
Finnes det et AI-søkindeks? Hvordan AI-motorer indekserer innhold
Lær hvordan AI-søkindekser fungerer, forskjellene mellom ChatGPT, Perplexity og SearchGPTs indekseringsmetoder, og hvordan du kan optimalisere innholdet ditt fo...
7 min lesing

Lær hvordan AI-søkemotorer som ChatGPT, Perplexity og Google AI Overviews fungerer. Oppdag LLM-er, RAG, semantisk søk og sanntids gjenfinningsmekanismer.
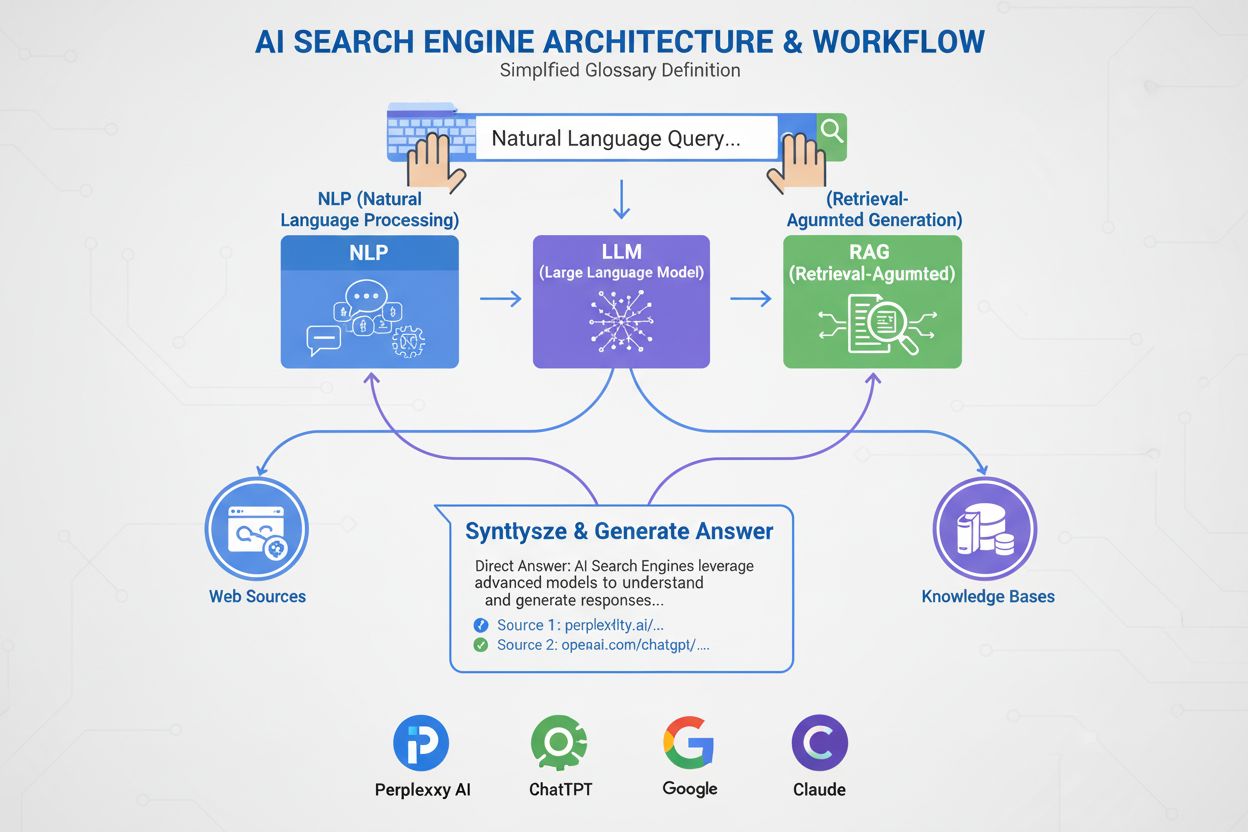
AI-søkemotorer bruker store språkmodeller (LLM-er) kombinert med retrieval-augmented generation (RAG) for å forstå brukerintensjon og hente relevant informasjon fra nettet i sanntid. De behandler forespørsler gjennom semantisk forståelse, vektorembeddinger og kunnskapsgrafer for å levere samtalebaserte svar med kildehenvisninger, i motsetning til tradisjonelle søkemotorer som returnerer rangerte lister over nettsteder.
AI-søkemotorer representerer et grunnleggende skifte fra tradisjonelt søk basert på nøkkelord til samtalebasert, intensjonsdrevet informasjonsinnhenting. I motsetning til Googles tradisjonelle søkemotor, som gjennomsøker, indekserer og rangerer nettsteder for å returnere en liste med lenker, genererer AI-søkemotorer som ChatGPT, Perplexity, Google AI Overviews og Claude originale svar ved å kombinere flere teknologier. Disse plattformene forstår hva brukerne faktisk leter etter, henter relevant informasjon fra autoritative kilder og syntetiserer denne informasjonen til sammenhengende, siterte svar. Teknologien som driver disse systemene, endrer måten folk oppdager informasjon på nettet, med ChatGPT som behandler 2 milliarder forespørsler daglig og AI Overviews som vises i 18 % av globale Google-søk. Å forstå hvordan disse systemene fungerer er avgjørende for innholdsskapere, markedsførere og bedrifter som ønsker synlighet i dette nye søkelandskapet.
AI-søkemotorer opererer gjennom tre sammenkoblede systemer som jobber sammen for å levere nøyaktige, kildebelagte svar. Den første komponenten er Large Language Model (LLM), som er trent på enorme mengder tekstdata for å forstå språkets mønstre, struktur og nyanser. Modeller som OpenAIs GPT-4, Googles Gemini og Anthropics Claude er trent ved hjelp av usupervisert læring på milliarder av dokumenter, noe som gjør dem i stand til å forutsi hvilke ord som bør følge basert på statistiske mønstre lært under treningen. Den andre komponenten er embedding-modellen, som konverterer ord og fraser til numeriske representasjoner kalt vektorer. Disse vektorene fanger opp semantisk betydning og relasjoner mellom konsepter, slik at systemet forstår at “gaming laptop” og “høyytelsesdatamaskin” er semantisk beslektet selv om de ikke deler nøyaktige nøkkelord. Den tredje viktige komponenten er Retrieval-Augmented Generation (RAG), som supplerer LLM-ens treningsdata ved å hente oppdatert informasjon fra eksterne kunnskapsbaser i sanntid. Dette er essensielt fordi LLM-er har en treningsavskjæringsdato og ikke kan få tilgang til sanntidsinformasjon uten RAG. Sammen gjør disse tre komponentene det mulig for AI-søkemotorer å gi oppdaterte, nøyaktige og siterte svar, i stedet for hallusinerte eller utdaterte opplysninger.
Retrieval-Augmented Generation er prosessen som gjør det mulig for AI-søkemotorer å forankre sine svar i autoritative kilder, i stedet for å stole utelukkende på treningsdata. Når du sender inn et spørsmål til en AI-søkemotor, konverterer systemet først spørsmålet ditt til en vektorreprresentasjon ved hjelp av embedding-modellen. Denne vektoren sammenlignes deretter med en database av indeksert nettinnhold, også konvertert til vektorer, ved bruk av teknikker som cosine similarity for å identifisere de mest relevante dokumentene. RAG-systemet henter disse dokumentene og sender dem til LLM-en sammen med ditt opprinnelige spørsmål. LLM-en bruker så både den hentede informasjonen og sine treningsdata til å generere et svar som direkte refererer til kildene den konsulterte. Denne tilnærmingen løser flere kritiske problemer: den sikrer at svarene er oppdaterte og faktabaserte, den lar brukere verifisere informasjon ved å sjekke kildehenvisninger, og den gir innholdsskapere mulighet til å bli sitert i AI-genererte svar. Azure AI Search og AWS Bedrock er bedriftsimplementeringer av RAG som viser hvordan organisasjoner kan bygge tilpassede AI-søkesystemer. Kvaliteten på RAG avhenger i stor grad av hvor godt gjenfinningssystemet identifiserer relevante dokumenter, derfor har semantisk rangering og hybridsøk (som kombinerer nøkkelord- og vektorsøk) blitt essensielle teknikker for å forbedre nøyaktigheten.
Semantisk søk er teknologien som gjør det mulig for AI-søkemotorer å forstå mening og ikke bare matche nøkkelord. Tradisjonelle søkemotorer leter etter eksakte nøkkelord, men semantisk søk analyserer intensjonen og den kontekstuelle betydningen bak et spørsmål. Når du søker etter “rimelige smarttelefoner med gode kameraer”, forstår en semantisk søkemotor at du ønsker budsjetttelefoner med utmerkede kamerafunksjoner, selv om resultatene ikke inneholder akkurat de samme ordene. Dette oppnås gjennom vektorembeddinger, som representerer tekst som høy-dimensjonale numeriske matriser. Avanserte modeller som BERT (Bidirectional Encoder Representations from Transformers) og OpenAIs text-embedding-3-small konverterer ord, fraser og hele dokumenter til vektorer der semantisk lignende innhold plasseres nær hverandre i vektorrommet. Systemet beregner deretter vektorsimilaritet ved hjelp av matematiske teknikker som cosine similarity for å finne dokumenter som ligger nærmest spørsmålets intensjon. Denne tilnærmingen er langt mer effektiv enn nøkkelordmatching fordi den fanger opp relasjoner mellom konsepter. For eksempel forstår systemet at “gaming laptop” og “høyytelsesdatamaskin med GPU” er beslektet selv om de ikke har noen felles nøkkelord. Kunnskapsgrafer legger til et nytt lag ved å skape strukturerte nettverk av semantiske relasjoner, og knytter konsepter som “laptop” til “prosessor”, “RAM” og “GPU” for å forbedre forståelsen. Denne flerlagstilnærmingen til semantisk forståelse er grunnen til at AI-søkemotorer kan levere relevante resultater for komplekse, samtalebaserte spørsmål som tradisjonelle søkemotorer sliter med.
| Søketeknologi | Hvordan det fungerer | Styrker | Begrensninger |
|---|---|---|---|
| Nøkkelordsøk | Matcher eksakte ord eller fraser i spørsmålet med indeksert innhold | Raskt, enkelt, forutsigbart | Fungerer dårlig med synonymer, skrivefeil og kompleks intensjon |
| Semantisk søk | Forstår mening og intensjon ved bruk av NLP og embeddinger | Håndterer synonymer, kontekst og komplekse spørsmål | Krever mer datakraft |
| Vektorsøk | Konverterer tekst til numeriske vektorer og beregner likhet | Presis likhetsmatching, skalerbart | Fokuserer på matematisk avstand, ikke kontekst |
| Hybridsøk | Kombinerer nøkkelord- og vektorsøk | Best av begge verdener for nøyaktighet og gjenfinning | Mer komplekst å implementere og justere |
| Kunnskapsgrafsøk | Bruker strukturerte relasjoner mellom konsepter | Legger til resonnering og kontekst til resultatene | Krever manuell kuratering og vedlikehold |
En av de største fordelene med AI-søkemotorer over tradisjonelle LLM-er er deres evne til å få tilgang til sanntidsinformasjon fra nettet. Når du spør ChatGPT om aktuelle hendelser, bruker den en bot kalt ChatGPT-User for å gjennomsøke nettsteder i sanntid og hente oppdatert informasjon. Perplexity søker tilsvarende på internett i sanntid for å hente innsikt fra toppkilder, noe som gjør at den kan svare på spørsmål om hendelser som har skjedd etter treningsdatakuttet. Google AI Overviews benytter Googles eksisterende nettindeks og crawling-infrastruktur for å hente oppdatert informasjon. Denne sanntidsfunksjonen er avgjørende for å opprettholde nøyaktighet og relevans. Gjenfinningsprosessen består av flere trinn: først deler systemet opp spørsmålet ditt i flere relaterte underforespørsler gjennom en prosess kalt query fan-out, som hjelper til med å hente mer omfattende informasjon. Deretter søker systemet i indeksert nettinnhold ved bruk av både nøkkelord- og semantisk matching for å finne relevante sider. De hentede dokumentene rangeres etter relevans ved hjelp av semantiske rangeringsalgoritmer som omvurderer resultatene basert på mening og ikke bare nøkkelordfrekvens. Til slutt trekker systemet ut de mest relevante avsnittene fra disse dokumentene og sender dem til LLM-en for svarproduksjon. Hele denne prosessen skjer i løpet av sekunder, noe som gjør at brukerne forventer AI-svar innen 3–5 sekunder. Hastigheten og nøyaktigheten til denne gjenfinningsprosessen påvirker direkte kvaliteten på det endelige svaret, og gjør effektiv informasjonsinnhenting til en kritisk komponent i AI-søkemotorers arkitektur.
Når RAG-systemet har hentet relevant informasjon, bruker Large Language Model denne informasjonen til å generere et svar. LLM-er “forstår” ikke språk i menneskelig forstand; de bruker statistiske modeller for å forutsi hvilke ord som skal følge basert på mønstre lært under treningen. Når du skriver inn et spørsmål, konverterer LLM-en det til en vektorreprresentasjon og bearbeider det gjennom et nevralt nettverk med millioner av sammenkoblede noder. Disse nodene har lært forbindelsesstyrker kalt vekter under treningen, som avgjør hvor mye innflytelse hver forbindelse har over de andre. LLM-en returnerer ikke én enkelt prediksjon for neste ord; den returnerer en rangert liste over sannsynligheter. For eksempel kan den forutsi 4,5 % sjanse for at neste ord bør være “lære” og 3,5 % sjanse for at det skal være “forutsi”. Systemet velger ikke alltid ordet med høyest sannsynlighet; det velger noen ganger ord med lavere rangering for å få svarene til å høres mer naturlige og kreative ut. Denne tilfeldigheten kontrolleres av temperaturparameteren, som varierer fra 0 (deterministisk) til 1 (svært kreativ). Etter å ha generert det første ordet, gjentar systemet denne prosessen for neste ord, og neste, til et komplett svar er generert. Denne token-for-token-genereringen er grunnen til at AI-svar noen ganger føles samtalebaserte og naturlige – modellen spår i praksis den mest sannsynlige fortsettelsen av en samtale. Kvaliteten på det genererte svaret avhenger både av kvaliteten på den hentede informasjonen og av hvor avansert LLM-ens trening har vært.
Ulike AI-søkeplattformer implementerer disse sentrale teknologiene med ulike tilnærminger og optimaliseringer. ChatGPT, utviklet av OpenAI, har fanget 81 % av markedet for AI-chatboter og behandler 2 milliarder forespørsler daglig. ChatGPT bruker OpenAIs GPT-modeller kombinert med sanntidstilgang til nettet gjennom ChatGPT-User for å hente oppdatert informasjon. Den er spesielt sterk på å håndtere komplekse, flertrinnsspørsmål og å opprettholde samtalekontekst. Perplexity skiller seg ut gjennom transparente kildehenvisninger, og viser brukerne nøyaktig hvilke nettsteder som informerte hver del av svaret. Perplexitys viktigste kildekilder inkluderer Reddit (6,6 %), YouTube (2 %) og Gartner (1 %), noe som gjenspeiler plattformens fokus på å finne autoritative, varierte kilder. Google AI Overviews er integrert direkte i Google Søk-resultatene, og vises øverst på siden for mange søk. Disse oversiktene vises i 18 % av globale Google-søk og drives av Googles Gemini-modell. Google AI Overviews er spesielt effektive for informasjonsspørsmål, med 88 % av søk som utløser dem, er av informativ art. Googles AI-modus, en separat søkeopplevelse lansert i mai 2024, omstrukturerer hele søkeresultatsiden rundt AI-genererte svar og har nådd 100 millioner månedlige aktive brukere i USA og India. Claude, utviklet av Anthropic, legger vekt på sikkerhet og nøyaktighet, og brukerne rapporterer høy tilfredshet med dens evne til å gi nyanserte, velfunderte svar. Hver plattform gjør forskjellige avveininger mellom hastighet, nøyaktighet, kildegjennomsiktighet og brukeropplevelse, men alle er avhengige av den grunnleggende arkitekturen med LLM-er, embeddinger og RAG.
Når du sender inn et spørsmål til en AI-søkemotor, går det gjennom en sofistikert flerstegsbehandlingsprosess. Første steg er forespørselsanalyse, der systemet bryter ned spørsmålet ditt i grunnleggende komponenter som nøkkelord, enheter og fraser. Naturlige språkprosesseringsteknikker som tokenisering, ordklassemerking og navngitt enhetsgjenkjenning identifiserer hva du spør om. For eksempel, i spørsmålet “beste bærbare til gaming”, identifiserer systemet “bærbare” som hovedenhet og “gaming” som intensjonsdriver, og utleder dermed at du trenger høy minnekapasitet, prosesseringskraft og GPU-funksjonalitet. Andre steg er utvidelse og fan-out av forespørsel, hvor systemet genererer flere relaterte spørsmål for å hente mer omfattende informasjon. I stedet for å bare søke etter “beste gaming-laptop”, søker systemet også etter “spesifikasjoner for gaming-laptop”, “høyytelses bærbare” og “laptop GPU-krav”. Disse parallelle søkene skjer samtidig, og øker dekningsgraden dramatisk. Tredje steg er gjenfinning og rangering, hvor systemet søker i indeksert innhold med både nøkkelord- og semantisk matching, og rangerer deretter resultatene etter relevans. Fjerde steg er avsnittsuttrekk, hvor systemet finner de mest relevante avsnittene i de hentede dokumentene i stedet for å sende hele dokumenter til LLM-en. Dette er kritisk fordi LLM-er har tokenbegrensninger – GPT-4 aksepterer omtrent 128 000 tokens, men du kan ha 10 000 sider med dokumentasjon. Ved å bare trekke ut de mest relevante avsnittene, maksimerer systemet kvaliteten på informasjonen som sendes til LLM-en, samtidig som det holder seg innenfor tokenbegrensningene. Siste steg er svargenerering og sitering, hvor LLM-en genererer et svar og inkluderer henvisninger til kildene den konsulterte. Hele denne prosessen må være ferdig på sekunder for å møte brukernes forventning til svartid.
Den grunnleggende forskjellen mellom AI-søkemotorer og tradisjonelle søkemotorer som Google ligger i deres kjerneformål og metodikk. Tradisjonelle søkemotorer er laget for å hjelpe brukere med å finne eksisterende informasjon ved å gjennomsøke nettet, indeksere sider og rangere dem basert på relevanssignaler som lenker, nøkkelord og brukerengasjement. Googles prosess består av tre hovedtrinn: crawling (oppdage sider), indeksering (analysere og lagre sideinformasjon) og rangering (avgjøre hvilke sider som er mest relevante for et spørsmål). Målet er å returnere en liste med nettsteder, ikke å generere nytt innhold. AI-søkemotorer, derimot, er laget for å generere originale, syntetiserte svar basert på mønstre lært fra treningsdata og oppdatert informasjon hentet fra nettet. Mens tradisjonelle søkemotorer bruker AI-algoritmer som RankBrain og BERT for å forbedre rangeringen, forsøker de ikke å lage nytt innhold. AI-søkemotorer genererer fundamentalt ny tekst ved å forutsi ordsekvenser. Dette skiller har store konsekvenser for synlighet. Med tradisjonelt søk må du rangere blant de ti øverste for å få klikk. Med AI-søk siteres 40 % av kildene i AI Overviews lavere enn topp 10-posisjoner i tradisjonelt Google-søk, og bare 14 % av URL-ene sitert av Googles AI-modus rangerer i Googles tradisjonelle topp 10 for samme spørsmål. Dette betyr at innholdet ditt kan bli sitert i AI-svar selv om det ikke rangerer høyt i tradisjonelt søk. I tillegg har merkede nettomtaler en 0,664 korrelasjon med synlighet i Google AI Overviews, langt høyere enn lenker (0,218), noe som tyder på at merkevaresynlighet og omdømme har mer å si i AI-søk enn tradisjonelle SEO-målinger.
AI-søkelandskapet utvikler seg raskt, med store konsekvenser for hvordan folk oppdager informasjon og hvordan bedrifter opprettholder synlighet. AI-søk forventes å overgå tradisjonell søketrafikk innen 2028, og nåværende data viser at AI-plattformer genererte 1,13 milliarder henvisningsbesøk i juni 2025, en økning på 357 % fra juni 2024. Viktigere er det at AI-søk konverterer i 14,2 % av tilfellene, sammenlignet med Googles 2,8 %, noe som gjør denne trafikken mye mer verdifull selv om den foreløpig bare utgjør 1 % av global trafikk. Markedet konsoliderer seg rundt noen få dominerende plattformer: ChatGPT har 81 % av markedet for AI-chatboter, Googles Gemini har 400 millioner månedlige aktive brukere, og Perplexity har over 22 millioner aktive månedlige brukere. Nye funksjoner utvider AI-søkets muligheter – ChatGPTs Agent Mode lar brukere delegere komplekse oppgaver som å bestille fly direkte i plattformen, mens Instant Checkout muliggjør produktkjøp rett fra chatten. ChatGPT Atlas, lansert i oktober 2025, bringer ChatGPT ut på nettet for umiddelbare svar og forslag. Disse utviklingene tyder på at AI-søk ikke bare blir et alternativ til tradisjonelt søk, men en omfattende plattform for informasjonsinnhenting, beslutningstaking og handel. For innholdsskapere og markedsførere krever dette et grunnleggende skifte i strategi. I stedet for å optimalisere for nøkkelordrangeringer, krever suksess i AI-søk at man etablerer relevante mønstre i treningsmateriell, bygger merkevareautoritet gjennom omtaler og siteringer, og sørger for at innholdet er oppdatert, omfattende og godt strukturert. Verktøy som AmICited gjør det mulig for bedrifter å overvåke hvor innholdet deres vises på tvers av AI-plattformer, følge siteringsmønstre og måle synlighet i AI-søk – essensielle ferdigheter for å navigere i dette nye landskapet.
Følg med på hvor innholdet ditt vises i ChatGPT, Perplexity, Google AI Overviews og Claude. Få sanntidsvarsler når domenet ditt blir sitert i AI-genererte svar.
Lær hvordan AI-søkindekser fungerer, forskjellene mellom ChatGPT, Perplexity og SearchGPTs indekseringsmetoder, og hvordan du kan optimalisere innholdet ditt fo...
Lær hva AI-søkemotorer er, hvordan de skiller seg fra tradisjonelle søk, og deres innvirkning på merkevaresynlighet. Utforsk plattformer som Perplexity, ChatGPT...
Lær hvordan du sender inn og optimaliserer innholdet ditt for AI-søkemotorer som ChatGPT, Perplexity og Gemini. Oppdag indekseringsstrategier, tekniske krav og ...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.