
Slik Gjenbruker Du Innhold for AI-Plattformer og Øker AI-siteringer
Lær hvordan du kan gjenbruke og optimalisere innhold for AI-plattformer som ChatGPT, Perplexity og Claude. Oppdag strategier for AI-synlighet, innholdsstrukture...
11 min lesing

Lær hvordan gjenpublisering av innhold skaper problemer med duplisert innhold som skader AI-synlighet mer alvorlig enn tradisjonelt søk. Oppdag tekniske sikringstiltak og beste praksis.
Å gjenpublisere innhold på flere kanaler, plattformer og formater er en legitim og ofte nødvendig strategi for å maksimere rekkevidde og engasjement. Men denne praksisen skaper en grunnleggende spenning med hvordan søkesystemer—særlig de som er drevet av AI—prosesserer og rangerer innhold. Utfordringen er ikke om du kan gjenpublisere; det handler om du gjør det på en måte som ikke saboterer synligheten din i AI-søkeresultater. I motsetning til tradisjonelle søkemotorer som over tid har utviklet sofistikerte mekanismer for å oppdage duplikater, håndterer AI-systemer duplisert innhold annerledes og skaper nye risikoer som mange utgivere ennå ikke har tilpasset seg til.
I følge Microsofts tekniske dokumentasjon om Copilot og AI-søk, “LLM-er grupperer nesten identiske URL-er i én enkelt klynge og velger så én side som representant for settet.” Denne klyngeatferden er fundamentalt forskjellig fra hvordan Googles PageRank-algoritme fordeler autoritet mellom dupliserte sider. I stedet for å konsolidere signaler, tar AI-systemer en binær avgjørelse: de velger én representativ side fra en klynge av lignende innhold og ignorerer i stor grad de andre. Denne utvelgelsen er ikke alltid forutsigbar eller basert på den versjonen du helst vil ha rangert. Algoritmen vurderer faktorer som aktualitet, innholdskvalitet, tekniske signaler og domenemyndighet—men vektingen av disse faktorene er uklar. Det som gjør dette spesielt problematisk er at AI-systemer kan velge en utdatert versjon hvis forskjellene mellom sidene er små nok til at klyngealgoritmen ikke oppfatter meningsfulle variasjoner.
| Aspekt | Tradisjonelt søk | AI-søk |
|---|---|---|
| Håndtering av duplikater | Konsoliderer autoritetssignaler | Klynge og velger én representant |
| Risiko for straff | Mulig manuell handling | Ingen straff, men utvanning av synlighet |
| Gjenkjenning av oppdateringer | Gradvis signaloverføring | Kan overse oppdateringer hvis forskjellene er små |
| Crawl-effektivitet | Sløser budsjett på duplikater | Redusert crawl-prioritet for duplikater |
| Kanonisk respekt | Respekteres, men ikke garantert | Kritisk for klyngevalg |
Gjenpublisering uten riktige sikringstiltak introduserer tre sammenhengende risikoer som direkte påvirker AI-synlighet:
Utvanning av intentsignal: Når det samme innholdet vises på flere URL-er, får AI-systemet motstridende signaler om hvilken versjon som best svarer på brukerens spørsmål. I stedet for å konsentrere autoritet på én URL, spres signalene over klyngen. Denne utvanningen reduserer tillitsscoren AI-systemene gir innholdet ditt når de avgjør om det skal inkluderes i svar. Innhold som kunne vært en primærkilde, blir en sekundær vurdering fordi systemet ikke trygt kan fastslå hvilken versjon som er autoritativ.
Representasjonsrisiko: AI-systemets valg av hvilken side som representerer innholdsklyngen din, stemmer kanskje ikke med dine forretningsmål. Du kan gjenpublisere et blogginnlegg til et syndikeringsnettverk i forventning om at den versjonen skal drive trafikk, men AI-systemet velger kanskje din opprinnelige domeneversjon—eller enda verre, den syndikerte versjonen som ikke lenker tilbake til ditt nettsted. Denne skjevheten gjør at gjenpubliseringsstrategien din motarbeider synlighetsmålene dine i stedet for å forsterke dem.
Oppdateringslatens og foreldelse: Når du oppdaterer ditt opprinnelige innhold, men de gjenpubliserte versjonene forblir uendret, kan AI-systemer velge en utdatert versjon som representativ side. Klyngealgoritmen oppdager ikke alltid at én versjon er nyere eller mer nøyaktig enn de andre, spesielt hvis endringene er inkrementelle og ikke strukturelle. Dette skaper et scenario der ditt mest oppdaterte og korrekte innhold er usynlig, mens en eldre versjon representerer din ekspertise overfor AI-systemer.
Den vanligste feilen ved gjenpublisering oppstår når innhold syndikeres til tredjepartsplattformer uten bruk av kanoniske tagger. Tenk deg et typisk scenario: et B2B programvareselskap publiserer en omfattende guide på sin blogg, og syndikerer den deretter til bransjepublikasjoner som Medium, LinkedIn og spesialiserte nyhetsaggregatorer. Hver plattform har identisk innhold under ulike URL-er. Uten kanoniske tagger som peker tilbake til originalen, behandler AI-systemets klyngealgoritme alle versjoner som like autoritative. Syndikeringsplattformen kan ha høyere domenemyndighet, og AI-systemet velger dermed den versjonen som representativ side. Nå blir ditt opprinnelige innhold—versjonen du har optimalisert, oppdatert og fått lenker til—usynlig i AI-søkeresultater. Trafikken og autoriteten går til syndikeringsplattformen i stedet for ditt eget nettsted. Dette scenariet gjentar seg tusenvis av ganger daglig i forlagsbransjen, der utgivere uforvarende saboterer sin egen synlighet ved å unnlate å implementere én enkelt HTML-tag.
Kampanjespesifikt innhold skaper et spesielt vanskelig problem med duplisert innhold når det gjenpubliseres på tvers av kanaler. Et markedsføringsteam lanserer en kampanjeside optimalisert for en bestemt kampanje, og gjenpubliserer så variasjoner av innholdet til nyhetsbrev, sosiale medier, betalte annonser og partnersider. Hver versjon har litt forskjellig tekst, CTA-er eller formatering—men kjernen og hensikten er identisk. AI-systemer gjenkjenner disse som nær-duplikater og klynger dem sammen. Problemet forsterkes når kampanjesider gjenpubliseres uten skikkelig kanonisk implementering. AI-systemet kan velge nyhetsbrevversjonen (uten konverteringssporing) som representativ side, eller partnersideversjonen som ikke gagner dine måltall. Og når kampanjene avsluttes og sidene blir arkivert eller slettet, kan AI-systemet allerede ha valgt en nå utgått versjon som representativ side, slik at innholdet ditt blir usynlig eller leder brukere til en ødelagt opplevelse.
Regional gjenpublisering tilfører kompleksitet fordi duplikatdeteksjon må ta hensyn til legitime lokaliseringsbehov. Et selskap med virksomhet i flere land kan publisere det samme innholdet på forskjellige språk eller med regionsspesifikke tilpasninger. Uten korrekt implementering konkurrerer disse regionale versjonene med hverandre i AI-klyngen. Tenk på et SaaS-selskap som publiserer en funksjonsguide på engelsk på sitt amerikanske domene, og så gjenpubliserer den til sitt britiske domene med britisk engelsk og lokale priser. AI-systemet klynger dette som duplikater og kan velge US-versjonen selv for britiske brukere. Løsningen krever bruk av hreflang-tagger som signaliserer regionale forhold til AI-systemene, selv om effekten av hreflang i AI-søk er mindre dokumentert enn i tradisjonelt søk.
<!-- På US-versjonen (example.com/feature-guide) -->
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
<!-- På UK-versjonen (example.co.uk/feature-guide) -->
<link rel="alternate" hreflang="en-GB" href="https://example.co.uk/feature-guide" />
<link rel="alternate" hreflang="en-US" href="https://example.com/feature-guide" />
<link rel="alternate" hreflang="x-default" href="https://example.com/feature-guide" />
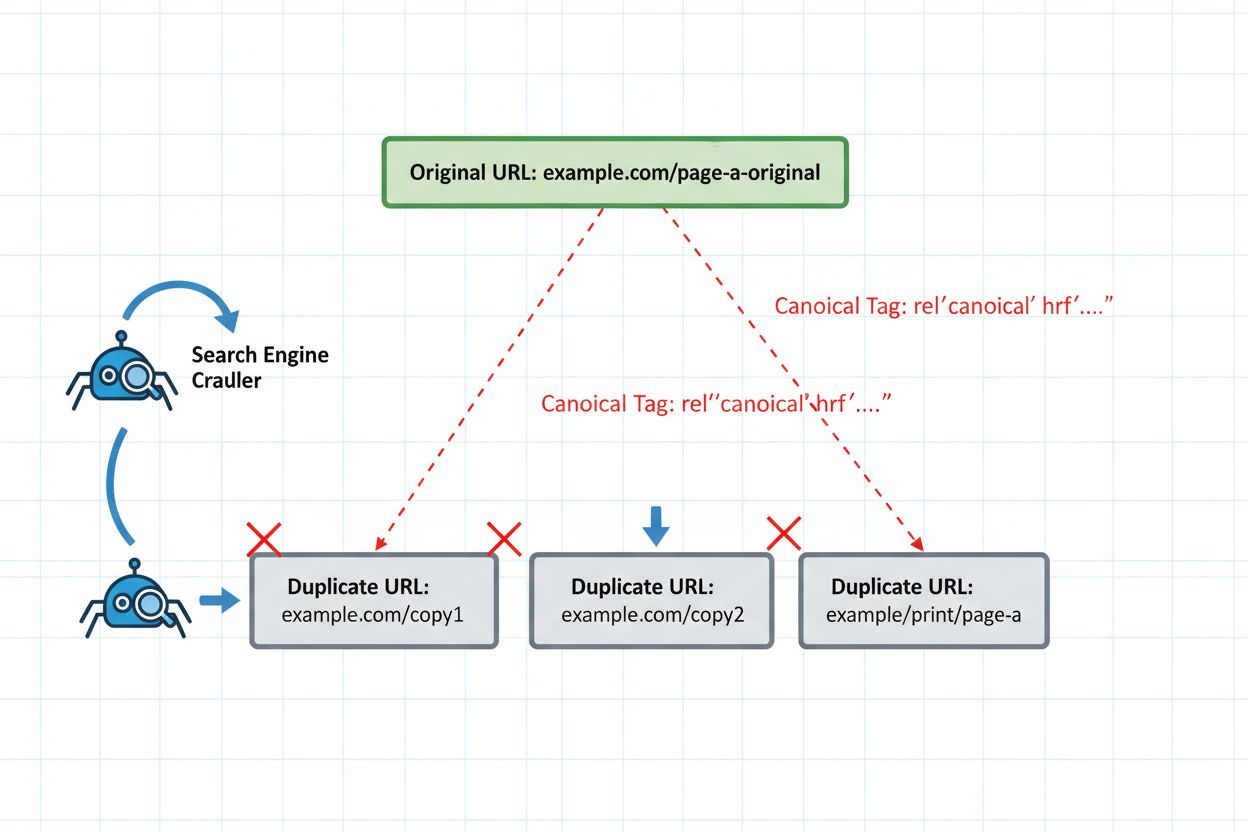
Å implementere riktige tekniske sikringstiltak er helt nødvendig for trygg gjenpublisering. Den kanoniske taggen er fortsatt ditt viktigste forsvar og forteller AI-systemene eksplisitt hvilken versjon som skal representere ditt innholdskluster. Plasser kanonisk tag i <head>-seksjonen på hver gjenpublisert versjon, og pek til din foretrukne autoritative versjon. For syndikert innhold betyr dette vanligvis å peke tilbake til ditt opprinnelige domene.
<!-- På syndikert versjon (medium.com/your-publication/article) -->
<link rel="canonical" href="https://yoursite.com/blog/article" />
For innhold som aldri skal konkurrere med andre versjoner, implementer noindex på sekundære versjoner. Dette fjerner dem fullstendig fra AI-indeksering og sørger for at de ikke kan velges som representativ side. Bruk denne tilnærmingen for interne duplikatsider, testversjoner eller syndikert innhold der du ønsker null synlighet i AI-søk.
<!-- På sekundær versjon som ikke skal indekseres -->
<meta name="robots" content="noindex, follow" />
301-videresendinger gir det sterkeste signalet for å konsolidere autoritet, men bruk det bare når den sekundære versjonen aldri skal oppdateres uavhengig. Videresending forteller AI-systemene at den gamle URL-en permanent er flyttet, og konsoliderer alle signaler til den nye adressen. Men hvis du trenger at begge versjoner skal være live (som ved syndikering), skaper videresending problemer fordi det ødelegger syndikeringsplattformens URL-struktur.
# I .htaccess eller serverinnstilling
Redirect 301 /old-article https://yoursite.com/new-article
For innholdsstyringssystemer, implementer rel=“canonical” dynamisk for å håndtere paginering, parametervariasjoner og sesjonsbaserte URL-er som skaper utilsiktede duplikater. Mange CMS genererer flere URL-er til samme innhold via ulike navigasjonsstier—kanoniske tagger konsoliderer disse automatisk.
IndexNow akselererer oppdagelsen av kanoniske signaler og duplikatkonsolidering, og reduserer det som tradisjonelt ville tatt uker til dager. Når du implementerer kanoniske tagger på gjenpublisert innhold, varsler IndexNow søkesystemer umiddelbart at disse URL-ene skal klynges sammen. I stedet for å vente på at crawlere skal oppdage det kanoniske forholdet gjennom normal crawling, sender IndexNow denne informasjonen direkte til Microsofts indeks og andre deltakende søkesystemer. Dette er spesielt verdifullt når du retter opp tidligere feil—du kan implementere kanoniske tagger og bruke IndexNow til å signalisere endringen umiddelbart, i stedet for å vente på at crawlere besøker sidene på nytt. For utgivere som håndterer innhold på flere plattformer, blir IndexNow et kritisk verktøy for å beholde kontrollen over hvilken versjon som representerer ditt innholdskluster. API-integrasjonen lar deg sende inn URL-er i bulk, slik at det er praktisk å håndtere hundrevis eller tusenvis av gjenpubliserte sider.
POST https://api.indexnow.org/indexnow
{
"host": "yoursite.com",
"key": "your-api-key",
"keyLocation": "https://yoursite.com/indexnow-key.txt",
"urlList": [
"https://yoursite.com/blog/article-1",
"https://yoursite.com/blog/article-2"
]
}
Å spore hvilken versjon av ditt gjenpubliserte innhold som velges av AI-systemer krever overvåkning utover tradisjonell analyse. Sett opp overvåkning for å identifisere når AI-systemer siterer eller refererer til innholdet ditt, og noter hvilken URL som vises i AI-søkeresultater. Verktøy som Semrush, Ahrefs og Moz begynner å legge til synlighetsmålinger for AI-søk, selv om disse fortsatt er mindre modne enn tradisjonell søkesporing. Implementer UTM-parametere på syndikerte versjoner for å spore trafikk, men vær klar over at AI-systemer kanskje ikke viderefører disse parameterne, noe som gjør direkte attribusjon vanskelig. Overvåk Search Console (eller tilsvarende verktøy for andre søkesystemer) for crawl-mønstre—hvis sekundære versjoner crawles oftere enn din kanoniske versjon, indikerer det at AI-systemet kan ha valgt feil representativ side. Sett opp varsler for omtale av innholdet ditt på syndikeringsplattformer, og kryssjekk disse med din AI-synlighet for å avdekke misforhold mellom hvor innholdet ditt vises og hvor AI-systemer henter det fra.
Bruk denne sjekklisten før du gjenpubliserer noe innhold for å sikre at du beholder kontrollen over AI-synlighet:
Før gjenpublisering, identifiser din kanoniske versjon—URL-en du vil skal representere innholdet i AI-søk. Dette bør vanligvis være ditt eget domene, ikke en syndikeringsplattform. Implementer kanoniske tagger på hver gjenpublisert versjon som peker til din kanoniske URL, selv om du gjenpubliserer til egne eiendommer (andre domener, underdomener eller parametervariasjoner). Bruk IndexNow for å varsle søkesystemene om det kanoniske forholdet umiddelbart, i stedet for å vente på crawl-oppdagelse. Unngå å gjenpublisere til autoritetssterke plattformer uten kanonisk støtte—noen plattformer fjerner kanoniske tagger eller tillater dem ikke, og gjør dem dermed uegnet for gjenpublisering hvis du ikke aksepterer synlighetstap. Overvåk de første 48 timene etter gjenpublisering for å verifisere at AI-systemene velger din tiltenkte kanoniske versjon, ikke et alternativ. Oppdater alle versjoner samtidig når du gjør endringer—hvis du bare oppdaterer den kanoniske versjonen, kan klyngealgoritmen overse oppdateringen på tvers av versjoner og føre til at AI-systemet velger en utdatert versjon. Etabler en gjenpubliseringsplan som forhindrer at innhold blir utdatert på sekundære plattformer; utdatert syndikert innhold øker risikoen for at AI-systemer velger det som representativ versjon hvis din kanoniske versjon ikke nylig er oppdatert.
Kanoniske tagger forhindrer ikke straff fordi duplisert innhold ikke utløser straff i utgangspunktet. Likevel er kanoniske tagger avgjørende for AI-søk fordi de forteller AI-systemer hvilken versjon som skal representere ditt innholdskluster. Uten kanoniske tagger kan AI-systemer velge en utilsiktet versjon som autoritativ kilde, noe som reduserer synligheten din.
Overvåk hvilke URL-er som vises i AI-søkeresultater og siteringer for ditt innhold. Verktøy som Semrush og Ahrefs legger til synlighetsmålinger for AI-søk. Sjekk Search Console for crawl-mønstre—hvis sekundære versjoner crawles oftere enn din kanoniske versjon, kan AI-systemet ha valgt feil side.
Teknisk sett ja, men det anbefales ikke. Uten kanoniske tagger vil AI-systemer klustre innholdet ditt og velge én versjon som representativ—men du vil ikke kontrollere hvilken. Syndikeringsplattformen kan ha høyere autoritet, slik at AI velger den versjonen i stedet for ditt opprinnelige domene.
Gjenpublisering refererer vanligvis til distribusjon av innholdet ditt på flere kanaler du kontrollerer eller samarbeider med. Innholdssyndikering er en spesifikk form for gjenpublisering der tredjepartsplattformer gjenpubliserer innholdet ditt med din tillatelse. Begge skaper problemer med duplisert innhold hvis de ikke håndteres riktig med kanoniske tagger.
Kanoniske tagger blir vanligvis gjenkjent innen 24–48 timer hvis du bruker IndexNow for å varsle søkesystemer umiddelbart. Uten IndexNow kan det ta uker før crawlere oppdager det kanoniske forholdet. Dette er grunnen til at IndexNow er kritisk for håndtering av gjenpublisert innhold—det akselererer prosessen betydelig.
Bruk 301-videresending bare når du vil permanent konsolidere URL-er og den sekundære versjonen aldri vil bli oppdatert uavhengig. Bruk kanoniske tagger når begge versjonene må forbli live (som ved syndikering). Videresending gir sterkere signaler, men ødelegger funksjonaliteten til den sekundære URL-en.
Ja, hvis det ikke håndteres riktig. Gjenpublisering uten kanoniske tagger utvanner autoritetssignalene dine over flere URL-er. AI-systemer kan velge syndikeringsversjonen i stedet for din opprinnelige, noe som reduserer synligheten på ditt eget domene. Riktig implementering av kanoniske tagger forhindrer dette.
Implementer kanoniske tagger på hver gjenpublisert versjon som peker til ditt opprinnelige domene. Bruk IndexNow for å umiddelbart varsle søkesystemer om det kanoniske forholdet. Unngå å gjenpublisere til plattformer som ikke støtter kanoniske tagger. Overvåk hvilken versjon AI-systemer velger de første 48 timene og juster ved behov.
Følg med på hvordan AI-systemer siterer og refererer til ditt gjenpubliserte innhold på alle plattformer. Få sanntidsinnsikt i hvilken versjon AI velger som din autoritative kilde.
Lær hvordan du kan gjenbruke og optimalisere innhold for AI-plattformer som ChatGPT, Perplexity og Claude. Oppdag strategier for AI-synlighet, innholdsstrukture...
Diskusjon i fellesskapet om hvordan AI-systemer håndterer duplisert innhold annerledes enn tradisjonelle søkemotorer. SEO-fagfolk deler innsikt om innholdsunikh...

Lær hvordan kanoniske URL-er forhindrer problemer med duplikatinnhold i AI-søkesystemer. Oppdag beste praksis for implementering av kanoniske for å forbedre AI-...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.