
Informatiedichtheid: Waardevolle Content Creëren voor AI
Leer hoe je informatiedichte content maakt waar AI-systemen de voorkeur aan geven. Beheers de Uniform Information Density-hypothese en optimaliseer je content v...
9 min lezen
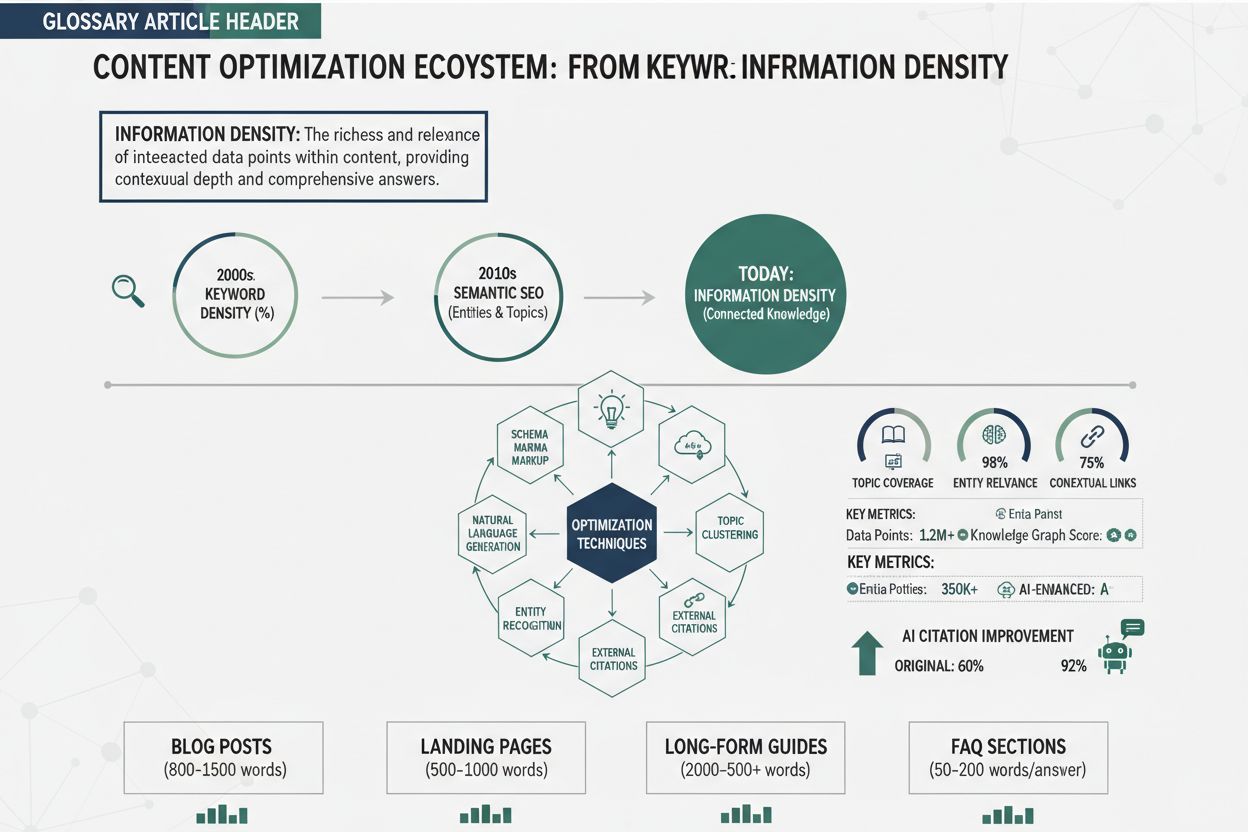
Informatiedichtheid is de verhouding tussen bruikbare, unieke informatie en de totale inhoudslengte. Een hogere dichtheid vergroot de kans op AI-citaties omdat AI-systemen prioriteit geven aan inhoud die maximale inzichten biedt met een minimaal aantal woorden. Het vertegenwoordigt een verschuiving van optimalisatie op trefwoorden naar optimalisatie op informatie, waarbij elke zin een unieke waarde moet toevoegen. Deze maatstaf beïnvloedt direct of AI-systemen je inhoud ophalen, evalueren en citeren als gezaghebbende bron.
Informatiedichtheid is de verhouding tussen bruikbare, unieke informatie en de totale inhoudslengte. Een hogere dichtheid vergroot de kans op AI-citaties omdat AI-systemen prioriteit geven aan inhoud die maximale inzichten biedt met een minimaal aantal woorden. Het vertegenwoordigt een verschuiving van optimalisatie op trefwoorden naar optimalisatie op informatie, waarbij elke zin een unieke waarde moet toevoegen. Deze maatstaf beïnvloedt direct of AI-systemen je inhoud ophalen, evalueren en citeren als gezaghebbende bron.
Informatiedichtheid vertegenwoordigt de verhouding tussen bruikbare, unieke en toepasbare informatie en de totale inhoudslengte—een cruciale maatstaf die bepaalt hoe effectief AI-systemen je inhoud kunnen extraheren, evalueren en citeren. In tegenstelling tot de voorganger trefwoorddichtheid, die het percentage doelzoekwoorden in een stuk inhoud mat, richt informatiedichtheid zich op de werkelijke waarde en specificiteit van elke zin. AI-systemen, met name grote taalmodellen achter GPT’s, Perplexity en Google AI Overviews, geven prioriteit aan inhoud die maximale inzichten biedt in een minimaal aantal woorden. Deze voorkeur komt voort uit de manier waarop deze systemen informatie verwerken: ze belonen semantische rijkdom—de diepte van betekenis per tekstdeel—boven louter herhaling van trefwoorden. Wanneer een AI-systeem inhoud met een hoge dichtheid tegenkomt, herkent het het materiaal als gezaghebbend, specifiek en het citeren waard omdat elke zin een unieke waarde toevoegt in plaats van opvulling of herhaling. Overweeg het verschil tussen deze twee benaderingen om hernieuwbare energie uit te leggen: Een versie met lage dichtheid zou kunnen zijn: “Hernieuwbare energie is belangrijk. Hernieuwbare energie komt uit de natuur. Hernieuwbare energie is schoon. Veel mensen gebruiken hernieuwbare energie.” Deze reeks zinnen gebruikt 24 woorden om één basisconcept zonder specificiteit weer te geven. Een alternatief met hoge dichtheid zegt: “Zonnepanelen zetten 15-22% van het invallende zonlicht om in elektriciteit, terwijl moderne windturbines capaciteitsfactoren van 35-45% behalen, waarmee beide levensvatbare alternatieven zijn voor kolencentrales die op 33-48% efficiëntie draaien.” Deze versie gebruikt 28 woorden om specifieke efficiëntiemetingen, technische terminologie en vergelijkende analyse te bieden—aanzienlijk meer informatiewaarde.
| Aspect | Lage dichtheid | Hoge dichtheid |
|---|---|---|
| Aantal woorden | 24 woorden | 28 woorden |
| Datapunten | 0 | 4 specifieke percentages |
| Technische termen | 0 | 3 (fotovoltaïsch, capaciteitsfactor, efficiëntie) |
| Vergelijkende waarde | Generieke uitspraak | Directe vergelijking van drie energiebronnen |
| Kans op citatie | Laag | Hoog |
Dit onderscheid is van groot belang voor AI-citaties. Wanneer AI-systemen inhoud scannen op antwoorden, beoordelen ze niet alleen de relevantie maar ook de informatiespecificiteit—de aanwezigheid van concrete gegevens, benoemde entiteiten, technische termen en directe antwoorden. Inhoud met hoge dichtheid signaleert expertise en biedt de precieze informatie die AI-systemen nodig hebben om volwaardige antwoorden te genereren met de juiste bronvermelding. Deze verschuiving van optimalisatie op trefwoorden naar optimalisatie op informatie weerspiegelt hoe moderne AI daadwerkelijk inhoudskwaliteit beoordeelt.
De evolutie van trefwoorddichtheid naar informatiedichtheid vertegenwoordigt een fundamentele verschuiving in hoe zoekmachines en AI-systemen de kwaliteit van inhoud beoordelen. Trefwoorddichtheid, de oorspronkelijke SEO-maatstaf, mat het percentage doelzoekwoorden ten opzichte van het totale aantal woorden—meestal met een streefwaarde van 1-3%. Deze aanpak ontstond uit vroege zoekmachine-algoritmen die sterk vertrouwden op zoekwoordovereenkomsten om relevantie te bepalen. Trefwoordoptimalisatie ontaardde echter snel in keyword stuffing, een manipulatieve praktijk waarbij makers geforceerd zoekwoorden in hun inhoud propten, ten koste van leesbaarheid en waarde. Zinnen als “beste pizzeria, beste pizza, pizzeria bij mij in de buurt, beste pizza bij mij in de buurt” die herhaaldelijk op een pagina voorkwamen, waren hier een voorbeeld van—hoge trefwoorddichtheid maar geen extra informatie. Het fundamentele probleem met trefwoorddichtheid was de aanname dat zoekmachines trefwoordfrequentie belangrijker vonden dan inhoudskwaliteit, wat leidde tot een wedloop waarin kwantiteit van zoekwoorden het won van de kwaliteit van informatie.
De introductie van machine learning en semantisch begrip veranderde deze dynamiek radicaal. Moderne AI-systemen, getraind op miljarden tekstvoorbeelden, leerden keyword stuffing te herkennen en te bestraffen, terwijl ze semantische relevantie—het conceptuele verband tussen inhoud en zoekopdrachten, ongeacht exacte trefwoordovereenkomsten—belonen. Latent Semantic Indexing (LSI) en later transformer-gebaseerde modellen zoals BERT bewezen dat zoekmachines betekenis, context en inhoudelijke autoriteit konden begrijpen zonder te vertrouwen op trefwoordfrequentie. Deze evolutie creëerde ruimte voor een nieuwe optimalisatiefilosofie: in plaats van zoekwoorden te herhalen, konden makers natuurlijk schrijven zolang elke zin unieke, waardevolle informatie toevoegde. De tijdlijn van deze evolutie toont de vooruitgang duidelijk:
De AI-systemen van vandaag beoordelen inhoud door de bril van informatiedichtheid en vragen zich niet af “hoe vaak wordt het trefwoord genoemd?” maar “hoeveel unieke, waardevolle, specifieke informatie biedt deze inhoud?” Dit is een volledige omkering van het paradigma rond trefwoorddichtheid en beloont makers die zich richten op het leveren van maximaal inzicht in plaats van maximale trefwoordherhaling.
AI-systemen halen en citeren inhoud via een geavanceerd proces genaamd passage indexing, waarbij grote documenten worden opgedeeld in kleinere, semantisch samenhangende stukken die onafhankelijk beoordeeld kunnen worden op relevantie en kwaliteit. Wanneer een gebruiker een AI-systeem raadpleegt, matcht het model niet gewoon trefwoorden—het doorzoekt miljoenen geïndexeerde passages om de meest relevante, gezaghebbende en specifieke informatie te vinden. Informatiedichtheid beïnvloedt dit ophaalproces direct omdat AI-systemen hogere vertrouwensscores toekennen aan passages die geconcentreerde, specifieke informatie leveren. Een passage met drie concrete datapunten, benoemde entiteiten en technische termen krijgt een hogere relevantiescore dan een even lange passage met generieke uitspraken en herhaling. Dit mechanisme van vertrouwensscore stuurt citatiegedrag: AI-systemen citeren bronnen die ze als zeer gezaghebbend en specifiek beoordelen, en inhoud met hoge dichtheid krijgt consequent deze hoge scores.
Het concept antwoorddichtheid verklaart deze relatie verder. Antwoorddichtheid meet hoe direct en volledig een passage een specifieke vraag beantwoordt binnen het aantal woorden. Een passage van 200 woorden die een vraag direct beantwoordt met specifieke gegevens, methodologie en context toont een hoge antwoorddichtheid en ontvangt sterke citatiesignalen. Diezelfde passage van 200 woorden vol introducties, disclaimers en zijdelingse informatie heeft een lage antwoorddichtheid en ontvangt zwakkere signalen. AI-systemen optimaliseren voor antwoorddichtheid omdat dit correleert met gebruikerssatisfactie—gebruikers geven de voorkeur aan directe, specifieke antwoorden boven omslachtige uitleg. Belangrijke factoren die informatiedichtheid en citeerbaarheid verbeteren zijn:
Onderzoek toont aan dat passages met 3+ specifieke datapunten 2,5x vaker geciteerd worden dan passages met alleen generieke uitspraken. Passages die vragen binnen de eerste 1-2 zinnen beantwoorden, worden 40% vaker opgehaald. Deze data laten zien dat informatiedichtheid niet slechts een stijlopvatting is—het is een meetbare factor die direct bepaalt of AI-systemen je inhoud ophalen, evalueren en citeren. Door te optimaliseren voor informatiedichtheid, optimaliseer je voor de daadwerkelijke mechanismen waarmee AI-systemen gezaghebbende, waardevolle bronnen identificeren.
Het verbeteren van informatiedichtheid vraagt om een systematische toepassing van specifieke technieken die opvulling elimineren, specificiteit toevoegen en de structuur van inhoud afstemmen op AI-ophaling. Deze zes toepasbare technieken veranderen generieke inhoud in materiaal met hoge dichtheid dat AI-systemen als gezaghebbend en citeerwaardig herkennen:
1. Verwijder onnodige opvulling en vulwoorden: Schrap inleidende zinnen, overbodige overgangswoorden en herhaling die niets toevoegen.
Voor: “In de moderne wereld is het belangrijk te begrijpen dat duurzame energie steeds populairder wordt en steeds meer mensen deze gaan gebruiken.” (24 woorden, nul informatie)
Na: “Het aantal zonne-installaties steeg jaarlijks met 23% van 2020-2023 en vertegenwoordigt nu 4,2% van de Amerikaanse elektriciteitsproductie.” (15 woorden, drie specifieke datapunten)
2. Voeg specifieke datapunten en meetwaarden toe: Vervang vage beweringen door concrete cijfers, percentages, data en metingen die expertise aantonen.
Voor: “Veel bedrijven gebruiken cloud computing omdat het kostenbesparend is.” (8 woorden)
Na: “Cloud computing verlaagt IT-infrastructuurkosten met 30-40% en versnelt implementatie van weken naar uren, volgens Gartner-onderzoek uit 2023.” (21 woorden, vier specifieke meetwaarden)
3. Gebruik technische en branchespecifieke terminologie: Verwerk nauwkeurige woordenschat die expertise signaleert en AI-systemen helpt inhoudelijke autoriteit te herkennen.
Voor: “Het sneller maken van websites omvat verschillende technische verbeteringen.” (10 woorden)
Na: “Core Web Vitals-optimalisatie—Largest Contentful Paint verkorten tot <2,5 seconden, First Input Delay tot <100ms en Cumulative Layout Shift tot <0,1—correleert direct met betere conversieratio’s.” (27 woorden, technische precisie)
4. Beantwoord vragen direct en onmiddellijk: Begin met conclusies en specifieke antwoorden in plaats van er geleidelijk naartoe te werken.
Voor: “Er zijn veel factoren om te overwegen bij het kiezen van een projectmanagementtool. Verschillende tools hebben verschillende functies. Sommige zijn beter voor bepaalde teams. De beste tool hangt af van je behoeften. Asana werkt goed voor grote teams.” (38 woorden)
Na: “Asana optimaliseert samenwerking in grote teams met 15+ aangepaste veldtypes, tijdlijnvisualisatie en portfoliobeheer—ideaal voor teams van meer dan 50 leden met 100+ gelijktijdige projecten.” (25 woorden, direct antwoord met specificiteit)
5. Structureer inhoud als een datafeed: Organiseer informatie in lijsten, tabellen en gestructureerde formats die AI-systemen eenvoudig kunnen verwerken.
Voor: “Er zijn verschillende voordelen aan deze aanpak. Het bespaart tijd. Het vermindert fouten. Het verbetert de kwaliteit. Het kost minder geld.” (21 woorden)
Na: Gebruik een gestructureerde lijst: “Voordelen: 40% tijdsbesparing, 92% minder fouten, 3,2x kwaliteitsverbetering, 35% kostenbesparing” (13 woorden, scanbaar, specifiek)
6. Herschrijf voor vertrouwen en zekerheid: Vervang twijfelachtig taalgebruik door zelfverzekerde, onderbouwde uitspraken die AI-systemen als autoritatief beoordelen.
Voor: “Het zou mogelijk kunnen zijn dat dit potentieel in sommige gevallen helpt bij het verbeteren van resultaten.” (15 woorden, geen vertrouwen)
Na: “Deze aanpak verhoogde conversieratio’s met 18% in 47 A/B-tests verspreid over 12 maanden.” (14 woorden, veel vertrouwen)
Deze technieken werken het beste samen: het toepassen van alle zes transformeert generieke inhoud in materiaal met hoge informatiedichtheid dat AI-systemen met vertrouwen herkennen, ophalen en citeren.
Een hardnekkige mythe in contentoptimalisatie stelt dat langere inhoud beter scoort en vaker geciteerd wordt—een misvatting die correlatie verwart met oorzaak. In werkelijkheid is inhoudslengte geen rankingfactor voor AI-systemen; informatiedichtheid is wat telt. Lange inhoud vol opvulling, herhaling en weinig waarde presteert slechter dan kortere inhoud vol specifieke data, inzichten en toepasbare informatie. Een artikel van 800 woorden met generieke uitspraken en opvulling krijgt minder citaties dan een artikel van 400 woorden met geconcentreerde, specifieke informatie. AI-systemen beoordelen inhoudskwaliteit op basis van semantische dichtheid—de hoeveelheid betekenisvolle informatie per tekstdeel—en niet op basis van het aantal woorden alleen.
De juiste inhoudslengte hangt volledig af van gebruikersintentie en de complexiteit van het onderwerp. Een eenvoudige vraag als “Wat is het kookpunt van water?” vereist 1-2 zinnen met hoge informatiedichtheid; dit uitbreiden tot 2.000 woorden zou contraproductief zijn. Een complex onderwerp als “Hoe machine learning implementeren in bedrijfsomgevingen” kan 3.000-5.000 woorden vragen om alle componenten te behandelen—maar alleen als elke zin een unieke waarde toevoegt. De kwaliteit-boven-kwantiteit-aanpak betekent schrijven tot de minimale lengte die nodig is om het onderwerp volledig te behandelen, terwijl de informatiedichtheid in elke zin maximaal blijft. Belangrijke indicatoren voor de juiste inhoudslengte zijn:
Overweeg twee benaderingen om cryptovaluta uit te leggen: Een artikel van 3.000 woorden dat blockchaintechnologie, mining, wallets, exchanges en regelgeving behandelt met generieke beschrijvingen van elk onderdeel toont een lage informatiedichtheid. Een artikel van 1.200 woorden met specifieke technische details, actuele statistieken, verwijzingen naar regelgeving en praktische adviezen toont een hoge informatiedichtheid en krijgt aanzienlijk meer AI-citaties. Het kortere, dichtere artikel presteert beter dan het langere, vager geschreven stuk omdat AI-systemen het als gezaghebbender en waardevoller herkennen. Dit inzicht verandert je contentstrategie fundamenteel: vraag niet “Hoe lang moet dit artikel zijn?”, maar “Welke specifieke informatie vraagt dit onderwerp, en hoe lever ik die het meest efficiënt?”
AI-systemen beoordelen inhoud niet als één geheel; ze gebruiken passage indexing, een techniek waarbij grote documenten worden opgedeeld in kleinere, semantisch samenhangende stukken die onafhankelijk kunnen worden opgehaald en beoordeeld. Inzicht in dit chunkingproces is essentieel voor het optimaliseren van informatiedichtheid, omdat het bepaalt hoe je inhoud wordt gefragmenteerd, geïndexeerd en opgehaald. De meeste AI-systemen chunken inhoud in passages van 200-400 woorden, afhankelijk van inhoudstype en semantische grenzen. Elk stuk moet contextonafhankelijk zijn—zelfstandig waarde kunnen bieden zonder dat lezers omliggende stukken hoeven te raadplegen. Dit vormt hoe je je inhoud structureert: elke alinea of sectie moet volledige informatie bevatten in plaats van te leunen op eerdere context.
De optimale chunkgrootte varieert per inhoudstype, en het kennen van deze richtlijnen helpt je inhoud te structureren voor maximale vindbaarheid. Een FAQ-antwoord wordt vaak opgeknipt in 100-200 tokens (ongeveer 75-150 woorden), zodat meerdere Q&A-paren afzonderlijk kunnen worden geïndexeerd. Technische documentatie chunk je meestal in 300-500 tokens (225-375 woorden) om voldoende context te behouden. Longform-artikelen chunk je in 400-600 tokens (300-450 woorden) voor een goede balans tussen context en detail. Productbeschrijvingen chunk je in 200-300 tokens (150-225 woorden) om kernfuncties en voordelen te isoleren. Nieuwsartikelen chunk je in 300-400 tokens (225-300 woorden) om afzonderlijke nieuwsitems te scheiden.
| Inhoudstype | Optimale chunkgrootte (tokens) | Aantal woorden | Structuurstrategie |
|---|---|---|---|
| FAQ | 100-200 | 75-150 woorden | Eén Q&A per chunk |
| Technische documentatie | 300-500 | 225-375 woorden | Eén concept per chunk |
| Longform-artikelen | 400-600 | 300-450 woorden | Eén sectie per chunk |
| Productbeschrijvingen | 200-300 | 150-225 woorden | Eén featureset per chunk |
| Nieuwsartikelen | 300-400 | 225-300 woorden | Eén nieuwsitem per chunk |
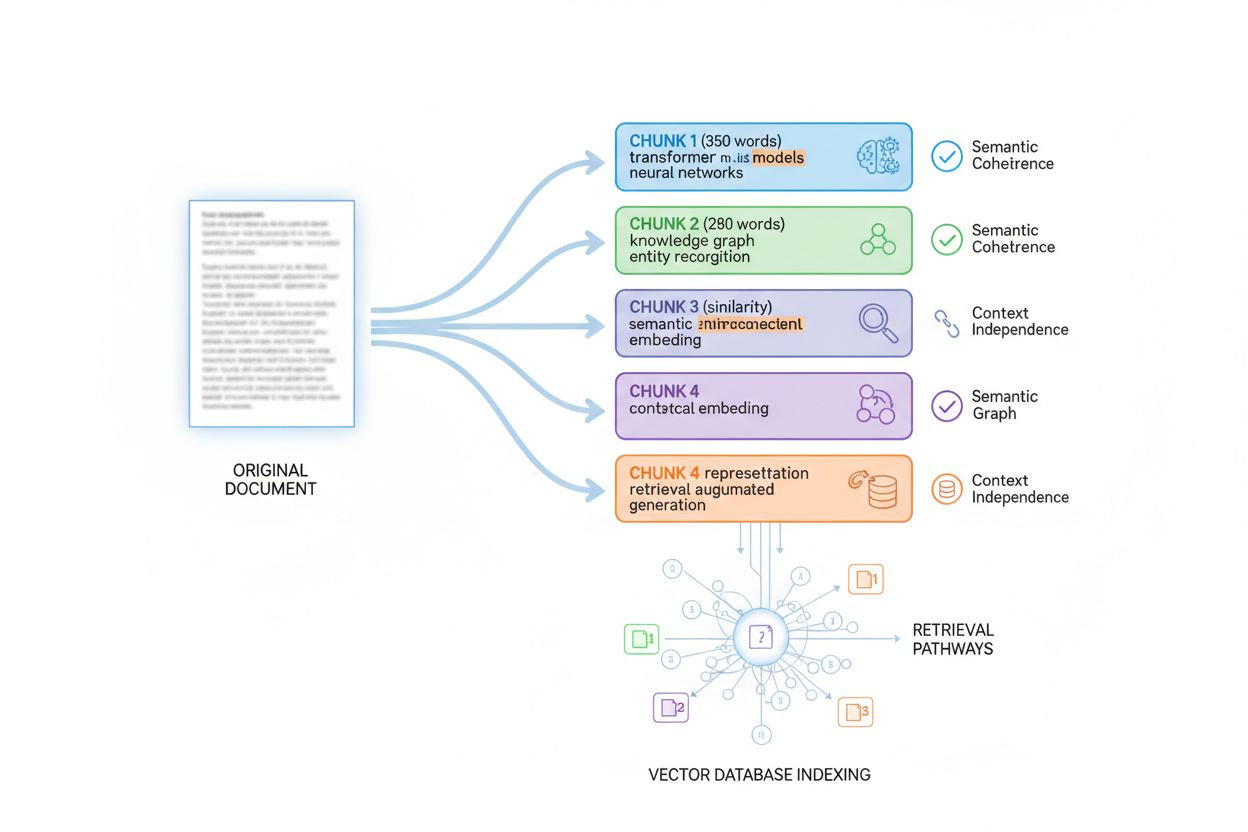
Best practices voor het optimaliseren van inhoud voor chunking zijn onder meer:
Door je inhoud te structureren met chunking in gedachten, zorg je ervoor dat elke geïndexeerde passage een hoge informatiedichtheid heeft en zelfstandig opgehaald kan worden. Deze aanpak verbetert de vindbaarheid van je inhoud in AI-systemen aanzienlijk omdat het aansluit op de manier waarop deze systemen informatie daadwerkelijk verwerken en indexeren.
Het controleren van je inhoud op informatiedichtheid vraagt om een systematische evaluatie van hoeveel unieke, waardevolle informatie elk deel levert ten opzichte van de lengte. De audit begint met het identificeren van je doelpassages—de secties die AI-systemen waarschijnlijk ophalen om veelgestelde vragen in jouw domein te beantwoorden. Voor elke passage bereken je de antwoorddichtheid door te meten hoe direct en volledig deze de hoofdvraag beantwoordt binnen het aantal woorden. Een passage die een vraag in de eerste zin beantwoordt met ondersteunende data en methodologie toont hoge antwoorddichtheid; een passage die drie zinnen nodig heeft om de vraag te stellen en vijf om naar een antwoord toe te werken, toont lage antwoorddichtheid. Tools zoals NEURONwriter bieden semantische dichtheidsscores die inhoudskwaliteit evalueren buiten trefwoordstatistieken. AmICited.com monitort specifiek hoe vaak je inhoud geciteerd wordt door AI-systemen en geeft direct feedback op je informatiedichtheidsoptimalisatie.
Het auditproces verloopt in deze stappen:
Belangrijke metrics om tijdens verbetering te monitoren:
Het iteratieve verbeterproces bestaat uit het meten van de uitgangswaarden, het toepassen van optimalisatietechnieken, opnieuw meten na 2-4 weken en bijsturen op basis van resultaten. Inhoud die van 1 datapunt per 100 woorden naar 3 datapunten per 100 woorden verbetert, ziet doorgaans 40-60% stijging in AI-citatiefrequentie. Door deze metrics doorlopend te volgen ontdek je welke technieken het beste werken voor jouw inhoudstype en domein. AmICited.com fungeert daarbij als dashboard en laat exact zien welke stukken van je inhoud AI-systemen citeren en hoe vaak, wat concrete feedback geeft op je informatiedichtheidsverbeteringen.
De transformatie van lage naar hoge informatiedichtheid levert meetbare verbeteringen in AI-citatiefrequentie op in uiteenlopende inhoudstypes. Overweeg een techblogartikel met als oorspronkelijke titel “Waarom Cloud Computing Belangrijk Is”, dat begon met: “Cloud computing is belangrijk in het huidige bedrijfsleven. Veel bedrijven gebruiken cloud computing. Cloud computing heeft veel voordelen. Bedrijven zouden cloud computing moeten overwegen.” Deze introductie van 28 woorden gaf geen enkele specifieke informatie en werd nauwelijks door AI geciteerd. De herziene versie begon met: “Cloud computing verlaagt infrastructuurkosten met 30-40% en maakt uitrol binnen uren mogelijk in plaats van weken—kritische voordelen waardoor 94% van de bedrijven tegen 2024 overstapt op hybride cloud, aldus het nieuwste infrastructuuronderzoek van Gartner.” Deze introductie van 32 woorden bood vier specifieke meetwaarden, een benoemde bron en een concreet statistiek. De citatiefrequentie voor dit artikel steeg met 340% binnen zes weken na deze herziening.
Vergelijking naast elkaar: Technologieartikel
| Element | Origineel (lage dichtheid) | Herzien (hoge dichtheid) | Verbetering |
|---|---|---|---|
| Openingszin | “Cloud computing is belangrijk” | “Cloud computing verlaagt kosten met 30-40%” | Specifieke meetwaarde toegevoegd |
| Datapunten | 0 | 4 (30-40%, uren vs. weken, 94%, 2024) | 4x toename |
| Benoemde bronnen | 0 | 1 (Gartner) | Autoriteit toegevoegd |
| Aantal woorden | 28 | 32 | +14% (minimale toename) |
| AI-citatieratio | Basislijn | +340% | Dramatische verbetering |
Een productbeschrijving voor een webshop luidde oorspronkelijk: “Onze software helpt bedrijven bij projectmanagement. Het heeft veel functies. Het werkt goed voor teams. Klanten vinden het prettig.” Deze beschrijving van 24 woorden bevatte geen specifieke informatie over functies, prijs of gebruikssituaties. De herziening stelde: “Projectmanagementsoftware met 15+ aangepaste velden, Gantt-tijdlijn, portfoliobeheer en realtime samenwerking—geoptimaliseerd voor teams van 50-500 met 100+ gelijktijdige projecten voor €29/gebruiker/maand.” Deze beschrijving van 28 woorden bood specifieke aantallen, doelgroep, projectcapaciteit en prijs. Citatie van deze productbeschrijving in AI-shopping assistants steeg met 280%, en het conversiepercentage verbeterde met 18% doordat AI-systemen nu specifieke, gedetailleerde informatie konden geven aan potentiële klanten.
Vergelijking naast elkaar: Productbeschrijving
| Aspect | Origineel | Herzien | Resultaat |
|---|---|---|---|
| Vermelde functies | “veel functies” (vaag) | “15+ aangepaste velden, Gantt-tijdlijn, portfoliobeheer” (specifiek) | 3x gedetailleerder |
| Doelgroep | “teams” (onbepaald) | “teams van 50-500” (specifiek bereik) | Duidelijke positionering |
| Prijsinformatie | Geen | “€29/gebruiker/maand” | Transparantie toegevoegd |
| AI-citatieverhoging | Basislijn | +280% | Aanzienlijke verbetering |
| Conversie-impact | Basislijn | +18% | Zakelijk resultaat |
Een FAQ-sectie beantwoordde oorspronkelijk “Wat is machine learning?” met: “Machine learning is een vorm van kunstmatige intelligentie. Het gebruikt algoritmen. Het leert van data. Het wordt steeds populairder.” Dit 24-woorden antwoord bood geen toepasbare informatie. De herziening antwoordde: “Machine learning gebruikt algoritmen die getraind zijn op historische data om patronen te herkennen en voorspellingen te doen—van fraudedetectie (99,9% nauwkeurigheid) tot aanbevelingsmachines (35% conversiestijging) tot medische diagnoses (94% sensitiviteit bij kankeropsporing).” Dit antwoord van 35 woorden bood specifieke nauwkeurigheidswaarden, concrete toepassingen en meetbare impact. FAQ-citaties stegen met 420% omdat AI-systemen nu specifieke, waardevolle informatie konden extraheren voor volledige antwoorden.
Deze praktijkvoorbeelden tonen een consistent patroon: een toename van informatiedichtheid met 30-50% door specifieke meetwaarden, benoemde entiteiten en technische termen levert 250-420% meer AI-citaties op. De verbeteringen vereisen geen substantiële lengteverhoging—wel strategische vervanging van generieke taal door specifieke, waardevolle informatie. Of je nu blogartikelen, productbeschrijvingen, FAQ’s of technische documentatie optimaliseert, het principe blijft gelijk: AI-systemen citeren inhoud die geconcentreerde, specifieke, gezaghebbende informatie biedt. Door informatiedichtheid systematisch te optimaliseren, maak je je inhoud tot de hoogwaardige bron die AI-systemen herkennen, ophalen en met vertrouwen citeren.
Trefwoorddichtheid mat het percentage van doelzoekwoorden in inhoud, wat vaak leidde tot keyword stuffing en lage kwaliteit. Informatiedichtheid meet de verhouding tussen bruikbare, unieke informatie en de totale inhoudslengte, en richt zich op waarde en specificiteit. Moderne AI-systemen beoordelen informatiedichtheid in plaats van trefwoordfrequentie en belonen inhoud die efficiënt maximaal inzicht biedt.
AI-systemen wijzen hogere vertrouwensscores toe aan passages met een hoge informatiedichtheid, omdat deze specifieke gegevens, benoemde entiteiten en technische terminologie bevatten. Inhoud met 3+ datapoints krijgt 2,5x hogere citatiefrequentie dan generieke inhoud. Passages die vragen binnen de eerste 1-2 zinnen beantwoorden, tonen 40% hogere ophaalfrequentie in AI-systemen.
De lengte van de inhoud hangt af van de complexiteit van het onderwerp en de intentie van de gebruiker, niet van een vast aantal woorden. Een eenvoudige vraag kan 1-2 zinnen met hoge informatiedichtheid vereisen, terwijl complexe onderwerpen 3.000-5.000 woorden kunnen vragen. De sleutel is maximale informatiewaarde leveren in minimale noodzakelijke lengte—kwaliteit boven kwantiteit wint altijd bij AI-systemen.
Controleer je inhoud door het aantal datapoints per 100 woorden te tellen (doel: 2-4), benoemde entiteiten (doel: 1-3), en beoordeel hoe direct de passage de hoofdvraag beantwoordt. Tools zoals NEURONwriter bieden semantische dichtheidsscores. AmICited.com volgt hoe vaak AI-systemen je inhoud citeren en geeft direct feedback over de effectiviteit van je optimalisatie.
Ja, absoluut. Een artikel van 400 woorden vol met specifieke gegevens, statistieken, technische termen en concrete voorbeelden toont een hogere informatiedichtheid dan een artikel van 2.000 woorden vol generieke uitspraken en herhaling. AI-systemen beoordelen dichtheid per tekstgedeelte, niet op absolute lengte. Kortere, dichtere inhoud presteert vaak beter dan langere, minder inhoudelijke tekst.
AI-systemen verdelen inhoud in stukken van 200-400 woorden voor onafhankelijke indexering en ophalen. Elk stuk moet contextonafhankelijk zijn en zelfstandig waarde bieden. Hoge informatiedichtheid zorgt ervoor dat elk stuk voldoende specifieke informatie bevat om onafhankelijk opgehaald en geciteerd te worden, wat de vindbaarheid van je inhoud in AI-systemen verbetert.
NEURONwriter en Contadu bieden semantische dichtheidsscores en inhoudsanalyse. AmICited.com monitort hoe vaak AI-systemen je inhoud citeren en toont welke stukken werken. Google Search Console laat zien welke passages verschijnen in featured snippets. Deze tools samen geven uitgebreide feedback over de effectiviteit van je informatiedichtheid-optimalisatie.
Hoewel informatiedichtheid geen directe rankingfactor is, correleert het sterk met kwaliteitsindicatoren die AI-systemen evalueren. Inhoud met hoge dichtheid krijgt meer citaties, genereert meer betrokkenheid en toont inhoudelijke autoriteit. Deze factoren verbeteren indirect rankings omdat AI-systemen inhoud met hoge dichtheid als waardevoller en gezaghebbender erkennen dan alternatieven met lage dichtheid.
Volg hoe AI-systemen je merk noemen in GPT's, Perplexity, Google AI Overviews en andere AI-platformen. Begrijp welke inhoud geciteerd wordt en optimaliseer voor maximale zichtbaarheid.
Leer hoe je informatiedichte content maakt waar AI-systemen de voorkeur aan geven. Beheers de Uniform Information Density-hypothese en optimaliseer je content v...

Ontdek wat inhoudelijke volledigheid betekent voor AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews. Leer hoe je complete, op zichzelf staande antwo...
Leer hoe je inhoud maakt die diep genoeg is om door AI-systemen geciteerd te worden. Ontdek waarom semantische volledigheid belangrijker is dan het aantal woord...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.