Hierarchia nagłówków dla AI: jak strukturyzować treści do parsowania przez LLM
Dowiedz się, jak zoptymalizować hierarchię nagłówków pod kątem parsowania przez LLM. Opanuj strukturę H1, H2, H3, aby zwiększyć widoczność w AI, cytowania oraz odkrywalność treści w ChatGPT, Perplexity i Google AI Overviews.
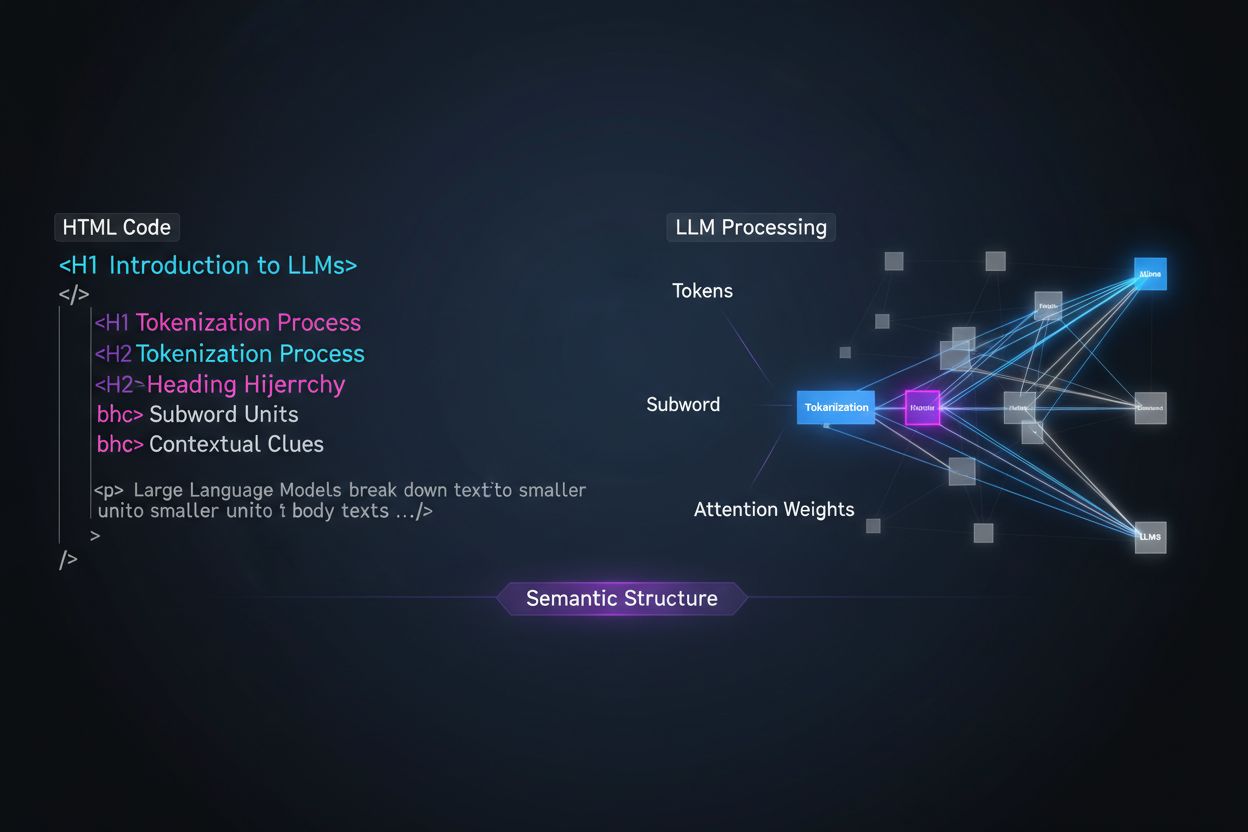
Duże modele językowe przetwarzają treści fundamentalnie inaczej niż ludzcy czytelnicy, a zrozumienie tej różnicy jest kluczowe dla optymalizacji strategii treści. Podczas gdy ludzie skanują strony wzrokiem i intuicyjnie wyczuwają strukturę dokumentu, LLM polegają na tokenizacji i mechanizmach uwagi, aby wydobyć znaczenie z sekwencyjnego tekstu. Gdy LLM napotyka Twoją treść, dzieli ją na tokeny (małe jednostki tekstu) i przypisuje wagi uwagi różnym sekcjom na podstawie sygnałów strukturalnych — a hierarchia nagłówków jest jednym z najsilniejszych dostępnych sygnałów strukturalnych. Bez jasnej organizacji nagłówków LLM mają trudności z identyfikacją głównych tematów, argumentów wspierających i relacji kontekstowych w treści, co prowadzi do mniej trafnych odpowiedzi i mniejszej widoczności w wyszukiwarkach i systemach AI opartych na ekstrakcji.
Jak hierarchia nagłówków kieruje chunkowaniem w LLM
Nowoczesne strategie chunkowania treści w systemach generowania wspomaganego wyszukiwaniem (RAG) i wyszukiwarkach AI w dużym stopniu opierają się na strukturze nagłówków, aby określić, gdzie dzielić dokumenty na segmenty możliwe do wyszukania. Gdy LLM napotyka dobrze zorganizowaną hierarchię nagłówków, wykorzystuje granice H2 i H3 jako naturalne linie cięcia do tworzenia semantycznych fragmentów — odrębnych jednostek informacji, które można niezależnie wyszukiwać i cytować. Ten proces jest znacznie skuteczniejszy niż arbitralny podział według liczby znaków, ponieważ fragmenty oparte na nagłówkach zachowują spójność semantyczną i kontekst. Zobacz różnicę między dwoma podejściami:
Podejście
Jakość fragmentów
Wskaźnik cytowań przez LLM
Trafność wyszukiwania
Semantyczne (na podstawie nagłówków)
Wysoka spójność, kompletne myśli
3x wyższy
85%+ trafności
Ogólne (liczba znaków)
Fragmentacja, brak pełnego kontekstu
Podstawowy
45-60% trafności
Badania pokazują, że dokumenty z wyraźną hierarchią nagłówków uzyskują 18-27% poprawę trafności odpowiedzi na pytania w przetwarzaniu przez LLM, głównie dlatego, że proces chunkowania zachowuje logiczne relacje między pomysłami. Systemy takie jak Retrieval-Augmented Generation (RAG), które napędzają narzędzia typu przeglądanie w ChatGPT czy rozwiązania AI dla firm, wyraźnie szukają struktury nagłówków, by zoptymalizować systemy wyszukiwania i zwiększyć trafność cytowania.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
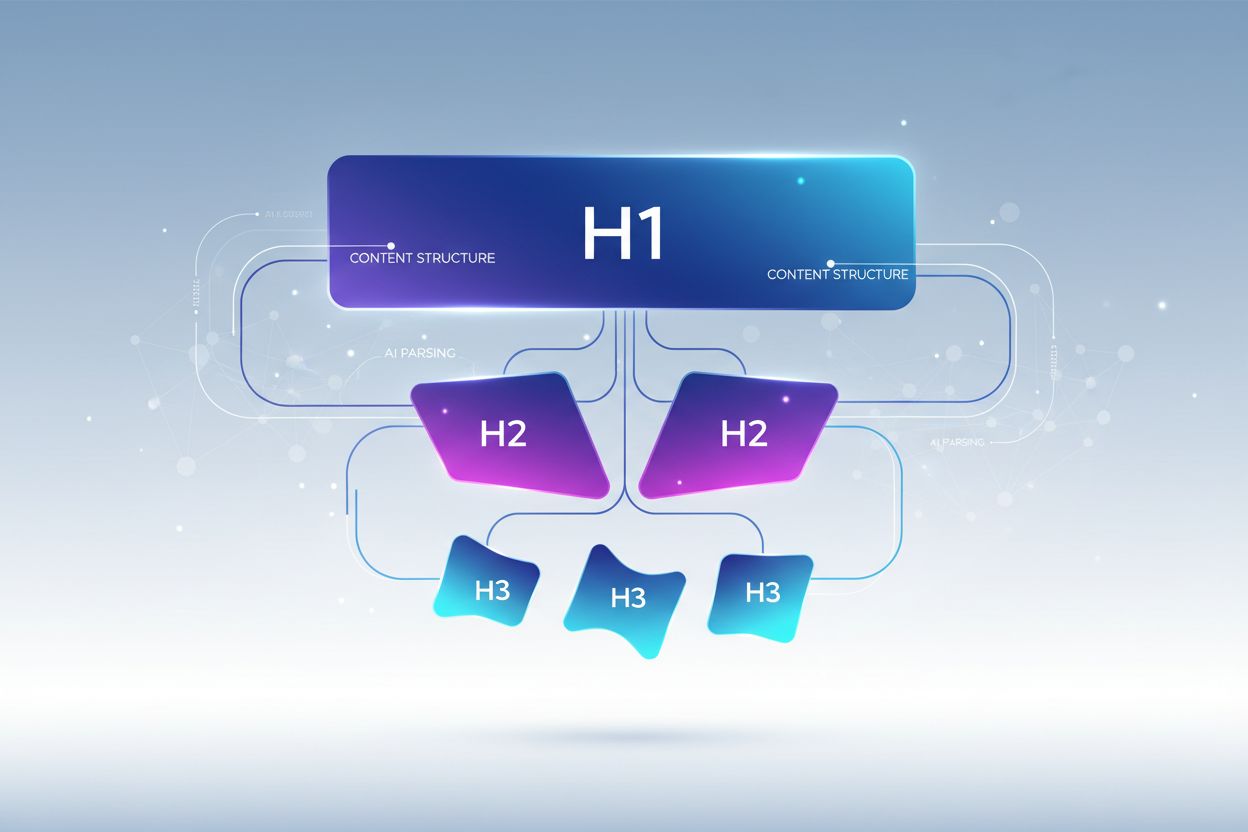
Prawidłowa hierarchia nagłówków polega na ścisłym zagnieżdżaniu, które odzwierciedla oczekiwaną przez LLM organizację informacji, gdzie każdy poziom pełni inną rolę w architekturze treści. Tag H1 oznacza główny temat dokumentu — na stronie powinien być tylko jeden i jasno określać główną tematykę. Tagi H2 to główne podziały tematyczne rozwijające lub wspierające H1, z których każdy dotyczy konkretnego aspektu głównego tematu. Tagi H3 schodzą głębiej w szczegóły podtematów w ramach danej sekcji H2, dostarczając detali i odpowiadając na pytania uzupełniające. Kluczowa zasada optymalizacji pod LLM to nie pomijać poziomów (nie przeskakiwać z H1 od razu do H3) i zachować konsekwentne zagnieżdżenie — każdy H3 musi należeć do H2, a każdy H2 do H1. Ta hierarchiczna struktura tworzy tzw. “drzewo semantyczne”, po którym LLM mogą się poruszać, by zrozumieć logiczny przepływ treści i precyzyjnie wydobyć istotne informacje.
Architektura nagłówków skupiona na odpowiedzi
Najskuteczniejsza strategia nagłówków pod kątem widoczności w LLM traktuje każdy nagłówek H2 jako bezpośrednią odpowiedź na konkretną intencję użytkownika lub pytanie, a nagłówki H3 odpowiadają na pod-pytania i dostarczają szczegółów. Takie podejście “odpowiedź najpierw” jest zgodne z tym, jak współczesne LLM wyszukują i syntezują informacje — szukają treści, które bezpośrednio odpowiadają na pytania użytkowników, a nagłówki zawierające gotowe odpowiedzi są znacznie częściej wybierane i cytowane. Każdy H2 powinien stanowić jednostkę odpowiedzi, czyli samodzielną odpowiedź na konkretne pytanie dotyczące Twojego tematu. Przykładowo, jeśli H1 to “Jak zoptymalizować wydajność strony”, Twoje H2 mogą brzmieć: “Zmniejsz rozmiary plików graficznych (przyspieszenie ładowania o 40%)” lub “Wdróż cache przeglądarki (zmniejszenie zapytań do serwera o 60%)” — każdy nagłówek odpowiada na konkretne pytanie o wydajność. H3 pod danym H2 rozwijają temat: pod “Zmniejsz rozmiary plików graficznych” mogą być H3: “Dobierz właściwy format”, “Kompresuj bez utraty jakości”, “Wdrażaj obrazy responsywne”. Taka struktura znacznie ułatwia LLM identyfikację, ekstrakcję i cytowanie treści, ponieważ same nagłówki zawierają odpowiedzi, a nie tylko ogólne etykiety.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Praktyczne techniki optymalizacji nagłówków
Aby zmaksymalizować widoczność w LLM, należy wdrożyć konkretne, praktyczne techniki wykraczające poza podstawową strukturę. Oto najskuteczniejsze metody optymalizacji:
Stosuj opisowe, konkretne nagłówki: Zamiast ogólników typu “Przegląd” czy “Szczegóły”, używaj precyzyjnych opisów: “Jak uczenie maszynowe zwiększa trafność rekomendacji” lub “Trzy czynniki wpływające na pozycje w wyszukiwarce”. Badania pokazują, że konkretne nagłówki zwiększają wskaźnik cytowań LLM nawet 3x w porównaniu do ogólnych.
Wprowadzaj nagłówki w formie pytań: Formułuj H2 jako bezpośrednie pytania użytkowników (“Czym jest wyszukiwanie semantyczne?” lub “Dlaczego hierarchia nagłówków ma znaczenie?”). LLM są trenowane na danych Q&A i naturalnie priorytetyzują nagłówki w formie pytań.
Zachowaj jasność jednostek w nagłówkach: Jeśli omawiasz konkretne pojęcia, narzędzia lub obiekty, nazwij je wprost w nagłówku zamiast używać zaimków czy ogólników. Przykładowo, “Optymalizacja wydajności PostgreSQL” jest znacznie lepsza dla LLM niż “Optymalizacja bazy danych”.
Unikaj łączenia wielu intencji: Każdy nagłówek powinien dotyczyć jednego, konkretnego tematu. Nagłówki typu “Instalacja, konfiguracja i rozwiązywanie problemów” rozmywają przekaz semantyczny i mylą algorytmy chunkowania LLM.
Dodawaj kontekst liczbowy: Gdy to możliwe, umieszczaj liczby, procenty lub ramy czasowe w nagłówkach (“Skróć czas ładowania o 40% dzięki optymalizacji obrazów” zamiast “Optymalizacja obrazów”). 80% treści cytowanych przez LLM zawiera w nagłówkach liczby lub kontekst ilościowy.
Stosuj równoległą konstrukcję: Zachowaj spójność gramatyczną H2 i H3 w ramach jednej sekcji. Jeśli jedno H2 zaczyna się od czasownika (“Wdróż cache”), reszta też powinna (“Skonfiguruj indeksy bazy”, “Optymalizuj zapytania”).
Naturalnie wplataj słowa kluczowe: Nie tylko dla SEO — obecność istotnych słów kluczowych w nagłówkach pomaga LLM zrozumieć temat i zwiększa trafność wyszukiwania o 25-35%.
Wzorce nagłówków według typu treści
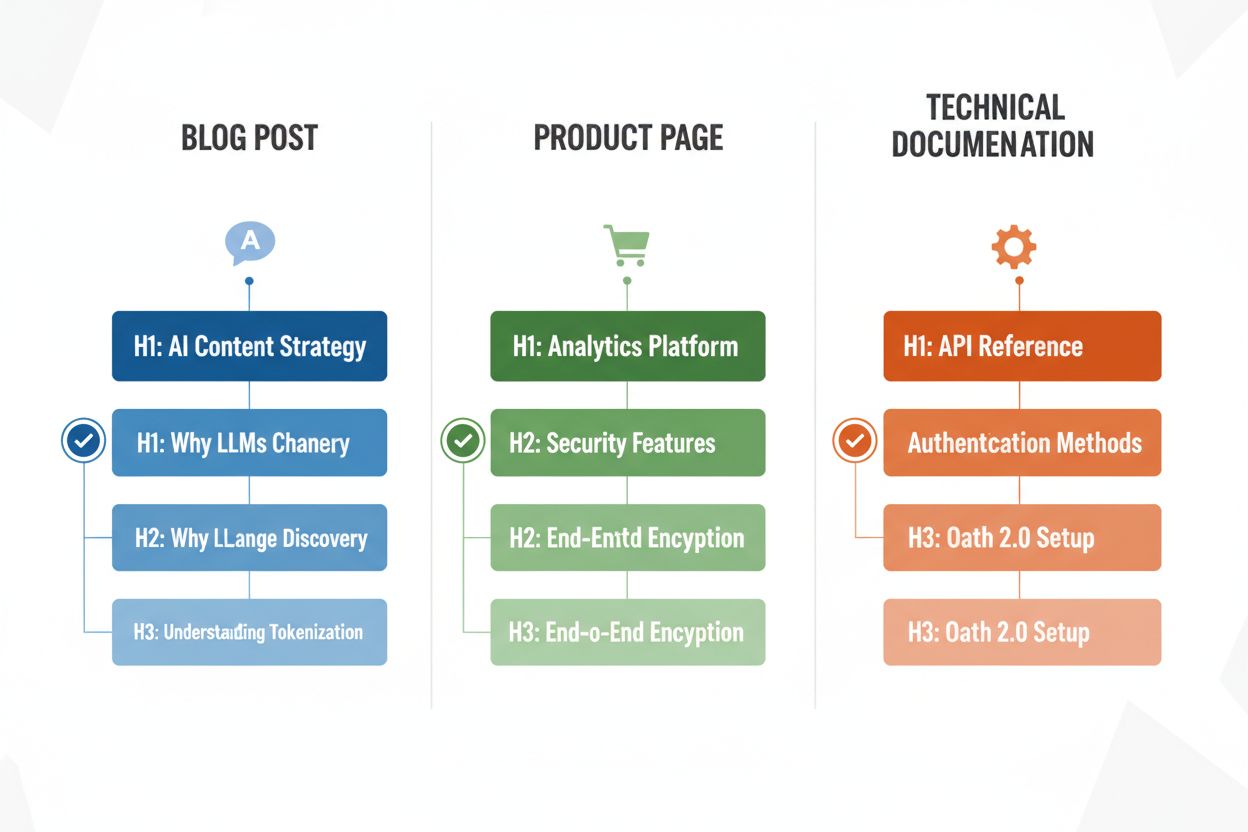
Różne typy treści wymagają dostosowanych strategii nagłówków, by maksymalizować efektywność parsowania przez LLM — znajomość tych wzorców pozwala zoptymalizować każdą formę. Wpisy blogowe korzystają z narracyjnej hierarchii nagłówków, gdzie H2 prowadzą logiczną ścieżką przez argumentację lub wyjaśnienie, a H3 dostarczają dowodów, przykładów lub głębszej analizy — np. wpis o “Strategii treści AI” może mieć H2: “Dlaczego LLM zmieniają odkrywalność treści”, “Jak zoptymalizować widoczność w AI”, “Mierzenie skuteczności treści AI”. Strony produktowe powinny stosować H2 odpowiadające na kluczowe potrzeby i pytania użytkownika (“Bezpieczeństwo i zgodność”, “Możliwości integracji”, “Cennik i skalowalność”), a H3 — konkretne pytania o funkcje lub przypadki użycia. Dokumentacja techniczna wymaga najdrobniejszej struktury, z H2 dla głównych funkcji lub procesów, a H3 dla szczegółowych zadań, parametrów czy opcji konfiguracji — ta struktura jest kluczowa, bo dokumentacja jest często cytowana przez LLM przy pytaniach technicznych. Strony FAQ powinny mieć H2 będące pytaniami (w dosłownej formie), a H3 — doprecyzowania lub tematy powiązane, bo ten układ idealnie odpowiada sposobowi prezentacji Q&A przez LLM. Każdy typ treści wiąże się z innymi intencjami użytkownika, a Twoja hierarchia nagłówków powinna je odzwierciedlać, by zmaksymalizować trafność i szansę na cytowanie.
Walidacja i testowanie struktury nagłówków
Po przebudowie nagłówków kluczowa jest walidacja, by upewnić się, że faktycznie poprawiają parsowanie i widoczność w LLM. Najpraktyczniejsza metoda to przetestowanie treści bezpośrednio w narzędziach AI, takich jak ChatGPT, Perplexity czy Claude, poprzez wgranie dokumentu lub podanie URL i zadawanie pytań, na które nagłówki mają odpowiadać. Zwracaj uwagę, czy narzędzie AI poprawnie identyfikuje i cytuje Twoją treść oraz czy wydobywa właściwe sekcje — jeśli Twój H2 o “Skracaniu czasu ładowania” nie jest cytowany przy pytaniach o optymalizację wydajności, nagłówek wymaga dopracowania. Możesz też korzystać ze specjalistycznych narzędzi SEO z funkcją śledzenia cytowań AI (np. Semrush lub nowe funkcje AI w Ahrefs), by monitorować, jak często Twoje treści pojawiają się w odpowiedziach LLM w czasie. Iteruj na podstawie wyników: jeśli pewne sekcje nie są cytowane, eksperymentuj z bardziej konkretnymi lub pytaniowymi nagłówkami, dodaj kontekst liczbowy lub doprecyzuj powiązanie nagłówka z typowymi pytaniami użytkowników. Taki cykl testowania zwykle przynosi mierzalne efekty w ciągu 2-4 tygodni, bo tyle trwa ponowne zindeksowanie i ocena treści przez systemy AI.
Typowe błędy w nagłówkach mylące LLM
Nawet autorzy z dobrą intencją często popełniają błędy strukturalne znacznie ograniczające widoczność w LLM i skuteczność parsowania. Jednym z najczęstszych jest łączenie wielu intencji w jednym nagłówku — np. “Instalacja, konfiguracja i rozwiązywanie problemów” zmusza LLM do wyboru, którego tematu dotyczy sekcja, co prowadzi do błędnego dzielenia i zmniejsza szansę na cytowanie. Niejasne, ogólne nagłówki typu “Przegląd”, “Kluczowe informacje” czy “Dodatkowe dane” nie dają jasności semantycznej i uniemożliwiają LLM określenie, co zawiera sekcja; AI często pomija wtedy taki fragment lub źle interpretuje jego znaczenie. Brak kontekstu to kolejny krytyczny błąd — nagłówek “Dobre praktyki” nie mówi LLM, do jakiej dziedziny się odnosi, podczas gdy “Dobre praktyki w limitowaniu API” jest od razu jasny i możliwy do wyszukania. Niespójna hierarchia (pomijanie poziomów, użycie H4 bez H3 czy mieszanie stylów nagłówków) myli algorytmy LLM, które polegają na powtarzalnych wzorcach strukturalnych do zrozumienia dokumentu. Przykładowo dokument z H1 → H3 → H2 → H4 wprowadza niejasność, które sekcje są powiązane, a które niezależne, co obniża trafność wyszukiwania o 30-40%. Testowanie treści w ChatGPT czy podobnym narzędziu szybko ujawni te błędy — jeśli AI ma problem ze zrozumieniem struktury lub cytuje złe fragmenty, nagłówki wymagają korekty.
Hierarchia nagłówków a dostępność
Optymalizacja hierarchii nagłówków pod kątem parsowania przez LLM przynosi potężną dodatkową korzyść: poprawę dostępności dla użytkowników z niepełnosprawnościami. Semantyczna struktura HTML (właściwe użycie tagów H1-H6) jest podstawą dla czytników ekranu, pozwalając osobom niewidomym i słabowidzącym na sprawną nawigację i zrozumienie organizacji treści. Tworząc jasne, opisowe nagłówki zoptymalizowane pod LLM, jednocześnie tworzysz lepszą nawigację dla czytników ekranu — ta sama precyzja i jasność, która pomaga LLM, ułatwia asystującym technologiom prowadzenie użytkownika przez treść. To rzadka sytuacja “win-win”: wymagania techniczne pod kątem AI wspierają standardy dostępności WCAG i poprawiają doświadczenie wszystkich użytkowników. Organizacje priorytetyzujące hierarchię nagłówków dla AI często zauważają nieoczekiwaną poprawę wyników zgodności z dostępnością oraz satysfakcji użytkowników korzystających z technologii wspomagających.
Wdrożenie ulepszeń hierarchii nagłówków wymaga pomiaru efektów, by uzasadnić wysiłek i zidentyfikować skuteczne działania. Najbardziej bezpośredni KPI to wskaźnik cytowań przez LLM — śledź, jak często Twoje treści pojawiają się w odpowiedziach ChatGPT, Perplexity, Claude i innych narzędzi AI, regularnie zadając powiązane pytania i rejestrując cytowane źródła. Narzędzia takie jak Semrush, Ahrefs czy nowe platformy typu Originality.AI oferują już monitorowanie cytowań przez LLM w czasie. Możesz spodziewać się 2-3x wzrostu cytowań w ciągu 4-8 tygodni od wdrożenia właściwej hierarchii nagłówków, choć wyniki zależą od typu treści i konkurencji. Poza cytowaniami, osobno śledź ruch organiczny z funkcji wyszukiwania opartych na AI (Google AI Overviews, cytaty w Bing Chat itd.), bo tam efekty często są szybsze niż w klasycznym SEO. Dodatkowo monitoruj zaangażowanie użytkowników (czas na stronie, głębokość przewijania) na stronach z zoptymalizowanymi nagłówkami — lepsza struktura zwykle zwiększa zaangażowanie o 15-25%, bo użytkownicy łatwiej znajdują poszukiwane informacje. Na koniec mierz trafność wyszukiwania w swoich systemach (jeśli korzystasz z RAG lub wewnętrznych narzędzi AI), testując czy odpowiednie sekcje są zwracane na typowe zapytania. Te metryki wspólnie pokazują ROI optymalizacji nagłówków i wskazują kierunki dalszego doskonalenia strategii treści.
Najczęściej zadawane pytania
Hierarchia nagłówków wpływa głównie na widoczność w AI i cytowania przez LLM, a nie bezpośrednio na tradycyjne pozycje Google. Jednak właściwa struktura nagłówków poprawia ogólną jakość i czytelność treści, co pośrednio wspiera SEO. Główną korzyścią jest zwiększona widoczność w wynikach wyszukiwania opartych na AI, takich jak Google AI Overviews, ChatGPT i Perplexity, gdzie struktura nagłówków jest kluczowa dla ekstrakcji treści i cytowania.
Tak, jeśli Twoje obecne nagłówki są niejasne lub nie stosują jasnej hierarchii H1→H2→H3. Zacznij od audytu najlepiej działających stron i wdrażaj poprawki nagłówków najpierw w treściach o największym ruchu. Dobra wiadomość jest taka, że nagłówki przyjazne LLM są także bardziej przyjazne użytkownikom, więc zmiany przynoszą korzyści zarówno ludziom, jak i systemom AI.
Zdecydowanie. Najlepsze struktury nagłówków sprawdzają się dla obu. Przejrzyste, opisowe, hierarchiczne nagłówki pomagające ludziom rozumieć organizację treści są dokładnie tym, czego LLM potrzebują do parsowania i dzielenia treści. Nie ma konfliktu między praktykami przyjaznymi dla ludzi i dla LLM.
Nie ma sztywnej granicy, ale dąż do 3-7 H2 na stronę, w zależności od długości i złożoności treści. Każdy H2 powinien reprezentować odrębny temat lub jednostkę odpowiedzi. Pod każdym H2 umieść 2-4 H3 z informacjami szczegółowymi. Strony z 12-15 sekcjami nagłówków (łącznie H2 i H3) zwykle dobrze wypadają w cytowaniach LLM.
Tak, nawet krótkie treści zyskują na prawidłowej strukturze nagłówków. Artykuł na 500 słów może mieć tylko 1-2 H2, ale powinny być one opisowe i konkretne. Krótkie treści z jasnymi nagłówkami są częściej cytowane przez LLM niż niestrukturyzowane krótkie teksty.
Przetestuj treść bezpośrednio w ChatGPT, Perplexity lub Claude, zadając pytania, na które nagłówki mają odpowiadać. Jeśli AI poprawnie zidentyfikuje i zacytuje Twoją treść, struktura działa. Jeśli AI ma trudności lub cytuje złe sekcje, nagłówki wymagają dopracowania. Większość poprawek daje efekty w ciągu 2-4 tygodni.
Zarówno Google AI Overviews, jak i ChatGPT korzystają z przejrzystej hierarchii nagłówków, ale ChatGPT przykłada do niej jeszcze większą wagę. ChatGPT cytuje treści ze spójną strukturą nagłówków 3x częściej niż te bez niej. Zasady są te same, ale LLM takie jak ChatGPT są bardziej wrażliwe na jakość i strukturę nagłówków.
Nagłówki w formie pytań najlepiej sprawdzają się na stronach FAQ, w poradnikach rozwiązywania problemów i treściach edukacyjnych. W przypadku blogów i stron produktowych często najlepiej działa mieszanka pytań i stwierdzeń. Kluczowe jest, aby nagłówki jasno określały zakres sekcji, czy to w formie pytania, czy stwierdzenia.
Monitoruj widoczność swojej marki w AI
Śledź, jak często Twoje treści są cytowane w ChatGPT, Perplexity, Google AI Overviews i innych LLM. Uzyskaj wgląd w czasie rzeczywistym w efektywność wyszukiwania AI i optymalizuj swoją strategię treści.
Najlepszy sposób formatowania nagłówków dla AI: Kompletny przewodnik na 2025 rok
Poznaj najlepsze praktyki formatowania nagłówków dla systemów AI. Dowiedz się, jak prawidłowa hierarchia H1, H2, H3 poprawia pobieranie treści przez AI, cytowan...
Jak poprawić czytelność treści dla systemów AI i wyszukiwarek AI
Dowiedz się, jak zoptymalizować czytelność treści dla systemów AI, ChatGPT, Perplexity i wyszukiwarek AI. Poznaj najlepsze praktyki dotyczące struktury, formato...
Restrukturyzacja treści pod kątem AI: Przykłady przed i po
Dowiedz się, jak restrukturyzować treści pod systemy AI na praktycznych przykładach przed i po. Odkryj techniki poprawiające cytowania przez AI i widoczność w C...
9 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.