
Hvordan bestride og korrigere unøyaktig informasjon i AI-svar
Lær hvordan du bestrider unøyaktig AI-informasjon, rapporterer feil til ChatGPT og Perplexity, og implementerer strategier for å sikre at merkevaren din represe...
9 min lesing
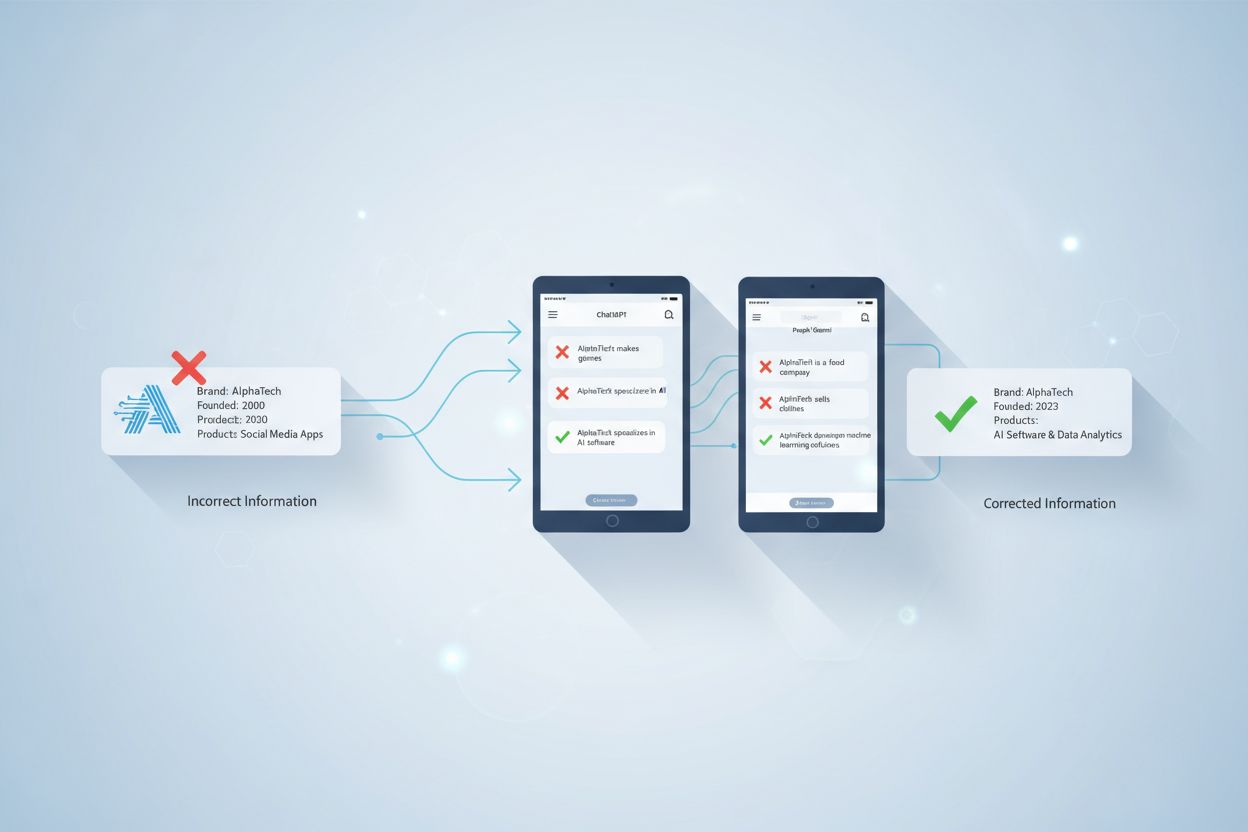
Korrigering av AI-feilinformasjon viser til strategier og verktøy for å identifisere og håndtere feilaktig merkevareinformasjon som dukker opp i AI-genererte svar fra systemer som ChatGPT, Gemini og Perplexity. Det innebærer overvåking av hvordan AI-systemer fremstiller merkevaren og å gjennomføre rettelser på kildenivå for å sikre at korrekt informasjon distribueres på tvers av betrodde plattformer. I motsetning til tradisjonell faktasjekk fokuserer dette på å rette opp kildene AI-systemene stoler på, snarere enn AI-svarene selv. Dette er avgjørende for å opprettholde omdømme og nøyaktighet i et AI-drevet søkemiljø.
Korrigering av AI-feilinformasjon viser til strategier og verktøy for å identifisere og håndtere feilaktig merkevareinformasjon som dukker opp i AI-genererte svar fra systemer som ChatGPT, Gemini og Perplexity. Det innebærer overvåking av hvordan AI-systemer fremstiller merkevaren og å gjennomføre rettelser på kildenivå for å sikre at korrekt informasjon distribueres på tvers av betrodde plattformer. I motsetning til tradisjonell faktasjekk fokuserer dette på å rette opp kildene AI-systemene stoler på, snarere enn AI-svarene selv. Dette er avgjørende for å opprettholde omdømme og nøyaktighet i et AI-drevet søkemiljø.
Korrigering av AI-feilinformasjon viser til strategiene, prosessene og verktøyene som brukes for å identifisere og håndtere feilaktig, utdatert eller misvisende informasjon om merkevarer som dukker opp i AI-genererte svar fra systemer som ChatGPT, Gemini og Perplexity. Nyere forskning viser at omtrent 45 % av AI-forespørsler gir feilaktige svar, noe som gjør merkevarenøyaktighet i AI-systemer til et kritisk tema for bedrifter. I motsetning til tradisjonelle søkeresultater hvor merkevarer kan kontrollere egne oppføringer, sammenstiller AI-systemer informasjon fra flere kilder på nettet. Dette skaper et komplekst landskap hvor feilinformasjon kan leve i det stille. Utfordringen handler ikke bare om å rette enkeltstående AI-svar—det handler om å forstå hvorfor AI-systemene får feil om merkevaren i utgangspunktet, og å gjennomføre systematiske rettelser på kildenivå.
AI-systemer finner ikke opp merkevareinformasjon fra ingenting; de setter sammen det som allerede finnes på internett. Men denne prosessen gir flere forutsigbare feilkilder som fører til feilaktig fremstilling av merkevarer:
| Årsak | Hvordan skjer det | Forretningspåvirkning |
|---|---|---|
| Kildeinkonsistens | Merkevaren beskrevet ulikt på nettsider, kataloger og artikler | AI tolker feil konsensus fra motstridende informasjon |
| Utdaterte autoritative kilder | Gamle Wikipedia-artikler, katalogoppføringer eller sammenligningssider har feil data | Nyere rettelser ignoreres fordi eldre kilder har høyere autoritetssignaler |
| Entitetsforvirring | Lignende merkenavn eller overlappende kategorier forvirrer AI-systemene | Konkurrenter får æren for dine egenskaper eller merkevaren utelates helt |
| Manglende primærsignaler | Manglende strukturert data, tydelige Om oss-sider eller konsistente begreper | AI må gjette, noe som gir vage eller feilaktige beskrivelser |
Når en merkevare beskrives ulikt på ulike plattformer, sliter AI-systemer med å avgjøre hvilken versjon som er autoritativ. I stedet for å be om avklaring, tolker de konsensus basert på frekvens og oppfattet autoritet—selv når denne konsensusen er feil. Små forskjeller i navn, beskrivelser eller posisjonering blir ofte duplisert på tvers av plattformer, og når de gjentas, blir disse fragmentene signaler AI-modellene anser som pålitelige. Problemet forsterkes når utdaterte, men autoritative sider inneholder feil: AI-systemer favoriserer ofte disse eldre kildene fremfor nyere rettelser, særlig hvis rettelsene ikke har spredt seg til betrodde plattformer.
Å rette feilaktig merkevareinformasjon i AI-systemer krever en helt annen tilnærming enn tradisjonell SEO-arbeid. I tradisjonell SEO oppdaterer merkevarer egne oppføringer, korrigerer NAP-data (navn, adresse, telefon) og optimaliserer innhold. AI-merkekorrigering handler om å endre det betrodde kilder sier om din merkevare, ikke om å kontrollere din egen synlighet. Du retter ikke AI direkte—du retter det AI stoler på. Å forsøke å “fikse” AI-svar ved å gjenta feilaktige påstander (selv for å avkrefte dem) kan slå tilbake ved å forsterke assosiasjonen du ønsker å fjerne. AI-systemer gjenkjenner mønstre, ikke intensjon. Derfor må alle rettelser starte på kildenivå, og man må jobbe baklengs fra der AI faktisk lærer informasjonen fra.
Før du kan rette feilaktig merkevareinformasjon, må du ha oversikt over hvordan AI-systemer beskriver merkevaren din i dag. Effektiv overvåking fokuserer på:
Manuelle sjekker alene er upålitelige fordi AI-svar varierer etter prompt, kontekst og oppdateringssyklus. Strukturerte overvåkingsverktøy gir innsikten du trenger for å oppdage feil tidlig, før de setter seg fast i AI-systemene. Mange merkevarer oppdager ikke feilfremstilling i AI før en kunde nevner det eller det oppstår en krise. Proaktiv overvåking forhindrer dette ved å fange opp inkonsistenser før de sprer seg.
Når du har identifisert feilaktig merkevareinformasjon, må rettelsen skje der AI faktisk lærer fra—ikke bare der feilen vises. Effektive kildenivå-rettelser inkluderer:
Hovedregelen er: rettelser fungerer kun når de gjøres på kildenivå. Å endre hva som vises i AI-svar uten å rette opp den underliggende kilden er kun midlertidig. AI-systemer revurderer signaler kontinuerlig etter hvert som nytt innhold publiseres og gamle sider dukker opp igjen. En rettelse som ikke tar tak i kilden vil til slutt bli overskrevet av den opprinnelige feilinformasjonen.
Når feilaktig merkevareinformasjon rettes på tvers av kataloger, markedsplasser eller AI-drevne plattformer, krever de fleste systemer dokumentasjon som knytter merkevaren til legitimt eierskap og bruk. Vanlige dokumentasjonskrav inkluderer:
Målet er ikke mengde—men konsistens. Plattformer vurderer om dokumentasjon, oppføringer og offentlig merkevaredata stemmer overens. Å ha dette klart på forhånd reduserer avvisningsrunder og gir raskere godkjenning når feilaktig merkevareinformasjon skal rettes i stor skala. Konsistens på tvers av kilder signaliserer til AI-systemer at informasjonen om din merkevare er pålitelig og autoritativ.
Flere verktøy hjelper nå team å følge merkevarefremstilling på tvers av AI-søk og nettet generelt. Selv om funksjonene overlapper, fokuserer de hovedsakelig på synlighet, attribusjon og konsistens:
Disse verktøyene retter ikke feilaktig informasjon direkte. De hjelper team å oppdage feil tidlig, finne datakonflikter før de sprer seg, vurdere om kildenivå-rettelser forbedrer AI-nøyaktighet og overvåke langsiktige trender i AI-attribusjon og synlighet. Når de brukes sammen med kildekorrigeringer og dokumentasjon, gir overvåkingsverktøy tilbakemeldingssløyfen som kreves for å fikse feilaktig merkevareinformasjon på en bærekraftig måte.
AI-søkenøyaktighet øker når merkevarer er tydelig definerte entiteter, ikke vage aktører i en kategori. For å redusere feilfremstilling av merkevaren i AI-systemer, fokuser på:
Målet er ikke å si mer—men å si det samme overalt. Når AI-systemer møter konsistente merkevaredefinisjoner fra autoritative kilder, slutter de å gjette og begynner å gjenta korrekt informasjon. Dette er spesielt viktig for merkevarer som opplever feilaktige omtaler, feilattribusjon til konkurrenter eller utelatelse fra relevante AI-svar. Selv etter at du har rettet feil, er ikke nøyaktighet permanent. AI-systemer revurderer signaler kontinuerlig, så vedvarende klarhet er avgjørende.
Det finnes ingen fast tidslinje for å rette feilaktig merkevareinformasjon i AI-systemer. AI-modeller oppdaterer seg basert på signalstyrke og konsensus, ikke innsendingstidspunkt. Typiske mønstre inkluderer:
Fremdrift viser seg sjelden som et plutselig “fikset” svar. Se heller etter indirekte tegn: mindre variasjon i AI-svar, færre motstridende beskrivelser, mer konsistente kilder og gradvis innlemmelse av merkevaren der den tidligere var utelatt. Stagnasjon ser annerledes ut—hvis samme feilaktige frase vedvarer til tross for flere rettelser, tyder det som regel på at kilden ikke er korrigert, eller at det trengs sterkere signalforsterkning andre steder.
Den mest pålitelige måten å rette feilaktig merkevareinformasjon på, er å redusere forutsetningene for at den skal oppstå. Effektiv forebygging inkluderer:
Merkevarer som behandler AI-synlighet som et levende system—ikke et engangsoppryddingsprosjekt—henter seg raskere inn etter feil og opplever færre gjentatte feilfremstillinger. Forebygging handler ikke om å kontrollere AI-svar. Det handler om å vedlikeholde rene, konsistente input AI-systemene kan gjenta trygt. Etter hvert som AI-søk utvikler seg, er det de merkevarene som ser på feilretting som en kontinuerlig prosess med overvåking, kildehåndtering og strategisk forsterkning av korrekt informasjon på betrodde plattformer, som lykkes.
Korrigering av AI-feilinformasjon er prosessen med å identifisere og rette feilaktig, utdatert eller misvisende informasjon om merkevarer som dukker opp i AI-genererte svar. I motsetning til tradisjonell faktasjekk fokuserer dette på å korrigere kildene AI-systemene stoler på (kataloger, artikler, oppføringer) istedenfor å forsøke å redigere AI-svar direkte. Målet er at brukere skal få korrekt informasjon om din merkevare når de spør et AI-system.
AI-systemer som ChatGPT, Gemini og Perplexity påvirker nå hvordan millioner lærer om merkevarer. Forskning viser at 45 % av AI-forespørsler inneholder feil, og feilaktig merkevareinformasjon kan skade omdømmet, forvirre kunder og føre til tapte forretninger. I motsetning til tradisjonelle søk der merkevarer kontrollerer sine egne oppføringer, henter AI-systemer informasjon fra mange kilder, noe som gjør merkevarenøyaktighet vanskeligere å kontrollere, men desto viktigere å håndtere.
Nei, direkte korrigering fungerer ikke effektivt. AI-systemer lagrer ikke merkevarefakta på redigerbare steder – de sammenstiller svar fra eksterne kilder. Å be AI om å 'rette' informasjonen gjentatte ganger kan faktisk forsterke feil ved å styrke assosiasjonen du prøver å fjerne. I stedet må rettelser skje på kildenivå: oppdatere kataloger, fikse utdaterte oppføringer og publisere korrekt informasjon på betrodde plattformer.
Det finnes ingen fast tidslinje fordi AI-systemer oppdateres basert på signalstyrke og konsensus, ikke innsendingstidspunkt. Mindre faktafeil rettes vanligvis i løpet av 2–4 uker, avklaringer på entitetsnivå tar 1–3 måneder, og konkurransefortrengning kan ta 3–6 måneder eller lengre. Fremdrift vises sjelden som et plutselig «fikset» svar – se heller etter mindre variasjon i svarene og mer konsistente sitater på tvers av kilder.
Flere verktøy sporer nå merkevareomtale på tvers av AI-plattformer: Wellows overvåker omtaler og sentiment på ChatGPT, Gemini og Perplexity; Profound sammenligner synlighet på tvers av LLM-er; Otterly.ai analyserer merkevaresentiment i AI-svar; BrandBeacon gir posisjoneringsanalyse; Ahrefs Brand Radar sporer omtale på nettet; og AmICited.com spesialiserer seg på å overvåke hvordan merkevarer siteres og fremstilles i AI-systemer. Disse verktøyene hjelper deg å oppdage feil tidlig og vurdere om rettelser virker.
AI-hallusinasjoner oppstår når AI genererer informasjon som ikke er basert på treningsdata eller er feil dekodet. AI-feilinformasjon er falsk eller misvisende informasjon i AI-svar, som kan skyldes hallusinasjoner, men også utdaterte kilder, entitetsforvirring eller inkonsistente data på tvers av plattformer. Korrigering av feilinformasjon omfatter både hallusinasjoner og kildenivå-feil som fører til feilaktig merkevarefremstilling.
Overvåk hvordan AI-systemer beskriver merkevaren din ved å stille dem spørsmål om selskapet, produkter og posisjonering. Se etter utdatert informasjon, feilaktige beskrivelser, manglende detaljer eller feil attribusjon til konkurrenter. Bruk overvåkingsverktøy for å spore omtaler på ChatGPT, Gemini og Perplexity. Sjekk om merkevaren din utelates fra relevante AI-svar. Sammenlign AI-beskrivelser med din offisielle merkevareinformasjon for å avdekke avvik.
Det er en kontinuerlig prosess. AI-systemer revurderer signaler fortløpende etter hvert som nytt innhold publiseres og eldre sider dukker opp igjen. En engangskorrigering uten løpende overvåking vil til slutt bli overskrevet av den opprinnelige feilinformasjonen. Merkevarer som lykkes, behandler AI-synlighet som et levende system, med konsistente merkevaredefinisjoner på tvers av kilder, jevnlig revisjon av kataloger og kontinuerlig overvåking av AI-omtaler for å fange opp nye feil før de sprer seg.
Følg med på hvordan AI-systemer som ChatGPT, Gemini og Perplexity fremstiller din merkevare. Få sanntidsinnsikt i merkevareomtale, sitater og synlighet på tvers av AI-plattformer med AmICited.com.
Lær hvordan du bestrider unøyaktig AI-informasjon, rapporterer feil til ChatGPT og Perplexity, og implementerer strategier for å sikre at merkevaren din represe...
Lær effektive metoder for å identifisere, verifisere og korrigere unøyaktig informasjon i AI-genererte svar fra ChatGPT, Perplexity og andre AI-systemer.

Lær hvordan du identifiserer, forebygger og korrigerer AI-feilinformasjon om din merkevare. Oppdag 7 dokumenterte strategier og verktøy for å beskytte ditt omdø...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.