
Transformer-architectuur
Transformer-architectuur is een neuraal netwerkontwerp dat gebruikmaakt van self-attention-mechanismen om sequentiële data parallel te verwerken. Het vormt de b...
18 min lezen
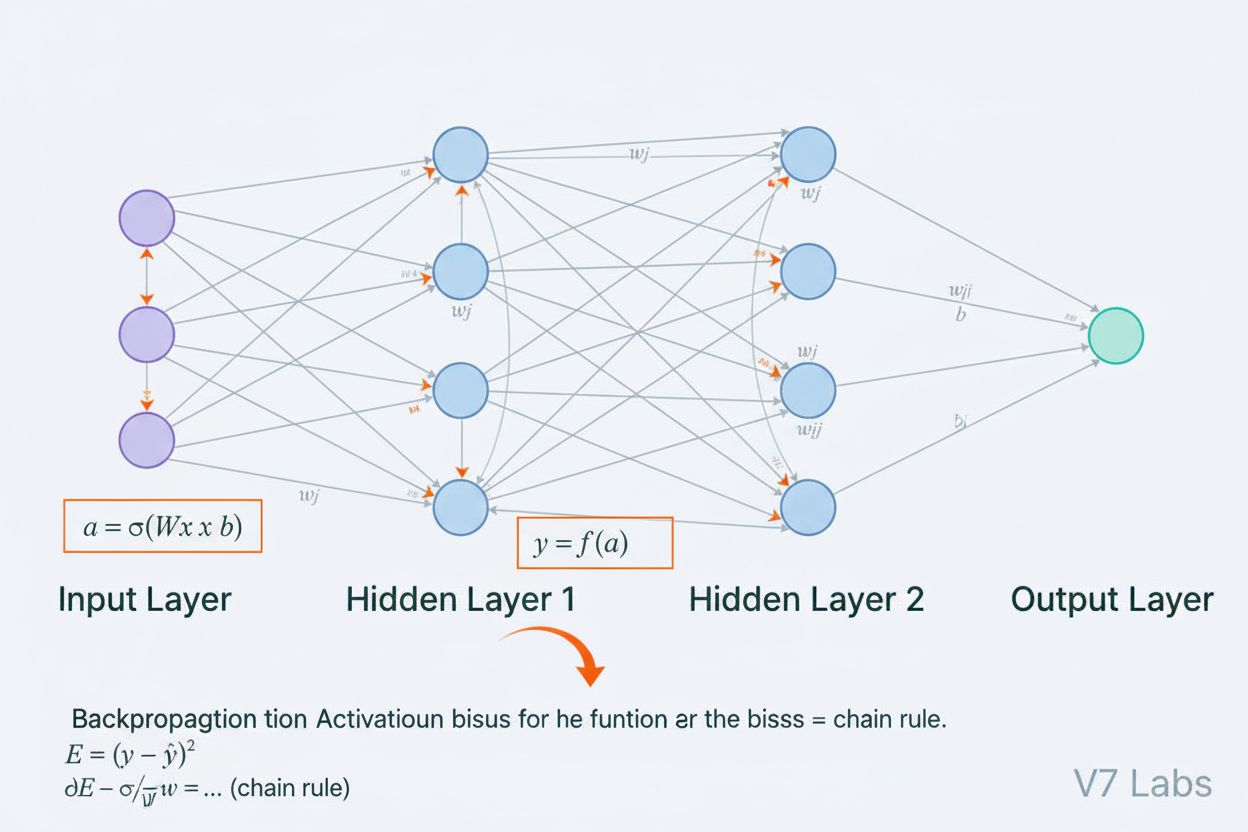
Een neuraal netwerk is een computersysteem geïnspireerd op biologische neurale netwerken, bestaande uit onderling verbonden kunstmatige neuronen die in lagen zijn georganiseerd en in staat zijn patronen uit data te leren via een proces dat backpropagation wordt genoemd. Deze systemen vormen de basis van moderne kunstmatige intelligentie en deep learning, en drijven toepassingen aan van natuurlijke taalverwerking tot computervisie.
Een neuraal netwerk is een computersysteem geïnspireerd op biologische neurale netwerken, bestaande uit onderling verbonden kunstmatige neuronen die in lagen zijn georganiseerd en in staat zijn patronen uit data te leren via een proces dat backpropagation wordt genoemd. Deze systemen vormen de basis van moderne kunstmatige intelligentie en deep learning, en drijven toepassingen aan van natuurlijke taalverwerking tot computervisie.
Een neuraal netwerk is een computersysteem dat fundamenteel is geïnspireerd op de structuur en functie van biologische neurale netwerken in dierenhersenen. Het bestaat uit onderling verbonden kunstmatige neuronen die zijn georganiseerd in lagen—meestal een inputlaag, een of meer verborgen lagen en een outputlaag—die samenwerken om data te verwerken, patronen te herkennen en voorspellingen te doen. Elk neuron ontvangt invoer, past wiskundige transformaties toe via gewichten en biases, en stuurt het resultaat door een activatiefunctie om een output te produceren. Het kenmerkende van neurale netwerken is hun vermogen om te leren van data via een iteratief proces genaamd backpropagation, waarbij het netwerk zijn interne parameters aanpast om voorspellingsfouten te minimaliseren. Dit leervermogen, gecombineerd met hun capaciteit om complexe niet-lineaire relaties te modelleren, heeft neurale netwerken tot de basistechnologie gemaakt achter moderne kunstmatige intelligentiesystemen, van grote taalmodellen tot toepassingen in computervisie.
Het concept van kunstmatige neurale netwerken ontstond uit vroege pogingen om wiskundig te modelleren hoe biologische neuronen communiceren en informatie verwerken. In 1943 stelden Warren McCulloch en Walter Pitts het eerste wiskundige model van een neuron voor, waarmee ze aantoonden dat eenvoudige computationele eenheden logische bewerkingen konden uitvoeren. Deze theoretische basis werd gevolgd door de introductie van de perceptron door Frank Rosenblatt in 1958, een algoritme voor patroonherkenning dat de historische voorloper werd van de hedendaagse geavanceerde neurale netwerkarchitecturen. De perceptron was in wezen een lineair model met een beperkte output, in staat om eenvoudige beslissingsgrenzen te leren. In de jaren zeventig kwam het veld echter tot stilstand toen onderzoekers ontdekten dat enkelvoudige perceptrons geen niet-lineaire problemen zoals de XOR-functie konden oplossen, wat leidde tot de zogenaamde “AI-winter”. De doorbraak kwam in de jaren tachtig met de herontdekking en verfijning van backpropagation, een algoritme dat het trainen van meerlaagse netwerken mogelijk maakte. Deze heropleving versnelde sterk in de jaren 2010 door de beschikbaarheid van enorme datasets, krachtige GPU’s en verfijnde trainingstechnieken, wat leidde tot de deep learning-revolutie die kunstmatige intelligentie heeft getransformeerd.
De architectuur van een neuraal netwerk bestaat uit verschillende essentiële componenten die samenwerken. De inputlaag ontvangt ruwe datafeatures van externe bronnen, waarbij elk neuron in deze laag overeenkomt met één feature. Verborgen lagen doen het zware rekenwerk en transformeren inputs naar steeds abstractere representaties via gewogen combinaties en niet-lineaire activatiefuncties. Het aantal en de grootte van verborgen lagen bepalen het vermogen van het netwerk om complexe patronen te leren—diepere netwerken kunnen meer geavanceerde relaties vastleggen, maar vereisen meer data en rekenkracht. De outputlaag levert de uiteindelijke voorspellingen, waarvan de structuur afhangt van de taak: een enkel neuron voor regressie, meerdere neuronen voor multi-class-classificatie, of gespecialiseerde architecturen voor andere toepassingen. Elke verbinding tussen neuronen heeft een gewicht dat de sterkte van de invloed bepaalt, terwijl elk neuron een bias heeft die zijn activatiedrempel verschuift. Deze gewichten en biases zijn de leerbare parameters die het netwerk tijdens training aanpast. De activatiefunctie die op elk neuron wordt toegepast, introduceert essentiële non-lineariteit, waardoor het netwerk complexe beslissingsgrenzen en patronen kan leren die lineaire modellen niet kunnen vastleggen.
Neurale netwerken leren via een iteratief proces in twee fasen. Tijdens forward propagation stroomt de inputdata door het netwerk, van de inputlaag naar de outputlaag. Bij elk neuron wordt de gewogen som van de inputs plus bias berekend (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b), waarna deze door een activatiefunctie wordt geleid om de output van het neuron te produceren. Dit proces herhaalt zich door elke verborgen laag tot aan de outputlaag, die de voorspelling van het netwerk oplevert. Het netwerk berekent vervolgens de fout tussen zijn voorspelling en het werkelijke label met behulp van een verliesfunctie, die kwantificeert hoe ver de voorspelling van het juiste antwoord afwijkt. In backpropagation wordt deze fout achterwaarts door het netwerk geleid via de kettingregel uit de calculus. Bij elk neuron berekent het algoritme de gradiënt van het verlies ten opzichte van elk gewicht en elke bias, waarmee wordt bepaald hoeveel elke parameter bijdroeg aan de totale fout. Deze gradiënten sturen de parameterupdates: gewichten en biases worden aangepast in de richting tegengesteld aan de gradiënt, geschaald door een learning rate die de stapgrootte bepaalt. Dit proces herhaalt zich vele keren over de trainingsdataset, waardoor het verlies geleidelijk afneemt en de voorspellingen van het netwerk verbeteren. De combinatie van forward propagation, verliesberekening, backpropagation en parameterupdates vormt de complete trainingscyclus waarmee neurale netwerken van data leren.
| Architectuurtype | Primaire Toepassing | Belangrijkste Kenmerk | Sterktes | Beperkingen |
|---|---|---|---|---|
| Feedforward-netwerken | Classificatie, regressie op gestructureerde data | Informatie stroomt slechts in één richting | Simpel, snelle training, interpreteerbaar | Kan sequentiële of ruimtelijke data slecht verwerken |
| Convolutionele neurale netwerken (CNN’s) | Beeldherkenning, computervisie | Convolutionele lagen detecteren ruimtelijke kenmerken | Uitstekend in het oppikken van lokale patronen, parameter-efficiënt | Vereist grote gelabelde afbeeldingsdatasets |
| Recurrente neurale netwerken (RNN’s) | Sequentiële data, tijdreeksen, NLP | Verborgen toestand behoudt geheugen over tijdstappen | Kan variabele lengtes van sequenties verwerken | Heeft last van verdwijnende/exploderende gradiënten |
| Long Short-Term Memory (LSTM) | Lange-afstandsafhankelijkheden in sequenties | Geheugencellen met input/forget/output gates | Behandelt lange termijn afhankelijkheden effectief | Complexer, tragere training dan RNN’s |
| Transformer-netwerken | Natuurlijke taalverwerking, grote taalmodellen | Multi-head attentie, parallelle verwerking | Zeer goed paralleliseerbaar, vangt lange-afstandsrelaties | Vereist enorme rekenkracht |
| Generative Adversarial Networks (GAN’s) | Beeldgeneratie, synthetische datacreatie | Generator- en discriminator-netwerken concurreren | Kan realistische synthetische data genereren | Moeilijk te trainen, mode collapse-problemen |
De introductie van activatiefuncties is een van de belangrijkste innovaties in het ontwerp van neurale netwerken. Zonder activatiefuncties zou een neuraal netwerk wiskundig gelijkwaardig zijn aan één enkele lineaire transformatie, ongeacht het aantal lagen. Dit komt doordat de samenstelling van lineaire functies zelf lineair is, wat het vermogen van het netwerk om complexe patronen te leren ernstig beperkt. Activatiefuncties lossen dit probleem op door bij elk neuron non-lineariteit toe te voegen. De ReLU (Rectified Linear Unit)-functie, gedefinieerd als f(x) = max(0, x), is de populairste keuze in moderne deep learning vanwege zijn computationele efficiëntie en effectiviteit bij het trainen van diepe netwerken. De sigmoidfunctie, f(x) = 1/(1 + e^(-x)), brengt de output terug naar een bereik tussen 0 en 1, waardoor hij nuttig is voor binaire classificatietaken. De tanh-functie, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), levert outputs tussen -1 en 1 en presteert vaak beter dan sigmoid in verborgen lagen. De keuze van activatiefunctie heeft een grote invloed op de leerdynamiek, convergentiesnelheid en uiteindelijke prestaties van het netwerk. Moderne architecturen gebruiken vaak ReLU in verborgen lagen vanwege de efficiëntie, en sigmoid of softmax in outputlagen voor waarschijnlijkheidsschatting. De non-lineariteit van activatiefuncties maakt het mogelijk dat neurale netwerken elke continue functie kunnen benaderen, een eigenschap die bekend staat als het universele benaderingstheorema, en die hun opmerkelijke veelzijdigheid in uiteenlopende toepassingen verklaart.
De markt voor neurale netwerken is explosief gegroeid, wat de centrale rol van deze technologie in moderne kunstmatige intelligentie weerspiegelt. Volgens recent marktonderzoek werd de wereldwijde markt voor neurale netwerksoftware in 2025 gewaardeerd op ongeveer $34,76 miljard en zal deze naar verwachting groeien tot $139,86 miljard in 2030, een samengesteld jaarlijks groeipercentage (CAGR) van 32,10%. De bredere markt voor neurale netwerken laat zelfs nog sterkere groei zien, met schattingen van $34,05 miljard in 2024 naar $385,29 miljard in 2033, met een CAGR van 31,4%. Deze explosieve groei wordt gedreven door verschillende factoren: de toenemende beschikbaarheid van grote datasets, de ontwikkeling van efficiëntere trainingsalgoritmen, de opkomst van GPU’s en gespecialiseerde AI-hardware, en de brede adoptie van neurale netwerken in uiteenlopende sectoren. Volgens het Stanford AI Index Report 2025 meldde 78% van de organisaties in 2024 gebruik te maken van AI, tegen 55% het jaar ervoor, waarbij neurale netwerken de ruggengraat vormen van de meeste bedrijfs-AI-implementaties. De adoptie strekt zich uit over de gezondheidszorg, financiën, industrie, retail en vrijwel elke andere sector, omdat organisaties het concurrentievoordeel van op neurale netwerken gebaseerde systemen voor patroonherkenning, voorspelling en besluitvorming inzien.
Neurale netwerken vormen de motor achter de meest geavanceerde AI-systemen van dit moment, waaronder ChatGPT, Perplexity, Google AI Overviews en Claude. Deze grote taalmodellen zijn gebouwd op transformer-gebaseerde neurale netwerkarchitecturen die aandachtmechanismen gebruiken om menselijke taal met opmerkelijke verfijning te verwerken en te genereren. De transformerarchitectuur, geïntroduceerd in 2017, heeft natuurlijke taalverwerking getransformeerd door parallelle verwerking van volledige sequenties mogelijk te maken in plaats van sequentiële verwerking, wat de trainingsefficiëntie en modelprestaties aanzienlijk heeft verbeterd. In de context van merkmonitoring en AI-citatietracking is kennis van neurale netwerken essentieel, omdat deze systemen neurale netwerken gebruiken om context te begrijpen, relevante informatie op te halen en antwoorden te genereren die mogelijk naar uw merk, domein of content verwijzen of citeren. AmICited gebruikt kennis over hoe neurale netwerken informatie verwerken en ophalen om te monitoren waar uw merk wordt genoemd in AI-gegenereerde antwoorden op meerdere platforms. Naarmate neurale netwerken steeds beter worden in het begrijpen van semantische betekenis en het ophalen van relevante informatie, wordt het monitoren van uw merk in AI-antwoorden steeds belangrijker voor het behouden van merkzichtbaarheid en het beheren van uw online reputatie in het tijdperk van door AI aangedreven zoeken en contentgeneratie.
Het effectief trainen van neurale netwerken brengt aanzienlijke uitdagingen met zich mee waar onderzoekers en praktijkmensen mee te maken hebben. Overfitting treedt op wanneer een netwerk de trainingsdata te goed leert, inclusief de ruis en eigenaardigheden, wat leidt tot slechte prestaties op nieuwe, ongeziene data. Dit is vooral een probleem bij diepe netwerken met veel parameters ten opzichte van de omvang van de trainingsdata. Underfitting is het tegenovergestelde, waarbij het netwerk onvoldoende capaciteit of training heeft om de onderliggende patronen in de data vast te leggen. Het probleem van verdwijnende gradiënten treedt op in zeer diepe netwerken, waar de gradiënten exponentieel kleiner worden tijdens het terugpropageren, waardoor gewichten in vroege lagen nauwelijks of niet worden bijgewerkt. Het exploderende gradiëntenprobleem is het omgekeerde, waarbij de gradiënten exponentieel groter worden en de training onstabiel wordt. Moderne oplossingen omvatten batchnormalisatie, dat laaginputs normaliseert voor stabielere gradiënten; residuele verbindingen (skip connections), die gradiënten direct door lagen laten stromen; en gradiëntafkapping, dat de grootte van gradiënten beperkt. Regularisatietechnieken zoals L1- en L2-regularisatie voegen straffen toe voor grote gewichten, wat eenvoudige modellen stimuleert die beter generaliseren. Dropout schakelt willekeurig neuronen uit tijdens training, waardoor co-adaptatie wordt voorkomen en generalisatie wordt verbeterd. De keuze van optimizer (zoals Adam, SGD of RMSprop) en learning rate heeft een grote invloed op de efficiëntie van de training en de uiteindelijke prestaties. Praktijkmensen moeten zorgvuldig het modelcomplexiteit, de omvang van de trainingsdata, de regularisatie en de optimalisatieparameters balanceren om netwerken te krijgen die effectief leren zonder overfitting.
De evolutie van neurale netwerkarchitecturen volgt een duidelijke lijn naar steeds geavanceerdere mechanismen voor informatieverwerking. Vroege feedforward-netwerken waren beperkt tot vaste inputgroottes en konden geen temporele of sequentiële afhankelijkheden vastleggen. Recurrente neurale netwerken (RNN’s) introduceerden terugkoppellussen, waardoor informatie over tijdstappen kon blijven bestaan en verwerking van variabele-lengte sequenties mogelijk werd. RNN’s hadden echter last van gradiëntproblemen en waren inherent sequentieel, waardoor parallelisatie op moderne hardware onmogelijk werd. Long Short-Term Memory (LSTM)-netwerken losten enkele van deze problemen op via geheugencellen en gating-mechanismen, maar bleven fundamenteel sequentieel. De doorbraak kwam met transformernetwerken, die recursie volledig vervingen door aandachtmechanismen. Het aandachtmechanisme stelt het netwerk in staat dynamisch te focussen op verschillende delen van de input en gewogen combinaties van alle inputelementen parallel te berekenen. Zo kunnen transformers efficiënt lange-afstandsafhankelijkheden vastleggen en tegelijkertijd volledig paralleliseren op GPU-clusters. De transformerarchitectuur, gecombineerd met schaalvergroting (moderne grote taalmodellen bevatten miljarden tot biljoenen parameters), is uiterst effectief gebleken voor natuurlijke taalverwerking, computervisie en multimodale taken. Het succes van transformers heeft geleid tot hun adoptie als standaardarchitectuur voor de meest geavanceerde AI-systemen, inclusief alle grote taalmodellen. Deze evolutie laat zien hoe architecturale innovaties, gecombineerd met meer rekenkracht en grotere datasets, de grenzen van wat neurale netwerken kunnen bereiken steeds verder verleggen.
Het veld van neurale netwerken ontwikkelt zich snel met verschillende veelbelovende richtingen. Neuromorfe computing streeft naar hardware die biologische neurale netwerken beter nabootst, met mogelijk een grotere energie-efficiëntie en rekenkracht. Few-shot en zero-shot learning richt zich op het mogelijk maken dat neurale netwerken leren van minimale voorbeelden, wat meer lijkt op menselijk leren. Uitlegbaarheid en interpretatie worden steeds belangrijker, waarbij onderzoekers technieken ontwikkelen om te begrijpen en te visualiseren wat neurale netwerken leren, essentieel voor toepassingen met grote impact zoals gezondheidszorg, financiën en strafrecht. Federated learning maakt het mogelijk om neurale netwerken te trainen op verspreide data zonder gevoelige informatie te hoeven centraliseren, waarmee privacyvraagstukken worden aangepakt. Quantumneurale netwerken zijn een grensgebied waarin principes uit de quantumcomputing worden gecombineerd met neurale netwerkarchitecturen, wat mogelijk exponentiële versnellingen oplevert voor bepaalde problemen. Multimodale neurale netwerken die tekst, afbeeldingen, audio en video naadloos integreren, worden steeds geavanceerder en maken meeromvattende AI-systemen mogelijk. Energie-efficiënte neurale netwerken worden ontwikkeld om de computationele en milieukosten van training en deployment van grote modellen te verlagen. Naarmate neurale netwerken zich verder ontwikkelen, wordt hun integratie in AI-monitoringsystemen zoals AmICited steeds belangrijker voor organisaties die hun merkpositie in AI-gegenereerde content en antwoorden op platforms als ChatGPT, Perplexity, Google AI Overviews en Claude willen begrijpen en beheren.
Neurale netwerken zijn geïnspireerd op de structuur en functie van biologische neuronen in het menselijk brein. In het brein communiceren neuronen via elektrische signalen over synapsen, die sterker of zwakker kunnen worden op basis van ervaring. Kunstmatige neurale netwerken bootsen dit gedrag na door gebruik te maken van wiskundige modellen van neuronen die via gewogen verbindingen verbonden zijn, waardoor het systeem kan leren en zich aanpassen aan data op een manier die analoog is aan hoe biologische hersenen informatie verwerken en herinneringen vormen.
Backpropagation is het belangrijkste algoritme waarmee neurale netwerken kunnen leren. Tijdens forward propagation stroomt data door de netwerk-lagen en worden voorspellingen gedaan. Het netwerk berekent vervolgens de fout tussen de voorspelde en werkelijke uitkomsten met behulp van een verliesfunctie. In de achterwaartse stap wordt deze fout teruggevoerd door het netwerk via de kettingregel uit de calculus, waarbij wordt berekend hoeveel elk gewicht en bias bijdroeg aan de fout. Gewichten worden vervolgens aangepast in de richting die de fout minimaliseert, meestal met behulp van gradient descent optimalisatie.
De belangrijkste neurale netwerkarchitecturen zijn feedforward-netwerken (data stroomt in één richting), convolutionele neurale netwerken of CNN's (geoptimaliseerd voor beeldverwerking), recurrente neurale netwerken of RNN's (ontworpen voor sequentiële data), long short-term memory-netwerken of LSTM's (verbeterde RNN's met geheugencellen) en transformer-netwerken (met aandachtmechanismen voor parallelle verwerking). Elke architectuur is gespecialiseerd voor verschillende soorten data en taken, van beeldherkenning tot natuurlijke taalverwerking.
Moderne AI-systemen zoals ChatGPT, Perplexity en Claude zijn gebouwd op transformer-gebaseerde neurale netwerken, die aandachtmechanismen gebruiken om taal efficiënt te verwerken. Deze neurale netwerken stellen deze systemen in staat context te begrijpen, samenhangende tekst te genereren en complexe redeneertaken uit te voeren. Het vermogen van neurale netwerken om te leren van enorme datasets en ingewikkelde patronen in taal te herkennen, maakt ze essentieel voor de bouw van conversatie-AI die menselijke vragen met opmerkelijke nauwkeurigheid kan begrijpen en beantwoorden.
Gewichten in neurale netwerken bepalen de sterkte van de verbindingen tussen neuronen, en bepalen hoeveel invloed elke input heeft op de output. Biases zijn extra parameters die de activatiedrempel van neuronen verschuiven, zodat ze kunnen activeren, zelfs als inputs zwak zijn. Samen vormen gewichten en biases de leerbare parameters van het netwerk die tijdens training worden aangepast om voorspellingsfouten te minimaliseren en het netwerk complexe patronen uit data te laten leren.
Activatiefuncties brengen non-lineariteit in neurale netwerken, waardoor ze complexe, niet-lineaire relaties in data kunnen leren. Zonder activatiefuncties zou het stapelen van meerdere lagen nog steeds resulteren in lineaire transformaties, wat het leervermogen van het netwerk ernstig beperkt. Veelgebruikte activatiefuncties zijn onder andere ReLU (Rectified Linear Unit), sigmoid en tanh, die elk verschillende vormen van non-lineariteit introduceren die het netwerk helpen ingewikkelde patronen te herkennen en geavanceerdere voorspellingen te doen.
Verborgen lagen zijn tussenliggende lagen tussen input- en outputlagen waarin het netwerk het grootste deel van zijn rekentaken uitvoert. Deze lagen extraheren en transformeren kenmerken uit ruwe inputdata naar steeds abstractere representaties. De diepte en breedte van verborgen lagen bepalen het vermogen van het netwerk om complexe patronen te leren. Diepere netwerken met meer verborgen lagen kunnen meer geavanceerde relaties in data vastleggen, maar vereisen meer rekenkracht en zorgvuldige training om overfitting te voorkomen.
Begin met het volgen van hoe AI-chatbots uw merk vermelden op ChatGPT, Perplexity en andere platforms. Krijg bruikbare inzichten om uw AI-aanwezigheid te verbeteren.
Transformer-architectuur is een neuraal netwerkontwerp dat gebruikmaakt van self-attention-mechanismen om sequentiële data parallel te verwerken. Het vormt de b...

Modelparameters zijn leerbare variabelen in AI-modellen die het gedrag bepalen. Begrijp gewichten, biases en hoe parameters invloed hebben op AI-modelprestaties...
Navigatiestructuur is het systeem dat websitepagina's en links organiseert om gebruikers en AI-crawlers te begeleiden. Ontdek hoe dit SEO, gebruikerservaring en...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.