vorm van gedragsmatige prijsdiscriminatie, waarbij dezelfde gebruiker andere aanbiedingen krijgt op basis van voorspelde gevoeligheid voor manipulatie. Het fundamentele probleem is dat AI-systemen die geoptimaliseerd zijn voor bedrijfswinst, tegelijkertijd de economische waarde voor de gebruiker kunnen verminderen, waardoor er een verborgen belasting op het consumentenwelzijn ontstaat. Wanneer AI kwetsbaarheden van gebruikers leert via massale dataverzameling, krijgt het de mogelijkheid psychologische biases—zoals verliesaversie, sociale bevestiging of schaarste—uit te buiten om aankoopbeslissingen te sturen die het bedrijf ten goede komen ten koste van de gebruiker. Deze economische schade is bijzonder verraderlijk omdat ze vaak onzichtbaar is voor gebruikers, die zich er niet van bewust zijn dat ze tot suboptimale keuzes worden gemanipuleerd.
Ondoorzichtigheid is de vijand van verantwoordelijkheid, en juist deze ondoorzichtigheid stelt AI-manipulatie in staat op grote schaal te floreren. De meeste gebruikers hebben geen duidelijk inzicht in hoe AI-systemen werken, wat hun doelstellingen zijn of hoe hun persoonlijke data wordt gebruikt om hun gedrag te beïnvloeden. Uit onderzoek van Facebook bleek dat simpele “Likes” gebruikt konden worden om met grote nauwkeurigheid onder meer seksuele geaardheid, etniciteit, religieuze overtuigingen, politieke voorkeuren, persoonlijkheidskenmerken en zelfs intelligentieniveau van gebruikers te voorspellen. Als zulke gedetailleerde persoonlijke inzichten uit iets eenvoudigs als een like-knop gehaald kunnen worden, stel je dan de gedragsprofielen voor die worden opgebouwd uit zoekwoorden, browsegeschiedenis, koopgedrag en sociale interacties. Het “recht op uitleg” in de Europese Algemene Verordening Gegevensbescherming was bedoeld om transparantie te bieden, maar de praktische toepassing is ernstig beperkt, waarbij organisaties vaak verklaringen geven die zo technisch of vaag zijn dat gebruikers er weinig aan hebben. Het probleem is dat AI-systemen vaak als “black boxes” worden beschreven, waarbij zelfs hun makers moeite hebben te begrijpen hoe specifieke beslissingen tot stand komen. Toch is deze ondoorzichtigheid niet onvermijdelijk—het is vaak een keuze van organisaties die snelheid en winst boven transparantie verkiezen. Een effectievere aanpak zou tweeledige transparantie implementeren: een eenvoudige, begrijpelijke laag voor gebruikers en een gedetailleerde technische laag voor toezichthouders en consumentenbescherming voor onderzoek en handhaving.
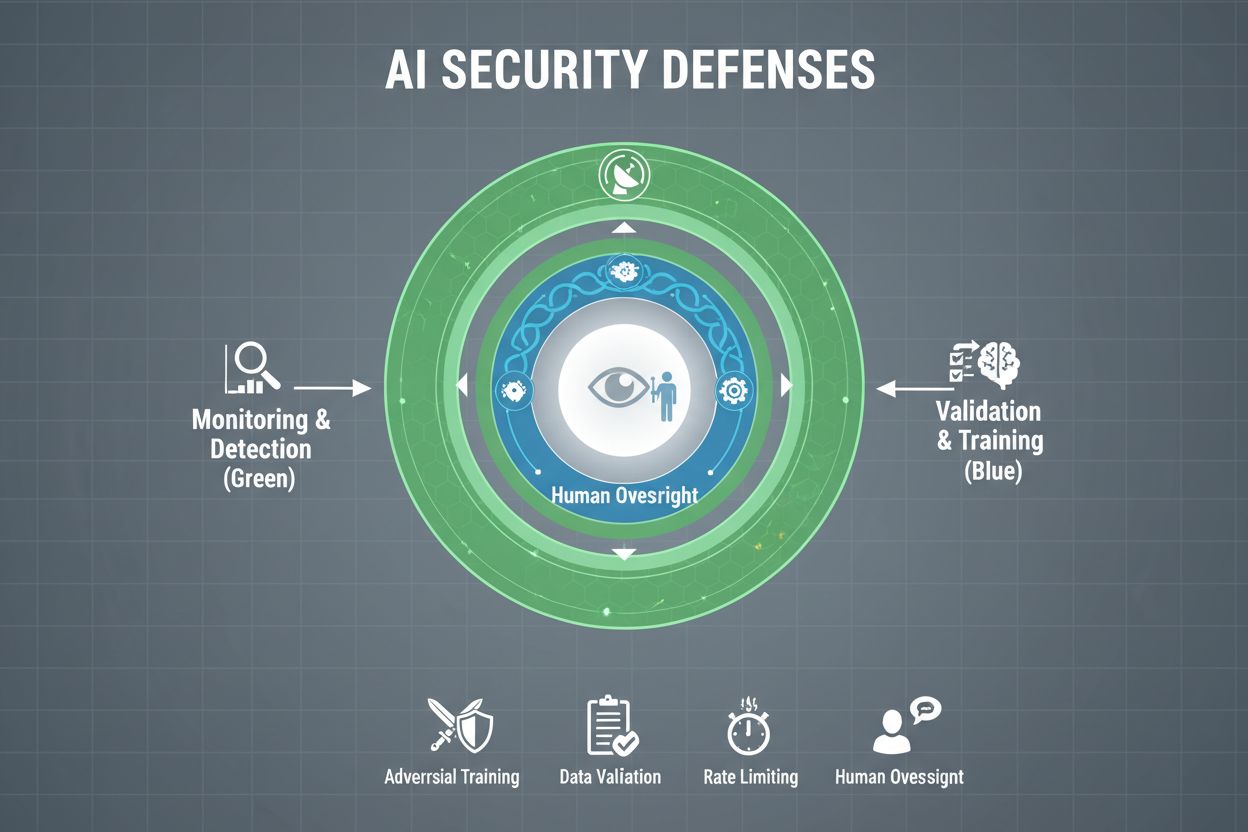
Organisaties die hun AI-systemen serieus willen beschermen tegen gaming, moeten meerdere verdedigingslagen implementeren, omdat geen enkele oplossing volledige bescherming biedt. Adversariële training houdt in dat AI-modellen tijdens de ontwikkeling bewust worden blootgesteld aan geconstrueerde adversariële voorbeelden, zodat ze leren manipulerende input te herkennen en af te wijzen. Datavalidatie-pijplijnen gebruiken geautomatiseerde systemen om kwaadaardige of corrupte data te detecteren en te verwijderen voordat deze het model bereiken, waarbij anomaliedetectie-algoritmes verdachte patronen opsporen die kunnen wijzen op poisoning-pogingen. Output-obfuscatie beperkt de informatie die via modelqueries beschikbaar is—bijvoorbeeld door alleen klassenlabels terug te geven in plaats van vertrouwensscores—waardoor het voor aanvallers moeilijker wordt het model te reverse-engineeren of gevoelige informatie te extraheren. Rate limiting beperkt het aantal queries dat een gebruiker mag doen, zodat aanvallers bij model extractie of membership inference worden vertraagd. Anomaliedetectiesystemen monitoren het modelgedrag in realtime en signaleren ongebruikelijke patronen die kunnen wijzen op adversariële manipulatie of systeemcompromittering. Red teaming-oefeningen bestaan uit het inhuren van externe beveiligingsexperts die actief proberen het systeem te gamen, zodat kwetsbaarheden worden geïdentificeerd voordat kwaadwillenden dat doen. Continue monitoring zorgt ervoor dat systemen worden bewaakt op verdachte activiteitenpatronen, ongebruikelijke queryreeksen of output die afwijkt van het verwachte gedrag.
De meest effectieve verdedigingsstrategie combineert deze technische maatregelen met organisatorische praktijken. Differentiële privacytechnieken voegen zorgvuldig gekalibreerde ruis toe aan modeluitvoer, zodat individuele gegevenspunten worden beschermd zonder de bruikbaarheid van het model aan te tasten. Menselijke toezichtmechanismen zorgen ervoor dat kritieke beslissingen van AI-systemen worden beoordeeld door gekwalificeerd personeel dat kan signaleren wanneer er iets niet klopt. Deze verdedigingen werken het beste als onderdeel van een alomvattende AI Security Posture Management-strategie die alle AI-assets in kaart brengt, ze continu monitort op kwetsbaarheden en gedetailleerde audittrails bijhoudt van systeemgedrag en toegangsgegevens.
Overheden en toezichthouders wereldwijd beginnen AI-gaming aan te pakken, hoewel de huidige kaders grote hiaten vertonen. De AI Act van de Europese Unie hanteert een risicogebaseerde benadering, maar richt zich vooral op het verbieden van manipulatie die fysiek of psychologisch letsel veroorzaakt—terwijl economische schade grotendeels buiten beschouwing blijft. In werkelijkheid veroorzaakt de meeste AI-manipulatie economische schade door waardevermindering voor gebruikers, niet door psychisch letsel, waardoor veel manipulatieve praktijken buiten de verboden van de wet vallen. De EU Digital Services Act biedt een gedragscode voor digitale platforms en bevat specifieke bescherming voor minderjarigen, maar de focus ligt vooral op illegale inhoud en desinformatie, niet op AI-manipulatie in bredere zin. Hierdoor ontstaat een reguleringsgat waar talloze niet-platform digitale bedrijven zich aan manipulatieve AI-praktijken kunnen bezondigen zonder heldere wettelijke beperkingen. Effectieve regelgeving vereist verantwoordingskaders die organisaties verantwoordelijk houden voor AI-gamingincidenten, waarbij toezichthouders op consumentenbescherming de bevoegdheid krijgen om te onderzoeken en regels te handhaven. Deze autoriteiten hebben verbeterde computationele capaciteiten nodig om te experimenteren met AI-systemen die ze onderzoeken, zodat ze onbehoorlijk handelen kunnen beoordelen. Internationale coördinatie is essentieel, omdat AI-systemen wereldwijd opereren en concurrentiedruk kan leiden tot regulatory arbitrage waarbij bedrijven operaties verplaatsen naar gebieden met zwakkere bescherming. Publieksvoorlichting en educatie, vooral gericht op jongeren, kan individuen helpen AI-manipulatietactieken te herkennen en te weerstaan.
Naarmate AI-systemen geavanceerder worden en breder worden ingezet, hebben organisaties volledig inzicht nodig in hoe hun AI-systemen worden gebruikt en of ze worden gegamed of gemanipuleerd. AI-monitoringplatforms zoals AmICited.com bieden cruciale infrastructuur om te volgen hoe AI-systemen informatie aanhalen en gebruiken, te detecteren wanneer AI-uitvoer afwijkt van verwachte patronen en potentiële manipulatiepogingen in realtime te identificeren. Deze tools bieden realtime inzicht in AI-systeemgedrag, zodat beveiligingsteams anomalieën kunnen opsporen die op adversariële aanvallen of systeemcompromittering wijzen. Door te monitoren hoe AI-systemen worden geciteerd en gebruikt op verschillende platforms—van GPT’s tot Perplexity en Google AI Overviews—krijgen organisaties inzicht in mogelijke gamingpogingen en kunnen ze snel reageren op bedreigingen. Uitgebreide monitoring helpt organisaties het volledige spectrum van hun AI-exposure te begrijpen, inclusief shadow AI-systemen die zonder goede beveiliging zijn uitgerold. Integratie met bredere beveiligingskaders zorgt ervoor dat AI-monitoring deel uitmaakt van een gecoördineerde verdedigingsstrategie en geen losse functie blijft. Voor organisaties die hun AI-investeringen en gebruikersvertrouwen serieus willen beschermen, zijn monitoringtools niet optioneel—het zijn essentiële voorzieningen om AI-gaming te detecteren en te voorkomen voordat er serieuze schade ontstaat.
Technische verdediging alleen kan AI-gaming niet voorkomen; organisaties moeten een safety-first cultuur ontwikkelen waarin iedereen van directie tot engineers veiligheid en ethisch gedrag boven snelheid en winst stelt. Dit vereist leiderschap dat zich inzet voor substantiële investeringen in veiligheidsonderzoek en beveiligingstesten, ook als dit productontwikkeling vertraagt. Het Swiss cheese model van organisatorische veiligheid—waarbij meerdere imperfecte verdedigingslagen elkaars zwaktes compenseren—is direct toepasbaar op AI-systemen. Geen enkele verdediging is perfect, maar overlappende lagen creëren veerkracht. Menselijk toezicht moet door de hele AI-levenscyclus worden ingebouwd, van ontwikkeling tot uitrol, waarbij gekwalificeerd personeel kritieke beslissingen beoordeelt en verdachte patronen signaleert. Transparantie-eisen moeten vanaf het begin in het systeemontwerp worden opgenomen, niet achteraf toegevoegd, zodat belanghebbenden begrijpen hoe AI-systemen werken en welke data ze gebruiken. Verantwoordingsmechanismen moeten duidelijk verantwoordelijkheid toewijzen voor AI-gedrag, met consequenties voor nalatigheid of wangedrag. Red teaming-oefeningen dienen regelmatig door externe experts uitgevoerd te worden, met bevindingen als input voor continue verbetering. Organisaties zouden gefaseerde uitrolprocessen moeten hanteren waarbij nieuwe AI-systemen uitgebreid worden getest in gecontroleerde omgevingen vóór brede inzet, met veiligheidsverificatie in elke stap. Deze cultuur vraagt om het besef dat veiligheid en innovatie geen tegenstelling zijn—organisaties die stevig investeren in AI-beveiliging innoveren juist effectiever, omdat ze systemen met vertrouwen kunnen uitrollen en op de lange termijn gebruikersvertrouwen behouden.
Gaming van een AI-systeem verwijst naar het opzettelijk manipuleren of uitbuiten van AI-modellen om onbedoelde uitkomsten te genereren, beveiligingsmaatregelen te omzeilen of gevoelige informatie te verkrijgen. Dit omvat technieken als prompt injection, adversariële aanvallen, data poisoning en model extractie. In tegenstelling tot normale systeemfouten is gaming een bewuste poging om het beoogde gedrag van AI-systemen te omzeilen.
Adversariële aanvallen komen steeds vaker voor naarmate AI-systemen belangrijker worden in cruciale toepassingen. Onderzoek toont aan dat de meeste AI-systemen kwetsbaarheden hebben die uitgebuit kunnen worden. De toegankelijkheid van aanvalstools en -technieken betekent dat zowel geavanceerde aanvallers als gewone gebruikers AI-systemen kunnen gamen, wat dit tot een breed probleem maakt.
Geen enkele verdediging biedt volledige immuniteit tegen gaming. Organisaties kunnen het risico echter aanzienlijk verkleinen door gelaagde verdedigingen toe te passen, zoals adversariële training, datavalidatie, output-obfuscatie, rate limiting en continue monitoring. De meest effectieve aanpak combineert technische maatregelen met organisatorische praktijken en menselijke controle.
Normale AI-fouten ontstaan wanneer systemen fouten maken door beperkingen in trainingsdata of modelarchitectuur. Gaming betreft bewuste manipulatie om kwetsbaarheden uit te buiten. Gaming is intentioneel, vaak onzichtbaar voor gebruikers, en bedoeld om de aanvaller te bevoordelen ten koste van het systeem of de gebruikers. Normale fouten zijn onbedoelde systeemstoringen.
Consumenten kunnen zich beschermen door te weten hoe AI-systemen werken, te begrijpen dat hun data wordt gebruikt om hun gedrag te beïnvloeden, en kritisch te zijn op aanbevelingen die te perfect lijken afgestemd. Het steunen van transparantie-eisen, het gebruiken van privacybeschermende tools en het pleiten voor strengere AI-regelgeving helpt ook. Kennis over AI-manipulatietechnieken wordt steeds belangrijker.
Regelgeving is essentieel om AI-gaming op grote schaal te voorkomen. Huidige kaders zoals de EU AI Act richten zich vooral op fysiek en psychologisch letsel, terwijl economische schade grotendeels buiten beschouwing blijft. Effectieve regelgeving vereist verantwoordingskaders, verbeterde bevoegdheden voor consumentenbescherming, internationale coördinatie en duidelijke regels die manipulatieve AI-praktijken verbieden zonder innovatie te remmen.
AI-monitoringplatforms bieden realtime inzicht in hoe AI-systemen zich gedragen en gebruikt worden. Ze detecteren afwijkingen die kunnen wijzen op adversariële aanvallen, volgen ongebruikelijke querypatronen die duiden op model extractiepogingen, en signaleren wanneer systeemuitvoer afwijkt van verwacht gedrag. Dit inzicht maakt snelle reactie op bedreigingen mogelijk voordat er grote schade optreedt.
Kosten omvatten directe financiële verliezen door fraude en manipulatie, reputatieschade door beveiligingsincidenten, juridische aansprakelijkheid en boetes, operationele verstoring door systeemuitval en langdurig verlies van gebruikersvertrouwen. Voor consumenten zijn er minder waardevolle diensten, privacyschendingen en uitbuiting van gedragskwetsbaarheden. De totale economische impact is aanzienlijk en groeiend.
AmICited bewaakt hoe AI-systemen worden genoemd en gebruikt op verschillende platforms, zodat u gamingpogingen en manipulatie in realtime kunt detecteren. Krijg inzicht in het gedrag van uw AI en blijf bedreigingen een stap voor.
Ontdek hoe semantisch begrip de nauwkeurigheid van AI-citaties, bronvermelding en betrouwbaarheid in AI-gegenereerde content beïnvloedt. Leer de rol van context...

Ontdek wat agentische AI is, hoe autonome AI-agenten werken, hun praktijktoepassingen, voordelen en uitdagingen. Ontdek hoe agentische AI enterprise-automatiser...
Ontdek hoe entertainmentmerken hun zichtbaarheid optimaliseren in AI-aanbevelingen op streamingplatforms. Leer strategieën om AI-aanwezigheid te monitoren en co...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.