Ontdek hoe Retrieval-Augmented Generation AI-verwijzingen transformeert, waardoor nauwkeurige bronvermelding en onderbouwde antwoorden mogelijk zijn in ChatGPT, Perplexity en Google AI Overviews.
Gepubliceerd op Jan 3, 2026.Laatst gewijzigd op Jan 3, 2026 om 3:24 am
Grote taalmodellen hebben AI getransformeerd, maar ze hebben een fundamenteel mankement: kennis-cutoffs. Deze modellen zijn getraind op data tot een specifiek moment, wat betekent dat ze geen toegang hebben tot informatie die daarna is verschenen. Naast veroudering lijden traditionele LLM’s aan hallucinaties—ze genereren vol vertrouwen onjuiste informatie die plausibel klinkt—en geven geen bronvermelding bij hun uitspraken. Wanneer een bedrijf actuele marktdata, eigen onderzoek of verifieerbare feiten nodig heeft, schieten traditionele LLM’s tekort en laten ze gebruikers achter met antwoorden die niet te vertrouwen of te verifiëren zijn.
Wat is RAG - Kernbegrip & Componenten
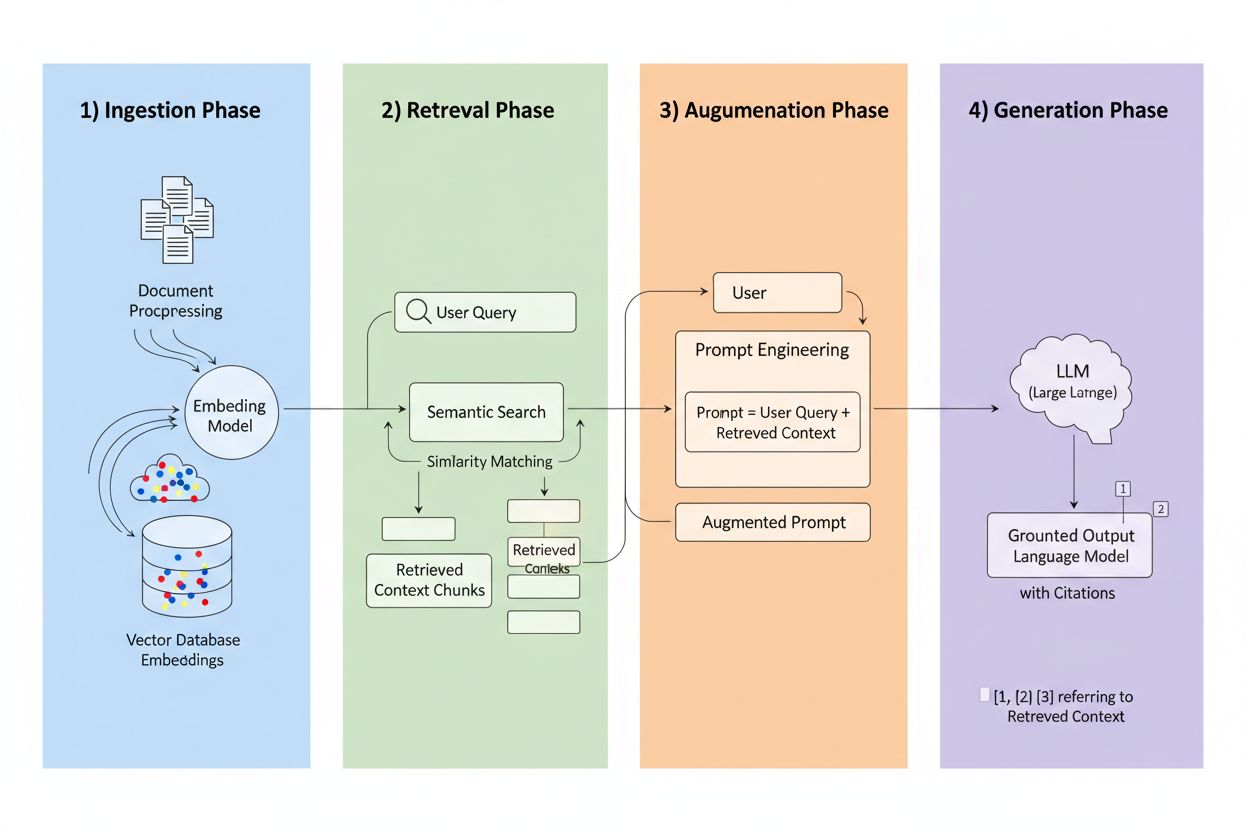
Retrieval-Augmented Generation (RAG) is een raamwerk dat het generatieve vermogen van LLM’s combineert met de precisie van informatieretrievalsystemen. In plaats van alleen te vertrouwen op trainingsdata, halen RAG-systemen relevante informatie uit externe bronnen voordat ze antwoorden genereren, waardoor een pijplijn ontstaat die antwoorden baseert op echte data. De vier kerncomponenten werken samen: Inname (documenten omzetten naar doorzoekbare formaten), Retrieval (de meest relevante bronnen vinden), Augmentatie (de prompt verrijken met opgehaalde context) en Generatie (het uiteindelijke antwoord met bronvermelding creëren). Zo vergelijkt RAG zich met traditionele benaderingen:
Aspect
Traditionele LLM
RAG-systeem
Kennisbron
Statistische trainingsdata
Externe geïndexeerde bronnen
Verwijzingsmogelijkheid
Geen/gefantaseerd
Herleidbaar naar bronnen
Nauwkeurigheid
Vatbaar voor fouten
Gebaseerd op feiten
Realtime data
Nee
Ja
Hallucinatierisico
Hoog
Laag
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
De retrieval-engine is het kloppende hart van RAG en veel geavanceerder dan simpelweg zoeken op trefwoord. Documenten worden omgezet in vector-embeddings—wiskundige representaties die semantische betekenis vangen—waardoor het systeem conceptueel vergelijkbare content kan vinden, zelfs als exacte woorden niet overeenkomen. Het systeem verdeelt documenten in behapbare stukken, meestal 256-1024 tokens, wat contextbehoud in balans brengt met precisie van retrieval. De meeste geavanceerde RAG-systemen gebruiken hybride zoekmethodes, waarbij semantische gelijkenis wordt gecombineerd met traditionele zoekwoordenmatching om zowel conceptuele als exacte overeenkomsten te vinden. Een herordeningmechanisme scoort vervolgens deze kandidaten, vaak met cross-encoder-modellen die relevantie nauwkeuriger inschatten dan de initiële retrieval. Relevantie wordt berekend op basis van meerdere signalen: semantische gelijkenisscores, trefwoordinvloed, metadatasynchronisatie en domeinautoriteit. Het hele proces vindt plaats in milliseconden, zodat gebruikers snelle, nauwkeurige antwoorden krijgen zonder merkbare vertraging.
Het voordeel van bronvermelding
Hier verandert RAG het verwijzingslandschap: wanneer een systeem informatie ophaalt uit een specifieke geïndexeerde bron, wordt die bron herleidbaar en verifieerbaar. Elk tekstfragment kan worden teruggeleid naar het originele document, de URL of publicatie, waardoor verwijzing automatisch wordt in plaats van gehallucineerd. Deze fundamentele verschuiving creëert ongekende transparantie in AI-besluitvorming—gebruikers kunnen precies zien welke bronnen het antwoord hebben gevormd, claims zelfstandig verifiëren en zelf de betrouwbaarheid van bronnen beoordelen. In tegenstelling tot traditionele LLM’s, waar verwijzingen vaak zijn verzonnen of generiek, zijn RAG-verwijzingen gebaseerd op daadwerkelijke retrieval-events. Deze herleidbaarheid vergroot het vertrouwen van gebruikers aanzienlijk, omdat mensen informatie kunnen valideren in plaats van deze op goed vertrouwen te accepteren. Voor contentmakers en uitgevers betekent dit dat hun werk ontdekt en gecrediteerd kan worden door AI-systemen, wat volledig nieuwe zichtbaarheid oplevert.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Kwaliteitsfactoren voor verwijzingen in RAG-systemen
Niet alle bronnen zijn gelijk in RAG-systemen, en verschillende factoren bepalen welke content het vaakst wordt aangehaald:
Autoriteit: Domeinreputatie, backlinkprofielen en aanwezigheid in kennisgrafieken signaleren betrouwbaarheid aan retrieval-algoritmes
Actualiteit: Content die binnen 48-72 uur is bijgewerkt, scoort hoger, omdat frisheid actieve onderhoud en betrouwbaarheid aanduidt
Relevantie: Semantische aansluiting op gebruikersvragen bepaalt of content überhaupt in de retrievalresultaten verschijnt
Structuur: Duidelijke hiërarchie, beschrijvende koppen en semantische markup helpen systemen informatie nauwkeurig te begrijpen en extraheren
Feitendichtheid: Content met veel specifieke data, statistieken en verwijzingen biedt meer bruikbare fragmenten dan generieke overzichten
Kennisgrafiek: Aanwezigheid op Wikipedia, Wikidata of branchegerichte kennisbanken verhoogt de kans op verwijzing aanzienlijk
Elke factor versterkt de andere—een goed gestructureerd, vaak bijgewerkt artikel van een autoritair domein met sterke backlinks en kennisgrafiekaanwezigheid wordt een verwijzingsmagneet in RAG-systemen. Dit creëert een nieuw optimalisatieparadigma waarbij zichtbaarheid minder afhankelijk is van SEO-verkeer en meer van het worden van een betrouwbare, gestructureerde informatiebron.
Hoe verschillende AI-platforms RAG gebruiken voor verwijzingen
Verschillende AI-platforms implementeren RAG met uiteenlopende strategieën, wat leidt tot verschillende verwijzingspatronen. ChatGPT geeft veel gewicht aan Wikipedia-bronnen; studies tonen aan dat ongeveer 26-35% van de verwijzingen alleen al uit Wikipedia komt, vanwege de autoriteit en gestructureerde opzet. Google AI Overviews hanteren een meer diverse bronselectie en halen uit nieuwssites, academische artikelen en fora, waarbij Reddit in ongeveer 5% van de verwijzingen voorkomt ondanks een lagere traditionele autoriteit. Perplexity AI citeert doorgaans 3-5 bronnen per antwoord en heeft een sterke voorkeur voor branchespecifieke publicaties en recent nieuws, waarbij wordt geoptimaliseerd voor volledigheid en actualiteit. Deze platforms wegen domeinautoriteit verschillend—sommigen geven prioriteit aan traditionele indicatoren zoals backlinks en domeinleeftijd, terwijl anderen contentfrisheid en semantische relevantie benadrukken. Inzicht in deze platformspecifieke retrievalstrategieën is cruciaal voor contentmakers, want optimalisatie voor het ene platform kan sterk verschillen van het andere.
RAG versus traditionele zoekopdrachten - gevolgen voor verwijzingen
De opkomst van RAG verstoort de traditionele SEO-wijsheid fundamenteel. In zoekmachineoptimalisatie correleren verwijzingen en zichtbaarheid direct met verkeer—je hebt klikken nodig om ertoe te doen. RAG keert deze vergelijking om: content kan worden aangehaald en AI-antwoorden beïnvloeden zonder enig verkeer te genereren. Een goed gestructureerd, autoritair artikel kan dagelijks in tientallen AI-antwoorden verschijnen terwijl het nul klikken ontvangt, omdat gebruikers hun antwoord direct uit de AI-samenvatting halen. Dit betekent dat autoriteitssignalen belangrijker zijn dan ooit, aangezien ze het primaire mechanisme zijn waarmee RAG-systemen bronkwaliteit beoordelen. Consistentie over platforms wordt cruciaal—als je content verschijnt op je website, LinkedIn, branche-databases en kennisgrafieken, zien RAG-systemen versterkte autoriteitssignalen. Aanwezigheid in kennisgrafieken verandert van een ’nice-to-have’ naar essentiële infrastructuur, omdat deze gestructureerde databases primaire retrievalbronnen zijn voor veel RAG-implementaties. Het verwijzingsspel is fundamenteel veranderd van “verkeer genereren” naar “een betrouwbare informatiebron worden”.
Content optimaliseren voor RAG-verwijzingen
Om het aantal RAG-verwijzingen te maximaliseren, moet de contentstrategie verschuiven van verkeeroptimalisatie naar bronoptimalisatie. Implementeer updatecycli van 48-72 uur voor evergreen content om retrievalsystemen te laten zien dat je informatie actueel blijft. Gebruik gestructureerde datamarkup (Schema.org, JSON-LD) om systemen te helpen de betekenis en relaties in je content te begrijpen. Stem je content semantisch af op veelgestelde vragen—gebruik natuurlijke taal die aansluit bij hoe mensen vragen stellen, niet alleen hoe ze zoeken. Structureer content met FAQ- en Q&A-secties, omdat deze direct aansluiten bij het vraag-antwoordpatroon van RAG-systemen. Ontwikkel of draag bij aan Wikipedia- en kennisgrafiekvermeldingen, want dit zijn primaire retrievalbronnen voor de meeste platforms. Bouw backlink-autoriteit op via strategische partnerschappen en verwijzingen van andere betrouwbare bronnen, want linkprofielen blijven sterke autoriteitssignalen. Zorg ten slotte voor consistentie over platforms heen—zorg dat je kernclaims, data en boodschappen overeenkomen op je website, sociale profielen, branche-databases en kennisgrafieken, zodat versterkte signalen van betrouwbaarheid ontstaan.
De toekomst van RAG en verwijzingen
RAG-technologie blijft zich snel ontwikkelen, met verschillende trends die verwijzingsmechanismen veranderen. Geavanceerdere retrieval-algoritmen zullen verder gaan dan semantische gelijkenis en inzetten op diepgaand begrip van vraagintentie en context, waardoor verwijzingsrelevantie verbetert. Gespecialiseerde kennisbanken zullen ontstaan voor specifieke domeinen—medische RAG-systemen met gecureerde vakliteratuur, juridische systemen met jurisprudentie en wetgeving—en nieuwe verwijzingskansen creëren voor gezaghebbende bronnen. Integratie met multi-agent-systemen stelt RAG in staat meerdere gespecialiseerde retrievers te coördineren en inzichten uit verschillende kennisbanken te combineren voor completere antwoorden. Realtime data-acces zal sterk verbeteren, zodat RAG-systemen live-informatie uit API’s, databases en streamingbronnen kunnen verwerken. Agentic RAG—waarbij AI-agenten autonoom beslissen wat ze ophalen, hoe ze het verwerken en wanneer ze itereren—zal dynamischere verwijzingspatronen opleveren, waarbij bronnen mogelijk meerdere keren worden aangehaald naarmate agenten hun redenering verfijnen.
De rol van AmICited bij RAG-verwijzingsmonitoring
Nu RAG de manier verandert waarop AI-systemen bronnen ontdekken en aanhalen, wordt inzicht in je verwijzingsprestaties essentieel. AmICited monitort AI-verwijzingen over platforms heen en volgt welke van jouw bronnen verschijnen in ChatGPT, Google AI Overviews, Perplexity en opkomende AI-systemen. Je ziet welke specifieke bronnen worden aangehaald, hoe vaak ze voorkomen en in welke context—zodat je ontdekt welke content aanslaat bij RAG-retrievalalgoritmen. Ons platform helpt je verwijzingspatronen te begrijpen binnen je contentportfolio en onthult wat bepaalde stukken verwijzingswaardig maakt en andere onzichtbaar. Meet de zichtbaarheid van je merk in AI-antwoorden met statistieken die ertoe doen in het RAG-tijdperk, voorbij de traditionele verkeersanalyse. Voer concurrentieanalyse uit van verwijzingsprestaties om te zien hoe jouw bronnen zich verhouden tot concurrenten in AI-gegenereerde antwoorden. In een wereld waar AI-verwijzingen zichtbaarheid en autoriteit bepalen, is duidelijk inzicht in je verwijzingsprestaties niet optioneel—het is hoe je concurrerend blijft.
Veelgestelde vragen
Wat is het verschil tussen RAG en traditionele LLM's?
Traditionele LLM's vertrouwen op statische trainingsdata met kennis-cutoffs en hebben geen toegang tot realtime-informatie, wat vaak leidt tot hallucinaties en niet-verifieerbare uitspraken. RAG-systemen halen informatie uit externe, geïndexeerde bronnen voordat ze antwoorden genereren, waardoor nauwkeurige bronvermelding en onderbouwde antwoorden mogelijk zijn op basis van actuele, verifieerbare data.
Hoe verbetert RAG de nauwkeurigheid van bronvermeldingen?
RAG herleidt elk stukje opgehaalde informatie naar de oorspronkelijke bron, waardoor verwijzingen automatisch en verifieerbaar worden in plaats van gehallucineerd. Dit creëert een directe link tussen het antwoord en het bronmateriaal, zodat gebruikers claims zelfstandig kunnen verifiëren en de geloofwaardigheid van de bron kunnen beoordelen.
Welke factoren bepalen welke bronnen worden aangehaald in RAG-systemen?
RAG-systemen beoordelen bronnen op basis van autoriteit (domeinreputatie en backlinks), actualiteit (inhoud geüpdatet binnen 48-72 uur), semantische relevantie voor de vraag, contentstructuur en -duidelijkheid, feitendichtheid met specifieke datapunten, en aanwezigheid in kennisgrafieken zoals Wikipedia. Deze factoren bepalen samen de kans op verwijzing.
Hoe kan ik mijn content optimaliseren voor RAG-verwijzingen?
Werk content elke 48-72 uur bij om frisheidssignalen te behouden, implementeer gestructureerde datamarkup (Schema.org), stem content semantisch af op veelvoorkomende vragen, gebruik FAQ- en Q&A-formaten, ontwikkel Wikipedia- en kennisgrafiekaanwezigheid, bouw backlink-autoriteit op en behoud consistentie op alle platforms.
Waarom is aanwezigheid in kennisgrafieken belangrijk voor AI-verwijzingen?
Kennisgrafieken zoals Wikipedia en Wikidata zijn primaire retrieval-bronnen voor de meeste RAG-systemen. Aanwezigheid in deze gestructureerde databases verhoogt de kans op verwijzing aanzienlijk en creëert fundamentele vertrouwenssignalen waar AI-systemen vaak naar verwijzen bij diverse vragen.
Hoe vaak moet ik content bijwerken voor RAG-zichtbaarheid?
Content moet elke 48-72 uur worden bijgewerkt om sterke actualiteitssignalen in RAG-systemen te behouden. Dit vereist geen volledige herschrijving—nieuwe datapunten toevoegen, statistieken updaten of secties uitbreiden met recente ontwikkelingen is voldoende om aanmerking voor verwijzing te behouden.
Welke rol speelt domeinautoriteit bij RAG-verwijzingen?
Domeinautoriteit fungeert als betrouwbaarheidsmaatstaf in RAG-algoritmen en bepaalt ongeveer 5% van de kans op verwijzing. Dit wordt beoordeeld aan de hand van domeinleeftijd, SSL-certificaten, backlinkprofielen, expertvermelding en aanwezigheid in kennisgrafieken, die allemaal samen de bronselectie beïnvloeden.
Hoe helpt AmICited bij het monitoren van RAG-verwijzingen?
AmICited volgt welke van jouw bronnen verschijnen in AI-gegenereerde antwoorden op ChatGPT, Google AI Overviews, Perplexity en andere platforms. Je ziet de frequentie van verwijzingen, context en concurrerende prestaties, zodat je begrijpt wat content verwijzingswaardig maakt in het RAG-tijdperk.
Monitor de AI-verwijzingen naar je merk
Begrijp hoe je merk verschijnt in AI-gegenereerde antwoorden op ChatGPT, Perplexity, Google AI Overviews en meer. Volg verwijzingspatronen, meet zichtbaarheid en optimaliseer je aanwezigheid in het door AI aangedreven zoeklandschap.
Wat is RAG in AI-zoekopdrachten: Complete gids voor Retrieval-Augmented Generation
Leer wat RAG (Retrieval-Augmented Generation) is in AI-zoekopdrachten. Ontdek hoe RAG de nauwkeurigheid verbetert, hallucinaties vermindert en ChatGPT, Perplexi...
Hoe Retrieval-Augmented Generation Werkt: Architectuur en Proces
Ontdek hoe RAG LLM's combineert met externe databronnen om nauwkeurige AI-antwoorden te genereren. Begrijp het proces in vijf fasen, de componenten en waarom he...
Hoe gaan RAG-systemen om met verouderde informatie?
Ontdek hoe Retrieval-Augmented Generation-systemen de actualiteit van kennisbanken beheren, verouderde data voorkomen en actuele informatie behouden via indexer...
10 min lezen
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.