
PerplexityBot: Wat Elke Website-Eigenaar Moet Weten
Complete gids voor de PerplexityBot-crawler - begrijp hoe het werkt, beheer toegang, monitor citaties en optimaliseer voor zichtbaarheid in Perplexity AI. Leer ...
8 min lezen

Amazon’s webcrawler die wordt gebruikt om producten en diensten te verbeteren, waaronder Alexa, de Rufus shopping assistant en Amazon’s AI-zoekfuncties. De crawler respecteert het Robots Exclusion Protocol en kan worden aangestuurd via robots.txt-directieven. Kan worden ingezet voor AI-modeltraining.
Amazon's webcrawler die wordt gebruikt om producten en diensten te verbeteren, waaronder Alexa, de Rufus shopping assistant en Amazon's AI-zoekfuncties. De crawler respecteert het Robots Exclusion Protocol en kan worden aangestuurd via robots.txt-directieven. Kan worden ingezet voor AI-modeltraining.
Amazonbot is de officiële webcrawler van Amazon, ontworpen om de producten en diensten van het bedrijf te verbeteren door webinhoud te verzamelen en te analyseren. Deze geavanceerde crawler drijft kritieke Amazon-functies aan, waaronder de Alexa spraakassistent, de Rufus AI shopping assistant en Amazon’s AI-gestuurde zoekervaringen. Amazonbot werkt met de user agent-string Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36, waarmee hij zich identificeert bij webservers. De gegevens die door Amazonbot worden verzameld, kunnen worden gebruikt om Amazon’s kunstmatige intelligentiemodellen te trainen, waardoor het een cruciaal onderdeel is van Amazon’s bredere AI-infrastructuur en productontwikkelingsstrategie.
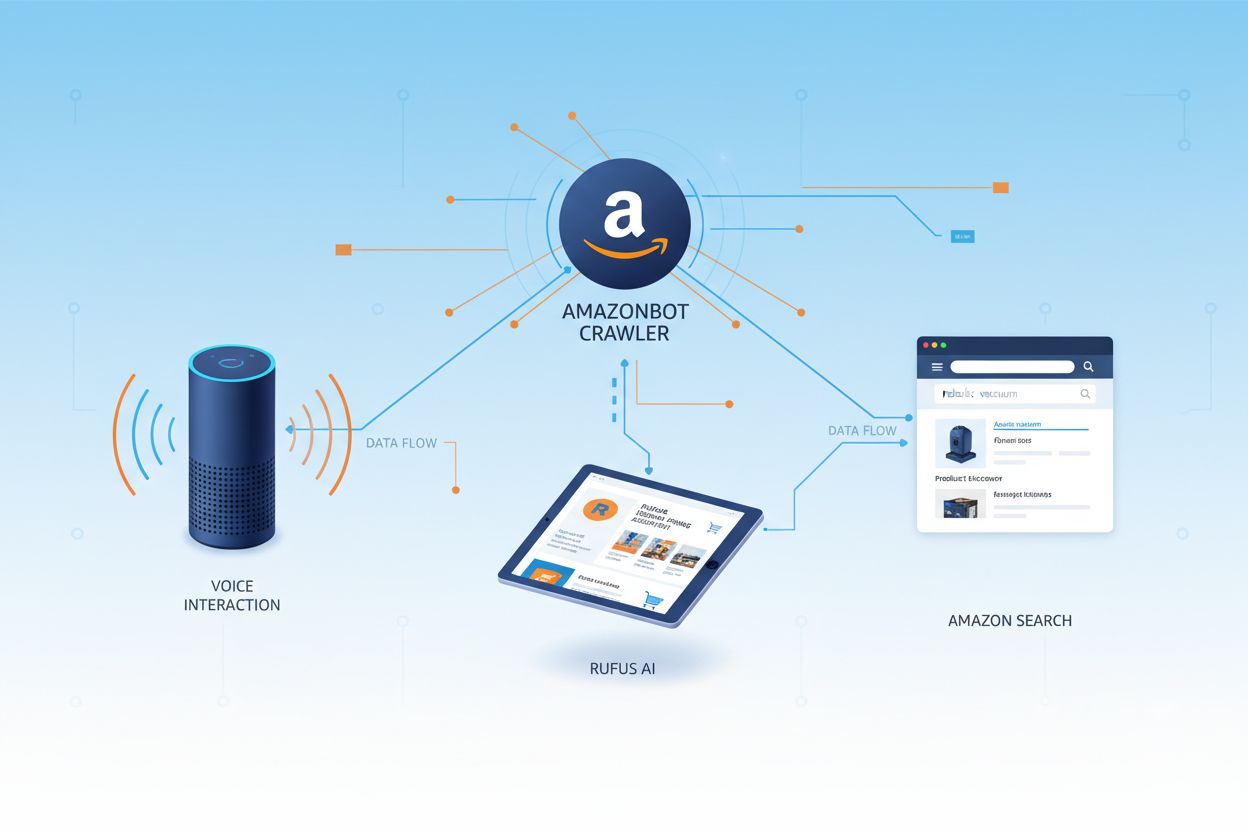
Amazon beheert drie verschillende webcrawlers, elk met een specifieke rol binnen het ecosysteem. Amazonbot is de primaire crawler voor algemene verbetering van producten en diensten, en kan gebruikt worden voor AI-modeltraining. Amzn-SearchBot is specifiek bedoeld om zoekervaringen in Amazon-producten als Alexa en Rufus te verbeteren, maar crawlt nadrukkelijk GEEN content voor generatieve AI-modeltraining. Amzn-User ondersteunt door gebruikers geïnitieerde acties, zoals het ophalen van live informatie wanneer klanten Alexa vragen stellen waarvoor actuele webgegevens nodig zijn, en crawlt ook niet voor AI-training. Alle drie de crawlers respecteren het Robots Exclusion Protocol en volgen robots.txt-regels, zodat website-eigenaren hun toegang kunnen beheren. Amazon publiceert de IP-adressen van elke crawler op het ontwikkelaarsportaal, waardoor site-eigenaren legitiem verkeer kunnen verifiëren. Daarnaast respecteren alle Amazon-crawlers linkniveau rel=nofollow-directieven en paginaniveau robots meta-tags zoals noarchive (blokkeert gebruik voor modeltraining), noindex (voorkomt indexatie) en none (voorkomt beide).
| Crawlernaam | Primair doel | AI-modeltraining | User Agent | Belangrijkste toepassingen |
|---|---|---|---|---|
| Amazonbot | Algemene verbetering producten/diensten | Ja | Amazonbot/0.1 | Algehele Amazon-dienstverbetering, AI-training |
| Amzn-SearchBot | Verbetering zoekervaring | Nee | Amzn-SearchBot/0.1 | Alexa-zoekopdrachten, Rufus shopping indexing |
| Amzn-User | Live data ophalen op verzoek gebruiker | Nee | Amzn-User/0.1 | Real-time Alexa-vragen, actuele informatie |
Amazon respecteert het industriestandaard Robots Exclusion Protocol (RFC 9309), wat betekent dat website-eigenaren toegang van Amazonbot kunnen regelen via hun robots.txt-bestand. Amazon haalt host-niveau robots.txt-bestanden op vanaf de root van je domein (bijv. example.com/robots.txt) en gebruikt een gecachte versie van maximaal 30 dagen als het bestand niet kan worden opgehaald. Wijzigingen in je robots.txt-bestand worden doorgaans binnen ongeveer 24 uur doorgevoerd in de systemen van Amazon. Het protocol ondersteunt standaard user-agent en allow/disallow-regels, waarmee je fijnmazige controle hebt over welke crawlers toegang krijgen tot specifieke mappen of bestanden. Het is echter belangrijk te weten dat Amazon-crawlers GEEN ondersteuning bieden voor de crawl-delay-directive; deze parameter wordt genegeerd als hij in je robots.txt staat.
Hier een voorbeeld van hoe je Amazonbot-toegang regelt:
# Blokkeer Amazonbot voor je hele site
User-agent: Amazonbot
Disallow: /
# Sta Amzn-SearchBot toe voor zichtbaarheid in zoekresultaten
User-agent: Amzn-SearchBot
Allow: /
# Blokkeer een specifieke map voor Amazonbot
User-agent: Amazonbot
Disallow: /private/
# Sta alle andere crawlers toe
User-agent: *
Disallow: /admin/
Website-eigenaren die zich zorgen maken over botverkeer, moeten verifiëren of crawlers die zich voordoen als Amazonbot daadwerkelijk legitieme Amazon-crawlers zijn. Amazon biedt hiervoor een verificatieproces via DNS-lookups om echt Amazonbot-verkeer te bevestigen. Zoek eerst het IP-adres dat toegang heeft gezocht in je serverlogs en voer een reverse DNS lookup uit met het host-commando. De opgehaalde domeinnaam moet een subdomein zijn van crawl.amazonbot.amazon. Doe vervolgens een forward DNS lookup op deze domeinnaam om te controleren of deze weer naar het originele IP-adres verwijst. Deze tweezijdige verificatie helpt spoofing tegen te gaan, omdat kwaadwillenden anders via reverse DNS Amazonbot zouden kunnen nabootsen. Amazon publiceert de geverifieerde IP-adressen van alle crawlers op het ontwikkelaarsportaal op developer.amazon.com/amazonbot/ip-addresses/, wat een extra referentiepunt biedt.
Voorbeeld verificatieproces:
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
Heb je vragen over Amazonbot of wil je verdachte activiteit melden, neem dan rechtstreeks contact op met Amazon via amazonbot@amazon.com en vermeld de relevante domeinnamen in je bericht.
Er is een belangrijk verschil tussen de Amazon-crawlers als het gaat om AI-modeltraining. Amazonbot kan worden gebruikt voor het trainen van Amazon’s kunstmatige intelligentiemodellen, wat relevant is voor contentmakers die zich zorgen maken over het gebruik van hun werk voor AI-training. Amzn-SearchBot en Amzn-User crawlen daarentegen expliciet GEEN content voor generatieve AI-modeltraining; ze richten zich alleen op het verbeteren van zoekervaringen en het ondersteunen van gebruikersvragen. Wil je voorkomen dat jouw content wordt gebruikt voor AI-training, gebruik dan de robots meta tag noarchive in de HTML-header van je pagina, waarmee je Amazonbot instrueert deze niet te gebruiken voor modeltraining. Dit onderscheid is belangrijk voor uitgevers, makers en website-eigenaren die controle willen houden over het gebruik van hun content in de AI-trainingspipeline, terwijl ze hun content toch zichtbaar willen houden in Amazon-zoekresultaten en Rufus-aanbevelingen.
Rufus is Amazon’s geavanceerde AI-shopping assistant die gebruik maakt van webcrawling en AI-technologie om gepersonaliseerde winkeladviezen en -hulp te bieden. Terwijl Amazonbot bijdraagt aan de algemene AI-infrastructuur van Amazon, gebruikt Rufus specifiek Amzn-SearchBot voor het indexeren van productinformatie en webinhoud die relevant is voor winkelvragen. Rufus is gebouwd op Amazon Bedrock en maakt gebruik van geavanceerde large language models, waaronder Claude Sonnet van Anthropic en Amazon Nova, gecombineerd met een eigen model dat is getraind op Amazon’s uitgebreide productcatalogus, klantbeoordelingen, community Q&A’s en webinformatie. De shopping assistant helpt klanten bij het onderzoeken van producten, vergelijken van opties, prijzen volgen, deals vinden en zelfs automatisch aankopen doen wanneer doelprijzen zijn bereikt. Sinds de lancering is Rufus enorm populair geworden, met meer dan 250 miljoen klanten, een toename van het aantal maandelijks actieve gebruikers van 149% en een stijging van 210% in interacties op jaarbasis. Klanten die Rufus gebruiken tijdens het winkelen zijn ruim 60% meer geneigd een aankoop te doen tijdens die sessie, wat het grote effect van AI-ondersteunde shopping laat zien.
Website-eigenaren doen er goed aan een strategische aanpak te kiezen voor het beheer van Amazon’s crawlers, passend bij hun eigen zakelijke doelen en contentbeleid:
noarchive robots meta tag of blokkeer volledig via robots.txtamazonbot@amazon.com met je domeingegevens voor persoonlijk advies als je specifieke vragen hebt over het gedrag van Amazon-crawlers op jouw siteAmazonbot is de algemene crawler van Amazon die wordt gebruikt om producten en diensten te verbeteren, en kan ook worden ingezet voor AI-modeltraining. Amzn-SearchBot is specifiek ontworpen voor zoekervaringen in Alexa en Rufus en crawlt nadrukkelijk NIET voor AI-modeltraining. Wil je AI-training voorkomen, blokkeer dan Amazonbot maar sta Amzn-SearchBot toe voor zichtbaarheid in zoekresultaten.
Voeg de volgende regels toe aan je robots.txt-bestand op de root van je domein: User-agent: Amazonbot gevolgd door Disallow: /. Dit voorkomt dat Amazonbot je gehele site crawlt. Je kunt ook Disallow: /specifiek-pad/ gebruiken om alleen bepaalde mappen te blokkeren.
Ja, Amazonbot kan worden gebruikt voor de training van Amazon's kunstmatige intelligentiemodellen. Als je dit wilt voorkomen, gebruik dan de robots meta tag in de HTML-header van je pagina. Dit instrueert Amazonbot om de pagina niet te gebruiken voor modeltraining.
Voer een reverse DNS lookup uit op het IP-adres van de crawler en controleer of het domein een subdomein is van crawl.amazonbot.amazon. Voer vervolgens een forward DNS lookup uit om te bevestigen dat het domein weer naar het originele IP verwijst. Je kunt ook de door Amazon gepubliceerde IP-adressen controleren op developer.amazon.com/amazonbot/ip-addresses/.
Gebruik de standaard robots.txt-syntax: User-agent: Amazonbot om de crawler te targeten, gevolgd door Disallow: / om alle toegang te blokkeren of Disallow: /pad/ om specifieke mappen te blokkeren. Je kunt ook Allow: / gebruiken om toegang expliciet toe te staan.
Amazon verwerkt wijzigingen in robots.txt doorgaans binnen ongeveer 24 uur. Amazon haalt regelmatig je robots.txt-bestand op en bewaart een gecachte versie tot maximaal 30 dagen, waardoor het een dag kan duren voordat wijzigingen overal zijn doorgevoerd.
Ja, absoluut. Je kunt afzonderlijke regels maken voor elke crawler in je robots.txt-bestand. Sta bijvoorbeeld Amzn-SearchBot toe met User-agent: Amzn-SearchBot en Allow: /, terwijl je Amazonbot blokkeert met User-agent: Amazonbot en Disallow: /.
Neem direct contact op met Amazon via amazonbot@amazon.com. Vermeld altijd je domeinnaam en relevante details over je vraag in je bericht. Het supportteam van Amazon kan je persoonlijk adviseren in jouw situatie.
Volg vermeldingen van jouw merk in AI-systemen zoals Alexa, Rufus en Google AI Overviews met AmICited - hét toonaangevende platform voor AI-antwoorden monitoring.
Complete gids voor de PerplexityBot-crawler - begrijp hoe het werkt, beheer toegang, monitor citaties en optimaliseer voor zichtbaarheid in Perplexity AI. Leer ...

Lees meer over PerplexityBot, de webcrawler van Perplexity die inhoud indexeert voor zijn AI-antwoordmachine. Begrijp hoe het werkt, robots.txt-naleving en hoe ...

Ontdek wat GPTBot is, hoe het werkt en of je OpenAI's webcrawler moet toestaan of blokkeren. Begrijp de impact op je merkzichtbaarheid in AI-zoekmachines en Cha...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.