
Hvordan Casestudier Presterer i AI-søkeresultater
Lær hvordan casestudier rangerer i AI-søkemotorer som ChatGPT, Perplexity og Google AI Overviews. Oppdag hvorfor AI-systemer siterer casestudier som autoritativ...
9 min lesing

Lær hvordan du formaterer case-studier for AI-sitater. Oppdag oppskriften på strukturering av suksesshistorier som LLM-er siterer i AI Overviews, ChatGPT og Perplexity.
AI-systemer som ChatGPT, Perplexity og Googles AI Overviews endrer fundamentalt hvordan B2B-kjøpere oppdager og validerer case-studier—likevel publiserer de fleste selskaper dem fortsatt i formater som LLM-er knapt kan tolke. Når en bedriftskjøper spør et AI-system “Hvilke SaaS-plattformer fungerer best for vårt brukstilfelle?”, søker systemet gjennom millioner av dokumenter for å finne relevante bevispunkter, men dårlig formaterte case-studier forblir usynlige for disse hentesystemene. Dette skaper et kritisk gap: Selv om tradisjonelle case-studier gir en grunnleggende 21 % gevinstsrate i sene salgsfaser, kan AI-optimaliserte case-studier øke sannsynligheten for å bli sitert med 28–40 % når de er riktig strukturert for maskinlæringsmodeller. Selskapene som vinner i dette nye landskapet forstår at førstepartsdata-fordel kommer av å være synlig for AI-systemer, ikke bare for menneskelige lesere. Uten bevisst optimalisering for LLM-henting er dine mest overbevisende kundehistorier i praksis låst bort fra AI-systemene som nå påvirker over 60 % av bedriftskjøpsbeslutninger.
En AI-klar case-studie er ikke bare en velskrevet fortelling—det er et strategisk strukturert dokument som tjener både menneskelige lesere og maskinlæringsmodeller samtidig. De mest effektive case-studiene følger en konsekvent arkitektur som lar LLM-er trekke ut nøkkelinformasjon, forstå kontekst og sitere selskapet ditt med trygghet. Nedenfor er hovedoppskriften som skiller AI-finnbare case-studier fra de som forsvinner i hentesystemene:
| Seksjon | Formål | AI-optimalisering |
|---|---|---|
| TL;DR Sammendrag | Umiddelbar kontekst for travle lesere | Plassert øverst for tidlig token-forbruk; 50–75 ord |
| Kundeoversikt | Rask identifikasjon av selskapets profil | Strukturert som: Bransje / Firmastørrelse / Lokasjon / Rolle |
| Forretningskontekst | Problembeskrivelse og markedssituasjon | Bruk konsekvent terminologi; unngå varianter og sjargong |
| Mål | Spesifikke, målbare mål kunden hadde | Formater som nummerert liste; inkluder kvantifiserte mål |
| Løsning | Hvordan produktet/tjenesten din adresserte behovet | Forklar eksplisitt koblingen funksjon–fordel |
| Implementering | Tidslinje, prosess og innføringsdetaljer | Del inn i faser; inkluder varighet og milepæler |
| Resultater | Kvantifiserte utfall og effektmålinger | Presenter som: Måling / Utgangspunkt / Endelig / Forbedring % |
| Bevis | Data, skjermbilder eller tredjepartsvalidering | Inkluder tabeller for målinger; siter kilder tydelig |
| Kundesitater | Autentisk stemme og følelsesmessig validering | Attribuer navn, tittel, selskap; 1–2 setninger hver |
| Gjenbrukssignaler | Intern lenking og krysspromotering | Foreslå relaterte case-studier, webinarer eller ressurser |
Denne strukturen sikrer at hver seksjon har et dobbelt formål: Den leses naturlig for mennesker, samtidig som den gir semantisk klarhet for RAG-systemer (Retrieval-Augmented Generation) som driver moderne LLM-er. Konsistensen i dette formatet på tvers av ditt casestudiebibliotek gjør det eksponentielt enklere for AI-systemer å trekke ut sammenlignbare datapunkter og sitere selskapet ditt med trygghet.
Utover struktur, vil spesifikke formateringsvalg du gjør dramatisk påvirke om AI-systemer faktisk finner og siterer dine case-studier. LLM-er prosesserer dokumenter annerledes enn mennesker—de “skummer” ikke eller bruker visuelle hierarkier slik lesere gjør, men de er svært sensitive for semantiske markører og konsistente mønstre. Her er formateringselementene som mest betydelig øker AI-henting:
Disse formateringsvalgene handler ikke om estetikk—de handler om å gjøre din case-studie maskinlesbar slik at når en LLM søker etter relevante bevispunkter, er det din selskaps historie som blir sitert.
Den mest sofistikerte tilnærmingen til AI-klare case-studier innebærer å bygge inn et JSON-skjema direkte i case-studiedokumentet eller metadata-laget, og skape en dobbeltlagstilnærming der mennesker leser fortellingen, mens maskiner tolker de strukturerte dataene. JSON-skjemaer gir LLM-er entydige, maskinlesbare representasjoner av nøkkelinformasjonen i case-studien, noe som dramatisk forbedrer nøyaktighet og relevans for sitering. Her er et eksempel på hvordan dette kan struktureres:
{
"@context": "https://schema.org",
"@type": "CaseStudy",
"name": "Enterprise SaaS Platform Reduserer Onboarding-tid med 60%",
"customer": {
"name": "TechCorp Industries",
"industry": "Finansielle tjenester",
"companySize": "500-1000 ansatte",
"location": "San Francisco, CA"
},
"solution": {
"productName": "Ditt Produktnavn",
"category": "Arbeidsflytautomatisering",
"implementationDuration": "8 uker"
},
"results": {
"metrics": [
{"name": "Reduksjon i onboarding-tid", "baseline": "120 dager", "final": "48 dager", "improvement": "60%"},
{"name": "Brukeradopsjonsrate", "baseline": "45%", "final": "89%", "improvement": "97%"},
{"name": "Reduksjon i supporthenvendelser", "baseline": "450/måned", "final": "120/måned", "improvement": "73%"}
]
},
"datePublished": "2024-01-15",
"author": {"@type": "Organization", "name": "Ditt Selskap"}
}
Ved å implementere schema.org-kompatible JSON-strukturer gir du LLM-er en standardisert måte å forstå og sitere case-studien din på. Denne tilnærmingen integreres sømløst med RAG-systemer, slik at AI-modeller kan trekke ut presise målinger, forstå kundekontekst og attribuere sitater tilbake til selskapet ditt med høy presisjon. Selskaper som bruker JSON-strukturerte case-studier opplever 3–4 ganger høyere siteringsnøyaktighet i AI-genererte svar sammenlignet med kun fortellende formater.
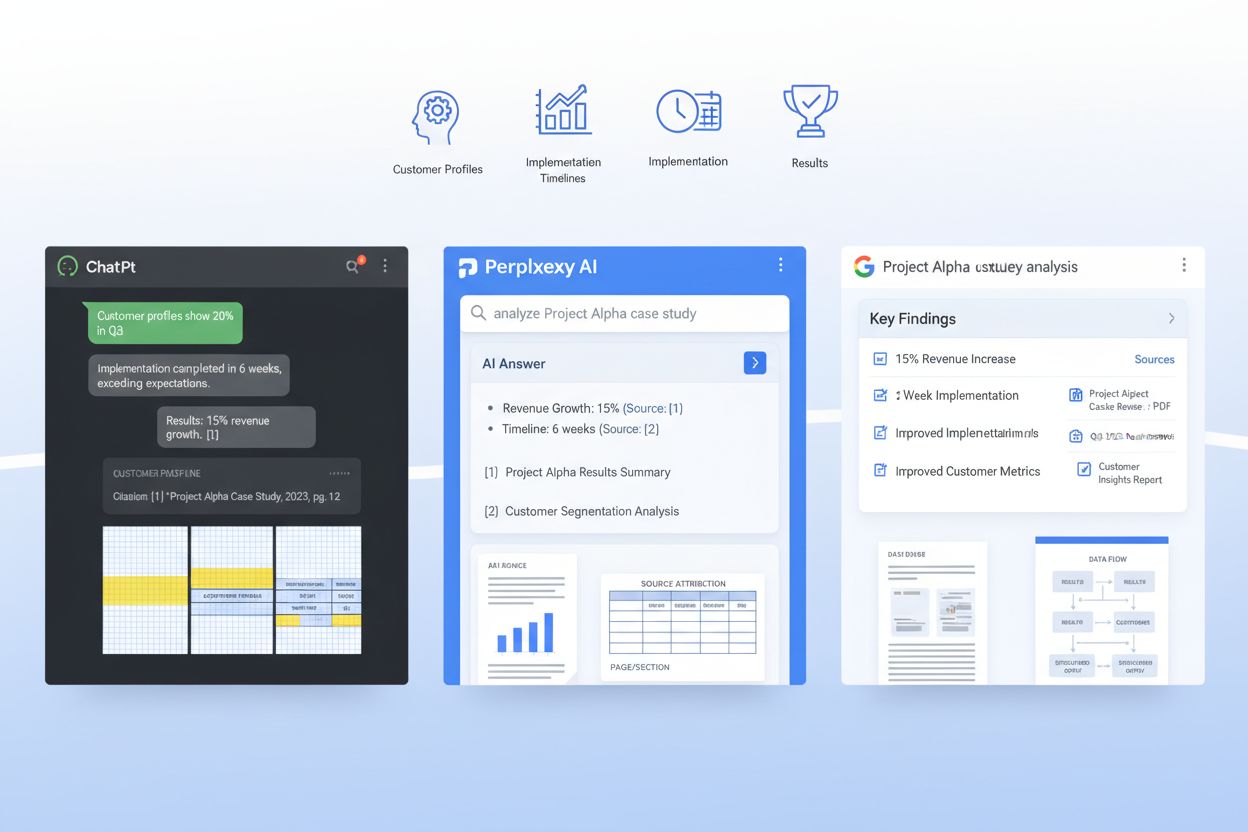
RAG-systemer prosesserer ikke hele case-studien din som én stor blokk—de deler den inn i semantiske deler som får plass i en LLMs kontekstvindu, og hvordan du strukturerer dokumentet avgjør direkte om disse delene er nyttige eller fragmenterte. Effektiv chunking betyr å organisere case-studien slik at naturlige semantiske grenser sammenfaller med hvordan RAG-systemet deler innholdet. Dette krever bevisst avsnittsstørrelse: hvert avsnitt bør fokusere på én idé eller datapunkt, typisk 100–150 ord, slik at når et RAG-system trekker ut et chunk, inneholder det komplett, sammenhengende informasjon i stedet for løsrevne setninger. Narrativ separasjon er kritisk—bruk tydelige seksjonsbrudd mellom problemstilling, løsningsbeskrivelse og resultater slik at en LLM kan hente “resultatseksjonen” som en helhet uten å blande den med implementeringsdetaljer. I tillegg er tokeneffektivitet viktig: Ved å bruke tabeller for målinger i stedet for prosa, reduserer du antall token som trengs for å overføre samme informasjon, slik at LLM-er kan inkludere mer av case-studien din i svaret uten å nå kontekstgrensen. Målet er å gjøre din case-studie “RAG-vennlig” slik at hvert chunk et AI-system trekker ut er selvstendig verdifullt og riktig kontekstualisert.
Publisering av case-studier for AI-systemer krever at man balanserer den spesifisiteten som gjør dem troverdige med konfidensialitetsforpliktelsene overfor kundene dine. Mange selskaper nøler med å publisere detaljerte case-studier fordi de frykter å utlevere sensitiv forretningsinformasjon, men strategisk sladding og anonymisering lar deg opprettholde både åpenhet og tillit. Den mest effektive tilnærmingen innebærer å lage flere versjoner av hver case-studie: en fullt detaljert intern versjon med kundens navn, nøyaktige målinger og proprietære detaljer, og en offentlig AI-optimalisert versjon som anonymiserer kunden, men bevarer kvantifisert effekt og strategisk innsikt. For eksempel, i stedet for “TechCorp Industries sparte 2,3 millioner dollar årlig,” kan du publisere “Mellomstort finansselskap reduserte driftskostnader med 34 %"—målingen er fortsatt spesifikk nok til at LLM-er kan sitere den, men kundens identitet er beskyttet. Versjonskontroll og etterlevelsessporing er essensielt: Hold klare oversikter over hva som er sladdet, hvorfor og når, slik at ditt casestudiebibliotek alltid er revisjonsklart. Denne styringstilnærmingen styrker faktisk din AI-siteringsstrategi fordi den lar deg publisere flere case-studier oftere uten juridisk friksjon, slik at LLM-er får flere bevispunkter å oppdage og sitere.
Før du publiserer en case-studie, valider at den faktisk fungerer godt når den prosesseres av LLM-er og RAG-systemer—ikke anta at god formatering automatisk gir god AI-ytelse. Testing av case-studier mot ekte AI-systemer avdekker om struktur, metadata og innhold faktisk muliggjør nøyaktig sitering og henting. Her er fem essensielle testtilnærminger:
Relevanssjekk: Matar inn case-studien din i ChatGPT, Perplexity eller Claude med spørsmål relatert til din løsningskategori. Henter og siterer AI-systemet case-studien din når det besvarer relevante spørsmål?
Sammendragsnøyaktighet: Be en LLM oppsummere case-studien din og verifiser at sammendraget fanger opp nøkkeltall, kundekontekst og forretningspåvirkning uten forvrengning eller hallusinasjon.
Måleuttrekk: Test om AI-systemet kan trekke ut spesifikke tall fra din case-studie (f.eks. “Hva var forbedringen i time-to-value?”). Tabeller bør gi over 96 % nøyaktighet; prosa bør testes separat.
Attribusjonslojalitet: Verifiser at når LLM-en siterer din case-studie, attribueres informasjonen riktig til ditt selskap og kunde, ikke til en konkurrent eller generisk kilde.
Randspørsmål: Test med uvanlige eller marginale spørsmål for å sikre at case-studien din ikke brukes feil til brukstilfeller den egentlig ikke dekker.
Disse testene bør kjøres kvartalsvis ettersom LLM-adferd utvikler seg, og resultatene bør informere oppdateringer av formatering og struktur på dine case-studier.
Å måle effekten av AI-optimaliserte case-studier krever at du sporer både AI-relaterte målinger (hvor ofte dine case-studier siteres av LLM-er) og menneskelige målinger (hvordan disse sitatene påvirker faktiske avtaler). På AI-siden bruker du AmICited.com for å overvåke siteringshyppighet i ChatGPT, Perplexity og Google AI Overviews—spor hvor ofte selskapet ditt dukker opp i AI-genererte svar på relevante spørsmål, og mål om siteringshyppigheten øker etter at du publiserer nye AI-optimaliserte case-studier. Etabler din nåværende siteringsrate, og sett et mål om å øke sitater med 40–60 % innen seks måneder etter implementering av AI-klare formater. På menneskesiden korrelerer du økning i AI-sitater med nedstrøms målinger: spor hvor mange avtaler som nevner “Jeg fant dere i et AI-søk” eller “en AI anbefalte deres case-studie,” mål forbedring i gevinstsrate i avtaler der din case-studie ble sitert av et AI-system (mål: 28–40 % forbedring over 21 % baseline), og følg med på forkortet salgssyklus i konti der prospekter fant din case-studie via AI. Overvåk også SEO-målinger—AI-optimaliserte case-studier med riktig skjema-markup rangerer ofte bedre i tradisjonelt søk, og gir dobbel gevinst. Kvalitativ tilbakemelding fra salgsavdelingen er like viktig: Spør om prospekter kommer med dypere produktkunnskap, og om case-studie-sitater reduserer tid brukt på innsigelser. Den ultimate KPI-en er inntekt: Spor mer-ARR knyttet til avtaler påvirket av AI-siterte case-studier, og du får et klart ROI-grunnlag for videre investeringer i dette formatet.
Å optimalisere case-studier for AI-sitater gir kun avkastning hvis prosessen blir operasjonalisert og repeterbar, ikke et engangsprosjekt. Start med å kode inn din AI-klare case-studie-mal i et standardformat som markeds- og salgsteamet bruker for hver nye kundehistorie—dette sikrer konsistens i hele biblioteket ditt og reduserer tiden det tar å publisere nye case-studier. Integrer malen i CMS-et eller innholdssystemet slik at publisering av en ny case-studie automatisk genererer JSON-skjema, metadata-overskrifter og formateringselementer uten manuelt arbeid. Gjør case-studieproduksjon til en kvartalsvis eller månedlig rutine, ikke en årlig hendelse, fordi LLM-er oppdager og siterer selskaper med dypere og ferskere casestudiebibliotek oftere. Posisjoner case-studier som en kjernekomponent i din bredere inntektsstrategi: de bør brukes i salgsmateriell, produktmarkedsføring, etterspørselsgenerering og kundesuksess. Til slutt, etabler en kontinuerlig forbedringssløyfe der du overvåker hvilke case-studier som får flest AI-sitater, hvilke målinger som gir best gjenklang hos LLM-er, og hvilke kundesegmenter som hyppigst siteres—og bruk innsikten til å styre neste generasjon case-studier. Selskapene som vinner i AI-æraen skriver ikke bare bedre case-studier; de behandler case-studier som strategiske inntektsressurser som krever kontinuerlig optimalisering, måling og forbedring.
Start med å trekke ut tekst fra dine PDF-er og kartlegg eksisterende innhold til et standard skjema med felt som kundens profil, utfordring, løsning og resultater. Lag deretter en lett HTML- eller CMS-versjon av hver historie med tydelige overskrifter og metadata, og behold den originale PDF-en som en nedlastbar ressurs i stedet for hovedkilden for AI-henting.
Markedsføring eller produktmarkedsføring eier vanligvis historien, men salg, løsningsingeniører og kundesuksess bør bidra med rådata, implementeringsdetaljer og validering. Juridiske, personvern- og RevOps-team hjelper til med å sikre styring, riktig sladding og samsvar med eksisterende systemer som CRM og salgsstøtteplattformer.
Et headless CMS eller en strukturert innholdsplattform er ideell for lagring av skjemaer og metadata, mens et CRM eller salgsstøtteverktøy kan gjøre riktige historier tilgjengelige i arbeidsflyten. For AI-henting kombinerer du vanligvis en vektordatabse med et LLM-orkestreringslag som LangChain eller LlamaIndex.
Transkriber videoanbefalinger og webinarer, og merk deretter transkriptene med de samme feltene og seksjonene som dine skriftlige case-studier slik at AI kan sitere dem. For grafikk og diagrammer, inkluder korte alt-tekster eller bildetekster som beskriver hovedinnsikten slik at hente-modeller kan koble visuelle ressurser til spesifikke spørsmål.
Hold kjerneskjemaet og ID-ene konsistente globalt, og lag deretter oversatte varianter som lokaliserer språk, valuta og regulatorisk kontekst samtidig som kanoniske måledata bevares. Lagre lokale versjoner som separate, men lenkede objekter slik at AI-systemer kan prioritere svar på brukerens språk uten å fragmentere datamodellen din.
Gå gjennom case-studier med stor innvirkning minst årlig, eller tidligere hvis det er større produktendringer, nye nøkkeltall eller endringer i kundekonteksten. Bruk en enkel versjonsprosedyre med sist-gjennomgått-datoer og statusflagg for å signalisere til AI-systemer og mennesker hvilke historier som er mest oppdaterte.
Integrer henting av case-studier direkte i verktøyene representantene allerede bruker og lag konkrete spillbøker som viser hvordan man ber assistenten om relevante bevis. Forsterk bruken ved å dele suksesshistorier der tilpassede, AI-fremhevede case-studier hjalp med å lukke avtaler raskere eller nå nye beslutningstakere.
Tradisjonelle case-studier er skrevet for menneskelige lesere med narrativ flyt og visuell design. AI-optimaliserte case-studier beholder dette, men legger til strukturert metadata, konsistent formatering, JSON-skjemaer og semantisk klarhet som gjør at LLM-er kan trekke ut, forstå og sitere spesifikk informasjon med over 96 % nøyaktighet.
Spor hvordan AI-systemer siterer merkevaren din i ChatGPT, Perplexity og Google AI Overviews. Få innsikt i din AI-synlighet og optimaliser innholdsstrategien din.
Lær hvordan casestudier rangerer i AI-søkemotorer som ChatGPT, Perplexity og Google AI Overviews. Oppdag hvorfor AI-systemer siterer casestudier som autoritativ...
Diskusjon i fellesskapet om hvordan case-studier presterer i AI-søkeresultater. Reelle erfaringer fra markedsførere som sporer case-studie-sitater i ChatGPT, Pe...
Oppdag hvordan Smart Rent genererte 345 % flere leads gjennom AI-sitater. Ekte casestudie som viser B2B lead-genereringsstrategi, resultater og implementeringst...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.