Akademisk forskning på GEO: Viktige studier og funn
Utforsk banebrytende akademisk forskning på Generative Engine Optimization (GEO), inkludert Aggarwal et al. KDD-studien, GEO-bench-benchmark og praktiske implikasjoner for synlighet i AI-søk.
Publisert den Jan 3, 2026.Sist endret den Jan 3, 2026 kl. 3:24 am
Fremveksten av generative AI-drevne søkemotorer har fundamentalt endret det digitale markedsføringslandskapet, og ført til at akademiske forskere utvikler nye rammeverk for å forstå og optimalisere innholdssynlighet i dette nye paradigmet. Generative Engine Optimization (GEO) oppstod som en formell akademisk disiplin i 2024 med publiseringen av den banebrytende artikkelen “GEO: Generative Engine Optimization” av Pranjal Aggarwal, Vishvak Murahari og kolleger fra Princeton University og Indian Institute of Technology Delhi, presentert på den prestisjetunge KDD-konferansen (Knowledge Discovery and Data Mining). Denne grunnleggende forskningen definerte formelt GEO som et black-box-optimaliseringsrammeverk designet for å hjelpe innholdsskapere med å øke synligheten i AI-genererte søkesvar, og adresserte et kritisk hull etterlatt av tradisjonell SEO-metodikk. I motsetning til tradisjonell søkemotoroptimalisering, som fokuserer på nøkkelordrangeringer og klikkrater på søkeresultatsider (SERPs), anerkjenner GEO at generative motorer syntetiserer informasjon fra flere kilder til sammenhengende, kildebelagte svar, noe som fundamentalt endrer hvordan synlighet oppnås og måles. Det akademiske miljøet innså at tradisjonelle SEO-teknikker—nøkkelordoptimalisering, lenkebygging og teknisk SEO—selv om de fortsatt er grunnleggende, ikke er tilstrekkelige for suksess i et AI-drevet søkemiljø hvor innhold må være oppdagbart, siterbart og troverdig nok til å inkluderes i syntetiserte svar.
Viktige funn fra Aggarwal et al.-studien
Aggarwal et al.-forskningen introduserte et omfattende sett med synlighetsmålinger spesielt utviklet for generative motorer, og gikk utover tradisjonelle rangeringsbaserte målinger for å fange det nyanserte ved AI-genererte svar. Studien identifiserte to hovedinntrykk-målinger: Posisjonsjustert ordtelling, som måler normalisert antall ord i setninger som siterer en kilde og tar hensyn til siteringsposisjonen i svaret, og Subjektivt inntrykk, som vurderer syv dimensjoner inkludert relevans, innflytelse, unikhet og sannsynlighet for brukerengasjement. Gjennom grundig evaluering på sin nylig opprettede GEO-bench-benchmark testet forskerne ni distinkte optimaliseringsmetoder og viste at de mest effektive strategiene kunne øke kilde-synlighet med opptil 40 % på posisjonsjustert ordtelling og 28 % på subjektive inntrykk. Forskningen viste at metoder som vektlegger troverdighet og bevis—spesielt Sitat-tillegg (41 % forbedring), Statistikk-tillegg (38 % forbedring) og Kildehenvisning (35 % forbedring)—utkonkurrerte tradisjonelle SEO-taktikker som nøkkelordstuffing, som faktisk reduserte synligheten. Viktig nok fant studien at GEO-effektivitet varierer betydelig mellom domener, med noen metoder som er mer effektive for bestemte spørsmålstyper og innholdskategorier, noe som understreker behovet for domenespesifikke optimaliseringsstrategier fremfor én universell tilnærming.
GEO-Bench-benchmarken: Standardisering av evaluering
For å muliggjøre grundig akademisk evaluering av GEO-metoder, introduserte forskerteamet GEO-bench, den første storskala benchmarken spesielt utviklet for generative motorer, bestående av 10 000 ulike søkespørsmål nøye valgt fra ni ulike datakilder og tagget på tvers av syv distinkte kategorier. Denne omfattende benchmarken adresserer et kritisk hull i forskningslandskapet, da ingen standardisert evalueringsramme fantes for å teste optimaliseringsstrategier mot generative motorer før dette arbeidet. Benchmarket inkluderer spørsmål fra flere domener og representerer ulike brukerintensjoner—80 % informative, 10 % transaksjonelle og 10 % navigasjonsbaserte—og reflekterer virkelige søkemønstre. Hvert spørsmål i GEO-bench utvides med renset tekstinnhold fra de fem øverste Google-søkeresultatene, noe som gir relevante kilder for svargenerering og sikrer at evalueringen reflekterer realistiske informasjonsinnhentingsscenarier.
De ni datasett som inngår i GEO-bench er:
MS Macro, ORCAS-I og Natural Questions – Ekte, anonymiserte brukerspørsmål fra Bing og Google
AllSouls – Essay-spørsmål fra Oxford University som krever multisource-resonnement
LIMA – Utfordrende spørsmål som krever syntese og resonnement
Davinci-Debate – Debattspørsmål for testing av generative motorer
Perplexity.ai Discover – Trendende spørsmål fra en lansert generativ motorplattform
ELI5 – Komplekse spørsmål som forventer enkle, folkelige svar
GPT-4-genererte spørsmål – Syntetisk genererte spørsmål på tvers av ulike domener og vanskelighetsgrader
Sammenlignende analyse: AI-søk vs. tradisjonelt søk
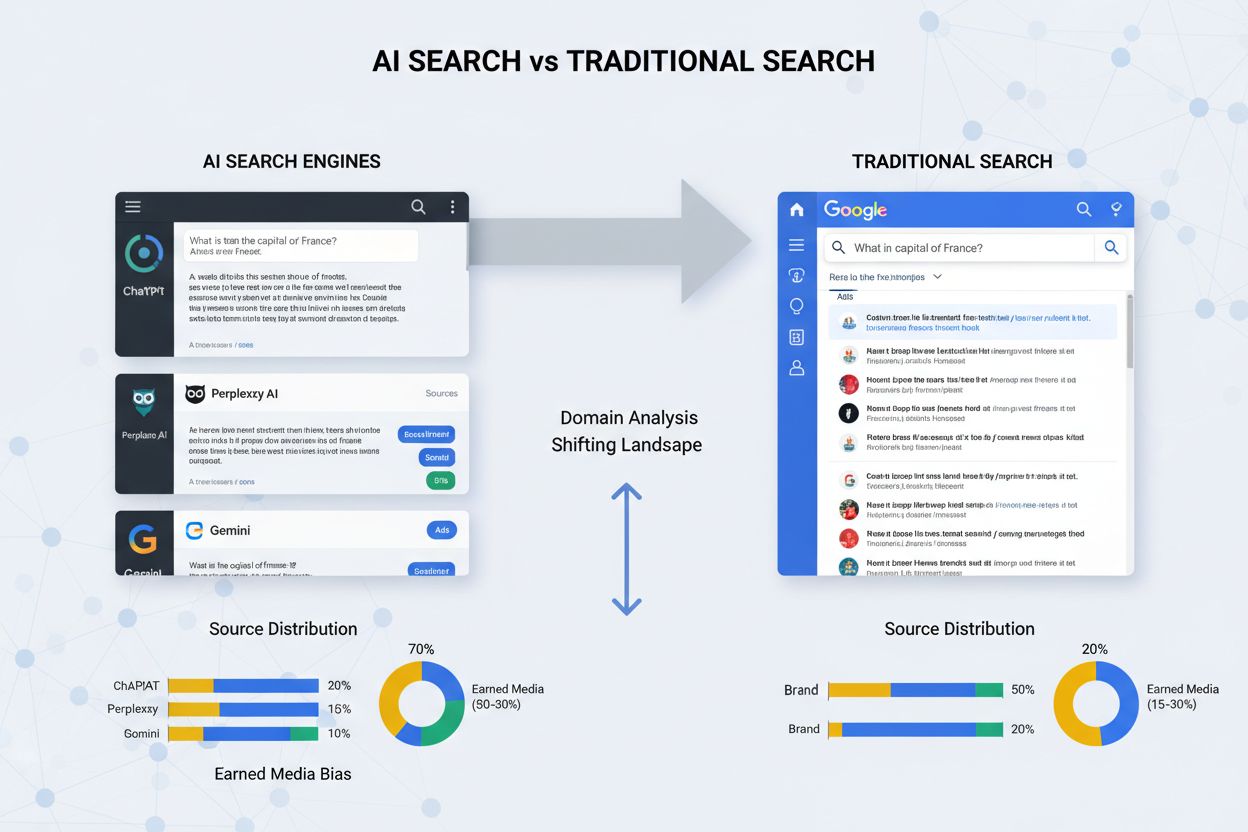
Utover GEO-spesifikk optimalisering har akademisk forskning avdekket grunnleggende forskjeller i hvordan AI-søkemotorer henter informasjon sammenliknet med tradisjonelle søkemotorer som Google. En omfattende sammenlignende studie av Chen et al., som analyserte ChatGPT, Perplexity, Gemini og Claude mot Google på tvers av flere vertikaler, avdekket en systematisk og overveldende slagside mot fortjent omtale i AI-motorer, der slike kilder utgjorde 60–95 % av siteringene avhengig av motor og spørsmålstype. Dette står i sterk kontrast til Googles mer balanserte tilnærming, hvor merkevare (25–40 %) og sosiale (10–20 %) kilder utgjør en betydelig del sammen med fortjente kilder. Forskningen viste at domeneoverlapp mellom AI-motorer og Google er bemerkelsesverdig lav, fra bare 15–50 % avhengig av vertikal, noe som indikerer at AI-systemer i stor grad syntetiserer svar fra andre informasjons-økosystemer enn tradisjonelle søkemotorer. Merk at AI-motorer nesten fullstendig ekskluderer sosiale plattformer som Reddit og Quora fra sine svar, mens Google ofte inkluderer brukergenerert innhold og diskusjoner. Dette funnet har store implikasjoner for innholdsstrategi, siden synlighet på Google ikke automatisk gir synlighet i AI-genererte svar, og krever ulike optimaliseringstilnærminger for hvert søkeparadigme.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Domenespesifikke GEO-optimaliseringsstrategier
Akademisk forskning har entydig vist at GEO-effektivitet ikke er lik på tvers av domener, og at innholdsskapere må tilpasse sine optimaliseringsstrategier etter sin bransje og spørsmålstyper. Aggarwal et al.-studien identifiserte tydelige mønstre i hvilke optimaliseringsmetoder som fungerer best for ulike innholdskategorier: Sitat-tillegg er mest effektivt for Mennesker & Samfunn, Forklaring og Historie, der fortelling og direkte sitater gir autentisitet; Statistikk-tillegg dominerer i Jus & Myndigheter, Debatt og Mening, der datadrevne bevis styrker argumentasjonen; og Kildehenvisning utmerker seg i Fakta, Påstander og Jus & Myndigheter, der troverdighetsverifisering er avgjørende. Forskning viser også at informative spørsmål (utforskende, kunnskapssøkende) reagerer annerledes på optimalisering enn transaksjonelle spørsmål (kjøpsintensjon), der informative innhold vinner på bred dekning og autoritetssignaler, mens transaksjonelt innhold krever tydelig produktinformasjon, priser og sammenligningsdata. Metodenes effektivitet varierer også etter om innholdet retter seg mot kjente merkevarer eller nisjeaktører, der nisjebrands må satse mer aggressivt på fortjent omtale og autoritetsbygging for å overvinne den innebygde “big brand bias” i AI-motorer. Denne domenespesifikke variasjonen understreker at vellykket GEO krever dyp forståelse av vertikalens informasjonsøkosystem og brukerintensjoner, i stedet for å anvende generiske optimaliseringstaktikker på alt innhold.
Språksensitivitet og flerspråklig GEO
Akademisk forskning på språksensitivitet viser at ulike AI-motorer håndterer flerspråklige spørsmål med dramatisk ulike tilnærminger, og at merkevarer som satser på global synlighet må utvikle språkspesifikke strategier, ikke bare oversette innhold. Chen et al.-studien fant at Claude har en bemerkelsesverdig høy tverrspråklig domenestabilitet, og gjenbruker de samme autoritative engelske kildene på kinesiske, japanske, tyske, franske og spanske spørsmål, noe som tilsier at autoritet i engelske topp-publikasjoner kan gi synlighet på tvers av språk i Claude-baserte systemer. I sterk kontrast viser GPT nærmest null tverrspråklig domenoverlapp, og bytter ut hele kildeøkosystemet ved spørsmål på andre språk, slik at synlighet på engelske spørsmål ikke gir noen fordel på ikke-engelske søk og krever separat autoritetsbygging i lokale medier. Perplexity og Gemini befinner seg mellom ytterpunktene, med noe gjenbruk av autoritetsdomener, men også betydelig lokaltilpasning mot målspråkkilder. Forskningen viser også at nettstedets språkutvalg varierer etter motor, der GPT og Perplexity sterkt favoriserer målspråklig innhold på ikke-engelske spørsmål, mens Claude fortsatt lener mot engelsk. Disse funnene har kritiske implikasjoner for multinasjonale merkevarer: Suksess i ikke-engelske markeder krever ikke bare oversettelse, men aktiv bygging av fortjent omtale og autoritetssignaler i hvert språks informasjonsøkosystem, med strategi avhengig av hvilke AI-motorer som er viktigst for virksomheten.
Autoritet og E-E-A-T-faktor i GEO
Forskning på GEO understreker konsekvent at autoritet og E-E-A-T (Erfaring, Ekspertise, Autoritet, Troværdighet) er grunnleggende for synlighet i AI-søk, der AI-motorer har en systematisk preferanse for kilder som oppfattes som autoritative og troverdige. Den overveldende slagsiden mot fortjent omtale dokumentert i flere studier reflekterer AI-motorenes avhengighet av tredjepartsvalidering som autoritetssignal—innhold som er uavhengig vurdert, sitert og omtalt av anerkjente publikasjoner signaliserer for AI-systemer at kilden er troverdig og fortjener å inkluderes i syntetiserte svar. Forskning viser at tilbakekoblinger fra autoritative domener fungerer som kritiske autoritetssignaler for AI-motorer, likt som i tradisjonell SEO, men med enda større betydning, ettersom AI-systemer bruker lenkeprofiler til å vurdere om en kilde skal stoles på som sitering. Studiene viser at forfatterens kvalifikasjoner, institusjonstilhørighet og dokumentert ekspertise i stor grad påvirker AI-motorens vilje til å sitere en kilde, og det er derfor avgjørende at innholdsskapere tydelig etablerer sine kvalifikasjoner og kunnskap. Viktig nok viser forskningen at E-E-A-T-signaler må fortjenes, ikke bare hevdes—å erklære ekspertise på eget nettsted har liten effekt sammenlignet med å få ekspertisen bekreftet via tredjepartsomtale, ekspertuttalelser og siteringer fra autoritative kilder. Dette flytter optimaliseringsfokuset fra on-page-signaler til off-page autoritetsbygging, og gjør fortjent omtale og strategiske partnerskap til sentrale GEO-komponenter.
Praktiske anvendelser: Fra forskning til implementering
Akademisk GEO-forskning omsettes i flere konkrete strategier for innholdsskapere som ønsker bedre synlighet i AI-genererte svar. For det første må innhold struktureres for maskinlesbarhet med schema markup og tydelig hierarkisk organisering, slik at AI-motorene lett kan tolke og hente ut informasjon; dette innebærer detaljert bruk av schema.org-markup for produkter, artikler, anmeldelser og andre entiteter, klare overskriftsnivåer og informasjon i skannbare formater som tabeller og punktlister. For det andre bør innhold konstrueres for begrunnelse, altså eksplisitt svare på sammenligningsspørsmål og gi tydelige grunner for hvorfor en kilde er best—dette krever detaljerte sammenligningstabeller mot konkurrenter, punktlister med fordeler og ulemper og tydelige verdiforslag som AI-systemer lett kan trekke ut som begrunnende attributter. For det tredje må bygging av fortjent omtale bli en kjerneprioritet, slik at ressurser flyttes fra eget innhold mot PR, medieinnsalg og ekspert-samarbeid for å sikre omtale og siteringer i autoritative publikasjoner som AI-motorer foretrekker. For det fjerde må synlighetsmålinger utvikles utover tradisjonelle KPI-er, med sporing av AI-siteringer, omtale i AI-genererte svar og synlighet på tvers av flere generative motorer, i stedet for bare klikkrater og rangeringer. Til slutt bør domenespesifikke optimaliseringsstrategier erstatte universelle tilnærminger, der innholdsskapere undersøker hvilke GEO-metoder som fungerer best for sin vertikal og tilpasser optimaliseringen etter akademiske funn om domenespesifikk effekt.
Begrensninger og fremtidige forskningsretninger
Selv om akademisk GEO-forskning gir verdifulle innsikter, anerkjenner forskerne viktige begrensninger som bør informere hvordan funnene brukes. Forskningens tidsavhengighet betyr at funnene reflekterer AI-motorenes atferd på et bestemt tidspunkt; etter hvert som systemene utvikler seg, algoritmer endres og konkurransen forandres, kan de kvantitative resultatene bli utdaterte og krever jevnlig revurdering og kontinuerlig overvåking av GEO-effekt. Black-box-naturen til AI-motorene gir en grunnleggende forskningsutfordring, da akademikere ikke får tilgang til interne rangeringsmodeller, treningsdata eller algoritmedetaljer—de kan derfor beskrive hva som skjer (hvilke kilder blir sitert), men de definitive mekanismene bak valgene blir antatt snarere enn bevist. Klassifiseringssystemene i forskningen (Merkevare, Fortjent, Sosialt) er konstruerte rammeverk som, selv om de er logiske, innebærer subjektive vurderinger om domenekategoriseringer som kunne gitt ulike resultater med andre klassifiseringer. I tillegg har forskningen primært fokusert på engelskspråklige spørsmål og vestlige markeder, med begrenset innsikt i hvordan GEO-prinsipper fungerer i ikke-engelske kontekster eller fremvoksende markeder med andre informasjonsøkosystemer. Foreslåtte fremtidige forskningsretninger inkluderer utvikling av mer sofistikerte synlighetsmålinger for å fange nyanserte aspekter av AI-siteringer, undersøkelser av hvordan GEO-strategier samspiller med nye AI-funksjoner som multimodalt søk og konversasjonelle agenter, og longitudinelle studier av hvordan GEO-effektivitet utvikler seg etter hvert som AI-motorer modnes og brukeradferd endres.
Fremtiden for GEO-forskning og utvikling av AI-søk
Etter hvert som generativ AI fortsetter å omforme informasjonsinnhenting, utvides akademisk forskning på GEO for å møte nye utfordringer og muligheter i dette raskt utviklende landskapet. Multimodalt søk—der AI-motorer syntetiserer informasjon fra tekst, bilder, video og andre medietyper—representerer et nytt forskningsfelt for GEO og krever nye optimaliseringsstrategier utover tekstbasert innhold. Konversasjonelle og agentbaserte AI-systemer som kan utføre handlinger på vegne av brukeren (kjøp, bookinger, transaksjoner) vil kreve nye GEO-tilnærminger rettet mot å gjøre innhold handlingsegnet og maskinutførbart, ikke bare siterbart. Det akademiske miljøet ser i økende grad behovet for prinsippbaserte GEO-metodologier og forvaltede tjenester som går utover enkelttiltak og gir helhetlige, kontinuerlige optimaliseringsstrategier på tvers av flere AI-motorer. Forskning undersøker også hvordan GEO-strategier bør tilpasses etter hvert som AI-motorer modnes og konsolideres, med tidlige funn som antyder at optimaliseringen kan bli mer standardisert etter hvert som markedet domineres av færre plattformer, men fortsatt skille seg fra tradisjonell SEO. Til slutt gransker forskere bredere implikasjoner av GEO for skaperøkonomien og digital publisering, og ser på hvordan overgangen til AI-syntetiserte svar påvirker trafikkfordeling, inntektsmodeller og levedyktigheten til små aktører og innholdsskapere i et AI-dominert søkelandskap. Disse nye forskningsretningene tyder på at GEO vil fortsette å utvikle seg som fagfelt, med akademisk forskning som en nøkkel for å hjelpe innholdsskapere, merkevarer og utgivere å navigere det grunnleggende skiftet i hvordan informasjon oppdages og konsumeres i generativ AI-æraen.
Vanlige spørsmål
Hva er GEO og hvordan skiller det seg fra tradisjonell SEO?
Generative Engine Optimization (GEO) er et rammeverk for å optimalisere innholdssynlighet i AI-genererte søkesvar, i stedet for tradisjonelle rangerte søkeresultater. I motsetning til SEO som fokuserer på nøkkelordrangeringer og klikkrater, vektlegger GEO å bli sitert som kilde i syntetiserte AI-svar, noe som krever andre strategier rundt autoritet, innholdsstruktur og fortjent omtale.
Hva var Aggarwal et al.-studien og hvorfor er den viktig?
KDD-artikkelen fra 2024 av Aggarwal et al. fra Princeton University og IIT Delhi introduserte det første omfattende rammeverket for GEO, inkludert synlighetsmålinger, optimaliseringsmetoder og GEO-bench-benchmarken. Denne banebrytende studien viste at innholdssynlighet i generative motorer kan forbedres med opptil 40 % gjennom målrettede optimaliseringsstrategier, og etablerte GEO som et legitimt akademisk felt.
Hva er GEO-bench og hvordan brukes det?
GEO-bench er den første storskala benchmarken for å evaluere generative engine optimization, bestående av 10 000 ulike søkespørsmål på tvers av 25 domener. Det gir et standardisert evalueringsrammeverk for å teste GEO-metoder og sammenligne deres effekt på tvers av ulike spørsmålstyper, domener og AI-motorer, og muliggjør grundig akademisk forskning og praktiske optimaliseringsstrategier.
Hvilke GEO-metoder er mest effektive ifølge forskning?
Akademisk forskning viser at de mest effektive GEO-metodene er Sitat-tillegg (41 % forbedring), Statistikk-tillegg (38 % forbedring) og Kildehenvisning (35 % forbedring). Disse metodene fungerer ved å legge til troverdige kilder, relevante statistikker og sitater fra autoritative kilder, som AI-motorer sterkt foretrekker når de lager svar.
Hvordan skiller AI-søkemotorer seg fra Google i kildevalg?
Forskning viser at AI-søkemotorer som ChatGPT og Claude har en sterk slagside mot fortjent omtale (60–95 %), mens Google har en mer balansert miks av merkevare-, fortjent- og sosiale kilder. AI-motorer nedprioriterer konsekvent brukergenerert innhold og sosiale plattformer, og foretrekker i stedet tredjepartsanmeldelser, redaksjonelle medier og autoritative publikasjoner.
Hvilken rolle spiller autoritet og E-E-A-T i GEO?
Autoritet og E-E-A-T (Erfaring, Ekspertise, Autoritet, Troværdighet) er grunnleggende for GEO-suksess. Akademisk forskning viser at AI-motorer prioriterer innhold fra kilder som oppfattes som autoritative, noe som gjør fortjent omtale, lenker fra anerkjente domener og dokumentert ekspertise til avgjørende faktorer for å oppnå synlighet i AI-genererte svar.
Hvordan påvirker språk GEO-strategier på tvers av ulike AI-motorer?
Forskning viser at forskjellige AI-motorer håndterer flerspråklige søk ulikt. Claude opprettholder høy tverrspråklig stabilitet og gjenbruker engelskspråklige autoritetsdomener, mens GPT sterkt lokaliserer og henter fra målspråkets økosystemer. Dette krever at merkevarer utvikler språkspesifikke autoritetsstrategier i stedet for bare enkel oversettelse.
Hva er de praktiske implikasjonene av GEO-forskning for innholdsskapere?
Akademisk GEO-forskning indikerer at innholdsskapere bør fokusere på å bygge fortjent omtale, strukturere innhold for maskinlesbarhet med schema markup, lage innhold rikt på begrunnelser med tydelige sammenligninger og verdiargumenter, og spore nye målinger som AI-siteringer og synlighet i stedet for tradisjonelle klikkrater.
Overvåk merkevarens synlighet i AI-søk
Følg med på hvordan innholdet ditt vises i AI-genererte svar hos ChatGPT, Perplexity, Google AI Overviews og andre generative motorer. Få sanntidsinnsikt i din GEO-ytelse.
Hvorfor GEO er avgjørende for forretningssuksess i 2025: Guide til synlighet i AI-søk
Oppdag hvorfor Generative Engine Optimization (GEO) er essensielt for bedrifter i 2025. Lær hvordan AI-drevne søk former merkevaresynlighet, forbrukeratferd, og...
Lær hva Generative Engine Optimization (GEO) er og hvordan du kan optimalisere merkevaren din for synlighet i AI-søkemotorer som ChatGPT, Perplexity og Gemini. ...
Hva er GEO? Den komplette guiden til Generative Engine Optimization
Lær det grunnleggende om Generative Engine Optimization (GEO). Oppdag hvordan du får merkevaren din sitert i ChatGPT, Perplexity og Google AI Overviews med velp...
15 min lesing
Informasjonskapselsamtykke Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.