
De waarheid over LLMs.txt: Overgewaardeerd of essentieel?
Kritische analyse van de effectiviteit van LLMs.txt. Ontdek of deze AI-contentstandaard essentieel is voor je site of slechts hype. Echte data over adoptie, pla...
9 min lezen

Een voorgestandaardiseerd bestand dat in het hoofddomein van een website wordt geplaatst en communiceert met AI-crawlers en grote taalmodellen over hoogwaardige, citeerbare content. Vergelijkbaar met robots.txt maar ontworpen voor begeleiding tijdens het opvragen (inference) in plaats van toegangscontrole. Helpt AI-systemen om gezaghebbende content te ontdekken en te prioriteren bij het genereren van antwoorden. Wordt steeds vaker geadopteerd door grote AI-platforms zoals OpenAI, Anthropic, Perplexity en Google.
Een voorgestandaardiseerd bestand dat in het hoofddomein van een website wordt geplaatst en communiceert met AI-crawlers en grote taalmodellen over hoogwaardige, citeerbare content. Vergelijkbaar met robots.txt maar ontworpen voor begeleiding tijdens het opvragen (inference) in plaats van toegangscontrole. Helpt AI-systemen om gezaghebbende content te ontdekken en te prioriteren bij het genereren van antwoorden. Wordt steeds vaker geadopteerd door grote AI-platforms zoals OpenAI, Anthropic, Perplexity en Google.
Het LLMs.txt-bestand is een platte tekst in markdown-formaat die op het hoofddomein van een website wordt geplaatst en dient als een samengestelde gids voor grote taalmodellen tijdens het opvragen (inference). In tegenstelling tot traditionele SEO-tools is LLMs.txt ontworpen om AI-crawlers en taalmodellen te helpen hoogwaardige content op je website te ontdekken en te prioriteren wanneer zij antwoorden genereren of informatie zoeken. Deze voorgestelde standaard betekent een verschuiving in hoe websites communiceren met kunstmatige intelligentiesystemen, waarbij men voorbijgaat aan de blokkeringsmechanismen van robots.txt en in plaats daarvan intelligente contentcuratie biedt. Het bestand fungeert als een contentroutekaart die AI-systemen vertelt welke pagina’s, artikelen en bronnen het meest waardevol, gezaghebbend en relevant zijn voor hun doeleinden. Het is belangrijk te begrijpen dat LLMs.txt niet bedoeld is om AI-training te blokkeren of toe te staan—het gaat specifiek om inference-tijdbestemming, en helpt AI-systemen de juiste content te vinden bij het beantwoorden van gebruikersvragen. Het bestand is geschreven in markdown-formaat en opgeslagen als platte tekst, waardoor het eenvoudig te maken en te onderhouden is. Door LLMs.txt te implementeren, kunnen websites ervoor zorgen dat wanneer AI-systemen hun content citeren, ze putten uit de meest accurate, goed gestructureerde en gezaghebbende bronnen die beschikbaar zijn.
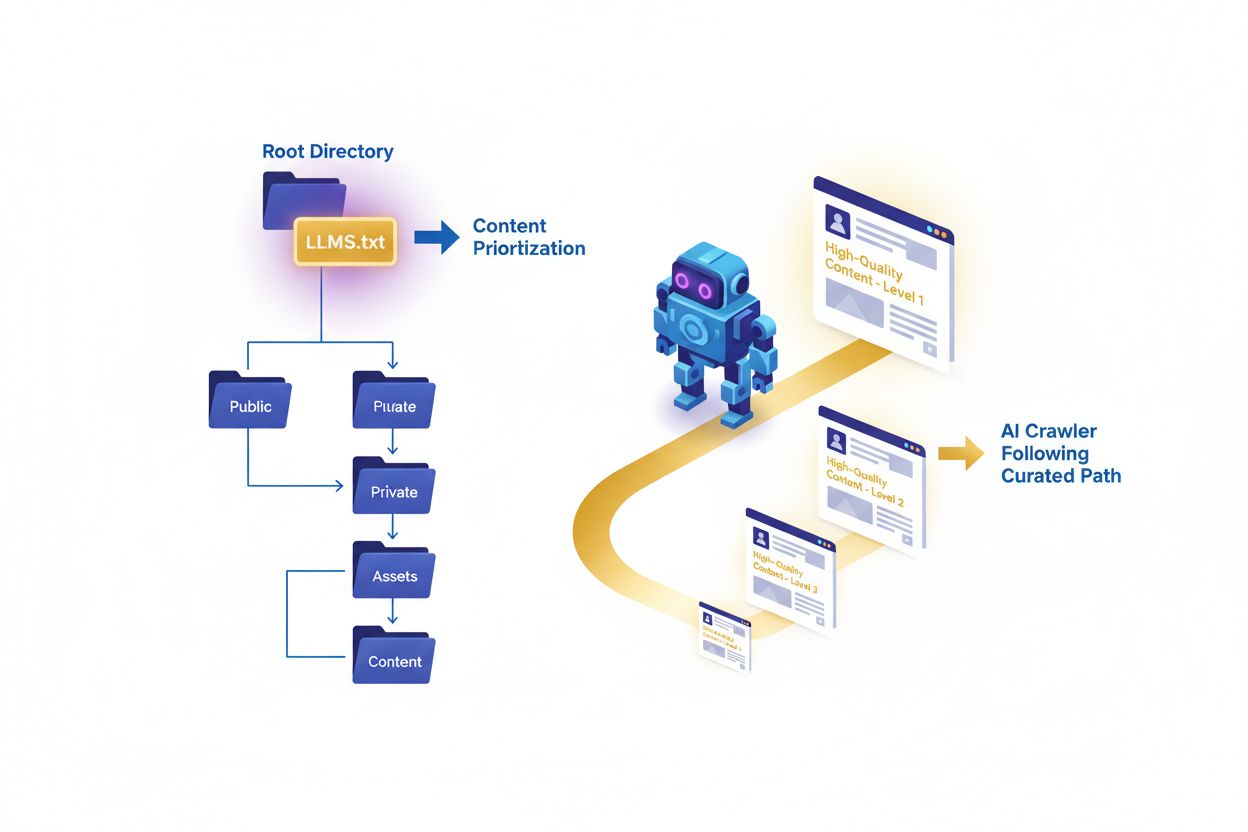
Hoewel robots.txt en sitemap.xml websites goed hebben gediend voor traditionele zoekmachines, voorziet LLMs.txt in een fundamenteel andere behoefte in het tijdperk van kunstmatige intelligentie. Het belangrijkste verschil zit in hun primaire functies en timing: robots.txt regelt het crawlgedrag en wat zoekmachines mogen benaderen, sitemap.xml helpt zoekmachines pagina’s te ontdekken en te indexeren, terwijl LLMs.txt AI-systemen aanstuurt tijdens inference wanneer ze actief antwoorden genereren. Het is cruciaal te begrijpen dat LLMs.txt geen AI-training blokkeert of toestaat—het stelt alleen samen welke content AI-systemen moeten prioriteren bij het beantwoorden van vragen of het ophalen van informatie. De drie bestanden dienen complementaire doelen en kunnen zonder conflict op hetzelfde domein bestaan. Waar robots.txt draait om toegangscontrole en sitemap.xml om vindbaarheid, draait LLMs.txt om contentkwaliteit en relevantie. Zie het als volgt: robots.txt zegt “dit mag je crawlen”, sitemap.xml zegt “dit bestaat er”, en LLMs.txt zegt “dit is het belangrijkste”. Dit onderscheid is vooral belangrijk omdat AI-systemen andere signalen nodig hebben dan traditionele zoekmachines—zij moeten begrijpen welke content gezaghebbend, goed gestructureerd en geschikt voor citatie is.
| Bestand | Primaire functie | Hoofd-doel | Gebruiksscenario |
|---|---|---|---|
| robots.txt | Toegangscontrole | Crawlers toegang geven/blokkeren | Gevoelige pagina’s blokkeren voor zoekmachines |
| sitemap.xml | Vindbaarheid | Zoekmachines helpen pagina’s te vinden | Indexatie van nieuwe of diepgelegen content verbeteren |
| LLMs.txt | Contentcuratie | AI aansturen bij opvragen | AI-systemen naar gezaghebbende bronnen sturen |
Het LLMs.txt-bestand volgt een markdown-gebaseerde structuur die zowel voor mensen leesbaar als door machines te verwerken is, waardoor het toegankelijk is voor zowel contentmakers als AI-systemen. Het bestand begint meestal met een H1-titel (met #) die de website en het doel identificeert, gevolgd door een introductie-blokcitaat dat context geeft over de missie of focus van de site. De kernstructuur bevat georganiseerde secties met H2-koppen (##) die verschillende soorten content categoriseren—zoals “Kernbronnen”, “Gidsen”, “Documentatie” of “Best Practices”—elk met een samengestelde lijst van URL’s met korte omschrijvingen. Een “Optioneel”-sectie aan het einde biedt websites de mogelijkheid om extra bronnen toe te voegen die waardevol kunnen zijn, maar niet tot de primaire selectie behoren. Het bestand gebruikt platte tekst in UTF-8-codering om compatibiliteit met alle systemen en AI-platforms te garanderen. Elke URL-entry bevat meestal het volledige pad en een korte beschrijving waarom die content waardevol is of wat het behandelt. De aanbevolen bestandsgrootte is over het algemeen minder dan 100KB om efficiënte verwerking door AI-systemen te ondersteunen, hoewel er geen harde limiet is. Het markdown-formaat maakt flexibele organisatie mogelijk met behoud van overzichtelijkheid, en de structuur moet de werkelijke contenthiërarchie en belangrijkheid van je site weerspiegelen.
# Voorbeeld Website - LLMs.txt
> Dit is Voorbeeld Website, een uitgebreide bron voor leren over [jouw onderwerp].
> We bieden gezaghebbende gidsen, tutorials en documentatie voor [jouw domein].
## Kernbronnen
- https://example.com/about - Overzicht van onze missie en expertise
- https://example.com/getting-started - Essentieel startpunt voor nieuwe gebruikers
## Uitgebreide Gidsen
- https://example.com/guide/advanced-techniques - Diepgaande verkenning van geavanceerde methoden
- https://example.com/guide/best-practices - Industriestandaarden en aanbevelingen
## Documentatie
- https://example.com/docs/api-reference - Complete API-documentatie
- https://example.com/docs/installation - Installatie- en setupinstructies
## Optioneel
- https://example.com/blog/latest-trends - Recente branche-inzichten
- https://example.com/case-studies - Voorbeelden van echte implementaties
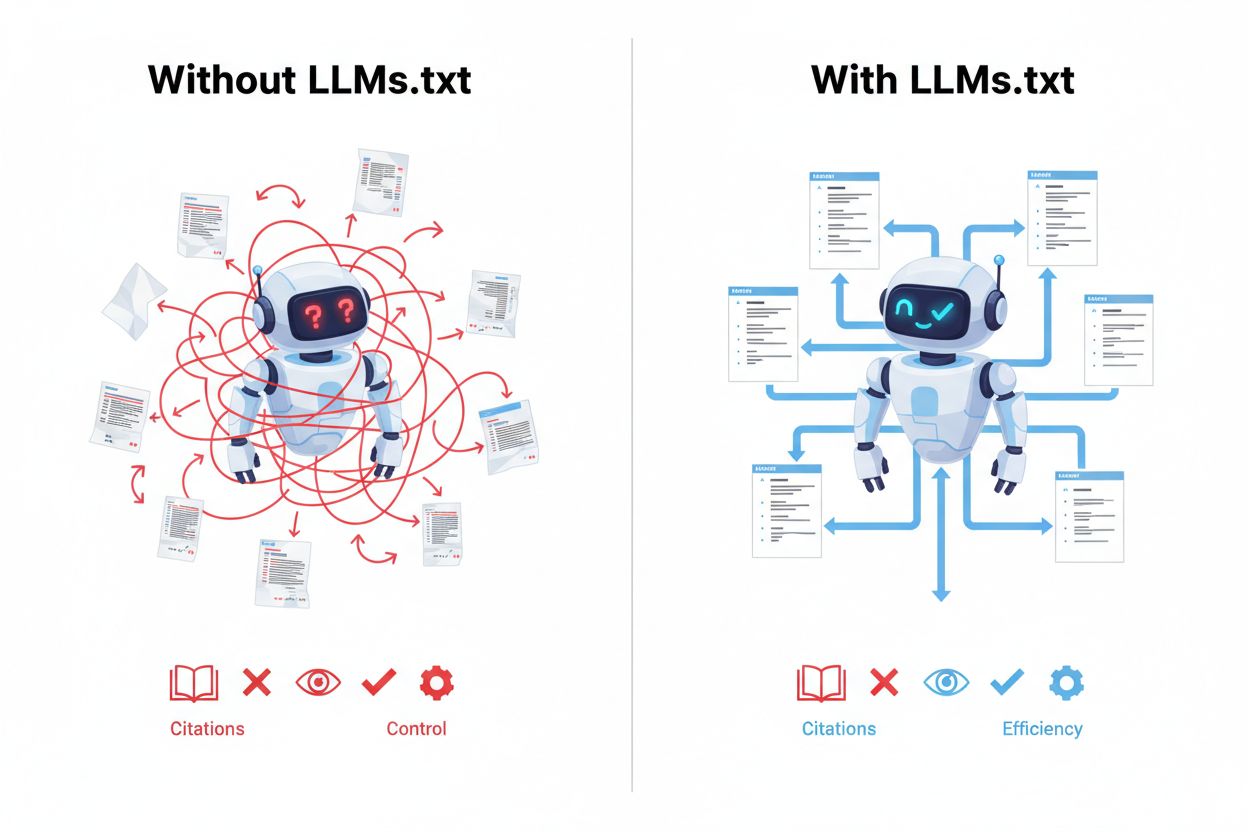
Het implementeren van LLMs.txt levert aanzienlijke voordelen op in het opkomende landschap van AI-gestuurde zoek- en contentontdekking. Het belangrijkste voordeel is inference-tijdbestemming, wat betekent dat je samengestelde content wordt voorgetrokken wanneer AI-systemen actief gebruikersvragen beantwoorden, in plaats van alleen tijdens training. Dit leidt tot betere AI-begrip van de context, autoriteit en relevantie van je content, wat resulteert in meer accurate citaties en verwijzingen wanneer AI-systemen je werk vermelden. Door LLMs.txt te implementeren krijg je directe controle over vindbaarheid, zodat AI-systemen eerst je beste content vinden in plaats van mogelijk minderwaardige pagina’s. Het bestand vergroot je zichtbaarheid in AI-zoekresultaten en AI-gestuurde applicaties, en creëert een nieuw kanaal voor verkeer en toeschrijving dat traditionele SEO aanvult. Organisaties die vroeg LLMs.txt adopteren, verkrijgen een concurrentievoordeel door zich als gezaghebbende bron te vestigen voordat de standaard wijdverspreid wordt. De implementatie dient tevens als toekomstbestendig maken van je website, in aanloop naar de onvermijdelijke verschuiving naar AI-gedreven contentontdekking.
Belangrijkste toepassingsgebieden zijn:
LLM-vriendelijke content heeft specifieke kenmerken die het waardevoller en bruikbaarder maken voor kunstmatige intelligentiesystemen tijdens inference. Het belangrijkste kenmerk is een duidelijke structuur met een juiste koppenhiërarchie, waarbij H1, H2 en H3-tags worden gebruikt om informatie logisch in te delen zodat AI-systemen het verloop en de relaties van de content begrijpen. Korte alinea’s (doorgaans 2-4 zinnen) hebben de voorkeur, omdat AI-systemen discrete concepten en ideeën effectiever kunnen extraheren dan uit lange tekstblokken. Content moet lijsten, tabellen en opsommingen bevatten die complexe informatie opdelen in overzichtelijke onderdelen, waardoor AI specifieke punten makkelijker kan analyseren en citeren. Minimale afleiding zoals automatisch afspelende video’s, pop-ups of overdadige advertenties moeten worden vermeden, omdat deze niet bijdragen aan de kernwaarde van de content. Semantische duidelijkheid is essentieel—gebruik duidelijke taal, definieer technische termen en vermijd dubbelzinnigheid om AI-systemen te helpen je bedoelingen nauwkeurig te begrijpen. De content moet zelfstandig en contextueel zijn, zodat ze ook buiten de oorspronkelijke pagina begrijpelijk blijft. Deze aanpak ondersteunt direct AI-SEO en vergroot de kans dat je content volledig en correct wordt geciteerd wanneer AI-systemen je werk noemen.
Juiste implementatie van LLMs.txt vereist strategisch nadenken over welke content echt een plek verdient en hoe je deze het beste organiseert voor maximale waarde. Het bestand moet op het hoofddomein worden geplaatst (bijv. example.com/llms.txt) zodat AI-systemen en crawlers het eenvoudig kunnen vinden. In plaats van je hele sitemap te plaatsen, focus je op kwaliteit boven kwantiteit—neem alleen je meest gezaghebbende, tijdloze en waardevolle content op die je door AI-systemen wilt laten citeren. Geef prioriteit aan waardevolle bronnen zoals uitgebreide gidsen, documentatie, tutorials en origineel onderzoek die expertise aantonen en echte waarde bieden. Overweeg ook je homepage of over-ons-pagina op te nemen, zodat AI-systemen de missie en geloofwaardigheid van je organisatie begrijpen. De geselecteerde content moet goed onderhouden en regelmatig bijgewerkt worden, want verouderde informatie schaadt je geloofwaardigheid bij AI-systemen. Organiseer content logisch met duidelijke sectiekoppen die de structuur en categorieën van je site weerspiegelen. Vermijd het opnemen van content achter authenticatie, betaalmuren of pagina’s waarvoor een gebruikersaccount nodig is, want AI-systemen kunnen daar niet bij. Controleer en update je LLMs.txt-bestand regelmatig om wijzigingen in je contentstrategie te weerspiegelen, dode links te verwijderen en nieuwe gezaghebbende bronnen toe te voegen zodra deze beschikbaar zijn.
De adoptie van LLMs.txt versnelt snel onder grote AI-platforms en bedrijven die het nut van samengestelde contentbronnen inzien. OpenAI, Anthropic, Perplexity en Google hebben allemaal support voor of interesse in de LLMs.txt-standaard aangegeven; sommige platforms gebruiken het al actief om hun retrieval- en citatiesystemen te verbeteren. De standaard is nog in ontwikkeling en (nog) niet verplicht, maar wordt steeds meer erkend als een best practice voor websites die hun zichtbaarheid in AI-gedreven toepassingen willen optimaliseren. Er zijn inmiddels directories en registers ontstaan die websites catalogiseren die LLMs.txt implementeren, zodat AI-systemen eenvoudiger samengestelde contentbronnen kunnen vinden en prioriteren. Vroege gebruikers profiteren van een aanzienlijk voordeel door zich als gezaghebbende bron te vestigen voordat de standaard wijdverspreid wordt. Praktijkvoorbeelden tonen aan dat websites met LLMs.txt meer citaties en betere weergave krijgen in AI-gegenereerde content. De adoptietrend suggereert dat LLMs.txt net zo standaard zal worden als robots.txt en sitemap.xml in de komende jaren, waardoor implementatie een slimme investering is voor vooruitstrevende organisaties.
Het onderscheid tussen llms.txt en llms-full.txt staat voor twee complementaire benaderingen om AI-systemen door je content te leiden. LLMs.txt is de samengestelde, door mensen geselecteerde versie die alleen je belangrijkste, gezaghebbende en waardevolle content bevat—meestal 20-100 URL’s per categorie met omschrijvingen. LLMs-full.txt daarentegen is een volledige, machineleesbare versie die elke pagina van je website in een gestructureerd formaat bevat, vaak automatisch gegenereerd op basis van je sitemap of contentmanagementsysteem. Het primaire verschil is intentionaliteit: llms.txt vereist menselijke beoordeling en selectie, terwijl llms-full.txt allesomvattend en uitputtend is. Gebruik LLMs.txt als je AI-systemen wilt leiden naar je beste content en duidelijke autoriteitssignalen wilt geven, terwijl llms-full.txt dient als vangnet voor AI-systemen die volledige dekking van je site willen. Beide bestanden gebruiken markdown-opmaak, maar met verschillende organisatiefilosofieën—llms.txt is selectief en strategisch, llms-full.txt is inclusief en volledig. Veel organisaties implementeren beide bestanden samen, zodat AI-systemen kunnen kiezen tussen samengestelde begeleiding (llms.txt) of volledige dekking (llms-full.txt). Zo biedt bijvoorbeeld AIOSEO tools die beide versies automatisch genereren, met llms.txt voor premium content en llms-full.txt voor volledige site-dekking.
Verschillende veelvoorkomende fouten kunnen de effectiviteit van je LLMs.txt-implementatie ondermijnen en moeten zorgvuldig worden vermeden. De belangrijkste fout is het bestand op de verkeerde locatie plaatsen—het moet op het hoofddomein staan (example.com/llms.txt), niet in submappen of met andere bestandsnamen. Ontbrekende vereiste elementen zoals de H1-titel en het inleidende blokcitaat kunnen AI-systemen in verwarring brengen over het doel en de autoriteit van je site. Kapotte of verouderde URL’s schaden je geloofwaardigheid en verspillen de bronnen van AI-systemen die proberen niet-bestaande content te benaderen. Te veel opnemen is ook een veelgemaakte fout—het toevoegen van te veel URL’s (honderden of duizenden) ondermijnt de selectie en maakt het voor AI-systemen moeilijker om echt belangrijke content te herkennen. Slechte of ontbrekende beschrijvingen bij elke URL zorgen ervoor dat AI-systemen niet begrijpen waarom die content waardevol is of wat het behandelt. Je LLMs.txt-bestand niet regelmatig updaten zorgt ervoor dat het verouderd raakt, met dode links en irrelevante content die niet langer de focus van je site weerspiegelt. Content achter authenticatie of betaalmuren opnemen waar AI-systemen niet bij kunnen, zorgt voor frustratie en vermindert het vertrouwen. Zorg tenslotte dat je het juiste MIME-type gebruikt (text/plain of text/markdown) bij het serveren van het bestand, want een verkeerde configuratie kan correcte parsing door AI-systemen verhinderen.
Er zijn verschillende tools en bronnen beschikbaar gekomen om het maken en onderhouden van LLMs.txt-bestanden te vereenvoudigen. AIOSEO biedt een speciale plugin die zowel llms.txt als llms-full.txt automatisch genereert, waardoor implementatie ook voor niet-technische gebruikers toegankelijk is. Wie liever handmatig aan de slag gaat, hoeft alleen een tekstbestand in markdown-formaat te maken en dit naar het hoofddomein te uploaden. Validatietools zijn online beschikbaar om je LLMs.txt-bestand te controleren op correcte opmaak, kapotte links en naleving van de standaard. De GitHub-community heeft tal van repositories gecreëerd met sjablonen, voorbeelden en best practices voor LLMs.txt-implementatie. Officiële documentatie op llmstxt.org biedt uitgebreide richtlijnen over de bestandsstructuur, opmaakvereisten en implementatiestrategieën. Veel AI-platformdocumentatiepagina’s bevatten nu secties over LLMs.txt-ondersteuning, zodat je begrijpt hoe verschillende systemen je samengestelde content gebruiken. Dankzij deze bronnen is het eenvoudiger dan ooit om LLMs.txt te implementeren en ervoor te zorgen dat je content optimaal vindbaar en citeerbaar is voor AI-gestuurde systemen.
LLMs.txt stuurt AI-systemen naar je beste content voor gebruik tijdens het opvragen (inference), terwijl robots.txt bepaalt wat zoekmachinecrawlers kunnen benaderen. Ze hebben verschillende doelen en kunnen op hetzelfde domein naast elkaar bestaan. LLMs.txt draait om selectie en begeleiding, robots.txt om toegangscontrole.
Nee, het is niet verplicht, maar het wordt een best practice. Door LLMs.txt te implementeren krijg je een concurrentievoordeel in AI-gestuurde zoekresultaten en zorg je dat je content correct wordt toegeschreven als deze door AI-systemen wordt geciteerd.
Het bestand moet op de root van je domein worden geplaatst (bijv. jouwsite.com/llms.txt) zodat AI-systemen en crawlers het kunnen vinden. Het moet publiek toegankelijk zijn zonder authenticatie.
Nee, llms.txt is niet ontworpen om te blokkeren of training te controleren. Het is specifiek bedoeld om AI-systemen te begeleiden tijdens inference (het genereren van antwoorden). Gebruik robots.txt of andere mechanismen als je trainingstoegang wilt regelen.
Controleer en werk het elk kwartaal bij, of wanneer je significante wijzigingen aanbrengt in de websitestructuur, belangrijke nieuwe content toevoegt of URL's wijzigt. Regelmatig onderhoud zorgt dat je bestand accuraat en waardevol blijft.
OpenAI, Anthropic, Perplexity en Google zijn begonnen met het implementeren van llms.txt-ondersteuning. De adoptie groeit naarmate de standaard verder wordt ontwikkeld en erkend als best practice.
LLMs.txt is een samengestelde lijst van je beste content (doorgaans 20-100 URL's), terwijl llms-full.txt een volledige machineleesbare versie van al je content in Markdown-formaat bevat. Beide kunnen samen worden gebruikt voor maximale flexibiliteit.
Focus op kwaliteit boven kwantiteit. Neem 10-20 van je belangrijkste, gezaghebbende pagina's op die het beste je expertise en contentwaarde weergeven. Zet niet je hele sitemap in het bestand.
AmICited houdt bij hoe AI-systemen je merk vermelden in ChatGPT, Perplexity, Google AI Overviews en meer. Zorg dat je content correcte toeschrijving en zichtbaarheid krijgt in AI-gegenereerde antwoorden.
Kritische analyse van de effectiviteit van LLMs.txt. Ontdek of deze AI-contentstandaard essentieel is voor je site of slechts hype. Echte data over adoptie, pla...

Leer hoe je LLMs.txt op je website implementeert om AI-systemen te helpen je content beter te begrijpen. Complete stapsgewijze gids voor alle platforms, waarond...

Leer wat LLM Seeding is en hoe je strategisch content plaatst op platforms met hoge autoriteit om AI-training te beïnvloeden en geciteerd te worden door ChatGPT...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.