
Hvordan bestride og korrigere unøyaktig informasjon i AI-svar
Lær hvordan du bestrider unøyaktig AI-informasjon, rapporterer feil til ChatGPT og Perplexity, og implementerer strategier for å sikre at merkevaren din represe...
9 min lesing

Lær effektive metoder for å identifisere, verifisere og korrigere unøyaktig informasjon i AI-genererte svar fra ChatGPT, Perplexity og andre AI-systemer.
Korriger feilinformasjon i AI-svar ved å bruke lateral lesing for å kryssjekke påstander med autoritative kilder, bryte ned informasjon i spesifikke påstander, og rapportere feil til AI-plattformen. Verifiser fakta gjennom akademiske databaser, offentlige nettsider og etablerte nyhetsmedier før du aksepterer AI-generert innhold som nøyaktig.
Feilinformasjon i AI-svar oppstår når kunstige intelligenssystemer genererer unøyaktig, foreldet eller misvisende informasjon som fremstår som troverdig for brukere. Dette skjer fordi store språkmodeller (LLM) trenes på enorme mengder data fra internett, som kan inneholde skjev, ufullstendig eller falsk informasjon. Fenomenet kjent som AI-hallusinasjon er spesielt problematisk—det oppstår når AI-modeller oppfatter mønstre som ikke faktisk eksisterer og lager tilsynelatende faktabaserte svar som er helt grunnløse. For eksempel kan et AI-system finne opp navnet på en fiktiv professor eller tilskrive feil informasjon til en virkelig person, og samtidig presentere informasjonen med fullstendig selvtillit. Å forstå disse begrensningene er avgjørende for alle som stoler på AI for forskning, forretningsbeslutninger eller innholdsproduksjon.
Utfordringen med feilinformasjon i AI-svar strekker seg utover enkle faktafeil. AI-systemer kan presentere spekulasjon som fakta, feiltolke data på grunn av treningsbegrensninger, eller hente informasjon fra foreldede kilder som ikke lenger gjenspeiler dagens virkelighet. I tillegg har AI-modeller problemer med å skille mellom faktiske utsagn og meninger, og behandler noen ganger subjektive oppfatninger som objektive sannheter. Dette skaper et sammensatt problem der brukere må utvikle kritiske vurderingsevner for å skille nøyaktig informasjon fra falske påstander, spesielt når AI presenterer alt med lik selvtillit og autoritet.
Lateral lesing er den mest effektive teknikken for å identifisere og korrigere feilinformasjon i AI-svar. Denne metoden innebærer å forlate AI-utdataene og konsultere flere eksterne kilder for å vurdere nøyaktigheten av bestemte påstander. I stedet for å lese vertikalt gjennom AI-svaret og akseptere informasjon uten videre, krever lateral lesing at du åpner nye faner og søker etter støttende bevis fra autoritative kilder. Denne tilnærmingen er spesielt viktig fordi AI-utdata er en sammensetning av flere ikke-identifiserbare kilder, noe som gjør det umulig å vurdere troverdigheten ved å undersøke selve kilden—i stedet må du evaluere faktapåstandene uavhengig.
Lateral leseprosessen starter med fraksjonering, som betyr å bryte ned AI-svaret i mindre, spesifikke og søkbare påstander. I stedet for å prøve å verifisere et helt avsnitt på en gang, isoler enkeltutsagn som kan verifiseres uavhengig. Hvis et AI-svar for eksempel hevder at en bestemt person gikk på et spesifikt universitet og studerte under en navngitt professor, blir dette tre separate påstander å verifisere. Når du har identifisert disse påstandene, åpne nye nettleserfaner og søk etter bevis som støtter hver enkelt ved å bruke pålitelige kilder som Google Scholar, akademiske databaser, offentlige nettsider eller etablerte nyhetsmedier. Hovedfordelen med denne metoden er at den tvinger deg til å undersøke antagelsene som ligger i både prompten din og AI-svaret, slik at du kan identifisere hvor feilene oppsto.
Verifisering av AI-generert informasjon krever at man konsulterer flere autoritative kilder som opprettholder høye standarder for nøyaktighet og troverdighet. Offentlige nettsider, fagfellevurderte akademiske tidsskrifter, etablerte nyhetsorganisasjoner og spesialiserte forskningsdatabaser gir de mest pålitelige verifikasjonspunktene. Når du faktasjekker AI-svar, prioriter kilder med spesifikke egenskaper: akademiske databaser som JSTOR, PubMed eller Google Scholar for forskningspåstander; offentlige nettsider for offisiell statistikk og politikk; og etablerte nyhetsmedier for nyheter og siste utvikling. Disse kildene har redaksjonelle prosesser, faktasjekkingsrutiner og ansvarsmekanismer som AI-systemer mangler.
| Kildetype | Best egnet for | Eksempler |
|---|---|---|
| Akademiske databaser | Forskningspåstander, historiske fakta, teknisk informasjon | JSTOR, PubMed, Google Scholar, WorldCat |
| Offentlige nettsider | Offisiell statistikk, politikk, regelverk | .gov-domener, offisielle etatsnettsteder |
| Etablerte nyhetsmedier | Nyheter, siste utvikling, hendelser | Store aviser, nyhetsbyråer med redaksjonelle standarder |
| Spesialdatabaser | Bransjespesifikk informasjon, tekniske detaljer | Bransjeforeninger, profesjonelle organisasjoner |
| Ideelle organisasjoner | Verifisert informasjon, forskningsrapporter | .org-domener med åpen finansiering |
Når du kryssjekker AI-svar, se etter flere uavhengige kilder som bekrefter den samme informasjonen, i stedet for å stole på én enkelt kilde. Finner du motstridende informasjon på tvers av kilder, undersøk nærmere for å forstå hvorfor uoverensstemmelsene finnes. Noen ganger inneholder AI-svar korrekt informasjon i feil kontekst—for eksempel ved å tilskrive et faktum om én organisasjon til en annen, eller plassere nøyaktig informasjon i feil tidsperiode. Denne typen feil er spesielt snikende fordi de enkelte faktaene kan verifiseres, men kombinasjonen skaper feilinformasjon.
Effektiv korrigering av feilinformasjon krever en systematisk tilnærming til å analysere AI-svar. Start med å identifisere de spesifikke faktapåstandene i svaret, og vurder hver påstand uavhengig. Denne prosessen innebærer å stille kritiske spørsmål om hvilke antakelser AI gjorde basert på prompten din, hvilket perspektiv eller agenda som kan påvirke informasjonen, og om påstandene stemmer overens med det du finner gjennom egen research. For hver påstand, dokumenter om den er helt korrekt, delvis misvisende eller faktisk feil.
Når du analyserer AI-svar, vær spesielt oppmerksom på selvtillitsindikatorer og hvordan AI presenterer informasjon. AI-systemer presenterer ofte usikker eller spekulativ informasjon med samme sikkerhet som godt etablerte fakta, noe som gjør det vanskelig for brukere å skille mellom verifisert informasjon og kvalifisert gjetning. Undersøk også om AI-svaret inkluderer henvisninger eller kildehenvisninger—mens noen AI-systemer forsøker å sitere kilder, kan disse henvisningene være unøyaktige, ufullstendige eller peke til kilder som ikke faktisk inneholder den oppgitte informasjonen. Hvis et AI-system siterer en kilde, verifiser at kilden faktisk eksisterer og at den siterte informasjonen står nøyaktig slik som presentert.
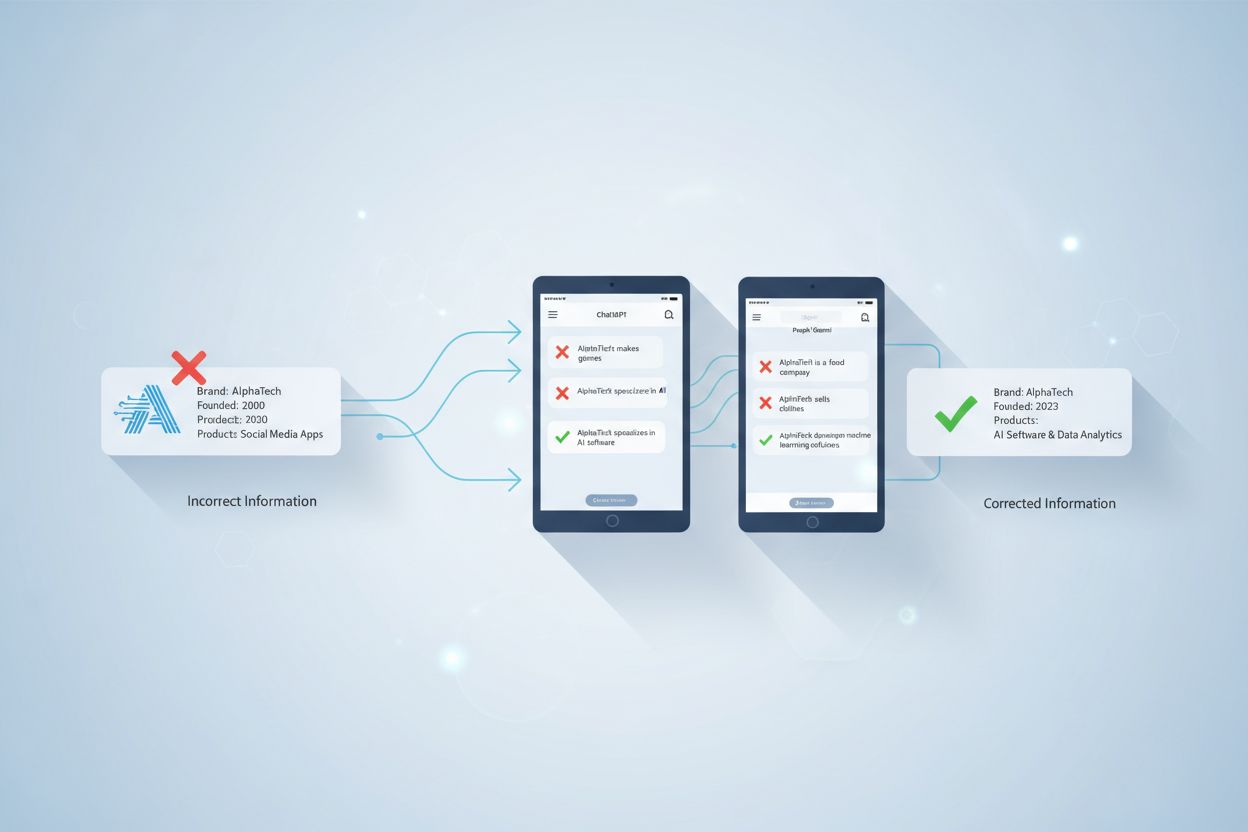
De fleste store AI-plattformer tilbyr mekanismer for brukere til å rapportere unøyaktige eller misvisende svar. Perplexity lar for eksempel brukere rapportere feilaktige svar gjennom et dedikert tilbakemeldingssystem eller ved å opprette en supportsak. ChatGPT og andre AI-systemer tilbyr lignende tilbakemeldingsalternativer som hjelper utviklere med å identifisere og korrigere problematiske svar. Når du rapporterer feilinformasjon, gi spesifikke detaljer om hva som var unøyaktig, hva som er korrekt informasjon, og helst lenker til autoritative kilder som støtter rettingen. Denne tilbakemeldingen bidrar til å forbedre AI-systemets trening og hjelper med å forhindre at de samme feilene gjentas for andre brukere.
Å rapportere feil tjener flere formål utover å korrigere individuelle svar. Det skaper en tilbakemeldingssløyfe som hjelper AI-utviklere å forstå vanlige feiltyper og områder der systemene deres sliter. Over tid bidrar denne kollektive tilbakemeldingen fra brukere til å forbedre nøyaktigheten og påliteligheten til AI-systemer. Det er imidlertid viktig å innse at å rapportere feil til plattformen ikke erstatter egen faktasjekk—du kan ikke stole på at plattformen korrigerer feilinformasjon før du støter på den, så personlig verifisering forblir essensielt.
AI-hallusinasjoner er en av de mest utfordrende typene feilinformasjon fordi de genereres med full selvtillit og ofte høres plausible ut. Disse oppstår når AI-modeller lager informasjon som høres rimelig ut, men som ikke har noen rot i virkeligheten. Vanlige eksempler inkluderer å finne opp fiktive personer, lage falske henvisninger, eller tilskrive uriktige prestasjoner til virkelige individer. Forskning har vist at noen AI-modeller korrekt identifiserer sannheter nesten 90 prosent av tiden, men gjenkjenner usannheter under 50 prosent av tiden, noe som betyr at de faktisk er dårligere enn tilfeldigheter til å gjenkjenne falske utsagn.
For å identifisere potensielle hallusinasjoner, se etter varselsignaler i AI-svar: påstander om ukjente personer eller hendelser du ikke kan verifisere gjennom noen kilde, henvisninger til artikler eller bøker som ikke eksisterer, eller informasjon som virker for beleilig eller perfekt tilpasset prompten din. Når et AI-svar inkluderer spesifikke navn, datoer eller henvisninger, er dette gode kandidater for verifisering. Hvis du ikke finner noen uavhengig bekreftelse på en spesifikk påstand etter å ha søkt i flere kilder, er det sannsynligvis en hallusinasjon. Vær også skeptisk til AI-svar som gir svært detaljerte opplysninger om nisjetemaer uten å sitere kilder—denne graden av spesifisitet kombinert med mangel på verifiserbare kilder er ofte et tegn på oppdiktet informasjon.
AI-systemer har kunnskapsavskjæringsdatoer, noe som betyr at de ikke kan få tilgang til informasjon publisert etter at treningsdataene deres ble avsluttet. Dette skaper en betydelig kilde til feilinformasjon når brukere spør om nylige hendelser, nåværende statistikk eller ny forskning. Et AI-svar om dagens markedsforhold, nylige politiske endringer eller siste nytt kan være fullstendig unøyaktig, rett og slett fordi AI-ens treningsdata er eldre enn disse hendelsene. Når du søker informasjon om nye hendelser eller oppdaterte data, må du alltid verifisere at AI-svaret gjenspeiler den mest oppdaterte informasjonen som finnes.
For å adressere foreldet informasjon, sjekk publiseringsdatoer på alle kilder du finner under faktasjekken, og sammenlign dem med AI-svarets dato. Hvis AI-svaret viser til statistikk eller informasjon fra flere år tilbake, men presenterer det som aktuelt, er dette et klart tegn på foreldet informasjon. For temaer hvor informasjon endres ofte—som teknologi, medisin, juss eller økonomi—bør du alltid supplere AI-svar med de mest oppdaterte kildene som finnes. Vurder å bruke AI-systemer som har tilgang til sanntidsinformasjon eller som eksplisitt oppgir sin kunnskapsavskjæringsdato, slik at du forstår begrensningene i svarene deres.
AI-systemer trent på internettdata arver skjevheter som finnes i disse dataene, noe som kan vise seg som feilinformasjon som favoriserer enkelte perspektiver og utelater andre. Når du vurderer AI-svar, undersøk om informasjonen presenterer flere perspektiver på kontroversielle eller komplekse temaer, eller om den fremstiller ett syn som objektiv sannhet. Feilinformasjon oppstår ofte når AI-systemer presenterer subjektive meninger eller kulturbestemte syn som universelle sannheter. Undersøk også om AI-svaret anerkjenner usikkerhet eller uenighet blant eksperter på temaet—hvis det finnes reell uenighet blant ekspertene, bør et ansvarlig AI-svar påpeke dette i stedet for å presentere én oppfatning som definitiv.
For å identifisere skjevhetsrelatert feilinformasjon, undersøk hvordan ulike autoritative kilder omtaler det samme temaet. Hvis du finner betydelig uenighet mellom anerkjente kilder, kan AI-svaret presentere en ufullstendig eller skjev versjon av informasjonen. Se etter om AI anerkjenner begrensninger, motargumenter eller alternative tolkninger av informasjonen den gir. Et svar som fremstiller informasjon som mer sikker enn den faktisk er, eller som utelater viktig kontekst eller alternative syn, kan være misvisende selv om de enkelte faktaene er teknisk riktige.
Selv om menneskelig faktasjekk forblir avgjørende, kan spesialiserte faktasjekkingsverktøy og ressurser bistå med å verifisere AI-generert informasjon. Nettsteder dedikert til faktasjekk, som Snopes, FactCheck.org og PolitiFact, har databaser over verifiserte og tilbakeviste påstander som kan hjelpe deg raskt å identifisere falske utsagn. I tillegg utvikles noen AI-systemer spesielt for å hjelpe med å oppdage når andre AI-systemer er overkonfidente med feilaktige spådommer. Disse nye verktøyene bruker teknikker som konfidenskalibrering for å hjelpe brukere å forstå når et AI-system sannsynligvis tar feil, selv når det uttrykker høy selvtillit.
Akademiske og forskningsinstitusjoner tilbyr i økende grad ressurser for å vurdere AI-generert innhold. Universitetsbiblioteker, forskningssentre og utdanningsinstitusjoner tilbyr guider om lateral lesing, kritisk evaluering av AI-innhold og faktasjekkmetoder. Disse ressursene inkluderer ofte steg-for-steg-prosesser for å bryte ned AI-svar, identifisere påstander og verifisere informasjon systematisk. Å benytte seg av slike utdanningsressurser kan øke din evne til å identifisere og korrigere feilinformasjon i AI-svar betydelig.
Følg med på hvordan ditt domene, merkevare og URL-er vises i AI-genererte svar på ChatGPT, Perplexity og andre AI-søkemotorer. Få varsler når feilinformasjon om din virksomhet dukker opp i AI-svar og ta korrigerende tiltak.
Lær hvordan du bestrider unøyaktig AI-informasjon, rapporterer feil til ChatGPT og Perplexity, og implementerer strategier for å sikre at merkevaren din represe...
Lær hvordan du identifiserer og korrigerer feilaktig merkevareinformasjon i AI-systemer som ChatGPT, Gemini og Perplexity. Oppdag overvåkingsverktøy, strategier...
Lær velprøvde strategier for å beskytte merkevaren din mot AI-hallusinasjoner i ChatGPT, Perplexity og andre AI-systemer. Oppdag overvåking, verifisering og sty...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.