Kunnskapsgraf
Lær hva en kunnskapsgraf er, hvordan søkemotorer bruker dem for å forstå enhetsrelasjoner, og hvorfor de er viktige for AI-synlighet og merkevareovervåking på t...
14 min lesing

Oppdag hva kunnskapsgrafer er, hvordan de fungerer, og hvorfor de er essensielle for moderne databehandling, AI-applikasjoner og forretningsinnsikt.
En kunnskapsgraf er et strukturert nettverk som kobler dataenheter gjennom definerte relasjoner, slik at både maskiner og mennesker kan forstå komplekse informasjonsmønstre. Den er viktig fordi den omdanner rådata til handlingsorienterte innsikter, driver AI-applikasjoner, forbedrer søkepresisjonen og gjør det mulig for organisasjoner å bryte ned datasiloer for bedre beslutningstaking.
En kunnskapsgraf er en strukturert, sammenkoblet representasjon av dataenheter og deres relasjoner, organisert som et nettverk av noder og kanter. I motsetning til tradisjonelle relasjonsdatabaser som er avhengige av rigide, forhåndsdefinerte strukturer, modellerer kunnskapsgrafer informasjon som et semantisk nett der hvert punkt (node) representerer en enhet—som en person, et sted, et produkt eller et konsept—og hver forbindelse (kant) illustrerer hvordan disse enhetene relaterer til hverandre. Denne grunnleggende forskjellen gjør det mulig for både mennesker og maskiner å tolke, forespørre og resonnere rundt data på måter som tidligere var umulig med konvensjonelle databasesystemer.
Begrepet fikk stor utbredelse da Google introduserte sin Knowledge Graph i 2012, og revolusjonerte søkeresultater ved å gi direkte svar og vise sammenhenger mellom konsepter i stedet for bare å liste relevante lenker. Kunnskapsgrafer har imidlertid utviklet seg langt forbi forbrukerrettede søkeapplikasjoner. I dag bruker organisasjoner på tvers av bransjer kunnskapsgrafer for å organisere kompleks informasjon, drive kunstig intelligens-systemer og avdekke skjulte mønstre i sine dataøkosystemer. Styrken til en kunnskapsgraf ligger i evnen til å fange kontekst, opprinnelse og mening på tvers av hele datalandskapet, og gjør den til et uunnværlig verktøy for moderne virksomheter som ønsker konkurransefortrinn gjennom intelligent databehandling.
Hver kunnskapsgraf består av fire essensielle komponenter som samarbeider for å skape et omfattende, forespørrbart informasjonssystem:
| Komponent | Definisjon | Eksempel |
|---|---|---|
| Enheter (Noder) | Objekter eller konsepter som beskrives med unike identifikatorer | “Albert Einstein”, “Apple Inc.”, “New York City” |
| Relasjoner (Kanter) | Forbindelser mellom noder som viser hvordan enheter samhandler | “Albert Einstein oppfant relativitetsteorien” |
| Attributter (Egenskaper) | Kjennetegn som beskriver noder og gir kontekst | Fødselsdato: 14. mars 1879; Sted: Berlin, Tyskland |
| Ontologier & Skjemaer | Formelle definisjoner og regler som styrer enhetstyper og relasjoner | RDF Schema (RDFS), Web Ontology Language (OWL), Schema.org |
Enheter utgjør fundamentet i enhver kunnskapsgraf, og representerer virkelige objekter på en strukturert og organisert måte. Hver enhet har en unik identifikator og kan ha flere egenskaper og relasjoner til andre enheter. Relasjoner, også kalt kanter, er forbindelsene som binder enhetene sammen og uttrykker hvordan de samhandler og relaterer. Disse relasjonene kan være rettede (fra én enhet til en annen, som “John jobber i Google”) eller urettede (gjensidige forbindelser, som “John og Mary er venner”). Utover enkle assosiasjoner kan relasjoner representere hierarkiske strukturer, årsakssammenhenger, sekvensielle avhengigheter eller nettverksbaserte interaksjoner.
Attributter eller egenskaper gir ytterligere beskrivende informasjon om enheter, og hjelper til å skille dem fra lignende enheter i nettverket. Disse kan variere fra enkle kjennetegn som alder eller sted, til komplekse, domenespesifikke egenskaper som medisinske tilstander, finansielle målinger eller tekniske spesifikasjoner. Til slutt etablerer ontologier og skjemaer det formelle rammeverket som styrer hvordan enheter, relasjoner og egenskaper defineres og brukes. Populære ontologier inkluderer RDF Schema (RDFS) for grunnleggende hierarkier, Web Ontology Language (OWL) for avansert resonnement, og Schema.org for standardisert webdatarepresentasjon. Disse komponentene arbeider sammen for å skape et fleksibelt, utvidbart system som kan representere kunnskap på tvers av nær sagt alle domener.
Kunnskapsgrafer fungerer ved å skape et semantisk lag over en organisasjons dataøkosystem, og omformer ulike datakilder til et samlet, sammenkoblet kunnskapsnettverk. Når data mates inn i en kunnskapsgraf, bruker maskinlæringsalgoritmer drevet av naturlig språkprosessering (NLP) en prosess kalt semantisk berikelse. Denne prosessen identifiserer individuelle objekter i dataene og forstår automatisk relasjonene mellom forskjellige objekter, selv når de kommer fra kilder med ulike strukturelle egenskaper. Det semantiske laget er spesielt kraftig fordi det kan skille mellom ord med flere betydninger—for eksempel å forstå at “Apple” i én sammenheng viser til teknologiselskapet, mens det i en annen viser til frukten.
Når kunnskapsgrafen er bygget, gjør den det mulig for avanserte spørresystemer og søkesystemer å hente ut helhetlige svar på komplekse spørsmål. I stedet for å kreve nøyaktige nøkkelord, kan semantiske søkesystemer forstå brukerens hensikt og returnere relevant informasjon selv om spesifikke termer ikke er eksplisitt brukt. Denne kontekstuelle forståelsen oppnås gjennom grafens evne til å modellere relasjoner og avhengigheter eksplisitt. Dataintegrasjonsarbeidet rundt kunnskapsgrafer genererer også ny kunnskap ved å etablere forbindelser mellom tidligere ikke-relaterte datapunkter, og avdekker innsikter som kanskje ikke var åpenbare i isolerte datasett. For organisasjoner betyr dette at kunnskapsgrafer kan eliminere manuelt dataarbeid og integrasjonsarbeid, akselerere forretningsbeslutninger og muliggjøre selvbetjent analyse der forretningsbrukere kan forespørre grafen direkte uten IT-støtte.
Kunnskapsgrafer har blitt stadig viktigere for moderne organisasjoner av flere overbevisende grunner. Raskere beslutningstaking er en av de mest umiddelbare fordelene—kunnskapsgrafer gir en 360-graders oversikt over dataenheter og deres relasjoner, slik at analytikere raskt kan identifisere mønstre, forbindelser og innsikter som ellers ville tatt langt tid å avdekke med tradisjonelle analysemetoder. Dette helhetlige perspektivet gjør det mulig for organisasjoner å ta informerte beslutninger basert på komplett informasjon, i stedet for fragmenterte datavisninger.
Forbedret kundeopplevelse er en annen avgjørende fordel. Ved å koble kundedata på tvers av ulike kontaktpunkter—inkludert kjøpshistorikk, supportinteraksjoner, nettleseratferd og demografisk informasjon—kan organisasjoner lage detaljerte kundeprofiler som muliggjør personaliserte og relevante opplevelser. Denne samlede visningen støtter målrettet markedsføring, produktanbefalinger og proaktiv kundeservice. Effektiv databehandling oppnås gjennom kunnskapsgrafers evne til å koble og harmonisere data fra ulike kilder, og bryte ned organisatoriske siloer som normalt hindrer effektiv datadeling og samarbeid. Ved å ta i bruk beste praksis for datatilrettelegging og utnytte kunnskapsgrafers semantiske kraft, oppnår organisasjoner et betydelig konkurransefortrinn.
Å styrke forretningsbrukere med selvbetjente muligheter demokratiserer datatilgangen i hele organisasjonen. I stedet for å være avhengig av IT-avdelinger for å få svar på hvert dataspørsmål, kan forretningsbrukere samhandle direkte med og forespørre kunnskapsgrafer ved hjelp av intuitive visualiseringsverktøy, akselerere innsiktsgenerering og redusere flaskehalser. Akselererte AI- og maskinlæringsinitiativ drar stor nytte av kunnskapsgrafers strukturerte, semantiske natur. De sammenkoblede dataene gir ideelt treningsgrunnlag for AI-systemer, slik at de kan utlede intrikate mønstre, trender og utfall, samtidig som de reduserer tid og kostnader til modellutvikling. Kunnskapsgrafer støtter også avanserte applikasjoner som Retrieval-Augmented Generation (RAG), hvor AI-systemer kan trekke komplekse relasjoner fra store datasett for å resonnere mer som mennesker og levere mer nøyaktige, kontekstuelt relevante svar.
Kunnskapsgrafer har beveget seg forbi teoretiske konsepter og leverer nå konkret verdi på tvers av ulike sektorer. Innen helsevesen og livsvitenskap bruker medisinske forskningsnettverk og kliniske beslutningsstøtteverktøy kunnskapsgrafer for å koble symptomer, behandlinger, utfall og medisinsk litteratur, slik at klinikere og forskere kan avdekke innsikter som forbedrer pasientbehandling og akselererer legemiddelutvikling. Finanstjenester bruker kunnskapsgrafer til kjenn-din-kunde (KYC) og anti-hvitvaskingsinitiativer, ved å kartlegge relasjoner mellom personer, kontoer og transaksjoner for å avdekke mistenkelige aktiviteter og forhindre økonomisk kriminalitet. Detaljhandel og e-handel benytter kunnskapsgrafer for å drive anbefalingsmotorer og oppsalg-/kryssalgstrategier, analysere kjøpsatferd og demografiske trender for å foreslå produkter kundene mest sannsynlig kjøper.
Underholdningsplattformer som Netflix, Spotify og Amazon bruker kunnskapsgrafer for å bygge sofistikerte anbefalingsmotorer som analyserer brukerengasjement og innholdsrelasjoner for å foreslå filmer, musikk og produkter tilpasset individuelle preferanser. Optimalisering av forsyningskjeder er et annet kraftig bruksområde, der kunnskapsgrafer modellerer komplekse leverandørrelasjoner, logistikknettverk og vareflyt, og muliggjør sanntidsdeteksjon av flaskehalser og risikoredusering. Regulatorisk etterlevelse og styring drar nytte av kunnskapsgrafers evne til automatisk å spore dataopprinnelse, kartlegge dataenheter til systemer og retningslinjer, og dokumentere overholdelse av regelverk som GDPR og HIPAA. For eksempel kan en kunnskapsgraf umiddelbart vise alle steder der personidentifiserbar informasjon (PII) er lagret, hvilke applikasjoner som har tilgang, og hvilke personvernregler som gjelder—kritiske egenskaper for moderne datastyring.
Selv om kunnskapsgrafer gir betydelige fordeler, må organisasjoner nøye håndtere flere utfordringer for å lykkes med implementeringen. Datakvalitet og kuratering er vedvarende bekymringer, da nøyaktigheten og fullstendigheten til kunnskapsgrafen direkte påvirker kvaliteten på innsiktene den gir. Organisasjoner må etablere prosesser for validering av data, løse inkonsistenser og holde dataene oppdaterte etter hvert som ny informasjon blir tilgjengelig. Skalerbarhet og vedlikehold gir tekniske utfordringer, spesielt når kunnskapsgrafer vokser til å omfatte millioner eller milliarder av enheter og relasjoner. Å sikre at forespørselsytelsen forblir akseptabel og at systemet kan håndtere økende datavolumer krever nøye arkitektonisk planlegging og investering i infrastruktur.
Enhetsoppløsning—prosessen med å identifisere når ulike datarepresentasjoner viser til samme virkelige enhet—er et komplekst problem som kan ha stor innvirkning på kunnskapsgrafens kvalitet. Personvern og sikkerhet blir stadig viktigere når kunnskapsgrafer inneholder sensitive eller personlige data, og krever robuste tilgangskontroller, kryptering og etterlevelsesmekanismer. Skjevhet i kunnskapsgrafer kan videreføre eller forsterke eksisterende skjevheter i kildedata, noe som potensielt kan føre til urettferdige eller diskriminerende utfall i AI-applikasjoner som drives av grafen. Organisasjoner må implementere nøye overvåkning og styringspraksis for å identifisere og motvirke skjevhet. Til tross for disse utfordringene gjør den strategiske verdien av kunnskapsgrafer dem verdt investeringen for organisasjoner som ønsker å utnytte data som et konkurransefortrinn.
Kunnskapsgrafer representerer et grunnleggende skifte i hvordan organisasjoner håndterer, styrer og utvinner verdi fra sine data. Ved å omforme statiske datalagre til levende, sammenkoblede kunnskapsnettverk, muliggjør de smartere oppdagelse, robust styring og AI-klare dataøkosystemer. Etter hvert som kunstig intelligens fortsetter å utvikle seg og organisasjoner samler stadig større datamengder, vil viktigheten av kunnskapsgrafer bare øke. De gir det kontekstuelle fundamentet som kreves for avansert analyse, maskinlæring og forklarbar AI—slik at organisasjoner kan avdekke skjulte mønstre, automatisere resonnement og støtte beslutningstaking i stor skala. For enhver organisasjon som ønsker å forbedre AI-evner, styrke kundeopplevelser eller oppnå konkurransefortrinn gjennom bedre datautnyttelse, bør implementering av kunnskapsgrafløsninger være en strategisk prioritet i den digitale transformasjonsstrategien.
Akkurat som kunnskapsgrafer organiserer informasjon intelligent, sporer vår AI-overvåkningsplattform hvordan merkevaren din vises på ChatGPT, Perplexity og andre AI-søkemotorer. Sørg for merkevaresynlighet i en AI-drevet fremtid.
Lær hva en kunnskapsgraf er, hvordan søkemotorer bruker dem for å forstå enhetsrelasjoner, og hvorfor de er viktige for AI-synlighet og merkevareovervåking på t...

Diskusjon i fellesskapet som forklarer Knowledge Graphs og deres betydning for synlighet i AI-søk. Eksperter deler hvordan entiteter og relasjoner påvirker AI-s...
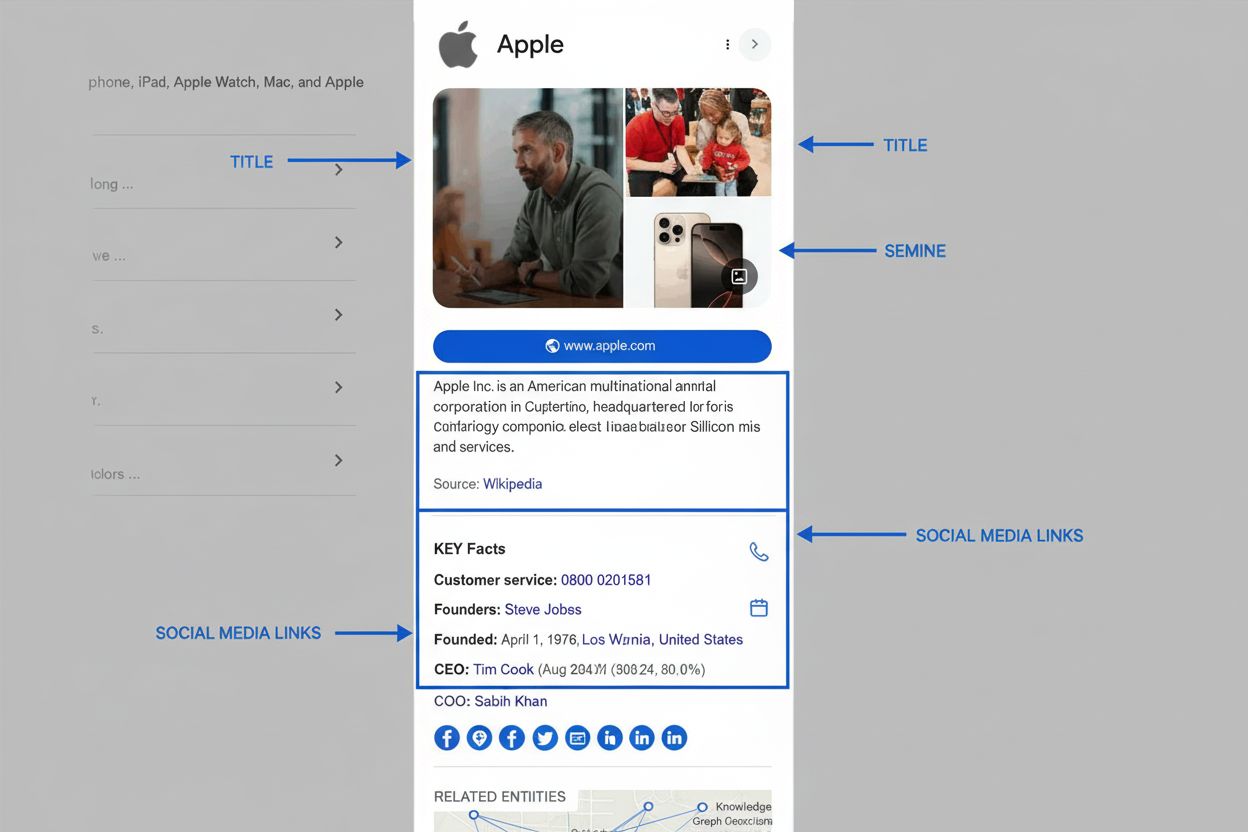
Lær hva et kunnskapspanel er, hvordan det fungerer, hvorfor det er viktig for SEO og AI-overvåkning, og hvordan du kan kreve eller optimalisere et for merkevare...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.