Een Retrieval-Augmented Generation (RAG)-pijplijn is een workflow waarmee AI-systemen externe bronnen kunnen vinden, rangschikken en citeren bij het genereren van antwoorden. Het combineert documentophaling, semantische rangschikking en LLM-generatie om nauwkeurige, contextueel relevante antwoorden te bieden die gebaseerd zijn op echte data. RAG-systemen verminderen hallucinaties door externe kennisbanken te raadplegen voordat antwoorden worden gegenereerd, waardoor ze essentieel zijn voor toepassingen die feitelijke nauwkeurigheid en bronvermelding vereisen.
RAG-pijplijn
Een Retrieval-Augmented Generation (RAG)-pijplijn is een workflow waarmee AI-systemen externe bronnen kunnen vinden, rangschikken en citeren bij het genereren van antwoorden. Het combineert documentophaling, semantische rangschikking en LLM-generatie om nauwkeurige, contextueel relevante antwoorden te bieden die gebaseerd zijn op echte data. RAG-systemen verminderen hallucinaties door externe kennisbanken te raadplegen voordat antwoorden worden gegenereerd, waardoor ze essentieel zijn voor toepassingen die feitelijke nauwkeurigheid en bronvermelding vereisen.
Wat is een RAG-pijplijn?
Een Retrieval-Augmented Generation (RAG)-pijplijn is een AI-architectuur die informatieophaling combineert met generatie door grote taalmodellen (LLM’s) om nauwkeurigere, contextueel relevante en verifieerbare antwoorden te produceren. In plaats van uitsluitend te vertrouwen op de trainingsdata van een LLM, halen RAG-systemen dynamisch relevante documenten of data op uit externe kennisbanken voordat antwoorden worden gegenereerd. Dit vermindert hallucinaties aanzienlijk en verbetert de feitelijke nauwkeurigheid. De pijplijn vormt een brug tussen statische trainingsdata en realtime informatie, waardoor AI-systemen actuele, domeinspecifieke of propriëtaire content kunnen raadplegen. Deze aanpak is essentieel geworden voor organisaties die antwoorden met bronvermelding, naleving van nauwkeurigheidsnormen en transparantie in AI-gegenereerde content vereisen. RAG-pijplijnen zijn vooral waardevol bij het monitoren van AI-systemen waar traceerbaarheid en bronattributie cruciale vereisten zijn.
Kerncomponenten
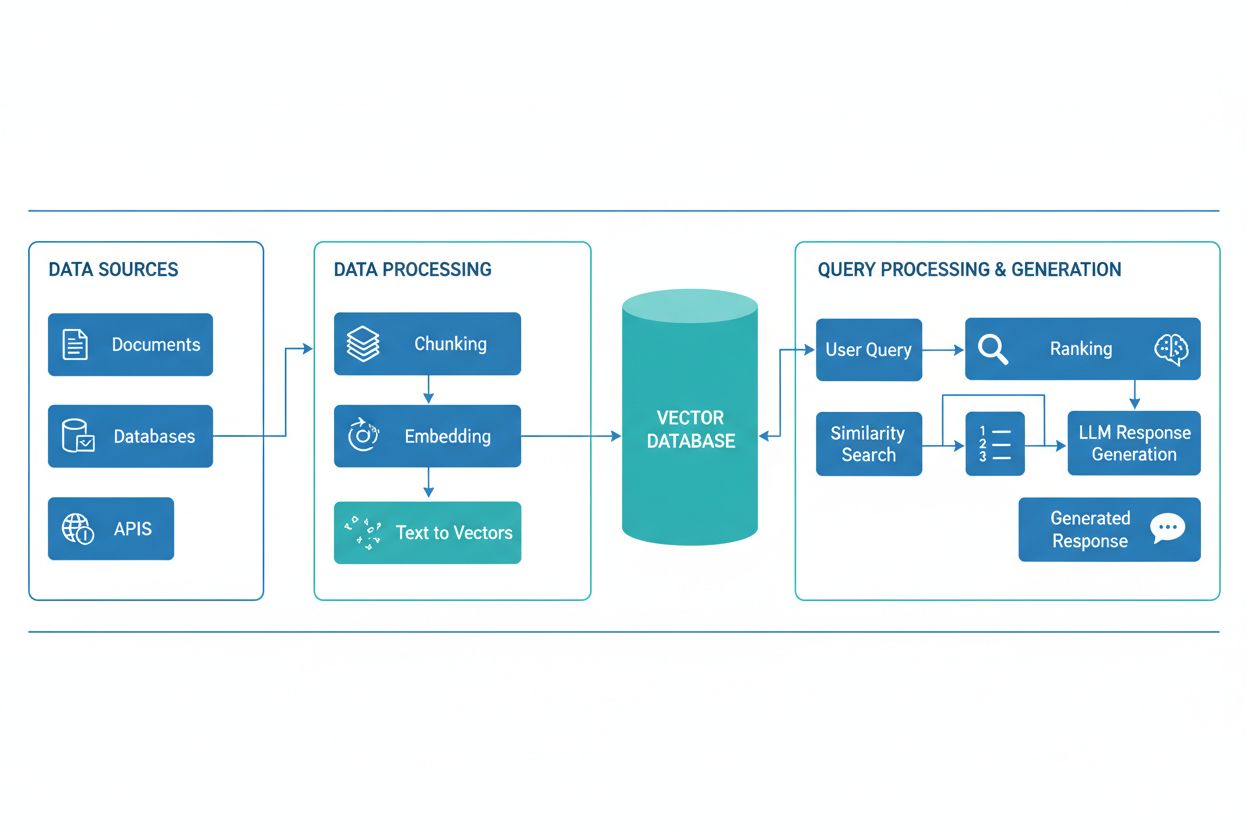
Een RAG-pijplijn bestaat uit verschillende onderling verbonden componenten die samenwerken om relevante informatie op te halen en onderbouwde antwoorden te genereren. De architectuur omvat doorgaans een documentinvoerlaag die ruwe data verwerkt en voorbereidt, een vectordatabase of kennisbank die embeddings en geïndexeerde content opslaat, een ophaalmechanisme dat relevante documenten identificeert op basis van gebruikersvragen, een rangschikking die de meest relevante resultaten prioriteert, en een generatiemodule aangedreven door een LLM die opgehaalde informatie samenvoegt tot samenhangende antwoorden. Extra componenten zijn queryverwerking en -voorverwerking die gebruikersinput normaliseren, embeddingmodellen die tekst omzetten in numerieke representaties, en een feedbacklus die de ophaalnauwkeurigheid voortdurend verbetert. De orkestratie van deze componenten bepaalt de algehele effectiviteit en efficiëntie van het RAG-systeem.
Component
Functie
Belangrijkste technologieën
Documentinvoer
Verwerken en voorbereiden van ruwe data
Apache Kafka, LangChain, Unstructured
Vectordatabase
Opslaan van embeddings en geïndexeerde content
Pinecone, Weaviate, Milvus, Qdrant
Ophaalmachine
Identificeren van relevante documenten
BM25, Dense Passage Retrieval (DPR)
Rangschikking
Prioriteren van zoekresultaten
Cross-encoders, LLM-gebaseerde herordening
Generatiemodule
Antwoorden samenstellen uit context
GPT-4, Claude, Llama, Mistral
Queryprocessor
Normaliseren en begrijpen van gebruikersinput
BERT, T5, aangepaste NLP-pijplijnen
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
De RAG-pijplijn werkt via twee afzonderlijke fasen: de ophaalfase en de generatie-fase. Tijdens de ophaalfase zet het systeem de gebruikersvraag om in een embedding met behulp van hetzelfde embeddingmodel als waarmee de kennisbankdocumenten zijn verwerkt. Vervolgens wordt de vectordatabase doorzocht om de meest semantisch vergelijkbare documenten of passages te vinden. Deze fase levert doorgaans een gerangschikte lijst van kandidaat-documenten op, die verder kan worden verfijnd met herordeningalgoritmen die cross-encoders of LLM-gebaseerde scores gebruiken om relevantie te waarborgen. In de generatie-fase worden de hoogst gerangschikte opgehaalde documenten geformatteerd tot een contextvenster en samen met de oorspronkelijke query aan de LLM aangeboden, waardoor het model antwoorden kan genereren die gebaseerd zijn op daadwerkelijk bronmateriaal. Deze tweeledige aanpak zorgt ervoor dat antwoorden zowel contextueel passend als herleidbaar naar specifieke bronnen zijn, wat het ideaal maakt voor toepassingen die citatie en verantwoording vereisen. De kwaliteit van de uiteindelijke output hangt sterk af van zowel de relevantie van opgehaalde documenten als het vermogen van de LLM om informatie samenhangend te synthetiseren.
Belangrijkste technologieën & tools
Het RAG-ecosysteem omvat een breed scala aan gespecialiseerde tools en frameworks die het bouwen en implementeren van pijplijnen vereenvoudigen. Moderne RAG-implementaties maken gebruik van verschillende categorieën technologie:
Orkestratieframeworks: LangChain, LlamaIndex (voorheen GPT Index) en Haystack bieden abstractielagen om RAG-workflows te bouwen zonder elk onderdeel apart te hoeven beheren
Vectordatabases: Pinecone, Weaviate, Milvus, Qdrant en Chroma bieden schaalbare opslag en retrieval van hoog-dimensionale embeddings met sub-millisec. querylatenties
Embeddingmodellen: OpenAI’s text-embedding-3, Cohere’s Embed API en open-source modellen zoals all-MiniLM-L6-v2 zetten tekst om in semantische representaties
LLM-aanbieders: OpenAI (GPT-4), Anthropic (Claude), Meta (Llama) en Mistral bieden verschillende modelgroottes en mogelijkheden voor generatie-taken
Herordeningoplossingen: Cohere’s Rerank API, cross-encodermodellen van Hugging Face en propriëtaire LLM-gebaseerde herordenaars verbeteren de ophaalprecisie
Datavoorbereidingstools: Unstructured, Apache Kafka en aangepaste ETL-pijplijnen verzorgen documentinvoer, chunking en voorverwerking
Monitoring en evaluatie: Tools zoals Ragas, TruLens en aangepaste evaluatieframeworks beoordelen de prestaties van RAG-systemen en identificeren faalpatronen
Deze tools kunnen modulair worden gecombineerd, waardoor organisaties RAG-systemen kunnen bouwen die zijn afgestemd op hun specifieke vereisten en infrastructuurbeperkingen.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Ophaalmechanismen
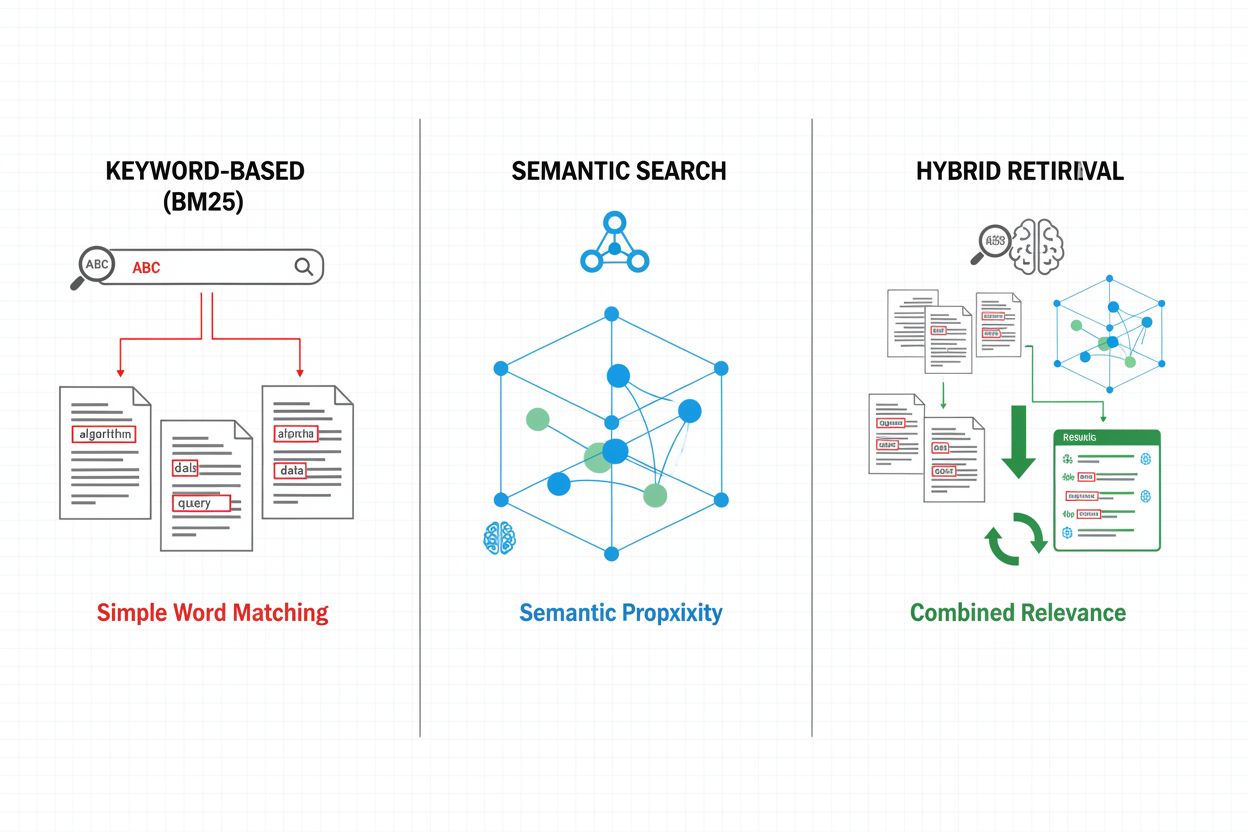
Ophaalmechanismen vormen de basis van de effectiviteit van een RAG-pijplijn, en zijn geëvolueerd van eenvoudige trefwoordbenaderingen tot geavanceerde semantische zoekmethoden. Traditionele trefwoordgebaseerde retrieval met BM25-algoritmen blijft efficiënt en effectief voor exacte overeenkomsten, maar schiet tekort in semantisch begrip en synoniemen. Dense Passage Retrieval (DPR) en andere neurale ophaalmethoden pakken deze tekortkomingen aan door zowel queries als documenten te coderen in dichte vectorembeddings, waardoor semantische gelijkenis wordt gematcht die verder gaat dan oppervlakkige trefwoorden. Hybride ophaalmethoden combineren trefwoordgebaseerd en semantisch zoeken en benutten zo de sterke punten van beide methoden om recall en precisie te verbeteren voor uiteenlopende querytypen. Geavanceerde ophaalmechanismen omvatten queryuitbreiding, waarbij de oorspronkelijke vraag wordt aangevuld met gerelateerde termen of herformuleringen om meer relevante documenten te vinden. Herordeneringslagen verfijnen de resultaten verder door duurdere modellen toe te passen die kandidaat-documenten beoordelen op diepgaander semantisch begrip of taakspecifieke relevantiecriteria. De keuze van het ophaalmechanisme heeft een grote invloed op zowel de nauwkeurigheid van de opgehaalde context als de rekensnelheid van de RAG-pijplijn, waardoor een zorgvuldige afweging tussen snelheid en kwaliteit vereist is.
Voordelen van RAG-pijplijnen
RAG-pijplijnen bieden aanzienlijke voordelen ten opzichte van traditionele LLM-only benaderingen, vooral voor toepassingen die nauwkeurigheid, actualiteit en traceerbaarheid vereisen. Door antwoorden te baseren op opgehaalde documenten, verminderen RAG-systemen hallucinaties drastisch—gevallen waarin LLM’s aannemelijk klinkende maar feitelijk onjuiste informatie genereren—waardoor ze geschikt zijn voor kritieke domeinen zoals gezondheidszorg, juridische en financiële diensten. De mogelijkheid om externe kennisbanken te raadplegen stelt RAG-systemen in staat actuele informatie te bieden zonder modellen opnieuw te moeten trainen, zodat organisaties up-to-date antwoorden kunnen blijven geven wanneer er nieuwe informatie beschikbaar komt. RAG-pijplijnen ondersteunen domeinspecifieke aanpassing door propriëtaire documenten, interne kennisbanken en gespecialiseerde terminologie toe te voegen, waardoor relevantere en contextueel passende antwoorden mogelijk zijn. Het ophaalonderdeel biedt transparantie en controleerbaarheid door expliciet te tonen welke bronnen elk antwoord hebben geïnformeerd, wat belangrijk is voor compliance-eisen en gebruikersvertrouwen. De kostenefficiëntie verbetert door gebruik te maken van kleinere, efficiëntere LLM’s die hoogwaardige antwoorden kunnen genereren wanneer ze relevante context krijgen, en zo de rekenlast verlagen ten opzichte van grotere modellen. Deze voordelen maken RAG bijzonder waardevol voor organisaties die AI-monitoringsystemen implementeren waarbij citaatnauwkeurigheid en contentzichtbaarheid voorop staan.
Uitdagingen en beperkingen
Ondanks hun voordelen ondervinden RAG-pijplijnen verschillende technische en operationele uitdagingen die zorgvuldig beheer vereisen. De kwaliteit van opgehaalde documenten bepaalt direct de antwoordkwaliteit, waardoor ophaalfouten moeilijk te herstellen zijn—een fenomeen bekend als “garbage in, garbage out”, waarbij irrelevante of verouderde documenten uit de kennisbank doordringen tot het uiteindelijke antwoord. Embeddingmodellen kunnen moeite hebben met domeinspecifieke terminologie, zeldzame talen of zeer technische inhoud, wat leidt tot slechte semantische matching en het missen van relevante documenten. De rekenkosten van retrieval, embeddinggeneratie en herordening kunnen aanzienlijk zijn op schaal, vooral bij grote kennisbanken of hoge queryvolumes. Beperkingen van het contextvenster in LLM’s beperken de hoeveelheid opgehaalde informatie die in prompts kan worden verwerkt, waardoor zorgvuldige selectie en samenvatting van relevante passages noodzakelijk is. Het actueel en consistent houden van de kennisbank vormt operationele uitdagingen, vooral in dynamische omgevingen waar informatie vaak verandert of uit meerdere bronnen komt. Het evalueren van RAG-systeemprestaties vereist uitgebreide meetmethoden, verder dan traditionele nauwkeurigheidsmaatstaven, waaronder ophaalprecisie, antwoordrelevantie en citaatcorrectheid, die lastig automatisch te beoordelen zijn.
RAG versus andere benaderingen
RAG is één van de strategieën om de nauwkeurigheid en relevantie van LLM’s te verbeteren, elk met hun eigen afwegingen. Fine-tuning houdt in dat LLM’s opnieuw getraind worden op domeinspecifieke data, wat diepe modelaanpassing oplevert maar aanzienlijke rekenkracht, gelabelde data en voortdurend onderhoud vereist naarmate informatie verandert. Prompt engineering optimaliseert instructies en context voor LLM’s zonder de modelgewichten te wijzigen, biedt flexibiliteit en lage kosten, maar is beperkt door de trainingsdata van het model en de grootte van het contextvenster. In-context learning gebruikt enkele voorbeelden in prompts om modelgedrag te sturen, biedt snelle aanpassing maar verbruikt waardevolle contexttokens en vereist zorgvuldige voorbeeldselectie. Vergeleken met deze benaderingen biedt RAG een tussenweg: het biedt dynamische toegang tot actuele informatie zonder hertraining, behoudt transparantie via expliciete bronvermelding en schaalt efficiënt over diverse kennisdomeinen. RAG brengt echter extra complexiteit met zich mee door retrievalinfrastructuur en mogelijke ophaalfouten, terwijl fine-tuning zorgt voor nauwere integratie van domeinkennis in het modelgedrag. De optimale aanpak combineert vaak meerdere strategieën—bijvoorbeeld RAG met getunede modellen en zorgvuldig ontworpen prompts—om nauwkeurigheid en relevantie te maximaliseren voor specifieke toepassingen.
Bouwen en implementeren van RAG
Het implementeren van een productieklare RAG-pijplijn vereist systematische planning op het gebied van datavoorbereiding, architectuurontwerp en operationele overwegingen. Het proces begint met de voorbereiding van de kennisbank: relevante documenten verzamelen, formaten opschonen en standaardiseren, en content opdelen in geschikte stukken die contextbehoud en ophaalprecisie in balans brengen. Vervolgens kiezen organisaties embeddingmodellen en vectordatabases op basis van prestatie-eisen, latency en schaalbaarheid, rekening houdend met factoren als embeddingdimensionaliteit, querydoorvoer en opslagcapaciteit. Het ophaalsysteem wordt daarna geconfigureerd, inclusief keuzes over retrievalalgoritmen (trefwoord, semantisch of hybride), herordeningstrategieën en criterium voor resultaatsfiltering. Integratie met LLM-aanbieders volgt, waarbij verbindingen met generatiemodellen worden gelegd en promptsjablonen worden gedefinieerd die opgehaalde context effectief verwerken. Testen en evalueren zijn cruciaal, met meetmethoden voor ophaalkwaliteit (precisie, recall, MRR), generatiekwaliteit (relevantie, samenhang, feitelijkheid) en end-to-end systeemprestaties. Implementatieoverwegingen omvatten het opzetten van monitoring voor ophaal- en generatiekwaliteit, het implementeren van feedbacklussen om faalpatronen te identificeren en aan te pakken, en het organiseren van processen voor updates en onderhoud van de kennisbank. Doorlopende optimalisatie bestaat uit het analyseren van gebruikersinteracties, het herkennen van veel voorkomende faalpatronen en het iteratief verbeteren van ophaalmechanismen, herordening en prompt engineering om de systeemprestaties te verhogen.
RAG in AI-monitoring en citatie
RAG-pijplijnen vormen de basis van moderne AI-monitoringplatforms zoals AmICited.com, waar het volgen van de bronnen en nauwkeurigheid van AI-gegenereerde content essentieel is. Door expliciet bronmateriaal op te halen en te citeren, creëren RAG-systemen een controleerbare keten waarmee monitoringplatforms claims kunnen verifiëren, feitelijke nauwkeurigheid kunnen beoordelen en mogelijke hallucinaties of verkeerde toeschrijvingen kunnen opsporen. Deze citaatmogelijkheid vult een belangrijke lacune in AI-transparantie: gebruikers en auditors kunnen antwoorden terugleiden naar de oorspronkelijke bronnen, wat onafhankelijke verificatie en vertrouwen in AI-content mogelijk maakt. Voor contentmakers en organisaties die AI-tools gebruiken, biedt monitoring met RAG inzicht in welke bronnen specifieke antwoorden hebben geïnformeerd, wat compliance ondersteunt met attributie-eisen en beheersbeleid voor content. Het retrievalonderdeel van RAG-pijplijnen genereert rijke metadata—waaronder relevantiescores, documentrangschikkingen en ophaalvertrouwensmetrics—die door monitoringsystemen kunnen worden geanalyseerd om de betrouwbaarheid van antwoorden te beoordelen en te identificeren wanneer AI-systemen buiten hun kennisdomein opereren. Integratie van RAG in monitoringplatforms maakt detectie mogelijk van citaatverschuiving, waarbij AI-systemen langzaam afwijken van gezaghebbende bronnen naar minder betrouwbare, en ondersteunt de handhaving van contentbeleid rond bronkwaliteit en diversiteit. Nu AI-systemen steeds meer worden geïntegreerd in kritische workflows, creëert de combinatie van RAG-pijplijnen met uitgebreide monitoring verantwoordingsmechanismen die gebruikers, organisaties en het bredere informatiesysteem beschermen tegen door AI gegenereerde desinformatie.
Veelgestelde vragen
Wat is het verschil tussen RAG en fine-tuning?
RAG en fine-tuning zijn complementaire benaderingen om de prestaties van LLM's te verbeteren. RAG haalt externe documenten op tijdens het uitvoeren van een query zonder het model aan te passen, waardoor er realtime toegang is tot data en eenvoudige updates mogelijk zijn. Fine-tuning traint het model opnieuw op domeinspecifieke data, wat diepere aanpassing biedt, maar aanzienlijke rekenkracht en handmatige updates vereist wanneer informatie verandert. Veel organisaties combineren beide technieken voor optimale resultaten.
Hoe vermindert RAG hallucinaties in AI-antwoorden?
RAG vermindert hallucinaties door LLM-antwoorden te baseren op opgehaalde feitelijke documenten. In plaats van uitsluitend op trainingsdata te vertrouwen, haalt het systeem relevante bronnen op voordat het antwoord wordt gegenereerd, waardoor het model concrete bewijzen krijgt om naar te verwijzen. Deze aanpak zorgt ervoor dat antwoorden gebaseerd zijn op werkelijke informatie in plaats van alleen aangeleerde patronen, wat de feitelijke nauwkeurigheid aanzienlijk verbetert en foutieve of misleidende beweringen vermindert.
Wat zijn vector-embeddings en waarom zijn ze belangrijk in RAG?
Vector-embeddings zijn numerieke representaties van tekst die semantische betekenis vastleggen in een multidimensionale ruimte. Ze stellen RAG-systemen in staat om semantisch te zoeken en documenten te vinden met een vergelijkbare betekenis, zelfs als ze andere woorden gebruiken. Embeddings zijn cruciaal omdat ze RAG in staat stellen verder te gaan dan alleen trefwoordmatching en conceptuele relaties te begrijpen, wat de relevantie van het ophalen verbetert en nauwkeurigere antwoordgeneratie mogelijk maakt.
Kunnen RAG-pijplijnen werken met realtime data?
Ja, RAG-pijplijnen kunnen realtime data verwerken via continue aanvoer- en indexeringsprocessen. Organisaties kunnen geautomatiseerde pijplijnen opzetten die de vectordatabase regelmatig bijwerken met nieuwe documenten, zodat de kennisbank actueel blijft. Deze mogelijkheid maakt RAG ideaal voor toepassingen die up-to-date informatie vereisen, zoals nieuwsanalyses, prijsinformatie en marktbewaking, zonder dat het onderliggende LLM-model opnieuw getraind hoeft te worden.
Wat is het verschil tussen semantisch zoeken en RAG?
Semantisch zoeken is een ophaaltechniek die documenten vindt op basis van betekenisovereenkomst met behulp van vector-embeddings. RAG is een volledige pijplijn die semantisch zoeken combineert met LLM-generatie om antwoorden te produceren die zijn gebaseerd op opgehaalde documenten. Waar semantisch zoeken zich richt op het vinden van relevante informatie, voegt RAG het generatieonderdeel toe dat opgehaalde content syntheseert tot samenhangende antwoorden met bronvermelding.
Hoe bepalen RAG-systemen welke bronnen ze citeren?
RAG-systemen gebruiken meerdere mechanismen om bronnen voor citatie te selecteren. Ze maken gebruik van ophaalalgoritmen om relevante documenten te vinden, herordemodellen om de meest relevante resultaten te prioriteren, en verificatieprocessen om te waarborgen dat citaties de gemaakte beweringen daadwerkelijk ondersteunen. Sommige systemen gebruiken 'cite-while-writing'-methoden waarbij alleen beweringen worden gedaan die worden ondersteund door opgehaalde bronnen, terwijl andere citaties achteraf controleren en niet-ondersteunde beweringen verwijderen.
Wat zijn de belangrijkste uitdagingen bij het bouwen van RAG-pijplijnen?
Belangrijke uitdagingen zijn het up-to-date en kwalitatief houden van de kennisbank, het optimaliseren van ophaalnauwkeurigheid over diverse contenttypes, het beheren van rekenkosten op schaal, het omgaan met domeinspecifieke terminologie die embeddingmodellen mogelijk niet goed begrijpen, en het evalueren van systeemprestaties met uitgebreide meetmethoden. Organisaties moeten ook rekening houden met contextvensterbeperkingen van LLM's en zorgen dat opgehaalde documenten relevant blijven naarmate informatie evolueert.
Hoe monitort AmICited RAG-citaties in AI-systemen?
AmICited volgt hoe AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews content ophalen en citeren via RAG-pijplijnen. Het platform monitort welke bronnen worden gekozen voor citatie, hoe vaak uw merk voorkomt in AI-antwoorden en of de citaties correct zijn. Dit inzicht helpt organisaties hun aanwezigheid in AI-gestuurde zoekopdrachten te begrijpen en zorgt voor juiste toeschrijving van hun content.
Monitor uw merk in AI-antwoorden
Volg hoe AI-systemen zoals ChatGPT, Perplexity en Google AI Overviews uw content vermelden. Krijg inzicht in RAG-citaties en AI-antwoordsmonitoring.
Wat is RAG in AI-zoekopdrachten: Complete gids voor Retrieval-Augmented Generation
Leer wat RAG (Retrieval-Augmented Generation) is in AI-zoekopdrachten. Ontdek hoe RAG de nauwkeurigheid verbetert, hallucinaties vermindert en ChatGPT, Perplexi...
Hoe Retrieval-Augmented Generation Werkt: Architectuur en Proces
Ontdek hoe RAG LLM's combineert met externe databronnen om nauwkeurige AI-antwoorden te genereren. Begrijp het proces in vijf fasen, de componenten en waarom he...
Ontdek wat Retrieval-Augmented Generation (RAG) is, hoe het werkt en waarom het essentieel is voor nauwkeurige AI-antwoorden. Verken RAG-architectuur, voordelen...
11 min lezen
Cookie Toestemming We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.