Organisasjonsskjema: Hjelper AI med å forstå din merkevareenhet
Lær hvordan organisasjonsskjema hjelper AI-systemer med å forstå og sitere din merkevare. Komplett guide til merkevareenhetsmarkup for LLM-synlighet og AI-siter...
8 min lesing
Schema.org-strukturert data som tydelig definerer enheter (personer, organisasjoner, produkter, steder) i maskinlesbart format, slik at AI-systemer som ChatGPT, Perplexity og Google AI Overviews kan gjenkjenne, forstå og sitere innholdet ditt med større selvtillit og autoritet.
Schema.org-strukturert data som tydelig definerer enheter (personer, organisasjoner, produkter, steder) i maskinlesbart format, slik at AI-systemer som ChatGPT, Perplexity og Google AI Overviews kan gjenkjenne, forstå og sitere innholdet ditt med større selvtillit og autoritet.
AI-enhetsmerking er Schema.org-strukturert data som tydelig definerer enheter—slik som personer, organisasjoner, produkter og steder—i et maskinlesbart format som AI-systemer enkelt kan gjenkjenne og forstå. I motsetning til tradisjonell SEO-merking som hovedsakelig er laget for søkemotorer, er AI-enhetsmerking spesielt optimalisert for hvordan kunstig intelligens-systemer som ChatGPT, Perplexity og Google AI Overviews tolker, fortolker og siterer nettinnhold. Denne merkingen forvandler tvetydig tekst til verifiserbare, strukturerte fakta som gjør at AI-systemer trygt kan trekke ut informasjon og tilskrive den til autoritative kilder. Etter hvert som AI-genererte svar i økende grad erstatter tradisjonelle søkeresultater, har korrekt implementering av enhetsmerking utviklet seg fra en hyggelig optimalisering til en helt nødvendig infrastruktur for merkevaresynlighet og troverdighet i et AI-drevet søkelandskap.

AI-systemer fungerer i bunn og grunn som statistiske mønstergjenkjenningsmotorer som analyserer enorme mengder data for å generere svar basert på sannsynlighet snarere enn resonnement. Når en AI møter ustrukturert tekst som “John Smith er administrerende direktør i Acme Corp”, må systemet utlede relasjoner mellom tokens uten garantert verifikasjon. Men når den samme informasjonen er pakket inn i Organization-schema med en founder-egenskap som peker til en Person-schema, blir det et verifiserbart, maskinlesbart faktum som AI-systemer trygt kan bruke og sitere. Forskning viser at LLM-er forankret i kunnskapsgrafer oppnår omtrent 300 % høyere nøyaktighet sammenlignet med de som kun stoler på ustrukturert data—en dramatisk forbedring som direkte påvirker om innholdet ditt blir sitert i AI-genererte svar.
| Aspekt | Ustrukturert innhold | Enhetsmerking |
|---|---|---|
| AI-forståelse | Sannsynlighetsbasert gjetting | Verifiserte fakta |
| Siterings-sikkerhet | Lav (16 % nøyaktighet) | Høy (54 % nøyaktighet) |
| Kunnskapsgraf-integrasjon | Begrenset eller fraværende | Full integrasjon |
| Sannsynlighet for AI-sitering | Lavere sannsynlighet | 30 % + høyere synlighet |
| Verifiseringsmulighet | Vanskelig for AI | Eksplisitt og verifiserbar |
| Tydelighet i enhetsrelasjoner | Tvetydig | Presist definert |
Microsofts Principal Product Manager Fabrice Canel bekreftet på SMX Munich at “Schema-merking hjelper Microsofts LLM-er å forstå innhold,” og Bings Copilot bruker spesifikt strukturert data for å tolke nettinnhold. Dette er ikke teoretisk—nettsteder med omfattende strukturert data ser opptil 30 % høyere synlighet i AI Overviews, noe som utgjør forskjellen mellom å bli sitert som en autoritativ kilde og å være fullstendig usynlig for AI-systemer som i økende grad styrer hvordan folk finner informasjon.
Ikke alle schema-typer er like viktige for AI-sitering. Selv om Schema.org inkluderer over 800 typer og mer enn tusen egenskaper, er det bare noen få som direkte påvirker hvordan LLM-er tolker og siterer innholdet ditt. Her er enhetstypene som betyr mest for AI-synlighet:
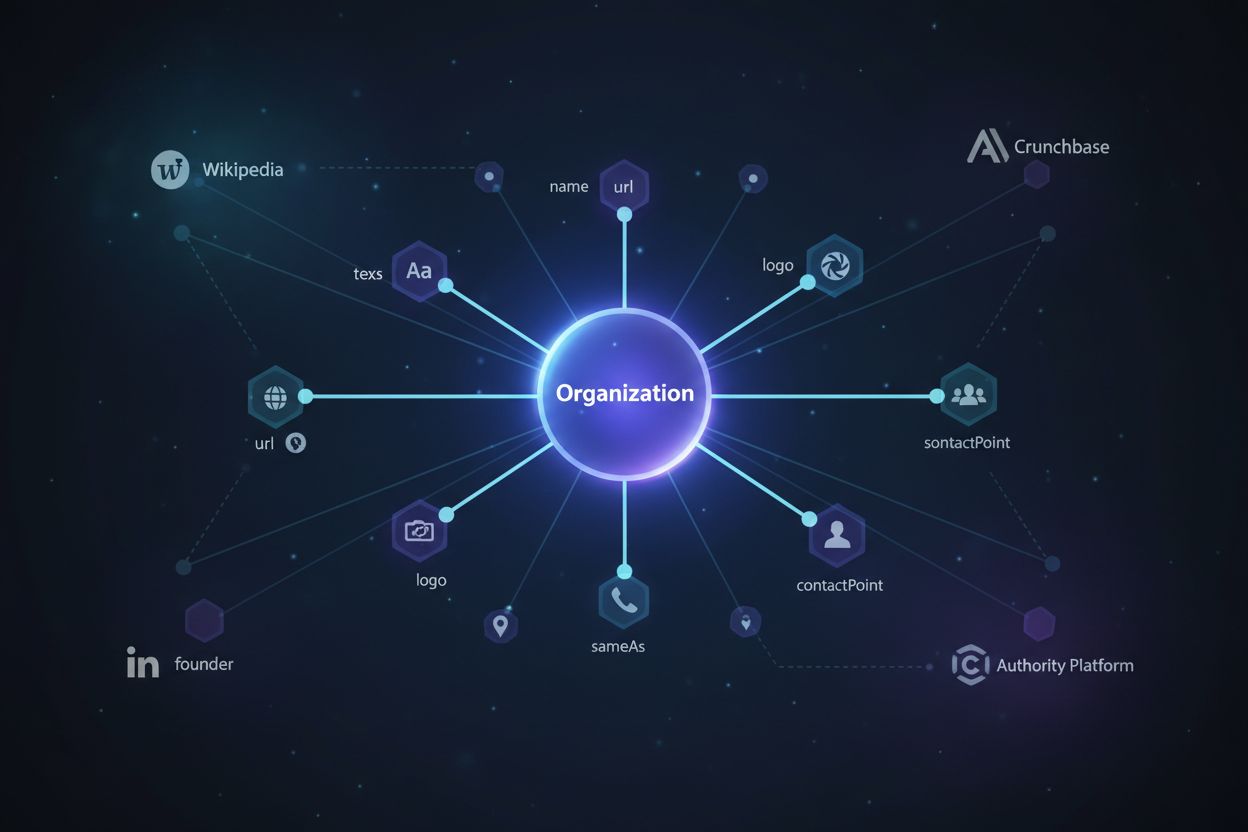
Organization-schema: Definerer selskapet ditt med omfattende sameAs-egenskaper som lenker til Wikipedia, LinkedIn, Crunchbase og andre autoritative plattformer. Dette etablerer merkevaren din som en anerkjent enhet i kunnskapsgrafer og signaliserer troverdighet til AI-systemer som vurderer kildeautoritet.
Person-schema: Etablerer forfatterens ekspertise og troverdighet ved å lage verifiserbare forfatterprofiler med lenker til eksterne plattformer. Når en forfatters Person-schema er korrekt implementert med sameAs-egenskaper, kan AI-systemer verifisere ekspertise på tvers av flere plattformer og styrke E-E-A-T-signaler.
Article-schema: Inkluderer publiseringsdatoer, forfatterinformasjon og utgiverdetaljer—alle signaler som hjelper AI-systemer å vurdere innholdets troverdighet og relevans når de avgjør hva som skal siteres. Article-schema med riktig forfatternavn er ditt troverdighetsbevis i AI-søkets tidsalder.
Product-schema: Merker opp produkter med pris, vurderinger, beskrivelser og tilgjengelighetsinformasjon. For e-handel og SaaS-selskaper gjør Product-schema det mulig for AI-systemer å forstå og anbefale produktene dine når brukere spør om løsninger i din kategori.
FAQPage-schema: Forhåndsformaterer innhold som spørsmål-svar-par, akkurat slik AI-systemer foretrekker å trekke ut og presentere informasjon. FAQPage er arbeidshesten for AI-sitering fordi den gir ferdige, siterbare svar som AI-systemer trygt kan hente når de svarer på relevante spørsmål.
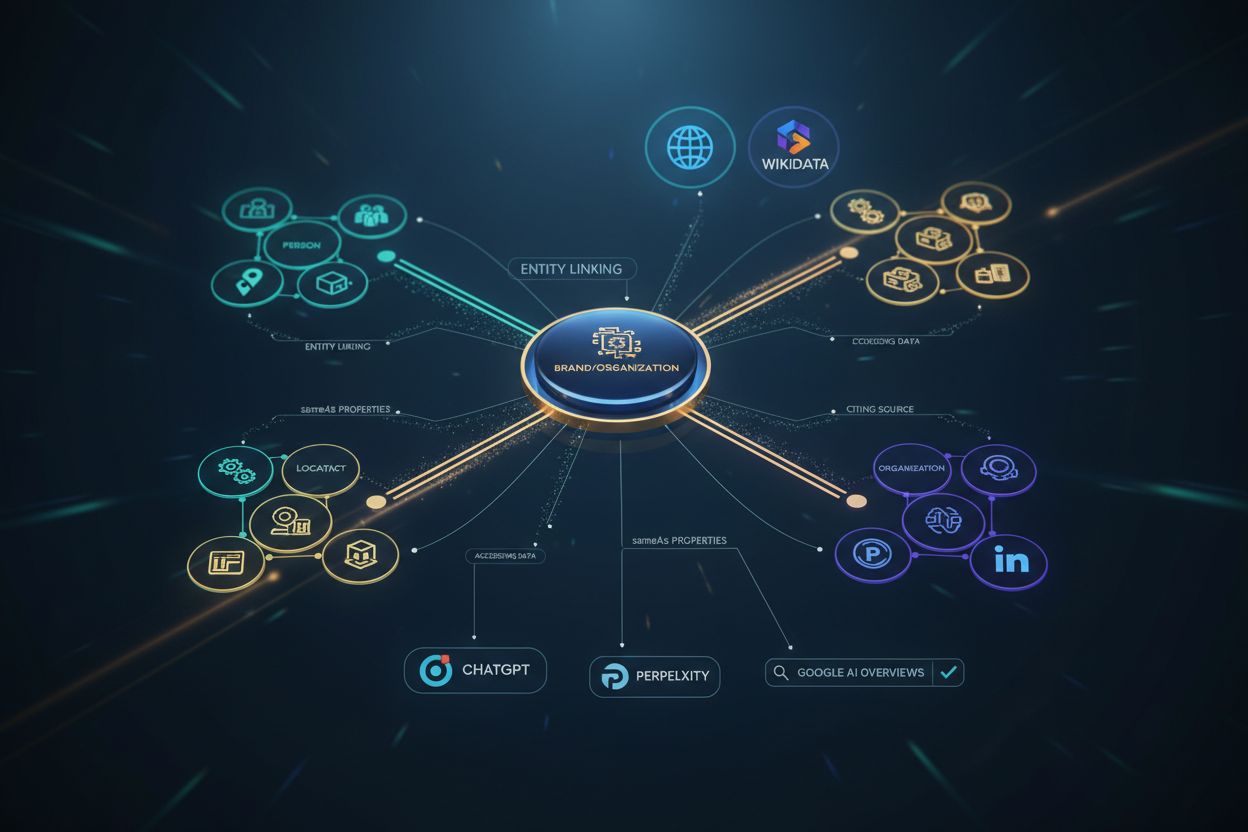
Enhetslenking er prosessen med å identifisere nøkkelbegreper eller “enheter” i innholdet ditt og koble dem til anerkjente kilder som Wikidata, Wikipedia, Googles Knowledge Graph eller din egen organisasjons kunnskapsgraf. Denne koblingen er avgjørende fordi den hjelper AI-systemer å forstå nøyaktig hvilken enhet du refererer til og hvordan den relaterer til andre konsepter i det bredere informasjonsøkosystemet. For eksempel, å lenke “Bronco” til Ford Bronco SUV i stedet for Bronco-hesten avklarer betydningen og sikrer at innholdet ditt tolkes riktig av AI-systemer.
Når du implementerer enhetslenking gjennom Schema.org-merking, bygger du i praksis broer mellom innholdet ditt og autoritative kunnskapskilder. Disse broene gjør det mulig for AI-systemer å navigere relasjoner og forstå kontekst med langt større presisjon. En bildel-forhandler som skriver om “hvordan bytte filter på din Bronco” blir semantisk koblet til enheter som “Ford Bronco” og “bilfilter”, noe som signaliserer til AI-systemer at dette er autoritativt, kontekstuelt relevant innhold verdt å sitere. sameAs-egenskapen er hovedverktøyet ditt for enhetslenking—ved å inkludere URL-er til Wikipedia, Wikidata og andre autoritative kilder, forteller du AI-systemer “denne enheten er den samme som denne anerkjente enheten i kunnskapsgrafen.” Denne plattformovergripende konsistensen bygger enhetsautoritet som AI-systemer bruker for å verifisere ekspertise og avgjøre siteringsverdighet.
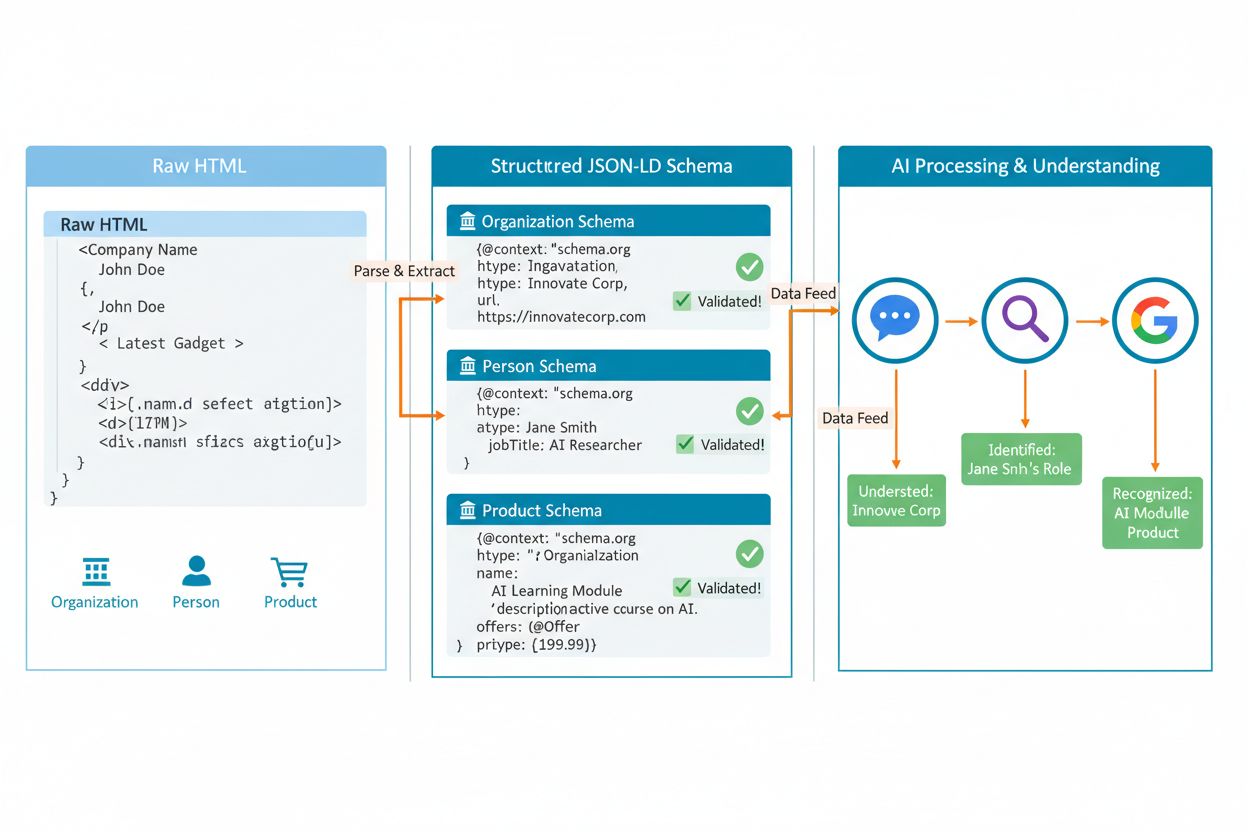
Den mest effektive måten å implementere AI-enhetsmerking på er å bruke JSON-LD-format, som Google eksplisitt anbefaler fordi det skiller schema fra HTML-innholdet, noe som gjør det lettere å implementere og vedlikeholde i stor skala. Plasser JSON-LD-en din i <head>-seksjonen på siden din:
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Your Company Name",
"url": "https://www.yourcompany.com",
"logo": "https://www.yourcompany.com/logo.png",
"description": "Your company description",
"foundingDate": "2020",
"sameAs": [
"https://www.linkedin.com/company/your-company",
"https://twitter.com/yourcompany",
"https://www.crunchbase.com/organization/your-company",
"https://en.wikipedia.org/wiki/Your_Company"
],
"contactPoint": {
"@type": "ContactPoint",
"contactType": "customer service",
"email": "support@yourcompany.com"
}
}
Den reelle styrken ved schema kommer fra å koble relaterte enheter ved hjelp av @id-egenskaper, som lager et nettverk av relasjoner AI-systemer kan navigere for å forstå kontekst. Ved å referere til samme @id på flere sider, bygger du en innholdskunnskapsgraf AI-systemer kan bruke for mer sofistikert resonnement. Kritisk regel: merk bare opp innhold som faktisk er synlig på siden. Hvis brukere ikke kan se informasjonen, skal den ikke inkluderes i schema. AI-systemer krysssjekker schema mot sideinnhold, og uoverensstemmelser skader troverdigheten din. Dette betyr at FAQ-svar i schema må vises et sted på siden, priser må samsvare med viste priser, og forfatterinformasjon må kunne verifiseres på nettstedet ditt.
Mens tradisjonell schema-merking hovedsakelig var laget for å hjelpe søkemotorer med å vise rike utdrag og forbedre klikkrater, handler AI-enhetsmerking i bunn og grunn om å gjøre det mulig for AI-systemer å forstå, verifisere og sitere innholdet ditt med trygghet. Tradisjonell SEO-merking kan hjelpe deg å få stjernerangering i søkeresultater; AI-enhetsmerking hjelper deg å bli sitert som en autoritativ kilde i AI-genererte svar. Dette skillet er svært viktig i en nullklikk-søk-verden der brukere ser oppsummerte svar fra flere kilder samlet i ett AI-generert resultat.
Innvirkningen på merkevareautoritet er betydelig. Når merkevaren din dukker opp i et AI-generert svar, signaliserer det troverdighet og ekspertise selv om brukerne ikke klikker seg inn på siden din. Å bli omtalt i en AI Overview bygger bevissthet og autoritet i stor skala, og når brukere tidligere i kjøpsreisen under research og utforsking. Tradisjonell SEO fokuserer på søkeord og rangeringer; AI-enhetsmerking fokuserer på enhetsrelasjoner og kunnskapsgraf-integrasjon. En merkevare som implementerer riktig enhetsmerking på hele nettstedet sitt, lager et semantisk datalag som gjør at AI-systemer kan forstå ikke bare hva du sier, men hvem du er, hva du står for, og hvordan du henger sammen med viktige temaer. Denne klarheten styrker E-E-A-T-signaler—Experience, Expertise, Authoritativeness og Trustworthiness—som avgjør hvordan AI-systemer gjenkjenner og siterer merkevaren din.
I motsetning til tradisjonell SEO der du kan spore rangeringer og klikk, er måling av AI-sitering fortsatt i utvikling, men flere tilnærminger gir pålitelige innsikter. Den enkleste metoden er manuell prøvetaking: spør ChatGPT, Claude og Perplexity månedlig med spørsmål målgruppen din ville stilt, og dokumenter om du blir sitert, i hvilken kontekst og med hvilket sentiment. Google Search Console inkluderer nå AI Overview-data under “Web”-søketypen, som gjør det mulig å overvåke mønstre for visninger og oppdage endringer i synlighet. Verktøy som AmICited.com overvåker spesifikt hvordan AI-systemer refererer til merkevaren din på tvers av GPT-er, Perplexity og Google AI Overviews, og gir dedikert sporing av AI-siteringsytelse.
Forventede resultater vises vanligvis innen 90 dager med systematisk optimalisering. Grunnarbeid—implementering av Organization-schema med sameAs-egenskaper og Article-schema på viktige innholdssider—kan gi målbare forbedringer i siteringer innen 4–8 uker. Autoritetsbygging gjennom plattformtilstedeværelse og enhetslenking tar 3–6 måneder før det får full effekt. Nettsteder med omfattende strukturert data ser opptil 30 % høyere synlighet i AI Overviews, mens riktig enhetslenking gir bedre engasjement, inkludert økt klikkrate. ROI strekker seg utover siteringer: strukturert data forbedrer også tradisjonell søkesynlighet gjennom rike utdrag, øker CTR med opptil 35 %, og styrker generell innholdsoppdagbarhet på tvers av flere AI-plattformer.
Den nye llms.txt-standarden, introdusert av Answer.AI i 2024, foreslår et enkelt tekstfilformat for å gi AI-systemer kuratert tilgang til ditt viktigste innhold. Selv om bruken fortsatt er begrenset—per midten av 2025 hadde bare rundt 951 domener publisert llms.txt-filer—er spesifikasjonen elegant og kan få gjennomslag etter hvert som AI-systemene utvikler seg. Imidlertid er tradisjonell schema-merking fortsatt den utprøvde, bredt støttede tilnærmingen for AI-synlighet. Den overordnede trenden er tydelig: AI-systemer bygges i økende grad på kunnskapsgrafer, og enheter og deres relasjoner utgjør nodene og forbindelsene som ligger til grunn for disse systemene. Merkevarer som nå investerer i omfattende, semantisk rik strukturert data vil ha betydelige konkurransefortrinn ikke bare i dagens AI Overviews og chatboter, men på tvers av alle fremtidige AI-drevne oppdagelsesplattformer.
Det semantiske datalaget du bygger gjennom korrekt enhetsmerking blir grunnleggende infrastruktur for hvordan AI forstår og representerer merkevaren din i årene som kommer. Per 2025 har over 45 millioner webdomener implementert Schema.org-strukturert data—bare rundt 12,4 % av alle registrerte domener. Det gapet representerer en enorm mulighet for fremoverlente merkevarer som er villige til å gjøre det tekniske arbeidet. Spørsmålet er ikke om AI-systemer vil basere seg mer på strukturert data i fremtiden; de gjør det allerede. Spørsmålet er om innholdet ditt vil være en del av det strukturerte, siterbare økosystemet eller usynlig for AI-systemene som i økende grad styrer hvordan folk finner informasjon.
Følg med på merkevareomtaler i ChatGPT, Perplexity, Google AI Overviews og andre AI-systemer. Forstå hvordan AI-systemer siterer innholdet ditt og optimaliser synligheten din.
Lær hvordan organisasjonsskjema hjelper AI-systemer med å forstå og sitere din merkevare. Komplett guide til merkevareenhetsmarkup for LLM-synlighet og AI-siter...

Lær hvordan strukturert data og schema markup hjelper AI-systemer å forstå, sitere og referere innholdet ditt nøyaktig. Komplett guide til JSON-LD-implementerin...

Lær hvordan forfatterskjema-markup forbedrer AI-sitater i ChatGPT, Perplexity og Google AI Overviews. Oppdag implementeringsstrategier for å øke merkevarens syn...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.