
Bør du blokkere eller tillate AI-crawlere? Beslutningsrammeverk
Lær hvordan du tar strategiske beslutninger om blokkering av AI-crawlere. Vurder innholdstype, trafikkilder, inntektsmodeller og konkurranseposisjon med vårt om...
11 min lesing

Lær hvordan AI-crawlere påvirker serverressurser, båndbredde og ytelse. Oppdag reelle statistikker, avbøtende strategier og infrastrukturløsninger for effektiv håndtering av bot-belastning.
AI-crawlere har blitt en betydelig drivkraft for nett-trafikk, med store AI-selskaper som bruker avanserte roboter for å indeksere innhold til trenings- og gjenfinningsformål. Disse crawlerne opererer i enorm skala, og genererer omtrent 569 millioner forespørsler per måned på tvers av nettet og forbruker over 30 TB båndbredde globalt. De viktigste AI-crawlerne inkluderer GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google) og Amazonbot (Amazon), hver med unike gjennomsøkingsmønstre og ressursbehov. Å forstå atferden og egenskapene til disse crawlerne er avgjørende for at nettstedsadministratorer skal kunne håndtere serverressurser riktig og ta informerte beslutninger om tilgangspolitikk.
| Crawler-navn | Selskap | Formål | Forespørselmønster |
|---|---|---|---|
| GPTBot | OpenAI | Treningsdata for ChatGPT og GPT-modeller | Aggressive, høyfrekvente forespørsler |
| ClaudeBot | Anthropic | Treningsdata for Claude AI-modeller | Moderat frekvens, respektfull gjennomsøking |
| PerplexityBot | Perplexity AI | Sanntidssøk og svar-generering | Moderat til høy frekvens |
| Google-Extended | Utvidet indeksering for AI-funksjoner | Kontrollert, følger robots.txt | |
| Amazonbot | Amazon | Produkt- og innholdsindeksering | Variabel, fokus på handel |
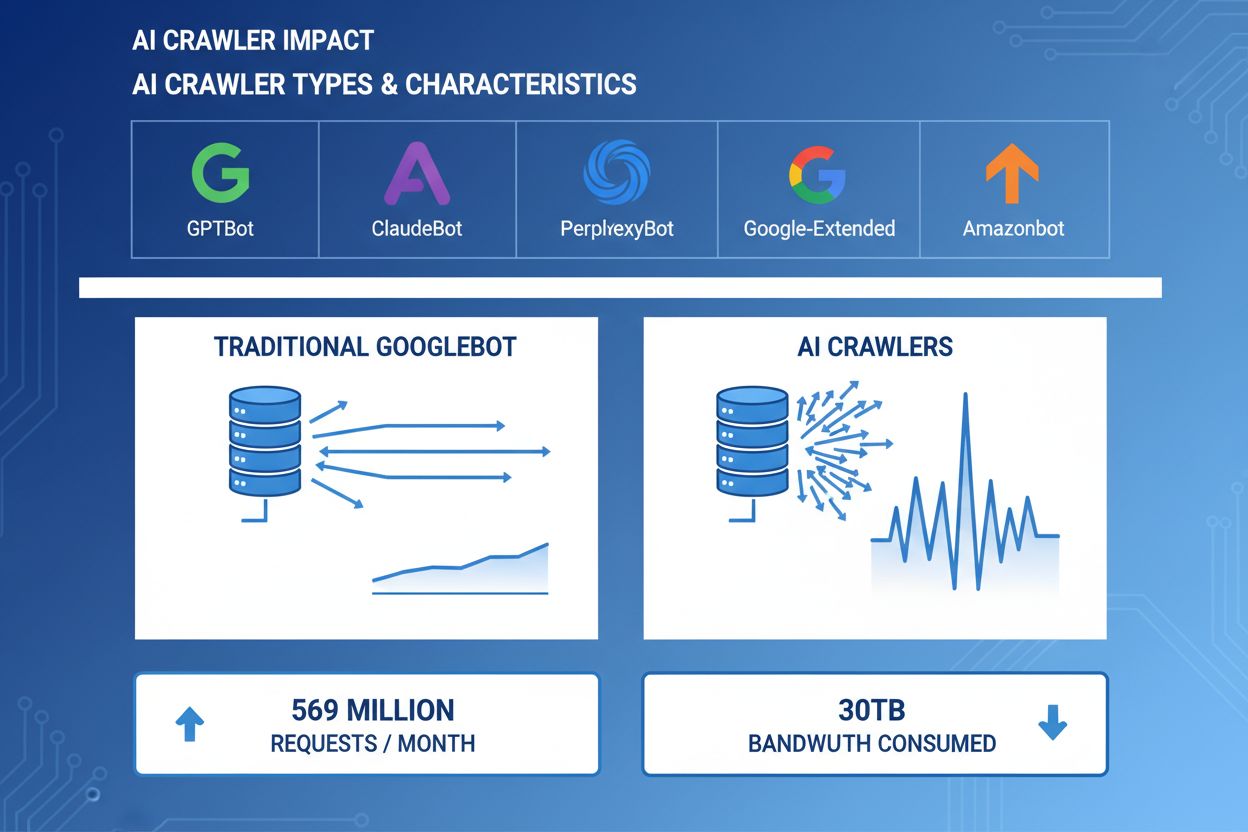
AI-crawlere forbruker serverressurser på flere områder, noe som gir målbare utslag på infrastrukturens ytelse. CPU-bruken kan øke med 300 % eller mer under perioder med høy crawleraktivitet, ettersom servere må håndtere tusenvis av samtidige forespørsler og analysere HTML-innhold. Båndbreddeforbruket er en av de mest synlige kostnadene, og et enkelt populært nettsted kan servere gigabyte med data til crawlere daglig. Minnebruken øker betydelig når servere opprettholder tilkoblingspuljer og buffer store datamengder for behandling. Databaseforespørsler mangedobles når crawlere ber om sider som utløser dynamisk innholdsgenerering og skaper ekstra I/O-belastning. Disk-I/O blir en flaskehals når servere må lese fra lagringsmedier for å betjene crawlerforespørsler, spesielt for nettsteder med store innholdsbiblioteker.
| Ressurs | Innvirkning | Virkelig eksempel |
|---|---|---|
| CPU | 200–300 % topper under høy gjennomsøking | Serverlast øker fra 2,0 til 8,0 |
| Båndbredde | 15–40 % av total månedlig bruk | 500 GB-side serverer 150 GB til crawlere per måned |
| Minne | 20–30 % økning i RAM-bruk | 8 GB-server krever 10 GB under crawleraktivitet |
| Database | 2–5x økning i forespørselsbelastning | Spørringstid øker fra 50 ms til 250 ms |
| Disk I/O | Vedvarende høy leseaktivitet | Diskutnyttelse hopper fra 30 % til 85 % |
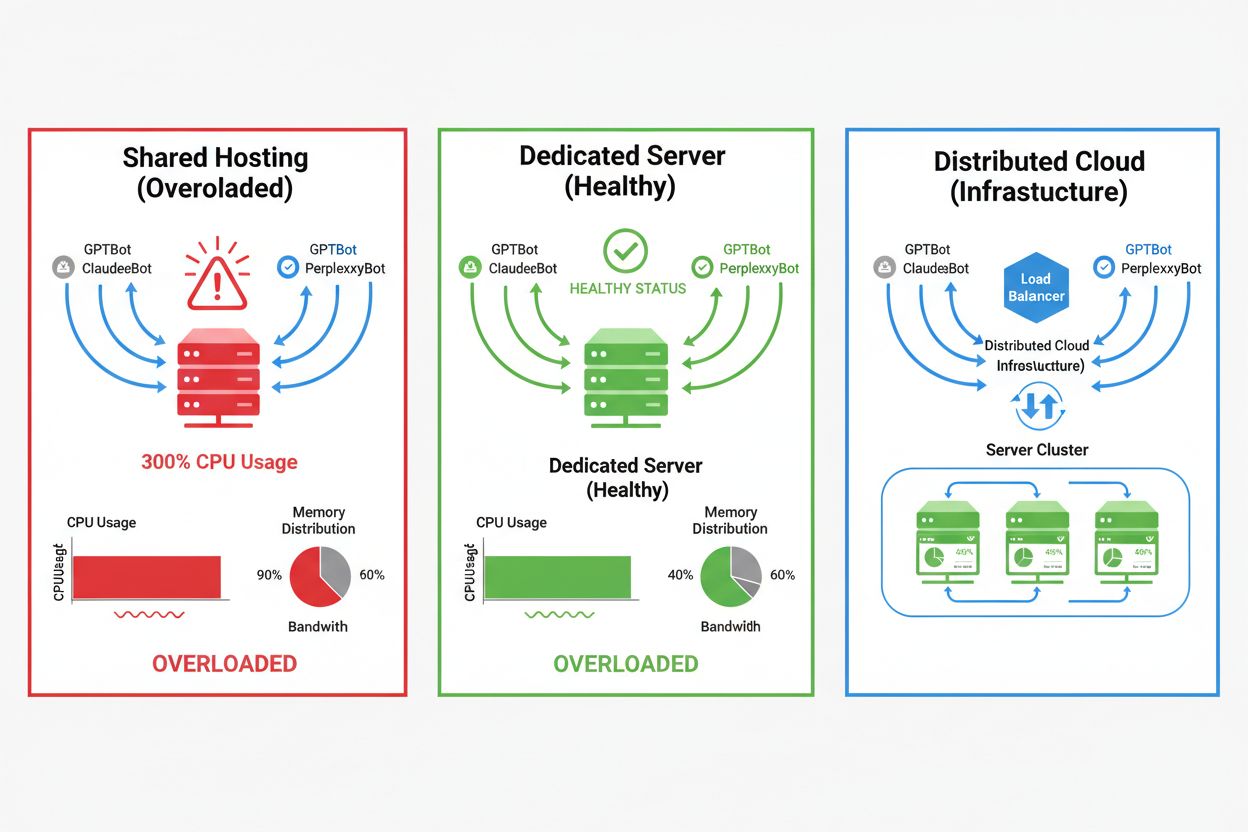
Effekten av AI-crawlere varierer kraftig avhengig av hostingmiljø, hvor delte hostingmiljøer rammes hardest. I delte hosting-scenarier blir “bråkete nabo-syndromet” særlig problematisk—når ett nettsted på en delt server tiltrekker mye crawlertrafikk, forbruker det ressurser som ellers ville vært tilgjengelig for andre hostede nettsteder, og svekker ytelsen for alle. Dedikerte servere og skytjenester gir bedre isolasjon og ressursgaranti, slik at du kan absorbere crawlertrafikk uten å påvirke andre tjenester. Men også dedikert infrastruktur krever nøye overvåking og skalering for å håndtere samlet belastning fra flere AI-crawlere.
Viktige forskjeller mellom hostingmiljøer:
Den økonomiske effekten av AI-crawlertrafikk går utover rene båndbreddekostnader og omfatter både direkte og skjulte utgifter som kan ha stor innvirkning på bunnlinjen. Direkte kostnader inkluderer økte båndbreddeavgifter fra hostingleverandøren din, noe som kan legge til hundrevis eller tusenvis av kroner i måneden avhengig av trafikkvolum og crawlerintensitet. Skjulte kostnader oppstår gjennom økte infrastrukturkrav—du må kanskje oppgradere til høyere hostingplaner, legge til ekstra cachelag eller investere i CDN-tjenester bare for å håndtere crawlertrafikk. Avkastningsberegningen blir komplisert når man tar i betraktning at AI-crawlere gir minimal direkte verdi til virksomheten din, samtidig som de bruker ressurser som kunne tjene betalende kunder eller forbedret brukeropplevelsen. Mange nettstedeiere opplever at kostnadene ved å imøtekomme crawlertrafikk overgår eventuelle fordeler fra AI-modelltrening eller synlighet i AI-drevne søkeresultater.
AI-crawlertrafikk degraderer direkte brukeropplevelsen for reelle besøkende ved å bruke serverressurser som ellers ville ha gjort at menneskelige brukere fikk raskere opplevelse. Core Web Vitals-metrikker svekkes målbart, med Largest Contentful Paint (LCP) som øker med 200–500 ms og Time to First Byte (TTFB) som forringes med 100–300 ms under perioder med mye crawleraktivitet. Disse ytelsesforringelsene utløser negative følgeeffekter: tregere sider gir lavere brukerengasjement, høyere fluktfrekvens og til slutt lavere konvertering for nettbutikker og leadgenerering. Søkemotorrangeringen svekkes også, siden Googles rangeringsalgoritme bruker Core Web Vitals som rangeringsfaktor, og skaper en ond sirkel hvor crawlertrafikk indirekte skader SEO-ytelsen din. Brukere som opplever treg innlasting, forlater oftere nettstedet og besøker konkurrenter, noe som påvirker inntekter og merkevareopplevelse direkte.
Effektiv håndtering av AI-crawlertrafikk starter med omfattende overvåking og deteksjon, slik at du kan forstå problemets omfang før du implementerer løsninger. De fleste webservere logger user-agent-strenger som identifiserer hvilken crawler som gjør hver forespørsel, og gir grunnlaget for trafikk-analyse og filtreringsbeslutninger. Serverlogger, analyseplattformer og spesialiserte overvåkingsverktøy kan tolke disse user-agent-strengene for å oppdage og kvantifisere crawlertrafikk-mønstre.
Viktige deteksjonsmetoder og verktøy:
Førstelinjeforsvaret mot overdreven AI-crawlertrafikk er å implementere en godt konfigurert robots.txt-fil som eksplisitt styrer crawler-tilgang til nettstedet ditt. Denne enkle tekstfilen, plassert i roten av nettstedet ditt, lar deg nekte bestemte crawlere, begrense gjennomsøkingsfrekvens og lede crawlere til et sitemap med kun det innholdet du vil ha indeksert. Rate-limiting på applikasjons- eller servernivå gir et ekstra beskyttelseslag, og begrenser forespørsler fra bestemte IP-adresser eller user-agents for å hindre ressursuttømming. Disse strategiene er ikke-blokkerende og reversible, og er derfor gode utgangspunkt før mer aggressive tiltak vurderes.
# robots.txt - Blokker AI-crawlere, men tillat legitime søkemotorer
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: CCBot
Disallow: /
# Tillat Google og Bing
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Crawl delay for alle andre roboter
User-agent: *
Crawl-delay: 10
Request-rate: 1/10s
Web Application Firewalls (WAF) og Content Delivery Networks (CDN) gir avansert, bedriftsnivå beskyttelse mot uønsket crawlertrafikk gjennom atferdsanalyse og intelligent filtrering. Cloudflare og lignende CDN-leverandører tilbyr innebygde bot-håndteringsfunksjoner som kan identifisere og blokkere AI-crawlere basert på atferdsmønstre, IP-omdømme og forespørselskarakteristika – uten at du trenger å konfigurere manuelt. WAF-regler kan settes opp for å utfordre mistenkelige forespørsler, rate-limite spesifikke user-agents eller blokkere trafikk fra kjente crawler-IP-intervaller helt. Disse løsningene jobber på kanten av nettverket og filtrerer ut uønsket trafikk før den når opprinnelsesserveren din, noe som reduserer belastningen betydelig. Fordelen med WAF- og CDN-løsninger er deres evne til å tilpasse seg nye crawlere og endrende angrepsmønstre uten manuelle oppdateringer.
Å bestemme om AI-crawlere skal blokkeres, krever nøye vurdering av avveiningene mellom å beskytte serverressurser og å opprettholde synlighet i AI-drevne søkeresultater og applikasjoner. Å blokkere alle AI-crawlere eliminerer muligheten for at innholdet ditt dukker opp i ChatGPT-søk, Perplexity AI-svar eller andre AI-drevne oppdagelsesmekanismer, noe som kan redusere henvisningstrafikk og merkevaresynlighet. På den annen side vil ubegrenset crawlertilgang forbruke betydelige ressurser og kan forringe brukeropplevelsen uten å gi målbar verdi for virksomheten. Den optimale strategien avhenger av situasjonen din: nettsteder med mye trafikk og rikelige ressurser kan velge å tillate crawlere, mens ressursbegrensede sider bør prioritere brukeropplevelse ved å blokkere eller rate-limite crawlertilgang. Strategiske beslutninger bør ta hensyn til bransje, målgruppe, innholdstype og forretningsmål — ikke velge en løsning som passer alle.
For nettsteder som velger å imøtekomme AI-crawlertrafikk, gir infrastrukturskalering en vei til å opprettholde ytelsen under økt belastning. Vertikal skalering—oppgradering til servere med mer CPU, RAM og båndbredde—er en enkel, men dyr løsning som til slutt når fysiske grenser. Horisontal skalering—fordele trafikken over flere servere med lastbalansering—gir bedre skalerbarhet og robusthet på sikt. Skyleverandører som AWS, Google Cloud og Azure tilbyr auto-skaleringsfunksjoner som automatisk tildeler ekstra ressurser under trafikk-topper, og skalerer ned i rolige perioder for å minimere kostnadene. Content Delivery Networks (CDN) kan cache statisk innhold nær brukeren, redusere belastningen på opprinnelsesserveren og forbedre ytelsen for både brukere og crawlere. Databaseoptimalisering, cache av spørringer og forbedringer på applikasjonsnivå kan også redusere ressursforbruket per forespørsel og øke effektiviteten uten ekstra infrastruktur.
Kontinuerlig overvåking og optimalisering er avgjørende for å opprettholde optimal ytelse i møte med vedvarende AI-crawlertrafikk. Spesialiserte verktøy gir innsyn i crawleraktivitet, ressursforbruk og ytelsesmetrikker, slik at du kan ta databaserte beslutninger om crawlerhåndtering. Å implementere helhetlig overvåking fra starten gir deg muligheten til å etablere grunnlinjer, identifisere trender og måle effekten av avbøtende tiltak over tid.
Essensielle overvåkingsverktøy og praksiser:
Landskapet for AI-crawlerhåndtering utvikler seg stadig, med nye standarder og bransjeinitiativer som former hvordan nettsteder og AI-selskaper samhandler. llms.txt-standarden representerer en ny tilnærming til å gi AI-selskaper strukturert informasjon om innholdsrettigheter og preferanser, og kan tilby et mer nyansert alternativ til enten full blokkering eller full tilgang. Bransjediskusjoner rundt kompensasjonsmodeller antyder at AI-selskaper etter hvert kan komme til å betale nettsteder for tilgang til treningsdata, noe som fundamentalt vil endre økonomien rundt crawlertrafikk. Å fremtidsrette infrastrukturen din krever at du holder deg oppdatert på nye standarder, følger med på bransjeutviklingen og bevarer fleksibiliteten i crawlerpolitikken din. Å bygge relasjoner til AI-selskaper, delta i bransjediskusjoner og arbeide for rettferdige kompensasjonsmodeller vil bli stadig viktigere etter hvert som AI blir en mer sentral del av nettdistribusjon og innholdsforbruk. De nettstedene som lykkes i dette utviklende landskapet, er de som balanserer innovasjon med pragmatisme—beskytter ressursene sine, men samtidig holder døren åpen for legitime muligheter for synlighet og partnerskap.
AI-crawlere (GPTBot, ClaudeBot) henter innhold for LLM-trening uten nødvendigvis å sende trafikk tilbake. Søkemotorcrawlere (Googlebot) indekserer innhold for søkesynlighet og sender vanligvis henvisningstrafikk. AI-crawlere opererer mer aggressivt med større batch-forespørsler og ignorerer ofte retningslinjer for å spare båndbredde.
Virkelige eksempler viser over 30 TB per måned fra enkeltcrawlere. Forbruket avhenger av nettstedets størrelse, innholdsvolum og crawlerfrekvens. OpenAIs GPTBot alene genererte 569 millioner forespørsler på én måned på Vercels nettverk.
Å blokkere AI-treningscrawlere (GPTBot, ClaudeBot) vil ikke påvirke Google-rangeringen. Men blokkering av AI-søkemotorcrawlere kan redusere synligheten i AI-drevne søkeresultater som Perplexity eller ChatGPT-søk.
Se etter uforklarlige CPU-topper (300 %+), økt båndbreddebruk uten flere menneskelige besøkende, tregere sideinnlasting og uvanlige user-agent-strenger i serverlogger. Core Web Vitals-metrikker kan også forringes betydelig.
For nettsteder med betydelig crawlertrafikk gir dedikert hosting bedre ressursisolasjon, kontroll og forutsigbare kostnader. Delte hostingmiljøer lider av 'bråkete nabo-syndromet' der én nettsides crawlertrafikk påvirker alle hostede sider.
Bruk Google Search Console for Googlebot-data, servertilgangslogger for detaljert trafikk-analyse, CDN-analyse (Cloudflare) og spesialiserte plattformer som AmICited.com for omfattende overvåking og sporing av AI-crawlere.
Ja, gjennom robots.txt-direktiver, WAF-regler og IP-basert filtrering. Du kan tillate fordelaktige crawlere som Googlebot, samtidig som du blokkerer ressurskrevende AI-treningscrawlere ved å bruke spesifikke regler for user-agent.
Sammenlign servermetrikker før og etter at du har implementert crawlerkontroller. Overvåk Core Web Vitals (LCP, TTFB), sideinnlastingstid, CPU-bruk og brukeropplevelsesmetrikker. Verktøy som Google PageSpeed Insights og serverovervåking gir detaljert innsikt.
Få sanntidsinnsikt i hvordan AI-modeller får tilgang til innholdet ditt og påvirker serverressursene dine med AmICiteds spesialiserte overvåkingsplattform.
Lær hvordan du tar strategiske beslutninger om blokkering av AI-crawlere. Vurder innholdstype, trafikkilder, inntektsmodeller og konkurranseposisjon med vårt om...

Lær hvilke AI-crawlere du bør tillate eller blokkere i robots.txt-filen din. Omfattende guide som dekker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med...
Lær hvordan du identifiserer og overvåker AI-crawlere som GPTBot, PerplexityBot og ClaudeBot i serverloggene dine. Oppdag user-agent-strenger, IP-verifiseringsm...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.