
Enhetsgjenkjenning
Enhetsgjenkjenning er en AI NLP-funksjon som identifiserer og kategoriserer navngitte enheter i tekst. Lær hvordan det fungerer, dets bruksområder innen AI-over...
9 min lesing

Utforsk hvordan AI-systemer gjenkjenner og behandler enheter i tekst. Lær om NER-modeller, transformer-arkitekturer og virkelige applikasjoner av enhetsforståelse.
Enhetsforståelse har blitt en hjørnestein i moderne kunstig intelligens, og gjør det mulig for maskiner å identifisere og forstå nøkkelaktører, steder og konsepter i ustrukturert tekst. Fra søkemotorer som forstår brukerintensjon til chatbots som kan svare på komplekse spørsmål om spesifikke personer og organisasjoner, utgjør enhetsgjenkjenning grunnlaget for meningsfull menneske-maskin-interaksjon. Denne tekniske evnen er kritisk på tvers av bransjer—finansinstitusjoner bruker den til etterlevelsesovervåkning, helsesystemer drar nytte av den for pasientjournalsystemer, og e-handelsplattformer er avhengige av den for å forstå produktomtaler og kundefeedback. Å forstå hvordan AI-systemer trekker ut og tolker enheter, er essensielt for alle som utvikler eller drifter NLP-applikasjoner i produksjonsmiljøer.
Navngitt enhetsgjenkjenning (NER) er NLP-oppgaven med å identifisere og klassifisere navngitte enheter—spesifikke, meningsfulle informasjonsenheter—i tekst i forhåndsdefinerte kategorier. Disse enhetene representerer de konkrete subjektene som bærer semantisk vekt i språket: personer som utfører handlinger, organisasjoner som tar beslutninger, steder hvor hendelser skjer, tidsuttrykk som forankrer hendelser i tid, pengeverdi som kvantifiserer transaksjoner, og produkter som kjøpes og selges. Klassifisering av enheter er viktig fordi det omgjør råtekst til strukturert kunnskap maskiner kan resonnere over og handle ut fra; uten dette kan et system ikke skille mellom “Apple selskapet” og “apple frukten”, eller forstå at “John Smith” og “J. Smith” refererer til samme person. Evnen til å klassifisere enheter nøyaktig muliggjør nedstrømsapplikasjoner som kunnskapsgraf-konstruksjon, informasjonsuttrekk, spørsmålsbesvarelse og relasjonsdeteksjon.
| Enhetstype | Definisjon | Eksempel |
|---|---|---|
| PERSON | Individuelle mennesker | “Steve Jobs”, “Marie Curie” |
| ORGANIZATION | Selskaper, institusjoner, grupper | “Microsoft”, “FN”, “Harvard University” |
| LOCATION | Geografiske steder og regioner | “New York”, “Amazonelven”, “Silicon Valley” |
| DATE | Tidsuttrykk og tidsperioder | “15. januar 2024”, “neste tirsdag”, “Q3 2023” |
| MONEY | Pengeverdier og valutaer | “50 millioner dollar”, “€100”, “5000 yen” |
| PRODUCT | Varer, tjenester og kreasjoner | “iPhone 15”, “Windows 11”, “ChatGPT” |
Moderne AI-systemer behandler enheter gjennom en sofistikert flerstegs pipeline som starter med tokenisering, hvor råtekst brytes ned i diskrete tokens som fungerer som grunnleggende enheter for videre behandling. Hver token konverteres deretter til en numerisk representasjon gjennom ordembeddinger—tette vektorer som fanger opp semantisk betydning—og mates inn i nevrale nettverksarkitekturer designet for å forstå kontekst og relasjoner. Transformerbaserte modeller, som har blitt den dominerende arkitekturen i moderne NLP, behandler hele sekvenser parallelt i stedet for sekvensielt, og gjør det mulig å fange opp langdistanseavhengigheter og komplekse kontekstuelle relasjoner som er avgjørende for nøyaktig enhetsforståelse. Self-attention-mekanismen i Transformere lar hver token dynamisk vekte viktigheten av alle andre tokens i sekvensen, og skaper rike kontekstuelle representasjoner hvor betydningen av et ord formes av dets omgivende kontekst; dette er grunnen til at “bank” forstås forskjellig i “river bank” versus “savings bank”. Forhåndstrente språkmodeller som BERT og GPT lærer generelle språklige mønstre fra enorme tekstkorpuser før de finjusteres på enhetsgjenkjenningsoppgaver, slik at de kan utnytte lærte representasjoner av syntaks, semantikk og verdensforståelse. Det siste laget i enhetsgjenkjenningssystemer bruker vanligvis en sekvensmerkingsmetode—ofte implementert som en Conditional Random Field (CRF) eller et enkelt klassifiseringshode—som tildeler enhetsklasser til hver token basert på de kontekstuelle representasjonene lært av det nevrale nettverket. Denne arkitekturen gjør AI-systemer i stand til å forstå ikke bare hvilke enheter som er til stede, men også hvordan de forholder seg til hverandre og hvilke roller de spiller i den bredere sammenhengen i teksten.
Enhetsgjenkjenning har utviklet seg dramatisk de siste to tiårene, fra enkle regelbaserte tilnærminger til avanserte nevrale arkitekturer. Tidlige systemer var basert på håndlagde regler og ordbøker, brukte regulære uttrykk og mønstergjenkjenning for å identifisere enheter—metoder som var tolkbare og krevde minimalt med treningsdata, men som hadde dårlig generalisering og høy vedlikeholdskostnad. Innføringen av maskinlæring førte til superviserte tilnærminger som Support Vector Machines (SVM) og Conditional Random Fields (CRF), som lærte fra merket data via feature engineering og ga betydelig bedre nøyaktighet, selv om de fortsatt krevde domeneeksperter for å designe meningsfulle trekk. Dype nevrale nettverk, spesielt LSTM og BiLSTM, automatiserte feature-ekstraksjon ved å lære representasjoner direkte fra råtekst, oppnådde mye høyere nøyaktighet uten manuell feature engineering, men krevde større merkede datasett. Transformerbaserte modeller som BERT og RoBERTa revolusjonerte feltet ved å bruke self-attention-mekanismer for å fange langtrekkende avhengigheter og kontekstuelle nyanser, og oppnå state-of-the-art resultater (BERT nådde 90,9% F1 på CoNLL-2003) samtidig som de muliggjorde transfer learning fra massive forhåndstrente modeller. Forholdet mellom kompleksitet og nøyaktighet har endret seg drastisk: mens regelbaserte systemer fortsatt er verdifulle i ressursbegrensede miljøer og høyt spesialiserte domener, dominerer transformer-modeller nå når det finnes tilstrekkelige ressurser og merkede data, med lettere alternativer som DistilBERT som tilbyr et kompromiss for produksjonssystemer med latenskrav.
Transformerbaserte modeller har fundamentalt endret enhetsgjenkjenning ved å erstatte sekvensiell behandling med parallelle self-attention-mekanismer som vurderer alle tokens i en setning samtidig, og gir rikere kontekstforståelse enn tidligere arkitekturer. BERT og dens varianter (RoBERTa, DistilBERT, ALBERT) benytter toveis forhåndstrening på store ukodede tekstkorpuser, og lærer universelle språkrepresentasjoner som fanger både syntaktisk og semantisk informasjon før de finjusteres på NER-oppgaver med relativt små merkede datasett. Forhåndstrening og finjusteringsparadigmet er spesielt kraftig for enhetsgjenkjenning: modeller forhåndstrent på milliarder av tokens utvikler robuste representasjoner av språkstrukturer og enhetsmønstre, som så kan tilpasses spesifikke domener med bare noen tusen merkede eksempler, og reduserer datakravene dramatisk sammenlignet med trening fra bunnen av. Transformere utmerker seg i enhetsforståelse gjennom sin multi-head attention-mekanisme, hvor ulike attention-hoder spesialiserer seg på ulike typer enhetsrelasjoner—noen hoder kan fokusere på syntaktiske grenser mens andre fanger semantiske assosiasjoner mellom enheter og deres kontekst. Flerspråklig enhetsgjenkjenning er revolusjonert av modeller som mBERT og XLM-RoBERTa, som er forhåndstrent på 100+ språk samtidig, og muliggjør zero-shot og few-shot overføring til lavressursspråk og krysspråklig enhetskobling. Fremvoksende modeller som GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition) strekker grensene ytterligere ved å muliggjøre instruksjonsbasert enhetsgjenkjenning, hvor modeller kan identifisere vilkårlige enhetstyper spesifisert i naturlige språkforespørsler uten oppgavespesifikk finjustering, og representerer et skifte mot mer fleksible og generaliserbare systemer for enhetsforståelse.
Til tross for bemerkelsesverdig fremgang står enhetsgjenkjenningssystemer overfor vedvarende utfordringer i praksis, hvor tvetydighet og kontekstsensitivitet er blant de mest krevende—ordet “Apple” krever forståelse av om det refererer til frukten eller teknologiselskapet basert på omgivende kontekst, og selv de mest avanserte modellene sliter med slik semantisk avklaring i støyende eller tvetydig tekst. Ukjente (OOV) enheter utgjør en annen grunnleggende utfordring: modeller trent på standarddatasett kan aldri ha sett sjeldne enheter, egennavn fra nye domener, eller feilstavelser, og kan dermed feilklassifisere eller overse disse enhetene helt. Domenetilpasning er fortsatt problematisk fordi modeller trent på nyhetskorpus (som CoNLL-2003) ofte presterer dårlig på biomedisinsk, juridisk eller sosiale medier-tekst hvor enhetsfordelinger og språkmønstre avviker dramatisk, og krever kostbar re-annotering og finjustering for hvert nye domene. Feil i grensedeteksjon—hvor systemene riktig identifiserer at en enhet eksisterer, men feilaktig bestemmer start- eller sluttposisjon—er spesielt vanlige for flerords-enheter og nestede strukturer, som å skille “New York City” fra “New York” eller håndtere enheter som “Chief Executive Officer of Apple Inc.” Flerspråklige utfordringer forsterker disse problemene, da ulike språk har forskjellige regler for store/små bokstaver, morfologi og navngivningsmønstre, noe som gjør at modeller trent på engelsk ofte feiler på språk med andre språklige egenskaper. Datamangel i spesialiserte domener som sjeldne sykdomsnavn, nye teknologier eller proprietære selskapsnavn skaper en flaskehals hvor kostnaden for manuell annotering er for høy, og tvinger praktikere til å velge mellom lavere nøyaktighet eller betydelige investeringer i domene-spesifikk datainnsamling.
Enhetsforståelse har blitt uunnværlig på tvers av bransjer, og endrer måten organisasjoner henter verdi fra ustrukturert tekst. Innen informasjonsekstraksjon og kunnskapsgraf-konstruksjon gir enhetsgjenkjenning automatisk befolkning av strukturerte databaser fra dokumenter, og driver søkemotorer og anbefalingssystemer som forstår relasjoner mellom personer, steder og konsepter. Helseorganisasjoner bruker enhetsforståelse for å identifisere legemiddelnavn, doseringer, symptomer og pasientdemografi fra kliniske notater, forbedrer klinisk beslutningsstøtte og gjør det mulig for farmakovigilans-systemer å oppdage bivirkninger i stor skala. Finansinstitusjoner bruker enhetsgjenkjenning for å trekke ut aksjesymboler, pengeverdi og markedsbegivenheter fra nyhetsstrømmer og resultatrapporter, og muliggjør algoritmisk handel og risikostyringsplattformer som reagerer på markedsbevegelser i sanntid. Juridiske teknologiselskaper benytter enhetsforståelse for automatisk å identifisere parter, datoer, forpliktelser og ansvarsparagrafer i kontrakter, og reduserer tiden advokater bruker på dokumentgjennomgang fra uker til timer. Kundeservice- og chatbot-plattformer bruker enhetsgjenkjenning for å trekke ut brukerintensjoner og relevant kontekst—som ordrenummer, produktnavn og problemtyper—og muliggjør mer presis ruting og raskere løsning. E-handelsplattformer bruker enhetsforståelse til å identifisere produktnavn, merker, egenskaper og spesifikasjoner fra kundeanmeldelser og søk, og forbedrer produktoppdagelse og personalisering. Anbefalingssystemer for innhold bruker enhetsgjenkjenning for å forstå hvilke enheter brukere interagerer med, og muliggjør mer sofistikerte anbefalinger som øker engasjement og inntekter.
Å implementere et produksjonsklart enhetsforståelsessystem krever nøye oppmerksomhet til datapreparering, modellvalg og evaluering. Start med høykvalitets annoterte data: etabler klare definisjoner for enhetstyper, bruk inter-annotator agreement-målinger for å sikre konsistens, og sikte på minst 500-1000 merkede eksempler per enhetstype, selv om domene-spesifikke applikasjoner ofte krever mer. Modellvalg avhenger av dine begrensninger: regelbaserte systemer gir tolkbarhet og lav ventetid for veldefinerte domener, tradisjonelle ML-modeller (CRF, SVM) gir god ytelse med moderate datamengder, mens transformerbaserte modeller (BERT, RoBERTa) gir state-of-the-art nøyaktighet, men krever mer ressurser og data. Trenings- og finjusteringsstrategier bør inkludere dataforsterkning for å håndtere klasseubalanse, kryssvalidering for å forhindre overtilpasning, og nøye tuning av hyperparametere for læringsrate og batch-størrelse. Evaluer systemet ditt med presisjon (riktige enheter identifisert), recall (enheter funnet av alle faktiske enheter), og F1-score (harmonisk gjennomsnitt som balanserer begge), med separate målinger for hver enhetstype for å finne svake punkter. Distribusjonsvurderinger inkluderer ventetidskrav (batch vs. sanntidsbehandling), skalerbarhetsbehov og integrasjon med eksisterende datapipelines, mens overvåkning etter produksjonssetting bør spore ytelsesdrift, falske positiver og brukertilbakemeldinger for å trigge retreningssykluser.
Økosystemet av verktøy for enhetsforståelse tilbyr løsninger for alle skalaer og bruksområder. Åpen kildekode-biblioteker som spaCy tilbyr produksjonsklare NER-pipelines med imponerende ytelse (89,22% F1-score på standard benchmarks) og utmerket dokumentasjon, noe som gjør det ideelt for team med maskinlæringskompetanse; NLTK gir pedagogisk verdi og grunnleggende NER-funksjonalitet; og Hugging Face Transformers gir tilgang til state-of-the-art forhåndstrente modeller som kan finjusteres for spesifikke domener med minimal kode. Skybaserte tjenester fjerner infrastrukturhodebry: Google Cloud Natural Language API, AWS Comprehend og IBM Watson NLP tilbyr forhåndstrent enhetsgjenkjenning med støtte for flere språk og enhetstyper, håndterer skalering automatisk og integreres sømløst med cloud-datapipelines. Spesialiserte rammeverk som Flair (bygget på PyTorch med utmerket støtte for sekvensmerking) og DeepPavlov (med forhåndstrente modeller for flere språk og domener) er rettet mot forskere og team som trenger mer tilpasning enn generelle biblioteker. Valget mellom å bygge egne løsninger og bruke ferdige verktøy avhenger av datasensitivitet (lokalt vs. sky), nødvendige nøyaktighetsnivåer, domenespesifisitet og teamkompetanse: bruk administrerte API-er for generelle applikasjoner med standard enhetstyper, bruk åpen kildekode for domene-tilpasning med interne data, og bygg egne modeller kun når eksisterende løsninger ikke møter dine krav til nøyaktighet eller lav ventetid.
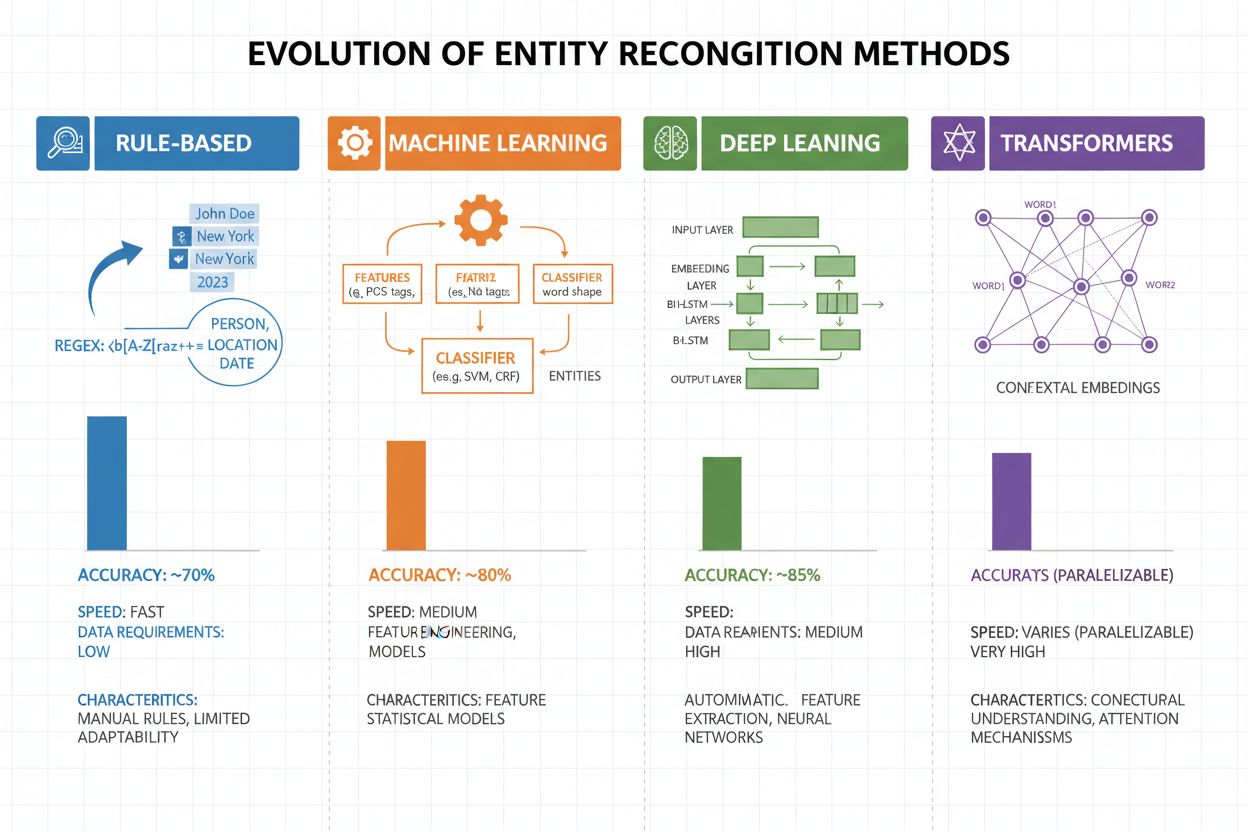
Fremtiden for enhetsforståelse formes av store språkmodeller som gir enestående fleksibilitet og ytelse for oppgaven. Modeller som GPT-4 og Claude viser imponerende few-shot og zero-shot enhetsgjenkjenning, som gjør det mulig for organisasjoner å identifisere tilpassede enhetstyper med bare noen få eksempler eller til og med naturlige språkbeskrivelser, og reduserer annotasjonsbyrden drastisk og gir raskere verdi. Multimodal enhetsforståelse er et nytt felt, hvor tekst, bilder og strukturerte data kombineres for å gjenkjenne enheter i dokumenter, fakturaer og nettsider med rikere kontekst, og muliggjør applikasjoner som automatisk dokumentbehandling og visuell søk. Forbedringer i sanntidsbehandling drevet av modellkomprimering og edge-distribusjon gjør avansert enhetsgjenkjenning mulig på mobile enheter og IoT-systemer, og åpner nye bruksområder innenfor utvidet virkelighet, sanntidstolkning og autonome systemer. Fremskritt innen domenespesifikk finjustering gir spesialiserte modeller for biomedisinske, juridiske og finansielle områder som overgår generelle modeller med stor margin, og teknikker som domenetilpasset forhåndstrening og transfer learning blir stadig mer tilgjengelig. Etter hvert som disse teknologiene modnes, vil enhetsforståelse bli et usynlig fundament i AI-systemer og gjøre det mulig for maskiner å forstå verden med menneskelignende semantisk forståelse, og åpne for muligheter vi bare så vidt har begynt å forestille oss.
Etter hvert som AI-systemer som ChatGPT, Perplexity og Google AI Overviews integreres stadig mer i hvordan informasjon oppdages og konsumeres, blir det kritisk å forstå hvordan disse systemene gjenkjenner og refererer til enheter—inkludert ditt brand. Enhetsforståelse er mekanismen hvor AI-systemer identifiserer og behandler omtaler av selskaper, produkter, personer og konsepter. Når du overvåker hvordan AI-systemer forstår og refererer til ditt brand via enhetsgjenkjenning, får du innsikt i:
Dette er nettopp det AmICited overvåker—sporer hvordan AI-systemer gjenkjenner og refererer til ditt brand som en enhet på tvers av flere AI-plattformer. Ved å forstå enhetsgjenkjenning får du bedre innsikt i hvordan AI-systemer oppfatter og kommuniserer om virksomheten din.
Enhetsgjenkjenning (NER) identifiserer og klassifiserer enheter i tekst (f.eks. 'Apple' som ORGANISASJON), mens enhetskobling knytter disse enhetene til kunnskapsbaser eller kanoniske referanser (f.eks. kobler 'Apple' til Wikipedia-siden for Apple Inc.). Enhetsgjenkjenning er første steg; enhetskobling gir semantisk forankring.
State-of-the-art transformerbaserte modeller som BERT oppnår 90,9% F1-score på standard benchmarks som CoNLL-2003. Nøyaktigheten varierer imidlertid betydelig mellom domener—modeller trent på nyheter presterer dårlig på biomedisinsk eller sosiale medier-tekst. Reell nøyaktighet avhenger sterkt av domenetilpasning og datakvalitet.
Ja, flerspråklige modeller som mBERT og XLM-RoBERTa støtter 100+ språk samtidig. Ytelsen varierer imidlertid mellom språk på grunn av forskjeller i store/små bokstaver-konvensjoner, morfologi og tilgjengelige treningsdata. Språkspecifikke modeller overgår vanligvis flerspråklige for kritiske applikasjoner.
Regelbaserte systemer bruker håndlagde mønstre og ordbøker (raske, tolkbare, men skjøre). ML-baserte systemer lærer fra merket data (mer fleksible, bedre generalisering, men krever treningsdata og feature engineering). Moderne deep learning-tilnærminger automatiserer feature-ekstraksjon og oppnår bedre nøyaktighet.
Regelbaserte systemer trenger kun mønsterdefinisjoner. Tradisjonelle ML-modeller krever 300-500 merkede eksempler. Transformerbaserte modeller fungerer med 800+ eksempler, men får fordeler av transfer learning—forhåndstrente modeller kan oppnå gode resultater med bare 100-200 domene-spesifikke eksempler gjennom finjustering.
Nøkkelutfordringer inkluderer: tvetydighet (samme ord betyr ulike ting), ukjente enheter, domenetilpasning (modeller trent på ett domene feiler på et annet), feil i grensedeteksjon, flerspråklige kompleksiteter og datamangel for spesialiserte domener. Disse krever nøye systemdesign og domenespesifikk tuning.
Kontekst er avgjørende—'bank' betyr ulike ting i 'river bank' vs. 'savings bank.' Moderne transformere bruker self-attention for å vekte kontekst fra alle omkringliggende tokens, slik at de kan avklare enheter basert på språklig og semantisk kontekst. Dårlig kontekstbehandling er en hovedkilde til feil i enhetsgjenkjenning.
Fremtidige utviklinger inkluderer: store språkmodeller som muliggjør zero-shot enhetsgjenkjenning, multimodal forståelse som kombinerer tekst og bilder, sanntidsbehandling på edge-enheter og fremskritt innen domenespesifikk finjustering. Enhetsforståelse vil bli et usynlig fundamentlag som gjør det mulig for maskiner å forstå verden med menneskelignende semantisk forståelse.
AmICited sporer enhetsomtaler på tvers av AI-systemer som ChatGPT, Perplexity og Google AI Overviews. Forstå hvordan AI forstår og refererer til ditt brand i sanntid.
Enhetsgjenkjenning er en AI NLP-funksjon som identifiserer og kategoriserer navngitte enheter i tekst. Lær hvordan det fungerer, dets bruksområder innen AI-over...

Lær hvordan AI-systemer identifiserer, ekstraherer og forstår forhold mellom entiteter i tekst. Oppdag teknikker for entitetsforholdsekstraksjon, NLP-metoder og...
Lær hva AI-enhetsmerking er, hvordan det hjelper AI-systemer å forstå og sitere innholdet ditt, og beste praksis for å implementere Schema.org-strukturert data ...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.