
Beste Manier om Koppen te Formatteren voor AI: Complete Gids voor 2025
Ontdek de best practices voor het formatteren van koppen voor AI-systemen. Leer hoe een juiste H1-, H2- en H3-hiërarchie AI-inhoudsophaling, citaties en zichtba...
10 min lezen
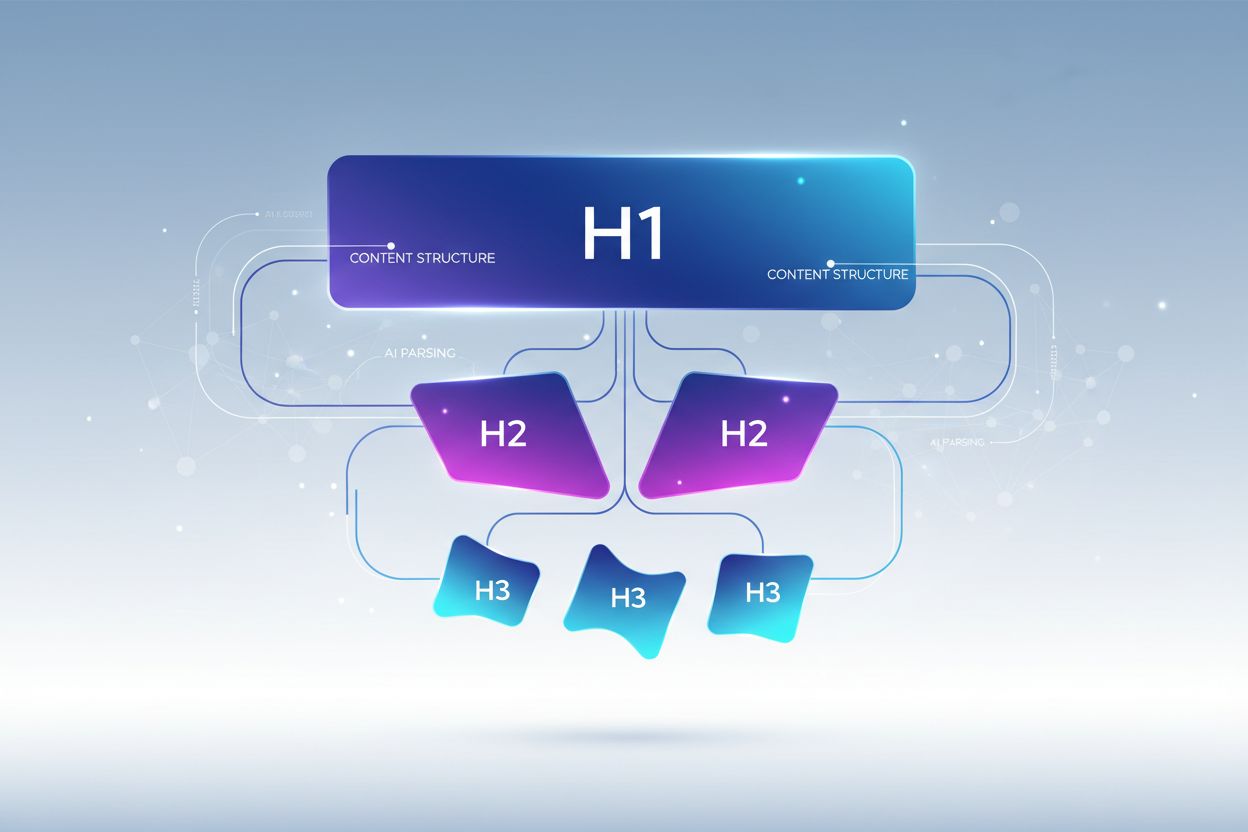
Leer hoe je de kopteksthiërarchie optimaliseert voor LLM-parsing. Beheers de H1-, H2-, H3-structuur om AI-zichtbaarheid, citaties en vindbaarheid van content te verbeteren in ChatGPT, Perplexity en Google AI Overviews.
Grote taalmodellen verwerken content fundamenteel anders dan menselijke lezers, en dit onderscheid begrijpen is cruciaal voor het optimaliseren van je contentstrategie. Waar mensen pagina’s visueel scannen en intuïtief de documentstructuur aanvoelen, vertrouwen LLM’s op tokenisatie en attention-mechanismen om betekenis uit opeenvolgende tekst te halen. Wanneer een LLM je content tegenkomt, splitst het deze in tokens (kleine tekstonderdelen) en kent het attention-gewichten toe aan verschillende secties op basis van structurele signalen—en kopteksthiërarchie is een van de krachtigste structurele signalen die er zijn. Zonder duidelijke koptekstorganisatie hebben LLM’s moeite om hoofdonderwerpen, ondersteunende argumenten en contextuele relaties binnen je content te identificeren, wat leidt tot minder nauwkeurige antwoorden en verminderde zichtbaarheid in AI-gestuurde zoek- en ophaalsystemen.
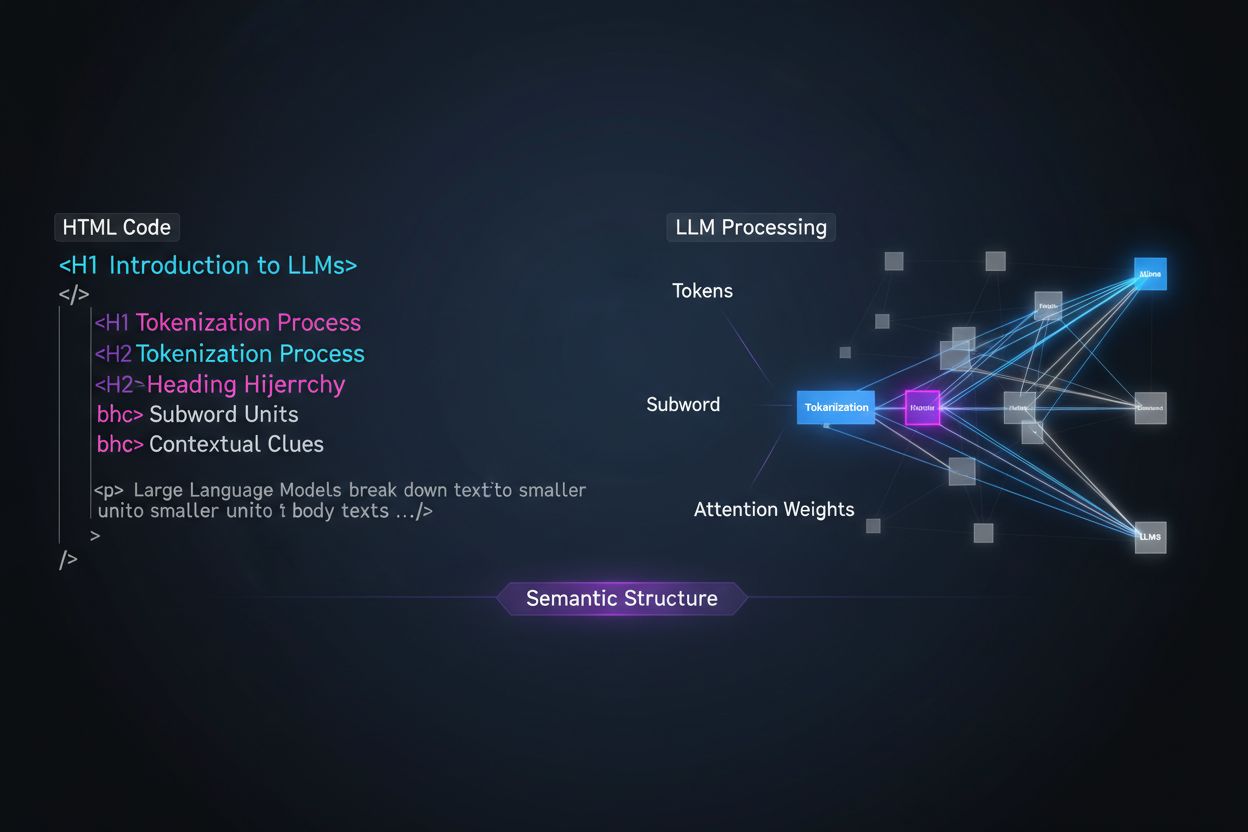
Moderne content-chunking strategieën in retrieval-augmented generation (RAG)-systemen en AI-zoekmachines zijn sterk afhankelijk van koptekststructuur om te bepalen waar documenten in ophaalbare segmenten worden gesplitst. Wanneer een LLM goed georganiseerde kopteksthiërarchieën tegenkomt, gebruikt het H2- en H3-grenzen als natuurlijke splitslijnen voor het creëren van semantische chunks—afgebakende informatiedelen die onafhankelijk kunnen worden opgehaald en geciteerd. Dit proces is veel effectiever dan willekeurig splitsen op aantal tekens omdat chunks op basis van kopteksten semantische samenhang en context behouden. Zie het verschil tussen twee benaderingen:
| Benadering | Chunkkwaliteit | LLM-citatiegraad | Ophaalnauwkeurigheid |
|---|---|---|---|
| Semantisch-rijk (koptekst-gebaseerd) | Hoge samenhang, volledige gedachten | 3x hoger | 85%+ nauwkeurigheid |
| Generiek (tekentellings-gebaseerd) | Gefragmenteerd, onvolledige context | Basislijn | 45-60% nauwkeurigheid |
Uit onderzoek blijkt dat documenten met duidelijke kopteksthiërarchieën 18-27% betere vraag-en-antwoord-nauwkeurigheid behalen bij verwerking door LLM’s, vooral omdat het chunking-proces de logische relaties tussen ideeën bewaart. Systemen zoals Retrieval-Augmented Generation (RAG)-pipelines, die tools aandrijven zoals de browsefunctie van ChatGPT en enterprise AI-systemen, zoeken expliciet naar koptekststructuren om hun retrieval-systemen te optimaliseren en de citatienauwkeurigheid te verbeteren.
Een goede kopteksthiërarchie volgt een strikte neststructuur die weerspiegelt hoe LLM’s informatie verwachten, waarbij elk niveau een duidelijke rol heeft in je contentarchitectuur. De H1-tag geeft het hoofdonderwerp van je document weer—er mag maar één per pagina zijn, en deze moet het hoofdonderwerp duidelijk weergeven. H2-tags zijn de grote onderverdelingen die de H1 ondersteunen of uitwerken, elk met een eigen aspect van het hoofdonderwerp. H3-tags gaan dieper in op specifieke subonderwerpen binnen elke H2-sectie, bieden gedetailleerde uitleg en beantwoorden vervolgvragen. De belangrijkste regel voor LLM-optimalisatie is dat je nooit niveaus overslaat (bijvoorbeeld van H1 direct naar H3 springt) en consistente nesting aanhoudt—elke H3 hoort bij een H2, en elke H2 hoort bij een H1. Deze hiërarchische structuur creëert wat onderzoekers een “semantische boom” noemen die LLM’s kunnen doorlopen om de logische opbouw van je content te begrijpen en relevante informatie nauwkeurig te extraheren.
De meest effectieve koptekststrategie voor LLM-zichtbaarheid behandelt elke H2-kop als een direct antwoord op een specifieke gebruikersintentie of vraag, waarbij H3-koppen subvragen zijn die verdere details geven. Deze “antwoordgerichte” aanpak sluit aan bij hoe moderne LLM’s informatie ophalen en samenstellen—ze zoeken naar content die direct ingaat op gebruikersvragen, en kopteksten die antwoorden bevatten worden veel vaker geselecteerd en geciteerd. Elke H2 moet functioneren als een antwoordeenheid, een zelfstandig antwoord op een specifieke vraag die een gebruiker over je onderwerp kan stellen. Als je H1 bijvoorbeeld “Hoe optimaliseer je websiteprestaties” is, kunnen je H2’s zijn “Verminder afbeeldingsbestandsgroottes (verbetert laadtijd met 40%)” of “Implementeer browsercaching (vermindert serveraanvragen met 60%)"—elke koptekst beantwoordt direct een specifieke prestatievraag. De H3’s onder elke H2 behandelen dan vervolgvragen: onder “Verminder afbeeldingsbestandsgroottes” kun je H3’s gebruiken als “Kies het juiste afbeeldingsformaat”, “Comprimeer zonder kwaliteitsverlies” en “Implementeer responsive afbeeldingen”. Deze structuur maakt het voor LLM’s veel eenvoudiger om je content te identificeren, extraheren en citeren omdat de kopteksten zelf het antwoord bevatten, niet alleen het onderwerp.
Je koptekststrategie transformeren voor maximale LLM-zichtbaarheid vereist het toepassen van specifieke, concrete technieken die verder gaan dan alleen structuur. Dit zijn de meest effectieve optimalisatiemethoden:
Gebruik beschrijvende, specifieke kopteksten: Vervang vage titels als “Overzicht” of “Details” door specifieke beschrijvingen zoals “Hoe machine learning de nauwkeurigheid van aanbevelingen verbetert” of “Drie factoren die zoekresultaten beïnvloeden”. Uit onderzoek blijkt dat specifieke kopteksten LLM-citaties tot 3x verhogen ten opzichte van generieke titels.
Implementeer kopteksten in vraagvorm: Structureer H2’s als directe vragen die gebruikers stellen (“Wat is semantisch zoeken?” of “Waarom is kopteksthiërarchie belangrijk?”). LLM’s zijn getraind op Q&A-data en geven van nature prioriteit aan kopteksten in vraagvorm bij het ophalen van antwoorden.
Zorg voor entiteit-clariteit in kopteksten: Noem bij het bespreken van specifieke concepten, tools of entiteiten deze expliciet in je kopteksten in plaats van voornaamwoorden of vage verwijzingen te gebruiken. Bijvoorbeeld, “PostgreSQL-prestatieoptimalisatie” is veel LLM-vriendelijker dan “Database-optimalisatie”.
Combineer geen meerdere intenties: Elke koptekst moet één, duidelijk afgebakend onderwerp behandelen. Koppen als “Installatie, configuratie en troubleshooting” verwateren de semantische helderheid en verwarren LLM-chunking-algoritmes.
Voeg kwantificeerbare context toe: Voeg waar relevant cijfers, percentages of tijdsbestekken toe aan kopteksten (“Verlaag laadtijd met 40% door afbeeldingsoptimalisatie” versus “Afbeeldingsoptimalisatie”). Uit studies blijkt dat 80% van LLM-geciteerde content kwantificeerbare context in kopteksten bevat.
Gebruik parallelle structuur op elk niveau: Houd consistente grammaticale structuur aan bij H2’s en H3’s binnen dezelfde sectie. Als één H2 met een werkwoord begint (“Implementeer caching”), laat anderen dat ook doen (“Configureer database-indexen”, “Optimaliseer queries”).
Verwerk keywords op natuurlijke wijze: Niet alleen voor SEO, maar het opnemen van relevante keywords in kopteksten helpt LLM’s om de relevantie te begrijpen en verhoogt de retrievalnauwkeurigheid met 25-35%.
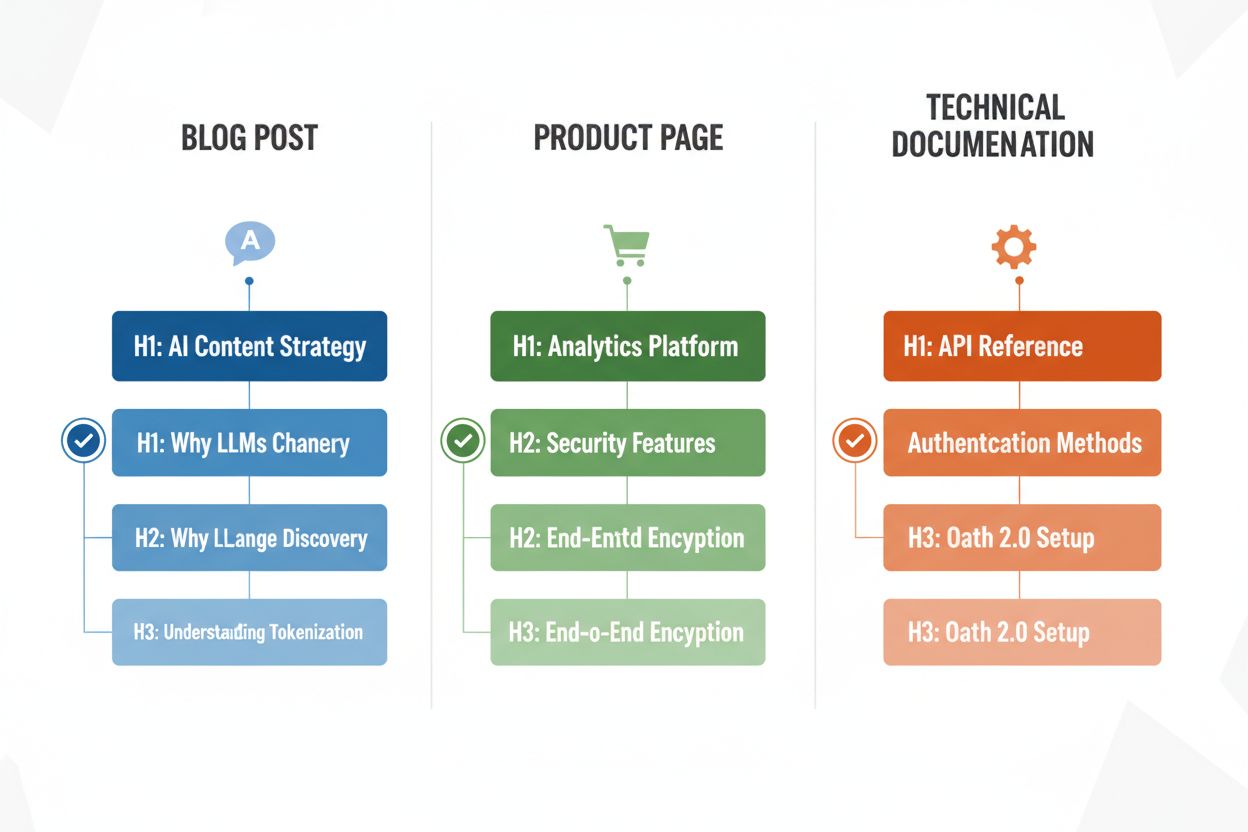
Verschillende contenttypes vereisen aangepaste koptekststrategieën om de effectiviteit van LLM-parsing te maximaliseren, en het begrijpen van deze patronen zorgt ervoor dat je content geoptimaliseerd is, ongeacht het format. Blogposts profiteren van verhalende kopteksthiërarchieën waarbij H2’s een logische opbouw volgen door een betoog of uitleg, met H3’s voor bewijs, voorbeelden of diepere verkenning—een post over “AI-contentstrategie” kan bijvoorbeeld H2’s bevatten als “Waarom LLM’s de contentontdekking veranderen”, “Hoe optimaliseer je voor AI-zichtbaarheid” en “Je AI-contentprestaties meten”. Productpagina’s moeten H2’s gebruiken die direct aansluiten op gebruikersvragen en beslissingsfactoren (“Beveiliging en compliance”, “Integratiemogelijkheden”, “Prijzen en schaalbaarheid”), met H3’s die specifieke featurevragen of use-cases behandelen. Technische documentatie vereist de meest gedetailleerde koptekststructuur, met H2’s voor hoofdfeatures of workflows en H3’s voor specifieke taken, parameters of configuratieopties—deze structuur is cruciaal omdat documentatie vaak door LLM’s wordt geciteerd bij technische vragen van gebruikers. FAQ-pagina’s moeten H2’s als de daadwerkelijke vragen gebruiken (geformuleerd als echte vragen) en H3’s voor verduidelijkingen of gerelateerde onderwerpen, want deze structuur sluit perfect aan bij hoe LLM’s Q&A-content ophalen en presenteren. Elk contenttype heeft andere gebruikersintenties, en je kopteksthiërarchie moet deze intenties weerspiegelen voor maximale relevantie en citatiekans.
Na het herstructureren van je kopteksten is validatie essentieel om te bepalen of ze daadwerkelijk de LLM-parsing en zichtbaarheid verbeteren. De meest praktische aanpak is je content direct testen met AI-tools zoals ChatGPT, Perplexity of Claude door je document te uploaden of een URL te geven en vragen te stellen waarop je kopteksten antwoord geven. Let erop of de AI-tool je content correct identificeert en citeert, en of de juiste secties worden geëxtraheerd—wordt je H2 over “Laadtijd verminderen” niet geciteerd wanneer gebruikers vragen naar prestatieoptimalisatie, dan moet je koptekst worden aangepast. Je kunt ook gespecialiseerde tools gebruiken zoals SEO-platforms met AI-citatietracking (zoals Semrush of de nieuwere AI-functies van Ahrefs) om te monitoren hoe vaak je content voorkomt in LLM-antwoorden in de tijd. Itereer op basis van resultaten: als bepaalde secties niet worden geciteerd, experimenteer dan met specifiekere of vraagvorm-kopteksten, voeg kwantificeerbare context toe of verduidelijk het verband tussen je koptekst en veelvoorkomende gebruikersvragen. Deze testcyclus duurt meestal 2-4 weken voor meetbare resultaten, omdat AI-systemen tijd nodig hebben om je content opnieuw te indexeren en beoordelen.
Zelfs goedbedoelende contentmakers maken vaak koptekstfouten die de LLM-zichtbaarheid en parsingnauwkeurigheid aanzienlijk verminderen. Een van de meest voorkomende fouten is het combineren van meerdere intenties in één koptekst—bijvoorbeeld “Installatie, configuratie en troubleshooting” dwingt LLM’s te kiezen welk onderwerp de sectie behandelt, wat vaak leidt tot verkeerde chunking en minder kans op citatie. Vage, generieke kopteksten zoals “Overzicht”, “Belangrijkste punten” of “Aanvullende informatie” bieden geen semantische helderheid en maken het voor LLM’s onmogelijk om te begrijpen welke specifieke informatie de sectie bevat; wanneer een LLM deze kopteksten tegenkomt, slaat het de sectie vaak helemaal over of interpreteert het de relevantie verkeerd. Ontbrekende context is een andere kritieke fout—een koptekst als “Best practices” vertelt een LLM niet voor welk domein of onderwerp de praktijken gelden, terwijl “Best practices voor API-rate limiting” direct duidelijk en ophaalbaar is. Inconsistente hiërarchie (niveaus overslaan, H4’s gebruiken zonder H3’s, of koptekststijlen mixen) verwart LLM-parsing-algoritmes omdat ze vertrouwen op consistente structuurpatronen om documentorganisatie te begrijpen. Een document dat bijvoorbeeld H1 → H3 → H2 → H4 gebruikt, creëert onduidelijkheid over welke secties gerelateerd zijn en welke onafhankelijk, waardoor de ophaalnauwkeurigheid met 30-40% afneemt. Je content testen met ChatGPT of vergelijkbare tools laat deze fouten snel zien—als de AI moeite heeft met de structuur of de verkeerde secties citeert, moeten je kopteksten waarschijnlijk worden herzien.
Het optimaliseren van kopteksthiërarchie voor LLM-parsing levert een krachtig bijkomend voordeel op: betere toegankelijkheid voor menselijke gebruikers met een beperking. Semantische HTML-koptekststructuur (juist gebruik van H1-H6-tags) is fundamenteel voor schermlezerfunctionaliteit, zodat visueel beperkte gebruikers efficiënt door documenten kunnen navigeren en de contentorganisatie begrijpen. Wanneer je duidelijke, beschrijvende kopteksten maakt die geoptimaliseerd zijn voor LLM-parsing, creëer je tegelijkertijd betere navigatie voor schermlezers—dezelfde specificiteit en helderheid die LLM’s helpt je content te begrijpen, helpt ook ondersteunende technologieën om gebruikers te begeleiden. Deze afstemming tussen AI-optimalisatie en toegankelijkheid is een zeldzame win-win: de technische eisen voor LLM-vriendelijke content ondersteunen direct de WCAG-toegankelijkheidsnormen en verbeteren de ervaring voor alle gebruikers. Organisaties die kopteksthiërarchie prioriteren voor AI-zichtbaarheid zien vaak onverwachte verbeteringen in toegankelijkheidscores en tevredenheidsstatistieken van gebruikers die afhankelijk zijn van ondersteunende technologieën.
Verbeteringen aan de kopteksthiërarchie doorvoeren vereist metingen om de inspanning te rechtvaardigen en te bepalen wat werkt. De meest directe KPI is de LLM-citatiegraad—houd bij hoe vaak je content verschijnt in antwoorden van ChatGPT, Perplexity, Claude en andere AI-tools door regelmatig relevante vragen te stellen en te loggen welke bronnen worden geciteerd. Tools als Semrush, Ahrefs en nieuwere platforms zoals Originality.AI bieden nu LLM-citatietracking waarmee je de zichtbaarheid van je content in AI-gegenereerde antwoorden over tijd kunt volgen. Je mag verwachten dat het aantal citaties 2-3x toeneemt binnen 4-8 weken na het implementeren van een goede kopteksthiërarchie, al verschillen de resultaten per contenttype en concurrentieniveau. Meet naast citaties ook organisch verkeer uit AI-gestuurde zoekfuncties (Google’s AI Overviews, Bing Chat-citaties, enz.) apart van traditioneel organisch zoeken, omdat hier vaak sneller verbetering zichtbaar is na koptekstoptimalisatie. Monitor daarnaast betrokkenheidsstatistieken zoals tijd-op-pagina en scroll-diepte voor pagina’s met geoptimaliseerde kopteksten—betere structuur verhoogt doorgaans de betrokkenheid met 15-25% omdat gebruikers sneller relevante informatie vinden. Meet ten slotte retrievalnauwkeurigheid in je eigen systemen als je RAG-pipelines of interne AI-tools gebruikt door te testen of de juiste secties worden opgehaald bij veelgestelde vragen. Deze statistieken samen tonen de ROI van koptekstoptimalisatie en sturen de verdere verfijning van je contentstrategie.
Kopteksthiërarchie heeft vooral invloed op AI-zichtbaarheid en LLM-citaties, niet zozeer op traditionele Google-rankings. Een goede koptekststructuur verbetert echter de algehele kwaliteit en leesbaarheid van je content, wat indirect SEO ondersteunt. Het belangrijkste voordeel is een grotere zichtbaarheid in AI-gestuurde zoekresultaten zoals Google AI Overviews, ChatGPT en Perplexity, waar koptekststructuur essentieel is voor contentextractie en citatie.
Ja, als je huidige kopteksten vaag zijn of geen duidelijke H1→H2→H3-hiërarchie volgen. Begin met het auditen van je best presterende pagina's en voer verbeteringen eerst door op content met veel verkeer. Het goede nieuws is dat LLM-vriendelijke kopteksten ook gebruiksvriendelijker zijn, dus wijzigingen zijn voordelig voor zowel mensen als AI-systemen.
Absoluut. Sterker nog, de beste koptekststructuren werken goed voor beide. Duidelijke, beschrijvende, hiërarchische kopteksten die mensen helpen de organisatie van de content te begrijpen, zijn precies wat LLM's nodig hebben voor parsing en chunking. Er is geen conflict tussen gebruiksvriendelijke en LLM-vriendelijke koptekstpraktijken.
Er is geen strikte limiet, maar streef naar 3-7 H2's per pagina, afhankelijk van de lengte en complexiteit van de content. Elke H2 moet een apart onderwerp of antwoordeenheid vertegenwoordigen. Onder elke H2 neem je 2-4 H3's op voor ondersteunende details. Pagina's met in totaal 12-15 koptekstsecties (H2's en H3's samen) presteren doorgaans goed in LLM-citaties.
Ja, zelfs korte content profiteert van een goede koptekststructuur. Een artikel van 500 woorden heeft misschien maar 1-2 H2's, maar die moeten nog steeds beschrijvend en specifiek zijn. Korte content met duidelijke kopteksten wordt vaker geciteerd in LLM-antwoorden dan ongestructureerde korte content.
Test je content direct met ChatGPT, Perplexity of Claude door vragen te stellen waarop je kopteksten antwoord moeten geven. Als de AI je content correct identificeert en citeert, werkt je structuur. Heeft de AI moeite of citeert deze de verkeerde secties, dan moeten je kopteksten worden verbeterd. De meeste verbeteringen tonen binnen 2-4 weken resultaat.
Google's AI Overviews en ChatGPT profiteren beide van een duidelijke kopteksthiërarchie, maar ChatGPT hecht er nog meer waarde aan. ChatGPT citeert content met een sequentiële koptekststructuur 3x vaker dan content zonder. De kernprincipes zijn hetzelfde, maar LLM's zoals ChatGPT zijn gevoeliger voor koptekstkwaliteit en -structuur.
Kopteksten in vraagvorm werken het beste voor FAQ-pagina's, troubleshooting-gidsen en educatieve content. Voor blogposts en productpagina's werkt een mix van vraagvorm- en stellingvormkopteksten vaak het beste. Het belangrijkste is dat kopteksten duidelijk aangeven wat de sectie behandelt, of dat nu in de vorm van een vraag of stelling is.
Volg hoe vaak je content wordt geciteerd in ChatGPT, Perplexity, Google AI Overviews en andere LLM's. Krijg realtime inzichten in je AI-zoekprestaties en optimaliseer je contentstrategie.
Ontdek de best practices voor het formatteren van koppen voor AI-systemen. Leer hoe een juiste H1-, H2- en H3-hiërarchie AI-inhoudsophaling, citaties en zichtba...
Ontdek waarom AI-modellen de voorkeur geven aan listicles en genummerde lijsten. Leer hoe je lijstgebaseerde content optimaliseert voor citaties door ChatGPT, G...
Leer hoe je je content kunt herstructureren voor AI-systemen met praktische voor en na voorbeelden. Ontdek technieken om AI-verwijzingen en zichtbaarheid te ver...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.