
AI-treningsroboter vs. søkeroboter: Forstå forskjellen
Oppdag de avgjørende forskjellene mellom AI-treningsroboter og søkeroboter. Lær hvordan de påvirker synligheten av innholdet ditt, optimaliseringsstrategier og ...
9 min lesing

Forstå hvordan AI-søkeboter som GPTBot og ClaudeBot fungerer, hvordan de skiller seg fra tradisjonelle søkeboter, og hvordan du optimaliserer nettstedet ditt for synlighet i AI-søk.
AI-søkeboter er automatiserte programmer utviklet for å systematisk surfe på internett og samle inn data fra nettsider, spesielt for å trene og forbedre kunstige intelligensmodeller. I motsetning til tradisjonelle søkemotorroboter som Googlebot, som indekserer innhold for søkeresultater, samler AI-søkeboter inn rå nettdata for å mate inn i store språkmodeller (LLM-er) som ChatGPT, Claude og andre AI-systemer. Disse botene opererer kontinuerlig på tvers av millioner av nettsteder, laster ned sider, analyserer innhold og trekker ut informasjon som hjelper AI-plattformer å forstå språk, fakta og varierte skrivestiler. De viktigste aktørene i dette markedet inkluderer GPTBot fra OpenAI, ClaudeBot fra Anthropic, Meta-ExternalAgent fra Meta, Amazonbot fra Amazon og PerplexityBot fra Perplexity.ai, som alle tjener sine respektive AI-plattformers trenings- og driftsbehov. Å forstå hvordan disse søkebotene fungerer har blitt essensielt for nettsideeier og innholdsskapere, ettersom AI-synlighet nå direkte påvirker hvordan merkevaren din vises i AI-drevne søkeresultater og anbefalinger.
Landskapet for web crawling har gjennomgått en dramatisk transformasjon det siste året, der AI-søkeboter har opplevd eksplosiv vekst mens tradisjonelle søkeboter har opprettholdt jevne mønstre. Mellom mai 2024 og mai 2025 økte den totale søkebottrafikken med 18 %, men fordelingen har skiftet betydelig—GPTBot økte med 305 % i antall forespørsler, mens andre søkeboter som ClaudeBot falt med 46 % og Bytespider stupte 85 %. Denne omrokkeringen gjenspeiler den økende konkurransen mellom AI-selskaper om å sikre treningsdata og forbedre modellene sine. Her er en detaljert oversikt over de største søkebotene og deres markedsposisjon:
| Søkebotnavn | Selskap | Månedlige forespørsler | Årlig vekst | Hovedformål |
|---|---|---|---|---|
| Googlebot | 4,5 milliarder | 96 % | Søkeindeksering & AI Overviews | |
| GPTBot | OpenAI | 569 millioner | 305 % | ChatGPT-modelltrening & søk |
| Claude | Anthropic | 370 millioner | -46 % | Claude-modelltrening & søk |
| Bingbot | Microsoft | ~450 millioner | 2 % | Søkeindeksering |
| PerplexityBot | Perplexity.ai | 24,4 millioner | 157 490 % | AI-søkeindeksering |
| Meta-ExternalAgent | Meta | ~380 millioner | Ny aktør | Meta AI-trening |
| Amazonbot | Amazon | ~210 millioner | -35 % | Søk & AI-applikasjoner |
Tallene viser at selv om Googlebot opprettholder dominansen med 4,5 milliarder månedlige forespørsler, representerer AI-søkeboter samlet omtrent 28 % av Googlebots volum, noe som gjør dem til en betydelig kraft i nettrafikken. Den eksplosive veksten til PerplexityBot (157 490 % økning) viser hvor raskt nye AI-plattformer skalerer sine søkeoperasjoner, mens nedgangen til noen etablerte AI-søkeboter antyder en konsolidering rundt de mest suksessrike AI-plattformene.
GPTBot er OpenAIs webcrawler, spesielt utviklet for å samle inn data til trening og forbedring av ChatGPT og andre OpenAI-modeller. Lansert som en relativt liten aktør med kun 5 % markedsandel i mai 2024, har GPTBot blitt den mest dominerende AI-søkeboten, og står for 30 % av all AI-søkebottrafikk i mai 2025—en bemerkelsesverdig økning på 305 % i antall forespørsler. Denne eksplosive veksten reflekterer OpenAIs aggressive strategi for å sikre at ChatGPT har tilgang til ferskt, variert nettinnhold både for modelltrening og sanntidssøk via ChatGPT Search. GPTBot opererer med et distinkt mønster, og prioriterer HTML-innhold (57,70 % av forespørslene), men laster også ned JavaScript-filer og bilder, selv om den ikke kjører JavaScript for å vise dynamisk innhold. Søkeboten støter ofte på 404-feil (34,82 % av forespørslene), noe som tyder på at den følger utdaterte lenker eller prøver å få tilgang til ressurser som ikke lenger eksisterer. For nettsideeier betyr GPTBots dominans at det er kritisk å sørge for at innholdet ditt er tilgjengelig for denne søkeboten, for synlighet i ChatGPTs søkefunksjoner og mulig inkludering i fremtidige modelltreninger.
ClaudeBot, utviklet av Anthropic, fungerer som hovedcrawler for trening og oppdatering av Claude AI-assistenten, samt støtte for Claudes søkefunksjoner og forankring. Tidligere den nest største AI-søkeboten med 27 % markedsandel i mai 2024, har ClaudeBot opplevd en markant nedgang til 21 % i mai 2025, med antall forespørsler ned 46 % fra året før. Denne nedgangen indikerer ikke nødvendigvis et problem med Anthropics strategi, men reflekterer den bredere markedsendringen mot OpenAIs dominans og fremveksten av nye konkurrenter som Meta-ExternalAgent. ClaudeBot viser lignende atferd som GPTBot, med prioritering av HTML-innhold, men dedikerer en høyere andel forespørsler til bilder (35,17 %), noe som kan tyde på at Anthropic trener Claude til å forstå visuelt innhold i tillegg til tekst. Som andre AI-søkeboter kjører ikke ClaudeBot JavaScript, og ser derfor kun rå HTML på sidene uten dynamisk innhold. For innholdsskapere er det fortsatt viktig å være synlig for ClaudeBot, spesielt ettersom Anthropic videreutvikler Claudes søke- og resonnementsevner.
I tillegg til GPTBot og ClaudeBot er flere andre betydningsfulle AI-søkeboter aktive med å samle inn nettdata til sine plattformer:
Meta-ExternalAgent (Meta): Metas crawler gjorde et dramatisk inntog i toppen, og oppnådde 19 % markedsandel innen mai 2025 som ny aktør. Denne boten samler inn data for Metas AI-initiativer, inkludert mulig trening for Meta AI og integrasjon med Instagrams og Facebooks AI-funksjoner. Metas raske vekst tyder på at selskapet satser seriøst på AI-drevet søk og anbefalinger.
PerplexityBot (Perplexity.ai): Til tross for kun 0,2 % markedsandel, hadde PerplexityBot den mest eksplosive vekstraten på 157 490 % år-over-år. Dette reflekterer Perplexitys raske vekst som en AI-svarmotor som er avhengig av sanntidssøk på nettet for å forankre svarene sine. For nettsteder gir besøk fra PerplexityBot direkte muligheter til å bli sitert i Perplexitys AI-genererte svar.
Amazonbot (Amazon): Amazons crawler falt fra 21 % til 11 % markedsandel, med 35 % færre forespørsler fra år til år. Amazonbot samler inn data for Amazons søkefunksjon og AI-applikasjoner, men den fallende andelen kan tyde på at Amazon endrer AI-strategien eller konsoliderer søkebotoperasjonene sine.
Applebot (Apple): Apples crawler opplevde en nedgang på 26 % i forespørsler, fra 1,9 % til 1,2 % markedsandel. Applebot betjener hovedsakelig Apples Siri og Spotlight-søk, men kan også støtte Apples voksende AI-initiativer. I motsetning til de fleste andre AI-søkeboter kan Applebot kjøre JavaScript, og har dermed evner som ligner på Googlebot.
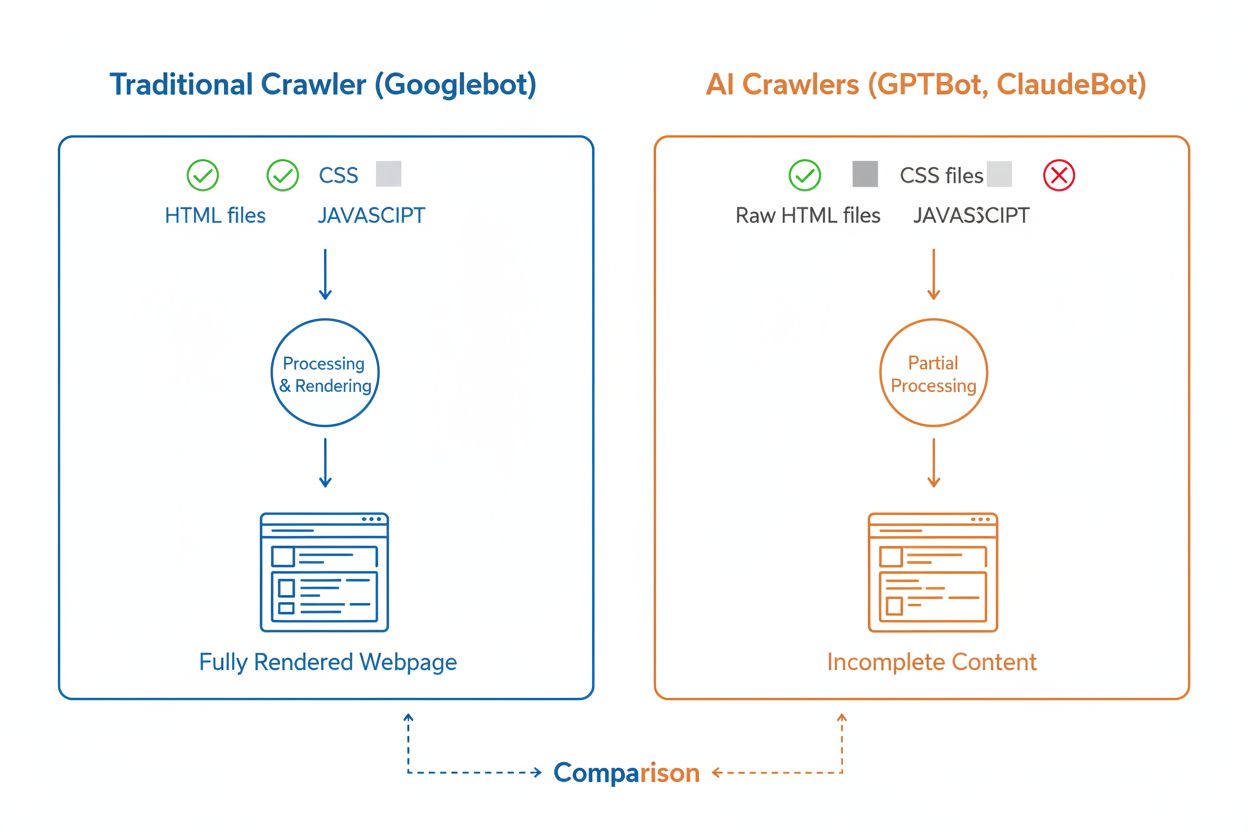
Selv om både AI-søkeboter og tradisjonelle søkeboter som Googlebot systematisk surfer på nettet, skiller deres tekniske evner og atferd seg betydelig, noe som direkte påvirker hvordan innholdet ditt blir oppdaget og forstått. Den viktigste forskjellen er JavaScript-rendering: Googlebot kan kjøre JavaScript etter å ha lastet ned en side, og dermed se dynamisk innhold, mens de fleste AI-søkeboter (GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider) kun leser rå HTML og ignorerer innhold som er avhengig av JavaScript. Hvis nettstedet ditt er avhengig av client-side rendering for å vise viktig informasjon, vil AI-søkeboter kun se en ufullstendig versjon av sidene dine. I tillegg har AI-søkeboter mindre forutsigbare crawl-mønstre sammenlignet med Googlebots systematiske tilnærming—de bruker 34,82 % av forespørslene på 404-sider og 14,36 % på videresendinger, mot Googlebots mer effektive 8,22 % på 404-sider og 1,49 % på videresendinger. Crawl-frekvensen er også forskjellig: mens Googlebot besøker sider basert på et sofistikert crawl-budsjettsystem, ser det ut til at AI-søkeboter crawler oftere, men mindre systematisk—noen undersøkelser viser at AI-søkeboter kan besøke sider over 100 ganger hyppigere enn Google i visse tilfeller. Disse forskjellene betyr at tradisjonelle SEO-strategier ikke nødvendigvis adresserer AI-søkbarhet, og krever en egen tilnærming med fokus på server-side rendering og rene URL-strukturer.
En av de største tekniske utfordringene for AI-søkeboter er deres manglende evne til å kjøre JavaScript, en begrensning som skyldes de store beregningskostnadene ved å kjøre JavaScript i stor skala for trening av språkmodeller. Når en søkebot laster ned nettsiden din, mottar den kun den opprinnelige HTML-en, men alt innhold som lastes eller endres med JavaScript—som produktdetaljer, prisinformasjon, brukeranmeldelser eller dynamisk navigasjon—er usynlig for AI-søkeboter. Dette skaper en kritisk utfordring for moderne nettsteder som er bygget med klientbaserte rammeverk som React, Vue eller Angular uten server-side rendering (SSR) eller statisk sidegenerering (SSG). For eksempel vil en nettbutikk som laster produktinformasjon via JavaScript fremstå for AI-søkeboter som en tom side uten produktdetaljer, noe som gjør det umulig for AI-systemer å forstå eller sitere innholdet. Løsningen er å sørge for at alt kritisk innhold leveres i den opprinnelige HTML-responsen gjennom server-side rendering, som genererer komplett HTML på serveren før den sendes til nettleseren. Dette sikrer at både menneskelige besøkende og AI-søkeboter får det samme innholdsrike inntrykket. Nettsteder som bruker moderne rammeverk som Next.js med SSR, statiske sidegeneratorer som Hugo eller Gatsby, eller tradisjonelle server-renderede plattformer som WordPress, er naturlig AI-søkebot-vennlige, mens sider kun basert på client-side rendering har betydelige synlighetsutfordringer i AI-søk.
AI-søkeboter har særegne crawl-frekvensmønstre som skiller seg markant fra Googlebots atferd, med viktige konsekvenser for hvor raskt innholdet ditt blir plukket opp av AI-systemer. Forskning viser at AI-søkeboter som ChatGPT og Perplexity ofte besøker sider oftere enn Google kort tid etter publisering—i noen tilfeller 8 ganger så ofte som Googlebot de første dagene. Dette raske innledende crawlet tyder på at AI-plattformer prioriterer å oppdage og indeksere nytt innhold raskt, trolig for å sikre at modellene og søkefunksjonene har tilgang til oppdatert informasjon. Men denne aggressive innledende crawlingen følges av et mønster der AI-søkeboter ikke nødvendigvis kommer tilbake hvis innholdet ikke møter kvalitetskrav, noe som gjør førsteinntrykket avgjørende. I motsetning til Googlebot, som har et sofistikert crawl-budsjettsystem og vil returnere til sider regelmessig basert på oppdateringsfrekvens og betydning, ser det ut til at AI-søkeboter vurderer om innholdet er verdt å besøke igjen. Det betyr at hvis en AI-søkebot besøker siden din og finner tynt innhold, tekniske feil eller dårlig brukeropplevelse, kan det ta lang tid før den kommer tilbake—om den i det hele tatt gjør det. For innholdsskapere er konklusjonen tydelig: du kan ikke forvente en ny sjanse til å optimalisere for AI-søkeboter slik du kan med tradisjonelle søkemotorer, og kvalitetssikring før publisering er derfor essensielt.
Nettsideeier kan bruke robots.txt-filen for å angi preferanser om AI-søkeboters tilgang, men effekten og håndhevelsen av disse reglene varierer betydelig mellom ulike søkeboter. Ifølge ferske data har omtrent 14 % av de 10 000 største nettstedene implementert spesifikke tillatelses- eller nektelsesregler rettet mot AI-boter i robots.txt-filene sine. GPTBot er den mest blokkerte søkeboten, med 312 domener (250 fullt, 62 delvis) som eksplisitt nekter tilgang, men det er også den mest eksplisitt tillatte boten med 61 domener som gir adgang. Andre vanlige blokkerte er CCBot (Common Crawl) og Google-Extended (Googles AI-trenings-token). Utfordringen med robots.txt er at etterlevelse er frivillig—søkeboter følger reglene kun hvis operatørene har implementert dette, og noen nye eller mindre transparente søkeboter respekterer ikke robots.txt-direktiver i det hele tatt. I tillegg korresponderer ikke robots.txt-tokens som “Google-Extended” direkte til user-agent-strenger i HTTP-forespørsler; de signaliserer formålet med crawling, så du kan ikke alltid verifisere etterlevelse via serverlogger. For sterkere håndhevelse benytter stadig flere nettsideeier brannmurregler og Web Application Firewalls (WAF) som aktivt kan blokkere bestemte søkebot-user-agents, noe som gir mer pålitelig kontroll enn robots.txt alene. Denne overgangen til aktive blokkeringsmekanismer reflekterer økende bekymringer rundt innholdsrettigheter og ønsket om mer håndhevbare kontroller over AI-søkeboters tilgang.
Å følge med på AI-søkeboters aktivitet på nettstedet ditt er avgjørende for å forstå synligheten din i AI-søk, men innebærer unike utfordringer sammenlignet med overvåking av tradisjonelle søkemotorroboter. Tradisjonelle analyseverktøy som Google Analytics er avhengige av JavaScript-sporing, som AI-søkeboter ikke utfører, noe som betyr at disse verktøyene ikke viser AI-bot-besøk. Det samme gjelder pikselbasert sporing, da de fleste AI-søkeboter kun prosesserer tekst og ignorerer bilder. Den eneste pålitelige måten å spore AI-søkebotaktivitet på er gjennom server-side overvåking—analyse av HTTP-request-headere og serverlogger for å identifisere søkebot-user-agents før siden leveres. Dette krever enten manuell logganalyse eller spesialverktøy utviklet for å identifisere og overvåke AI-søkebottrafikk. Sanntidsovervåking er spesielt viktig fordi AI-søkeboter opererer på uforutsigbare tidspunkter og kanskje ikke returnerer til sider hvis de møter problemer, slik at ukentlige eller månedlige crawl-revisjoner kan overse viktige feil. Hvis en AI-søkebot besøker nettstedet ditt og finner en teknisk feil eller dårlig innhold, får du kanskje aldri en ny sjanse til å gjøre et godt inntrykk. Implementering av 24/7-overvåkningsløsninger som varsler deg umiddelbart når AI-søkeboter støter på problemer—som 404-feil, trege lastetider eller manglende schema-markup—gjør at du kan rette opp i problemer før de påvirker AI-synligheten din. Denne sanntidstilnærmingen representerer et grunnleggende skifte fra tradisjonelle SEO-overvåkingspraksiser, og reflekterer tempoet og uforutsigbarheten i AI-søkeboters atferd.
Å optimalisere nettstedet ditt for AI-søkeboter krever en annen tilnærming enn tradisjonell SEO, med fokus på tekniske faktorer som direkte påvirker hvordan AI-systemer får tilgang til og forstår innholdet ditt. Førsteprioritet er server-side rendering: sørg for at alt kritisk innhold—overskrifter, brødtekst, metadata, strukturert data—er inkludert i den opprinnelige HTML-responsen i stedet for å bli lastet inn dynamisk via JavaScript. Dette gjelder for forsiden, viktige landingssider og alt innhold du ønsker at AI-systemer skal sitere eller referere til. For det andre, implementer strukturert datamerking (Schema.org) på dine viktigste sider, inkludert artikkel-skjema for blogginnlegg, produkt-skjema for nettbutikker og forfatter-skjema for å etablere ekspertise og autoritet. AI-søkeboter bruker strukturert data for raskt å forstå innholdshierarki og kontekst, noe som gjør det mye enklere for dem å tolke og sitere informasjonen din. For det tredje, oppretthold høy innholdskvalitet på alle sider, da AI-søkeboter ser ut til å gjøre raske vurderinger av om innholdet er verdt å indeksere og sitere. Det betyr at innholdet må være originalt, godt undersøkt, faktabasert og gi reell verdi for leseren. For det fjerde, overvåk og optimaliser Core Web Vitals og generelle sideytelse, da trege sider signaliserer dårlig brukeropplevelse og kan gjøre at AI-søkeboter ikke returnerer. Til slutt, sørg for en ren og konsistent URL-struktur, oppdatert XML-sitemap og korrekt konfigurert robots.txt-fil for å veilede søkeboter til det viktigste innholdet. Disse tekniske optimaliseringene gir grunnlaget for at innholdet ditt blir oppdagbart, forståelig og siterbart av AI-systemer.
Landskapet for AI-søkeboter vil fortsette å utvikle seg raskt i takt med økt konkurranse mellom AI-selskaper og teknologisk modning. En tydelig trend er konsolidering av markedsandeler rundt de mest suksessrike plattformene—OpenAIs GPTBot har blitt den dominerende aktøren, mens nye som Meta-ExternalAgent vokser aggressivt, noe som antyder at markedet sannsynligvis vil stabilisere seg rundt noen få hovedspillere. Etter hvert som AI-søkeboter modnes, kan vi forvente forbedringer i deres tekniske evner, spesielt rundt JavaScript-rendering og mer effektive crawl-mønstre som reduserer bortkastede forespørsler på 404-sider og utdatert innhold. Bransjen beveger seg også mot mer standardiserte kommunikasjonsprotokoller, som den nye llms.txt-spesifikasjonen, som lar nettsteder eksplisitt kommunisere innholdsstruktur og crawl-preferanser til AI-systemer. I tillegg blir håndhevingsmekanismene for å kontrollere AI-søkeboters tilgang stadig mer avanserte, med plattformer som Cloudflare som nå tilbyr automatisk blokkering av AI-treningsroboter som standard, noe som gir nettsideeier mer detaljert kontroll over innholdet sitt. For innholdsskapere og nettsideeier betyr det å holde seg foran disse endringene at man kontinuerlig må overvåke AI-søkebotaktivitet, holde den tekniske infrastrukturen optimalisert for AI-tilgjengelighet, og tilpasse innholdsstrategien til virkeligheten at AI-systemer nå utgjør en betydelig andel av nettstedets trafikk og er en kritisk kanal for merkevaresynlighet. Fremtiden tilhører dem som forstår og optimaliserer for dette nye søkebot-økosystemet.
AI-søkeboter er automatiserte programmer som samler inn nettdata spesielt for å trene og forbedre kunstige intelligensmodeller som ChatGPT og Claude. I motsetning til tradisjonelle søkemotorroboter som Googlebot, som indekserer innhold for søkeresultater, samler AI-søkeboter inn rå nettdata for å mate inn i store språkmodeller. Begge typer søkeboter surfer systematisk på internett, men de har ulike formål og forskjellige tekniske kapasiteter.
AI-søkeboter får tilgang til nettstedet ditt for å samle inn data til trening av AI-modeller, forbedre søkefunksjoner og forankre AI-svar med oppdatert informasjon. Når AI-systemer som ChatGPT eller Perplexity svarer på brukerspørsmål, må de ofte hente innholdet ditt i sanntid for å gi nøyaktig og sitert informasjon. Å tillate AI-søkeboter tilgang øker sjansen for at merkevaren din blir nevnt og sitert i AI-genererte svar.
Ja, du kan bruke robots.txt-filen din til å nekte bestemte AI-søkeboter ved å spesifisere deres user-agent-navn. Imidlertid er etterlevelse av robots.txt frivillig, og ikke alle søkeboter respekterer disse reglene. For sterkere håndheving kan du bruke brannmurregler og Web Application Firewalls (WAF) for aktivt å blokkere bestemte user-agent-navn. Dette gir deg mer pålitelig kontroll over hvilke AI-søkeboter som får tilgang til innholdet ditt.
Nei, de fleste AI-søkeboter (GPTBot, ClaudeBot, Meta-ExternalAgent) utfører ikke JavaScript. De leser bare den rå HTML-en på sidene dine, noe som betyr at alt innhold som lastes inn dynamisk via JavaScript vil være usynlig for dem. Derfor er server-side rendering kritisk for AI-søkbarhet. Hvis nettstedet ditt er avhengig av client-side rendering, vil AI-søkeboter se en ufullstendig versjon av sidene dine.
AI-søkeboter besøker nettsteder oftere enn tradisjonelle søkemotorer på kort sikt etter publisering av innhold. Forskning viser at de kan besøke sider 8–100 ganger hyppigere enn Google de første dagene. Men hvis innholdet ikke møter kvalitetsstandarder, kommer de kanskje ikke tilbake. Dette gjør førsteinntrykket kritisk – du får kanskje ikke en ny sjanse til å optimalisere innholdet for AI-søkeboter.
De viktigste optimaliseringene er: (1) Bruk server-side rendering for å sikre at kritisk innhold er i den opprinnelige HTML-en, (2) Legg til strukturert datamerking (Schema) for å hjelpe AI å forstå innholdet ditt, (3) Oppretthold høy innholdskvalitet og relevans, (4) Overvåk Core Web Vitals for god brukeropplevelse, og (5) Hold URL-strukturen ryddig og vedlikehold et oppdatert sitemap. Disse tekniske optimaliseringene gir et fundament som gjør innholdet ditt oppdagbart og siterbart av AI-systemer.
GPTBot fra OpenAI er for øyeblikket den dominerende AI-søkeboten, og står for 30 % av all AI-søkebottrafikk og vokser 305 % årlig. Du bør imidlertid optimalisere for alle de store søkebotene, inkludert ClaudeBot (Anthropic), Meta-ExternalAgent (Meta), PerplexityBot (Perplexity) og andre. Ulike AI-plattformer har ulike brukerbaser, så synlighet på tvers av flere søkeboter maksimerer merkevarens tilstedeværelse i AI-søk.
Tradisjonelle analyserverktøy som Google Analytics fanger ikke opp AI-søkebotaktivitet fordi de er avhengige av JavaScript-sporing. I stedet trenger du server-side overvåking som analyserer HTTP-request-headere og serverlogger for å identifisere søkebot-user-agents. Spesialiserte verktøy designet for sporing av AI-søkeboter gir sanntidsinnsikt i hvilke sider som blir crawlet, hvor ofte og om søkebotene støter på tekniske problemer.
Følg med på hvordan AI-søkeboter som GPTBot og ClaudeBot får tilgang til og siterer innholdet ditt. Få sanntidsinnsikt i din AI-synlighet med AmICited.
Oppdag de avgjørende forskjellene mellom AI-treningsroboter og søkeroboter. Lær hvordan de påvirker synligheten av innholdet ditt, optimaliseringsstrategier og ...

Lær hvordan du lar AI-boter som GPTBot, PerplexityBot og ClaudeBot crawle nettstedet ditt. Konfigurer robots.txt, sett opp llms.txt, og optimaliser for AI-synli...

Fullstendig guide til PerplexityBot crawler – forstå hvordan den fungerer, styr tilgang, overvåk siteringer og optimaliser for synlighet i Perplexity AI. Lær om...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.