
AI-crawlerbeheer
Leer hoe je AI-crawlertoegang tot de content van je website kunt beheren. Begrijp het verschil tussen trainings- en zoekcrawlers, implementeer robots.txt-contro...
7 min lezen
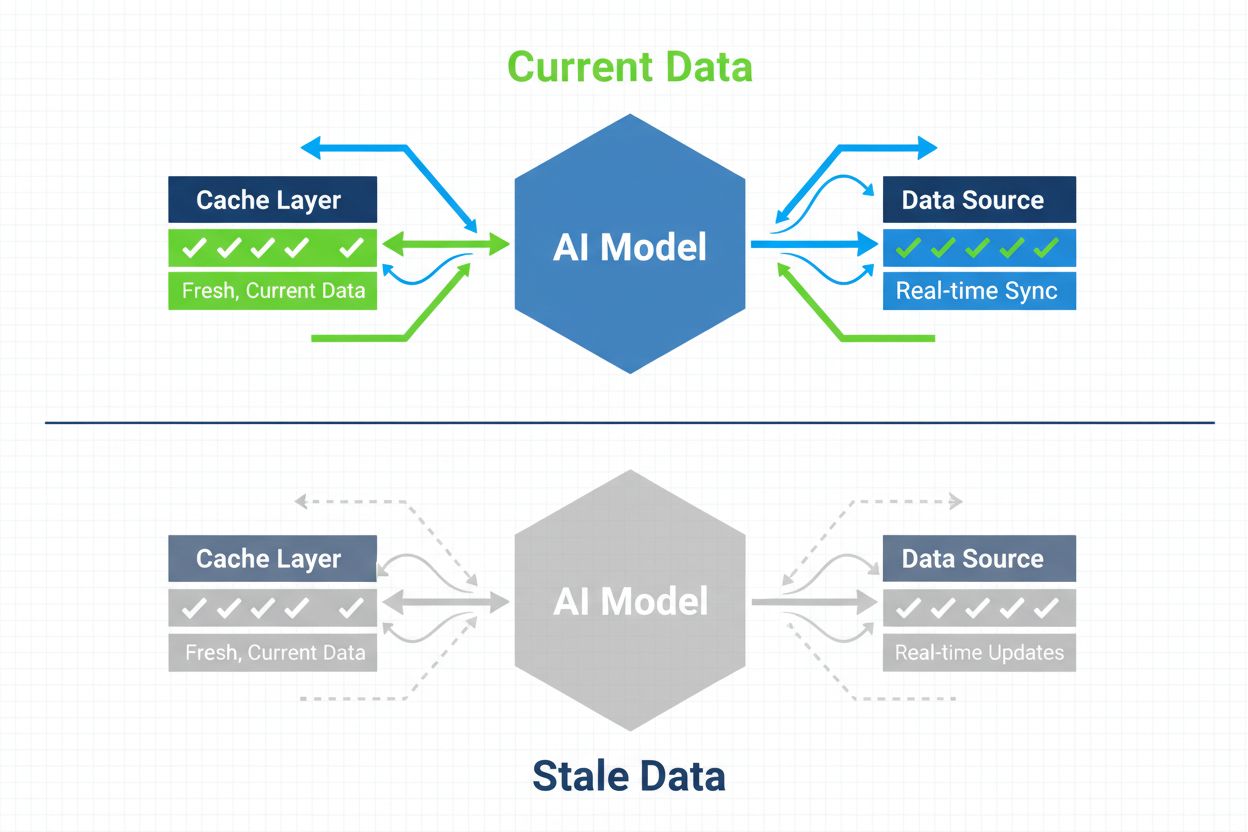
Strategieën om ervoor te zorgen dat AI-systemen toegang hebben tot actuele content in plaats van verouderde gecachte versies. Cachebeheer balanceert de prestatievoordelen van caching tegen het risico van het serveren van achterhaalde informatie, door gebruik te maken van invalidatiestrategieën en monitoring om datafrisheid te behouden terwijl latentie en kosten worden verminderd.
Strategieën om ervoor te zorgen dat AI-systemen toegang hebben tot actuele content in plaats van verouderde gecachte versies. Cachebeheer balanceert de prestatievoordelen van caching tegen het risico van het serveren van achterhaalde informatie, door gebruik te maken van invalidatiestrategieën en monitoring om datafrisheid te behouden terwijl latentie en kosten worden verminderd.
AI cachebeheer verwijst naar de systematische aanpak voor het opslaan en ophalen van eerder berekende resultaten, modeluitvoer of API-responses om dubbele verwerking te voorkomen en de latentie in artificiële intelligentiesystemen te verminderen. De kernuitdaging ligt in het balanceren van de prestatievoordelen van gecachte data tegen het risico dat verouderde of niet-actuele informatie wordt geleverd die niet langer de huidige systeemstatus of gebruikersbehoeften weerspiegelt. Dit wordt vooral cruciaal in grote taalmodellen (LLM’s) en AI-toepassingen waar de inferentiekosten aanzienlijk zijn en de responstijd direct de gebruikerservaring beïnvloedt. Cachebeheersystemen moeten intelligent bepalen wanneer gecachte resultaten nog geldig zijn en wanneer een nieuwe berekening nodig is, waardoor het een fundamentele architecturale overweging is voor AI-implementaties in productie.
De impact van effectief cachebeheer op de prestaties van AI-systemen is aanzienlijk en meetbaar op meerdere dimensies. Het implementeren van cachingstrategieën kan de responstijd voor herhaalde queries met 80-90% verlagen en tegelijkertijd de API-kosten met 50-90% verminderen, afhankelijk van cache hit rates en systeemarchitectuur. Naast prestatie-indicatoren beïnvloedt cachebeheer direct de consistentie van nauwkeurigheid en systeem betrouwbaarheid, want goed geïnvalideerde caches zorgen ervoor dat gebruikers actuele informatie ontvangen terwijl slecht beheerde caches problemen met verouderde data introduceren. Deze verbeteringen worden steeds belangrijker naarmate AI-systemen opschalen naar miljoenen verzoeken, waarbij het cumulatieve effect van cache-efficiëntie direct de infrastructuurkosten en de gebruikerservaring bepaalt.
| Aspect | Gecachte Systemen | Niet-Gecachte Systemen |
|---|---|---|
| Responstijd | 80-90% sneller | Basislijn |
| API-kosten | 50-90% reductie | Volledige kosten |
| Nauwkeurigheid | Consistent | Variabel |
| Schaalbaarheid | Hoog | Beperkt |
Cache-invalidatiestrategieën bepalen hoe en wanneer gecachte data wordt vernieuwd of verwijderd uit opslag, en vormen een van de meest kritische beslissingen in cache-architectuurontwerp. Verschillende invalidatiebenaderingen bieden unieke afwegingen tussen datafrisheid en systeemprestaties:
De keuze van invalidatiestrategie is fundamenteel afhankelijk van applicatievereisten: systemen die datanauwkeurigheid prioriteren kunnen hogere latentie accepteren via agressieve invalidatie, terwijl prestatiekritische toepassingen iets verouderde data tolereren om onder de milliseconde responstijden te behouden.
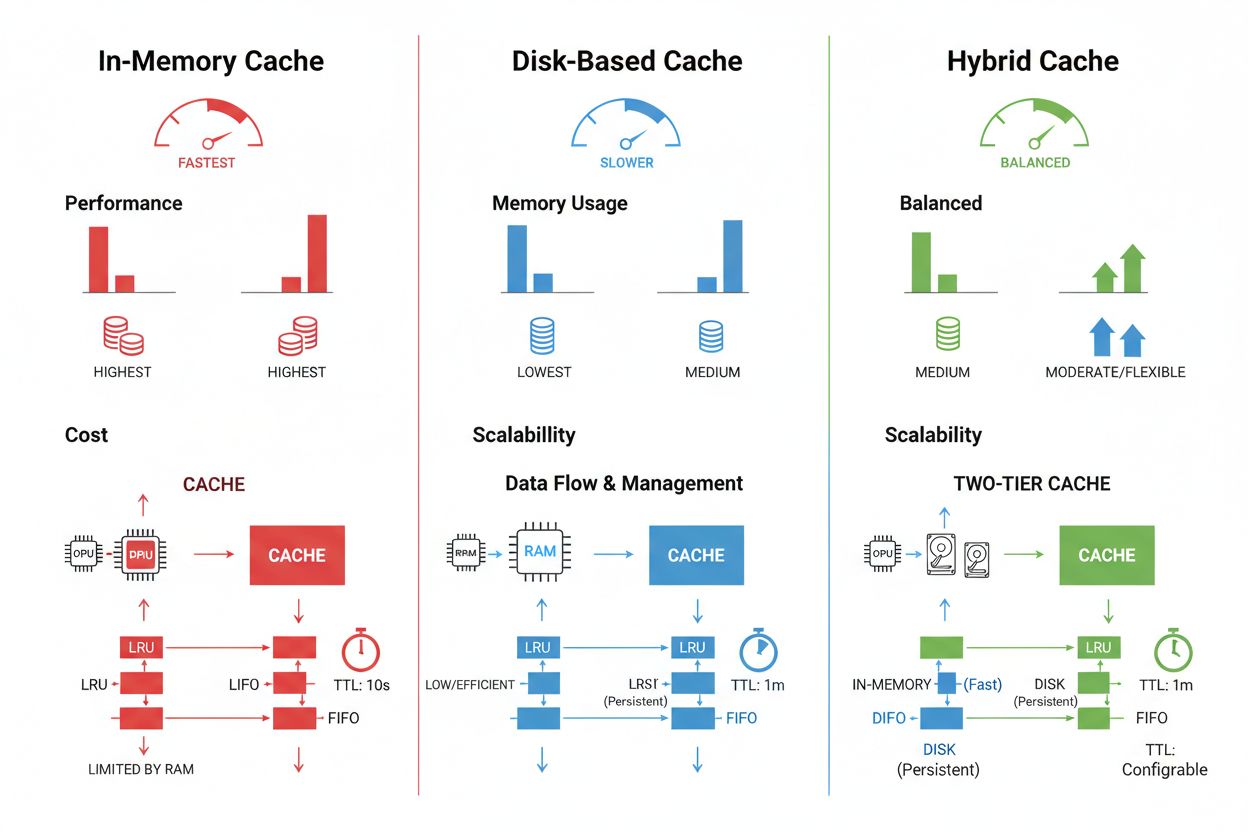
Prompt caching in grote taalmodellen is een gespecialiseerde toepassing van cachebeheer waarbij tussentijdse modelstatussen en tokensequenties worden opgeslagen om het opnieuw verwerken van identieke of vergelijkbare input te voorkomen. LLM’s ondersteunen twee primaire cachingbenaderingen: exacte caching matcht identieke prompts karakter-voor-karakter, terwijl semantische caching functioneel equivalente prompts met verschillende bewoordingen herkent. OpenAI implementeert automatische prompt caching met een kostenreductie van 50% op gecachte tokens, waarbij minimaal 1024 tokens per prompt vereist zijn om cachingvoordelen te activeren. Anthropic biedt handmatige prompt caching met een agressievere kostenreductie tot 90%, maar vereist dat ontwikkelaars expliciet cache keys en -duur beheren, met minimale cachevereisten van 1024-2048 tokens afhankelijk van de modelconfiguratie. De cacheduur in LLM-systemen varieert doorgaans van enkele minuten tot uren, waarbij de rekensbesparing van het hergebruiken van gecachte status wordt gebalanceerd tegen het risico van het leveren van verouderde modeloutput voor tijdgevoelige toepassingen.
Cache opslag- en beheerstechnieken verschillen sterk op basis van prestatie-eisen, datavolume en infrastructuurbeperkingen, waarbij elke aanpak unieke voordelen en beperkingen biedt. In-memory caching-oplossingen zoals Redis bieden toegangssnelheden op microsecondeniveau, ideaal voor veelvoorkomende queries maar vergen veel RAM en zorgvuldige geheugenbeheer. Schijfgebaseerde caching is geschikt voor grotere datasets en blijft behouden bij systeemherstart maar introduceert latentie in milliseconden vergeleken met in-memory alternatieven. Hybride benaderingen combineren beide opslagtypes, waarbij vaak geraadpleegde data naar het geheugen wordt gestuurd en grotere datasets op schijf worden bewaard:
| Opslagtype | Beste Voor | Prestaties | Geheugengebruik |
|---|---|---|---|
| In-Memory (Redis) | Frequente queries | Snelst | Hoger |
| Schijfgebaseerd | Grote datasets | Gemiddeld | Lager |
| Hybride | Gemengde workloads | Gebalanceerd | Gebalanceerd |
Effectief cachebeheer vereist het configureren van geschikte TTL-instellingen die datavolatiliteit weerspiegelen—korte TTL’s (minuten) voor snel veranderende data versus langere TTL’s (uren/dagen) voor stabiele content—gecombineerd met continue monitoring van cache hit rates, eviction-patronen en geheugengebruik om optimalisatiemogelijkheden te identificeren.
Praktische AI-toepassingen tonen zowel het transformerende potentieel als de operationele complexiteit van cachebeheer in uiteenlopende usecases. Klantenservice-chatbots gebruiken caching om consistente antwoorden te leveren op veelgestelde vragen en verlagen de inferentiekosten met 60-70%, waardoor kostenefficiënte schaalbaarheid naar duizenden gelijktijdige gebruikers mogelijk wordt. Code-assistenten cachen veelvoorkomende codepatronen en documentatiefragmenten, zodat ontwikkelaars autosuggesties ontvangen met minder dan 100 ms latentie, zelfs tijdens piekperiodes. Documentverwerkende systemen cachen embeddings en semantische representaties van vaak geanalyseerde documenten, wat zoekopdrachten naar gelijkenis en classificatietaken aanzienlijk versnelt. Productiecachebeheer brengt echter aanzienlijke uitdagingen met zich mee: de complexiteit van invalidatie neemt exponentieel toe in gedistribueerde systemen waarin cacheconsistentie op meerdere servers moet worden behouden, resourcebeperkingen dwingen tot lastige afwegingen tussen cachegrootte en dekking, beveiligingsrisico’s ontstaan wanneer gecachte data gevoelige informatie bevat die versleuteling en toegangscontrole vereist, en het coördineren van cache-updates tussen microservices introduceert mogelijke racecondities en datainconsistenties. Uitgebreide monitoringsoplossingen die cachefrisheid, hit rates en invalidatiegebeurtenissen volgen, worden essentieel om systeembetrouwbaarheid te behouden en te bepalen wanneer cache-strategieën moeten worden aangepast op basis van veranderende datapatronen en gebruikersgedrag.
Cache-invalidatie verwijdert of werkt verouderde data bij wanneer wijzigingen optreden, wat directe frisheid biedt maar gebeurtenisgestuurde triggers vereist. Cache-expiratie stelt een tijdslimiet (TTL) in voor hoe lang data in de cache blijft, wat eenvoudiger te implementeren is maar mogelijk verouderde data serveert als de TTL te lang is. Veel systemen combineren beide benaderingen voor optimale prestaties.
Effectief cachebeheer kan API-kosten met 50-90% verlagen, afhankelijk van cache hit rates en systeemarchitectuur. OpenAI's prompt caching biedt 50% kostenreductie op gecachte tokens, terwijl Anthropic tot 90% reductie biedt. De daadwerkelijke besparing hangt af van querypatronen en hoeveel data effectief gecachet kan worden.
Prompt caching slaat tussentijdse modelstatussen en tokensequenties op om het opnieuw verwerken van identieke of soortgelijke input in grote taalmodellen te vermijden. Het ondersteunt exacte caching (karakter-voor-karakter overeenkomsten) en semantische caching (functioneel equivalente prompts met andere bewoording). Dit vermindert de latentie met 80% en de kosten met 50-90% bij herhaalde vragen.
De belangrijkste strategieën zijn: Tijdgebaseerde Expiratie (TTL) voor automatische verwijdering na een ingestelde periode, Gebeurtenis-gebaseerde Invalidatie voor directe updates bij dataveranderingen, Semantische Invalidatie voor soortgelijke queries op basis van betekenis, en Hybride Benaderingen die meerdere strategieën combineren. De keuze hangt af van datavolatiliteit en frisheidseisen.
Geheugencaching (zoals Redis) biedt toegangssnelheden op microsecondeniveau, ideaal voor frequente queries maar verbruikt veel RAM. Schijfgebaseerde caching biedt plaats aan grotere datasets en blijft behouden bij herstarten, maar heeft een latentie van milliseconden. Hybride benaderingen combineren beide, waarbij vaak geraadpleegde data naar het geheugen gaat en grotere datasets op schijf blijven.
TTL is een afteltimer die bepaalt hoe lang gecachte data geldig blijft voor expiratie. Korte TTL's (minuten) zijn geschikt voor snel veranderende data, terwijl langere TTL's (uren/dagen) werken voor stabiele content. Juiste TTL-configuratie balanceert datafrisheid met onnodige cacheverversingen en serverbelasting.
Effectief cachebeheer stelt AI-systemen in staat veel meer verzoeken te verwerken zonder evenredige uitbreiding van de infrastructuur. Door de rekenlast per verzoek te verminderen via caching kunnen systemen miljoenen gebruikers kostenefficiënter bedienen. Cache hit rates bepalen direct de infrastructuurkosten en gebruikerservaring in productieomgevingen.
Het cachen van gevoelige data brengt beveiligingsrisico's met zich mee als deze niet goed wordt versleuteld en gecontroleerd op toegang. Risico's zijn onder andere ongeoorloofde toegang tot gecachte informatie, datalekken tijdens cache-invalidatie en het per ongeluk cachen van vertrouwelijke inhoud. Grondige versleuteling, toegangscontrole en monitoring zijn essentieel om gevoelige gecachte data te beschermen.
AmICited volgt hoe AI-systemen naar jouw merk verwijzen en zorgt ervoor dat je content actueel blijft in AI-caches. Krijg inzicht in AI cachebeheer en contentfrisheid binnen GPT's, Perplexity en Google AI Overviews.
Leer hoe je AI-crawlertoegang tot de content van je website kunt beheren. Begrijp het verschil tussen trainings- en zoekcrawlers, implementeer robots.txt-contro...
Ontdek wat AI-inhoudsconsolidatie is en hoe het samenvoegen van vergelijkbare content zichtbaarheidssignalen voor ChatGPT, Perplexity en Google AI Overviews ver...

Leer hoe je het monitoren van je merkvermeldingen en websitecitaties automatiseert over ChatGPT, Perplexity, Google AI Overviews en andere AI-zoekmachines met c...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.