
Hva er RAG i AI-søk: Komplett guide til Retrieval-Augmented Generation
Lær hva RAG (Retrieval-Augmented Generation) er i AI-søk. Oppdag hvordan RAG forbedrer nøyaktighet, reduserer hallusinasjoner og driver ChatGPT, Perplexity og G...
7 min lesing

Oppdag hvordan Retrieval-Augmented Generation forvandler AI-sitater, muliggjør nøyaktig kildehenvisning og forankrede svar på tvers av ChatGPT, Perplexity og Google AI Overviews.
Store språkmodeller har revolusjonert AI, men de har en kritisk svakhet: kunnskapsbegrensninger. Disse modellene trenes på data frem til et bestemt tidspunkt, noe som betyr at de ikke kan få tilgang til informasjon etter denne datoen. I tillegg til foreldet informasjon, lider tradisjonelle LLM-er av hallusinasjoner—de genererer selvsikkert feilinformasjon som høres plausibel ut—og gir ingen kildehenvisning for sine påstander. Når en bedrift trenger oppdatert markedsdata, proprietær forskning eller verifiserbare fakta, kommer tradisjonelle LLM-er til kort og etterlater brukerne med svar de ikke kan stole på eller verifisere.
Retrieval-Augmented Generation (RAG) er et rammeverk som kombinerer den generative kraften til LLM-er med presisjonen til informasjonshentingssystemer. I stedet for å kun stole på treningsdata, henter RAG-systemer relevant informasjon fra eksterne kilder før de genererer svar, og skaper en prosess som forankrer svarene i faktiske data. De fire kjernekomponentene arbeider sammen: Inntak (konverterer dokumenter til søkbare formater), Henting (finner de mest relevante kildene), Augmentering (beriker prompten med hentet kontekst), og Generering (lager det endelige svaret med sitater). Slik sammenlignes RAG med tradisjonelle tilnærminger:
| Aspekt | Tradisjonell LLM | RAG-system |
|---|---|---|
| Kilde til kunnskap | Statisk treningsdata | Eksterne indekserte kilder |
| Siteringsevne | Ingen/hallusinert | Sporbar til kilder |
| Nøyaktighet | Feilutsatt | Forankret i fakta |
| Sanntidsdata | Nei | Ja |
| Hallusinasjonsrisiko | Høy | Lav |
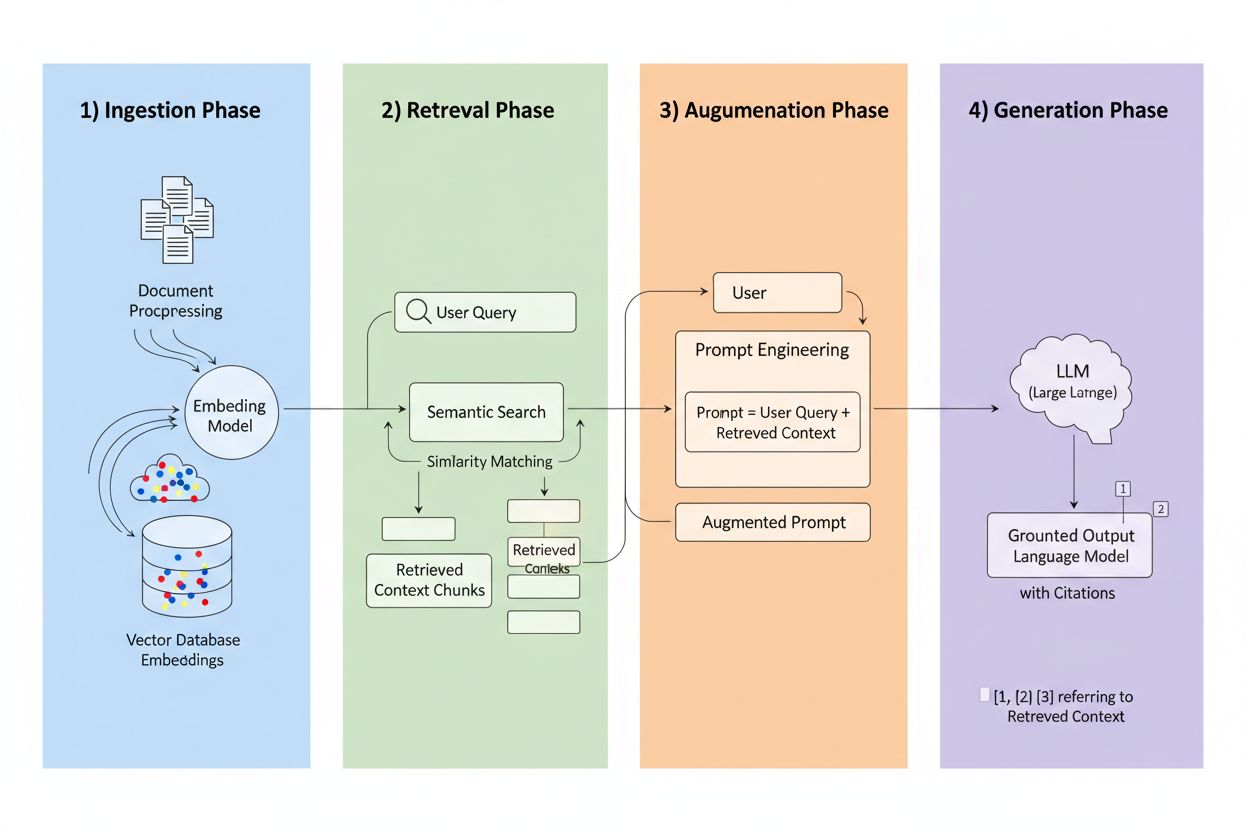
Hentemotoren er hjertet av RAG, og langt mer sofistikert enn enkel nøkkelordmatching. Dokumenter konverteres til vektorembeddinger—matematiske representasjoner som fanger semantisk mening—slik at systemet kan finne konseptuelt lignende innhold selv når de eksakte ordene ikke samsvarer. Systemet deler dokumentene opp i håndterbare biter, vanligvis 256–1024 tokens, for å balansere kontekstbevaring med presis henting. De mest avanserte RAG-systemene bruker hybridsøk, som kombinerer semantisk likhet med tradisjonell nøkkelordmatching for å fange både konseptuelle og eksakte treff. En reranking-mekanisme rangerer deretter kandidatene, ofte ved hjelp av cross-encoder-modeller som vurderer relevans mer nøyaktig enn den innledende hentingen. Relevans beregnes gjennom flere signaler: semantiske likhetspoeng, nøkkelordoverlapp, metadata-matching og domenemyndighet. Hele prosessen skjer på millisekunder og sikrer brukerne raske, nøyaktige svar uten merkbar ventetid.
Her forvandler RAG siteringslandskapet: når et system henter informasjon fra en spesifikk indeksert kilde, blir denne kilden sporbar og verifiserbar. Hver tekstbit kan spores tilbake til sitt opprinnelige dokument, URL eller publikasjon, noe som gjør sitering automatisk i stedet for hallusinert. Dette grunnleggende skiftet gir enestående åpenhet i AI-beslutninger—brukere kan se nøyaktig hvilke kilder som har informert svaret, verifisere påstander selvstendig og selv vurdere kildens troverdighet. I motsetning til tradisjonelle LLM-er, hvor sitater ofte er oppdiktede eller generiske, er RAG-sitater forankret i faktiske hentehendelser. Denne sporbarheten øker brukertilliten dramatisk, da folk kan validere informasjonen istedenfor å akseptere den på tro og ære. For innholdsskapere og utgivere betyr dette at arbeidet deres kan oppdages og krediteres gjennom AI-systemer, og åpner helt nye synlighetskanaler.
Ikke alle kilder er like i RAG-systemer, og flere faktorer avgjør hvilket innhold som blir hyppigst sitert:
Hver faktor forsterker de andre—en godt strukturert, hyppig oppdatert artikkel fra et autoritativt domene med sterke tilbakekoblinger og tilstedeværelse i kunnskapsgrafer blir en siteringsmagnet i RAG-systemer. Dette skaper et nytt optimaliseringsparadigme hvor synlighet avhenger mindre av SEO for trafikk, og mer av å bli en pålitelig, strukturert informasjonskilde.
Ulike AI-plattformer implementerer RAG med ulike strategier, noe som gir varierende siteringsmønstre. ChatGPT vektlegger Wikipedia-kilder høyt, med studier som viser at omtrent 26–35 % av sitatene kommer fra Wikipedia alene, noe som reflekterer autoritet og strukturert format. Google AI Overviews benytter et mer variert kildeutvalg og trekker fra nyhetssider, vitenskapelige artikler og forum, med Reddit i omtrent 5 % av sitatene til tross for lavere tradisjonell autoritet. Perplexity AI siterer vanligvis 3–5 kilder per svar og viser sterk preferanse for bransjespesifikke publikasjoner og ferske nyheter, noe som optimaliserer for grundighet og aktualitet. Disse plattformene vektlegger domenemyndighet forskjellig—noen prioriterer tradisjonelle indikatorer som tilbakekoblinger og domenets alder, mens andre fokuserer på innholdsfriskhet og semantisk relevans. Å forstå disse plattformspesifikke hentestrategiene er avgjørende for innholdsskapere, da optimalisering for én plattforms RAG-system kan avvike betydelig fra en annens.
Fremveksten av RAG forstyrrer grunnleggende SEO-visdom. I søkemotoroptimalisering henger siteringer og synlighet direkte sammen med trafikk—du må ha klikk for å bety noe. RAG snur denne ligningen på hodet: innhold kan bli sitert og påvirke AI-svar uten å drive noe trafikk. En godt strukturert, autoritativ artikkel kan dukke opp i dusinvis av AI-svar daglig og samtidig få null klikk, da brukerne får svaret direkte fra AI-oppsummeringen. Dette betyr at autoritetssignaler er viktigere enn noen gang, da de er den primære mekanismen RAG-systemer bruker for å vurdere kildekvalitet. Konsistens på tvers av plattformer blir kritisk—hvis innholdet ditt finnes på nettsiden din, LinkedIn, bransjedatabaser og kunnskapsgrafer, ser RAG-systemene forsterkede autoritetssignaler. Tilstedeværelse i kunnskapsgrafer går fra å være et “kjekt å ha” til essensiell infrastruktur, da disse strukturerte databasene er hovedkilder for mange RAG-implementeringer. Siteringsspillet har fundamentalt endret seg fra “få trafikk” til “bli en pålitelig informasjonskilde”.
For å maksimere RAG-sitater må innholdsstrategien skifte fra trafikkoptimalisering til kildeoptimalisering. Implementer oppdateringssykluser på 48–72 timer for tidløst innhold, og signaliser til hentesystemene at informasjonen din er oppdatert. Bruk strukturert datamerking (Schema.org, JSON-LD) for å hjelpe systemene å tolke og forstå innholdets betydning og relasjoner. Tilpass innholdet semantisk til vanlige spørsmålsmønstre—bruk naturlig språk som samsvarer med hvordan folk stiller spørsmål, ikke bare hvordan de søker. Formater innhold med FAQ- og Q&A-seksjoner, da disse direkte matcher spørsmål–svar-mønsteret RAG-systemer benytter. Utvikle eller bidra til Wikipedia- og kunnskapsgrafoppføringer, da disse er hovedkilder for de fleste plattformer. Bygg tilbakekoblingsautoritet gjennom strategiske partnerskap og siteringer fra andre autoritative kilder, siden lenkeprofiler fortsatt er sterke autoritetssignaler. Til slutt, oppretthold konsistens på tvers av plattformer—sørg for at dine viktigste påstander, data og budskap er i samsvar på nettsiden din, sosiale profiler, bransjedatabaser og kunnskapsgrafer, og dermed skaper forsterkede pålitelighetssignaler.
RAG-teknologien utvikler seg raskt, med flere trender som omformer hvordan siteringer fungerer. Mer avanserte hentealgoritmer vil bevege seg forbi semantisk likhet og mot dypere forståelse av spørsmålsintensjon og kontekst, noe som forbedrer siteringsrelevansen. Spesialiserte kunnskapsbaser vil dukke opp for spesifikke domener—medisinske RAG-systemer som bruker kuraterte medisinske publikasjoner, juridiske systemer som bruker rettspraksis og lovverk—og skaper nye siteringsmuligheter for autoritative domenekilder. Integrasjon med multi-agent-systemer vil gjøre det mulig for RAG å orkestrere flere spesialiserte hentesystemer, kombinere innsikt fra forskjellige kunnskapsbaser for mer omfattende svar. Sanntidsdata-tilgang vil forbedres dramatisk, og tillate RAG-systemer å inkludere liveinformasjon fra API-er, databaser og strømmetjenester. Agentisk RAG—hvor AI-agenter autonomt bestemmer hva de skal hente, hvordan det skal behandles og når de skal iterere—vil skape mer dynamiske siteringsmønstre, og potensielt sitere kilder flere ganger mens agentene finpusser resonnementet.
Etter hvert som RAG former hvordan AI-systemer oppdager og siterer kilder, blir forståelse av din siteringsprestasjon essensiell. AmICited overvåker AI-sitater på tvers av plattformer, og sporer hvilke av dine kilder som vises i ChatGPT, Google AI Overviews, Perplexity og nye AI-systemer. Du får innsikt i hvilke spesifikke kilder som blir sitert, hvor ofte de dukker opp og i hvilken kontekst—og avslører hvilket innhold som treffer hos RAG-hentealgoritmer. Plattformen vår hjelper deg å forstå siteringsmønstre på tvers av innholdsporteføljen din, og identifiserer hva som gjør enkelte artikler siteringsverdige og andre usynlige. Mål merkevarens synlighet i AI-svar med metrikker som betyr noe i RAG-æraen, og gå utover tradisjonell trafikkstatistikk. Gjennomfør konkurranseanalyse av siteringsprestasjon, og se hvordan dine kilder står seg mot konkurrenter i AI-genererte svar. I en verden der AI-sitater driver synlighet og autoritet, er klar innsikt i siteringsytelsen ikke valgfritt—det er slik du forblir konkurransedyktig.
Tradisjonelle LLM-er er avhengige av statiske treningsdata med kunnskapsbegrensninger og har ikke tilgang til sanntidsinformasjon, noe som ofte resulterer i hallusinasjoner og ikke-verifiserbare påstander. RAG-systemer henter informasjon fra eksterne indekserte kilder før de genererer svar, noe som muliggjør nøyaktige sitater og forankrede svar basert på oppdatert, verifiserbar data.
RAG sporer hvert hentet informasjonsstykke tilbake til den opprinnelige kilden, slik at sitater blir automatiske og verifiserbare i stedet for hallusinert. Dette skaper en direkte kobling mellom svaret og kildematerialet, slik at brukerne kan verifisere påstander selvstendig og vurdere kildens troverdighet.
RAG-systemer vurderer kilder basert på autoritet (domenets omdømme og tilbakekoblinger), aktualitet (innhold oppdatert innen 48-72 timer), semantisk relevans til spørsmålet, innholdsstruktur og klarhet, faktatetthet med spesifikke datapunkter, og tilstedeværelse i kunnskapsgrafer som Wikipedia. Disse faktorene virker sammen for å avgjøre sannsynligheten for sitering.
Oppdater innholdet hvert 48-72. time for å opprettholde friskhetssignaler, implementer strukturert datamerking (Schema.org), tilpass innholdet semantisk til vanlige spørsmål, bruk FAQ- og Q&A-format, utvikle Wikipedia- og kunnskapsgraftilstedeværelse, bygg autoritet gjennom tilbakekoblinger, og oppretthold konsistens på tvers av alle plattformer.
Kunnskapsgrafer som Wikipedia og Wikidata er primære hentekilder for de fleste RAG-systemer. Tilstedeværelse i disse strukturerte databasene øker siteringssannsynligheten dramatisk og gir grunnleggende tillitssignaler som AI-systemer refererer til gjentatte ganger på tvers av ulike spørsmål.
Innhold bør oppdateres hver 48-72. time for å opprettholde sterke aktualitetssignaler i RAG-systemer. Dette krever ikke fullstendig omskriving – det holder å legge til nye datapunkter, oppdatere statistikk eller utvide seksjoner med nylige utviklinger for å opprettholde siteringsberettigelse.
Domenemyndighet fungerer som en pålitelighetsindikator i RAG-algoritmer og utgjør omtrent 5 % av siteringssannsynligheten. Den vurderes gjennom domenets alder, SSL-sertifikater, tilbakekoblingsprofiler, ekspertattributter og tilstedeværelse i kunnskapsgrafer, som alle virker sammen for å påvirke kildeutvalget.
AmICited sporer hvilke av dine kilder som vises i AI-genererte svar på tvers av ChatGPT, Google AI Overviews, Perplexity og andre plattformer. Du får oversikt over siteringsfrekvens, kontekst og konkurranseytelse, slik at du forstår hva som gjør innhold siteringsverdig i RAG-æraen.
Forstå hvordan merkevaren din vises i AI-genererte svar på tvers av ChatGPT, Perplexity, Google AI Overviews og mer. Spor siteringsmønstre, mål synlighet og optimaliser tilstedeværelsen din i det AI-drevne søkelandskapet.
Lær hva RAG (Retrieval-Augmented Generation) er i AI-søk. Oppdag hvordan RAG forbedrer nøyaktighet, reduserer hallusinasjoner og driver ChatGPT, Perplexity og G...
Lær hvordan RAG kombinerer LLM-er med eksterne datakilder for å generere nøyaktige AI-svar. Forstå femstegsprosessen, komponentene og hvorfor det er viktig for ...

Lær hva Retrieval-Augmented Generation (RAG) er, hvordan det fungerer, og hvorfor det er essensielt for nøyaktige AI-svar. Utforsk RAG-arkitektur, fordeler og b...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.