
Publicatiedata en AI-citaties: Maakt recentheid uit?
Ontdek hoe publicatiedata AI-citaties beïnvloeden binnen ChatGPT, Perplexity en Google AI Overviews. Leer branchegerichte strategieën voor actualiteit en voorko...
8 min lezen

Leer hoe het opnieuw publiceren van content voor problemen met dubbele content zorgt, die de AI-zoekzichtbaarheid ernstiger schaden dan bij traditionele zoekopdrachten. Ontdek technische waarborgen en best practices.
Content opnieuw publiceren via meerdere kanalen, platforms en formaten is een legitieme en vaak noodzakelijke strategie om het bereik en de betrokkenheid te maximaliseren. Deze praktijk zorgt echter voor een fundamentele spanning met hoe zoeksystemen—vooral AI-gestuurde systemen—content verwerken en rangschikken. De uitdaging is niet of je kunt herpubliceren, maar of je het zo doet dat je je zichtbaarheid in AI-zoekresultaten niet saboteert. In tegenstelling tot traditionele zoekmachines, die in de loop der decennia verfijnde mechanismen voor het detecteren van dubbele content hebben ontwikkeld, gaan AI-systemen op een andere manier met dubbele content om. Daardoor ontstaan nieuwe risico’s waar veel uitgevers zich nog niet op hebben aangepast.
Volgens de technische documentatie van Microsoft over Copilot en AI-zoekopdrachten “groeperen LLM’s nagenoeg identieke URL’s in één cluster en kiezen vervolgens één pagina om de set te vertegenwoordigen.” Dit clusteringgedrag verschilt fundamenteel van hoe Google’s PageRank-algoritme autoriteit over dubbele pagina’s verdeelt. In plaats van signalen te consolideren, nemen AI-systemen een binaire beslissing: ze selecteren één representatieve pagina uit een cluster van vergelijkbare content en negeren de rest grotendeels. Dit selectieproces is niet altijd voorspelbaar of gebaseerd op de versie die jij het liefst wilt laten ranken. Het algoritme kijkt naar factoren als actualiteit, contentkwaliteit, technische signalen en domeinautoriteit—maar de weging daarvan blijft ondoorzichtig. Wat dit bijzonder problematisch maakt, is dat AI-systemen een verouderde versie kunnen selecteren als de verschillen tussen pagina’s minimaal zijn en het clusteringsalgoritme geen wezenlijke variaties detecteert.
| Aspect | Traditionele zoekopdracht | AI-zoekopdracht |
|---|---|---|
| Omgaan met dubbele content | Consolideert autoriteitssignalen | Clustert en selecteert enkel representatief |
| Strafrisico | Mogelijke handmatige actie | Geen straf, maar verwatering van zichtbaarheid |
| Herkenning van updates | Geleidelijke signaalverspreiding | Kan updates missen als verschillen minimaal zijn |
| Crawlefficiëntie | Verspilt crawlbudget aan duplicaten | Vermindert crawlprioriteit voor duplicaten |
| Respecteren van canonicals | Gewoonlijk gehonoreerd | Cruciaal voor clusterselectie |
Opnieuw publiceren zonder juiste waarborgen introduceert drie onderling verbonden risico’s die direct de AI-zichtbaarheid beïnvloeden:
Verwatering van intentsignalen: Wanneer dezelfde content op meerdere URL’s verschijnt, ontvangt het AI-systeem tegenstrijdige signalen over welke versie het beste antwoord geeft op de vraag van de gebruiker. In plaats van autoriteit op één URL te concentreren, verspreiden je signalen zich over het cluster. Deze verwatering verlaagt de vertrouwensscore die AI-systemen aan je content toekennen bij de keuze om deze in antwoorden op te nemen. Een stuk content dat een primaire bron had kunnen zijn, wordt zo een secundaire optie omdat het systeem niet met zekerheid kan bepalen welke versie gezaghebbend is.
Representatierisico: De keuze van het AI-systeem voor welke pagina je contentcluster vertegenwoordigt, sluit mogelijk niet aan bij je zakelijke doelen. Je publiceert bijvoorbeeld een blogpost naar een syndicatienetwerk met de verwachting dat die versie verkeer genereert, maar het AI-systeem kiest je oorspronkelijke domeinversie—of erger nog, de gesyndiceerde versie die niet naar je site linkt. Deze misafstemming betekent dat je herpublicatiestrategie je zichtbaarheid juist schaadt in plaats van versterkt.
Updatevertraging en veroudering: Wanneer je je originele content bijwerkt, maar de opnieuw gepubliceerde versies onveranderd blijven, kunnen AI-systemen een verouderde versie als representatieve pagina kiezen. Het clusteringsalgoritme herkent niet altijd dat één versie nieuwer of accurater is dan de andere, zeker als de wijzigingen incrementeel en niet structureel zijn. Zo ontstaat de situatie dat je meest actuele, correcte content onzichtbaar wordt, terwijl een oudere versie je expertise voor AI-systemen vertegenwoordigt.
De meest voorkomende fout bij opnieuw publiceren ontstaat wanneer content wordt gesyndiceerd naar externe platforms zonder canonical tags te implementeren. Stel je voor: een B2B-softwarebedrijf publiceert een uitgebreide gids op hun blog en syndiceert deze vervolgens naar vakpublicaties zoals Medium, LinkedIn en gespecialiseerde nieuwsaggregators. Elk platform host identieke content onder verschillende URL’s. Zonder canonical tags die terugverwijzen naar het origineel, beschouwt het clusteringsalgoritme van het AI-systeem alle versies als even gezaghebbend. Het syndicatieplatform kan een hogere domeinautoriteit hebben, waardoor het AI-systeem die versie als representatieve pagina selecteert. Nu wordt je originele content—de versie die je hebt geoptimaliseerd, bijgewerkt en van backlinks hebt voorzien—onzichtbaar in AI-zoekresultaten. Het verkeer en de autoriteit gaan naar het syndicatieplatform in plaats van naar je eigen site. Dit scenario herhaalt zich dagelijks duizenden keren in de uitgeverswereld, waarbij uitgevers onbewust hun eigen zichtbaarheid saboteren door het nalaten van één HTML-tag.
Campagnespecifieke content veroorzaakt een bijzonder verraderlijk probleem met dubbele content als deze over kanalen wordt hergepubliceerd. Een marketingteam lanceert een campaign-landingpage voor een specifieke promotie en publiceert variaties van die content vervolgens opnieuw naar e-mailnieuwsbrieven, sociale media, betaalde advertenties en partnerwebsites. Elke versie bevat licht afwijkende tekst, CTA’s of opmaak—maar de kern en intentie blijven identiek. AI-systemen herkennen deze als near-duplicaten en clusteren ze samen. Het probleem verergert als campagnepagina’s zonder juiste canonical-implementatie worden hergepubliceerd. Het AI-systeem kan de e-mailnieuwsbriefversie (zonder conversietracking) als representatieve pagina kiezen, of de versie op een partnerwebsite die niet bijdraagt aan je eigen metrics. Bovendien, wanneer campagnes eindigen en pagina’s worden gearchiveerd of verwijderd, kan het AI-systeem al een inmiddels niet-bestaande versie als representatieve pagina hebben gekozen, met als gevolg dat je content onzichtbaar wordt of leidt naar kapotte pagina’s.
Regionaal opnieuw publiceren brengt extra complexiteit met zich mee omdat detectie van dubbele content rekening moet houden met legitieme lokalisatiebehoeften. Een bedrijf met activiteiten in meerdere landen kan dezelfde kerncontent publiceren in verschillende talen of met regiogebonden variaties. Zonder correcte implementatie concurreren deze regionale versies met elkaar in AI-clustering. Denk aan een SaaS-bedrijf dat een feature guide in het Engels publiceert op hun Amerikaanse domein en vervolgens herpubliceert op hun Britse domein met Britse spelling en lokale prijzen. Het AI-systeem clustert deze als duplicaten en kan de Amerikaanse versie selecteren, zelfs voor Britse gebruikers. De oplossing is het implementeren van hreflang-tags die regionale relaties aan AI-systemen signaleren, hoewel de effectiviteit van hreflang in AI-zoekopdrachten minder goed is vastgesteld dan bij traditionele zoekopdrachten.
<!-- Op de Amerikaanse versie (example.com/feature-guide) -->
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
<!-- Op de Britse versie (example.co.uk/feature-guide) -->
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
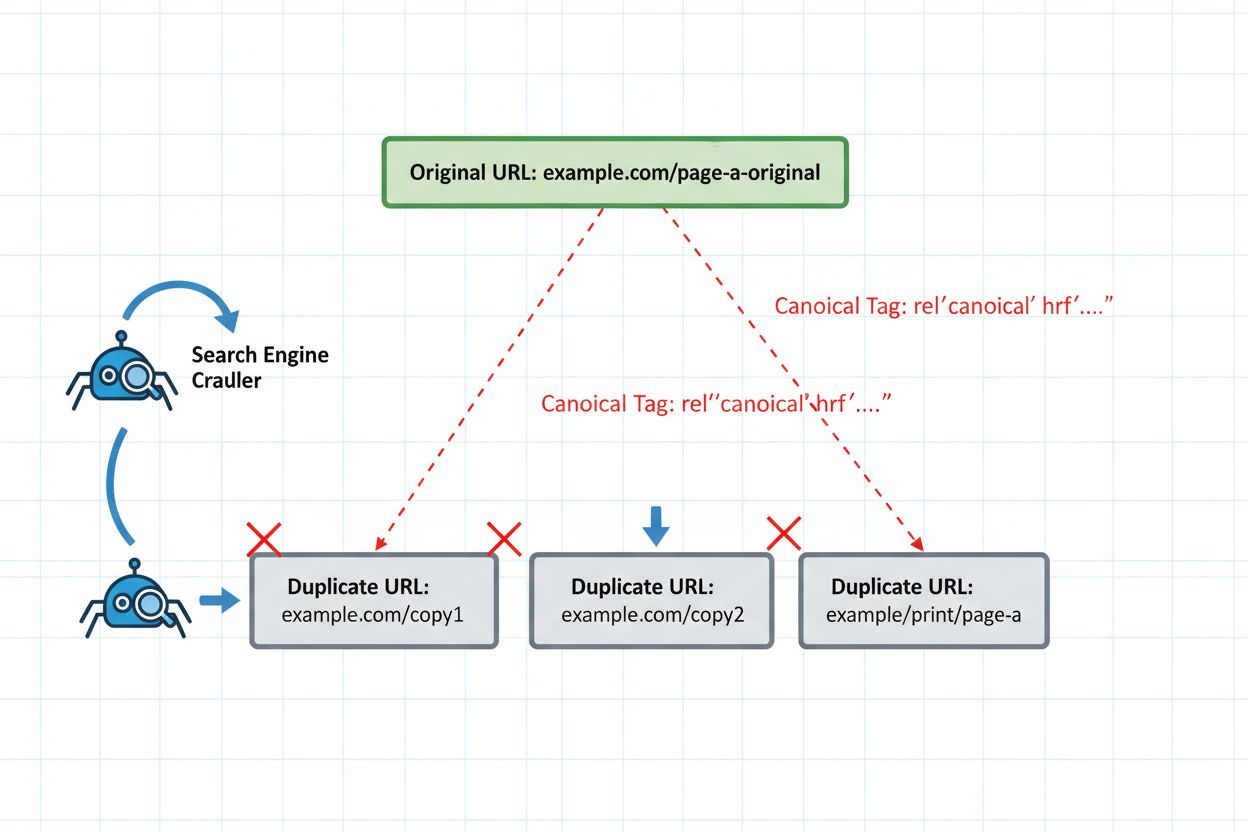
Het implementeren van de juiste technische waarborgen is onmisbaar voor veilig opnieuw publiceren. De canonical tag blijft je belangrijkste verdediging: deze vertelt AI-systemen expliciet welke versie je contentcluster moet vertegenwoordigen. Plaats de canonical tag in de <head> van elke opnieuw gepubliceerde versie, verwijzend naar je voorkeursversie. Voor gesyndiceerde content betekent dit doorgaans dat je terugverwijst naar je originele domein.
<!-- Op gesyndiceerde versie (medium.com/your-publication/article) -->
<link rel="canonical" href="https://yoursite.com/blog/article" />
Voor content die nooit mag concurreren met andere versies, implementeer je noindex op de secundaire versies. Zo worden deze volledig uit de AI-indexering gehaald, zodat ze nooit als representatieve pagina geselecteerd kunnen worden. Gebruik deze aanpak voor interne dubbele pagina’s, testversies of gesyndiceerde content die je geen zichtbaarheid in AI-zoekresultaten wilt geven.
<!-- Op secundaire versie die niet geïndexeerd mag worden -->
<meta name="robots" content="noindex, follow" />
301-redirects geven het sterkste signaal voor het consolideren van autoriteit, maar gebruik ze alleen als de secundaire versie nooit zelfstandig zal worden bijgewerkt. Redirects geven AI-systemen aan dat de oude URL permanent is verhuisd, waardoor alle signalen naar de nieuwe locatie gaan. Maar als beide versies live moeten blijven (zoals bij syndicatie), veroorzaken redirects problemen omdat ze de URL-structuur van het syndicatieplatform breken.
# In .htaccess of serverconfiguratie
Redirect 301 /oude-artikel https://yoursite.com/nieuwe-artikel
Voor contentmanagementsystemen implementeer je rel=“canonical” dynamisch om paginering, parametervariaties en sessiegebaseerde URL’s die onbedoelde duplicaten veroorzaken, te beheren. Veel CMS’en genereren meerdere URL’s voor dezelfde content via verschillende navigatiepaden—canonical tags consolideren deze automatisch.
IndexNow versnelt het ontdekken van canonieke signalen en het consolideren van duplicaten, waardoor processen die traditioneel weken duurden, nu binnen enkele dagen gebeuren. Wanneer je canonical tags op opnieuw gepubliceerde content implementeert, meldt IndexNow direct aan zoeksystemen dat deze URL’s samen moeten worden geclusterd. In plaats van te wachten tot crawlers de canonical-relatie via normale patronen ontdekken, stuurt IndexNow deze informatie direct naar Microsoft’s index en andere deelnemende zoeksystemen. Dit is vooral waardevol als je achteraf fouten bij herpublicatie corrigeert—je kunt canonical tags implementeren en IndexNow gebruiken om de wijziging direct te signaleren, zonder te wachten op een nieuwe crawl. Voor uitgevers die content op meerdere platforms beheren, wordt IndexNow een onmisbare tool om controle te houden over welke versie je contentcluster vertegenwoordigt. De API-integratie maakt het mogelijk om URL’s in bulk te verzenden, waardoor het praktisch wordt om honderden of duizenden opnieuw gepubliceerde pagina’s te beheren.
POST https://api.indexnow.org/indexnow
{
"host": "yoursite.com",
"key": "your-api-key",
"keyLocation": "https://yoursite.com/indexnow-key.txt",
"urlList": [
"https://yoursite.com/blog/article-1",
"https://yoursite.com/blog/article-2"
]
}
Bijhouden welke versie van je opnieuw gepubliceerde content door AI-systemen wordt geselecteerd, vereist monitoring die verder gaat dan traditionele analytics. Stel tracking in om te identificeren wanneer AI-systemen je content citeren of refereren, en noteer welke URL verschijnt in AI-zoekresultaten. Tools als Semrush, Ahrefs en Moz beginnen AI-zoekzichtbaarheidsstatistieken toe te voegen, al zijn deze minder volwassen dan traditionele zoektracking. Implementeer UTM-parameters op gesyndiceerde versies om verkeersattributie te meten, maar besef dat AI-systemen deze parameters mogelijk niet meenemen, waardoor directe attributie lastig is. Monitor je Search Console (of soortgelijke tools voor andere zoeksystemen) op crawlpatronen—als secundaire versies vaker worden gecrawld dan je canonical versie, duidt dit erop dat het AI-systeem de verkeerde representatieve pagina heeft gekozen. Stel meldingen in voor vermeldingen van je content op syndicatieplatforms en vergelijk deze met je AI-zoekzichtbaarheid om te zien of er een mismatch is tussen waar je content verschijnt en waar AI-systemen deze vandaan halen.
Gebruik deze checklist voordat je content opnieuw publiceert om de controle over AI-zichtbaarheid te behouden:
Bepaal vóór het opnieuw publiceren je canonical versie—de URL die je als representatie in AI-zoekresultaten wilt hebben. Dit is meestal je eigen domein, niet het syndicatieplatform. Implementeer canonical tags op elke opnieuw gepubliceerde versie die verwijst naar je canonical URL, zelfs als je publiceert op je eigen eigendommen (andere domeinen, subdomeinen of parametervariaties). Gebruik IndexNow om zoeksystemen direct te informeren over de canonical-relatie, in plaats van te wachten op crawl discovery. Vermijd opnieuw publiceren op platforms met hoge autoriteit zonder canonical-ondersteuning—sommige platforms verwijderen canonical tags of staan ze niet toe, waardoor ze ongeschikt zijn als je geen zichtbaarheid wilt verliezen. Monitor de eerste 48 uur na herpublicatie om te verifiëren dat AI-systemen je beoogde canonical versie selecteren, niet een alternatief. Update alle versies gelijktijdig als je wijzigingen aanbrengt—als je alleen de canonical versie bijwerkt, herkent het clusteringsalgoritme de update mogelijk niet overal, waardoor het AI-systeem een verouderde versie kiest. Stel een republishing-schema op om te voorkomen dat content op secundaire platforms veroudert; achterhaalde gesyndiceerde content verhoogt het risico dat AI-systemen deze als representatieve versie kiezen als je canonical versie recent niet is bijgewerkt.
Canonical tags voorkomen geen straffen omdat dubbele content in de eerste plaats geen straffen oplevert. Canonical tags zijn echter cruciaal voor AI-zoekopdrachten omdat ze AI-systemen vertellen welke versie jouw contentcluster moet vertegenwoordigen. Zonder canonical tags kan het gebeuren dat AI-systemen een onbedoelde versie als gezaghebbende bron kiezen, waardoor je zichtbaarheid afneemt.
Monitor welke URL's verschijnen in AI-zoekresultaten en citaties voor je content. Tools als Semrush en Ahrefs voegen AI-zoekzichtbaarheidsstatistieken toe. Controleer je Search Console op crawlpatronen—als secundaire versies vaker gecrawld worden dan je canonical versie, kan het AI-systeem de verkeerde pagina hebben geselecteerd.
Technisch gezien wel, maar het is niet aan te raden. Zonder canonical tags zullen AI-systemen je content clusteren en één versie als representatief kiezen—maar je hebt geen controle over welke. Het syndicatieplatform kan meer autoriteit hebben, waardoor AI die versie selecteert in plaats van je originele domein.
Opnieuw publiceren verwijst meestal naar het verspreiden van je content over meerdere kanalen die je beheert of waar je mee samenwerkt. Content-syndicatie is een specifieke vorm van opnieuw publiceren waarbij externe platforms jouw content met toestemming opnieuw publiceren. Beide zorgen voor problemen met dubbele content als ze niet goed worden beheerd met canonical tags.
Canonical tags worden doorgaans binnen 24-48 uur herkend als je IndexNow gebruikt om zoeksystemen direct te informeren. Zonder IndexNow kan het weken duren voordat crawlers de canonical-relatie ontdekken. Daarom is IndexNow cruciaal voor het beheren van opnieuw gepubliceerde content—het versnelt het proces aanzienlijk.
Gebruik 301-redirects alleen als je URL's permanent wilt consolideren en de secundaire versie nooit zelfstandig wordt bijgewerkt. Gebruik canonical tags als beide versies live moeten blijven (zoals bij syndicatie). Redirects zijn sterkere signalen, maar breken de functionaliteit van de secundaire URL.
Ja, als het niet goed wordt beheerd. Opnieuw publiceren zonder canonical tags verwatert je autoriteitssignalen over meerdere URL's. AI-systemen kunnen de gesyndiceerde versie selecteren in plaats van je originele, waardoor zichtbaarheid op je eigen domein afneemt. Een juiste canonical-implementatie voorkomt dit.
Implementeer canonical tags op elke opnieuw gepubliceerde versie die verwijst naar je originele domein. Gebruik IndexNow om zoeksystemen direct te informeren over de canonical-relatie. Vermijd opnieuw publiceren op platforms die geen canonical tags ondersteunen. Monitor welke versie AI-systemen binnen de eerste 48 uur selecteren en pas indien nodig aan.
Volg hoe AI-systemen je opnieuw gepubliceerde content citeren en refereren op alle platforms. Krijg realtime-inzichten in welke versie AI selecteert als jouw gezaghebbende bron.
Ontdek hoe publicatiedata AI-citaties beïnvloeden binnen ChatGPT, Perplexity en Google AI Overviews. Leer branchegerichte strategieën voor actualiteit en voorko...

Leer hoe je dubbele content beheert en voorkomt bij het gebruik van AI-tools. Ontdek canonical tags, redirects, detectietools en best practices voor het behoude...

Leer hoe canonieke URL's problemen met dubbele content in AI-zoeksystemen voorkomen. Ontdek best practices voor het implementeren van canonicals om AI-zichtbaar...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.