
A/B-testing for AI-synlighet: Metodikk og beste praksis
Bli ekspert på A/B-testing for AI-synlighet med vår omfattende guide. Lær GEO-eksperimenter, metodikk, beste praksis og virkelige casestudier for bedre AI-overv...
9 min lesing

Isolerte sandkassemiljøer designet for å validere, evaluere og feilsøke kunstig intelligens-modeller og applikasjoner før produksjonsutrulling. Disse kontrollerte rommene muliggjør testing av AI-innhold på tvers av ulike plattformer, måling av metrikker og sikrer pålitelighet uten å påvirke levende systemer eller eksponere sensitiv data.
Isolerte sandkassemiljøer designet for å validere, evaluere og feilsøke kunstig intelligens-modeller og applikasjoner før produksjonsutrulling. Disse kontrollerte rommene muliggjør testing av AI-innhold på tvers av ulike plattformer, måling av metrikker og sikrer pålitelighet uten å påvirke levende systemer eller eksponere sensitiv data.
Et AI-testmiljø er et kontrollert, isolert datarom designet for å validere, evaluere og feilsøke kunstig intelligens-modeller og applikasjoner før de rulles ut til produksjonssystemer. Det fungerer som en sandkasse hvor utviklere, dataforskere og QA-team trygt kan kjøre AI-modeller, teste ulike konfigurasjoner og måle ytelse mot forhåndsdefinerte metrikker uten å påvirke levende systemer eller eksponere sensitiv data. Disse miljøene etterligner produksjonsforhold samtidig som de opprettholder full isolasjon, slik at team kan identifisere problemer, optimalisere modellatferd og sikre pålitelighet i ulike scenarier. Testmiljøet fungerer som en kritisk kvalitetsport i AI-utviklingslivssyklusen, og bygger bro mellom eksperimentell prototyping og utrulling på foretaksnivå.

Et omfattende AI-testmiljø består av flere sammenkoblede tekniske lag som sammen gir fullstendige testmuligheter. Modellkjøringslaget håndterer selve inferensen og beregningene, og støtter flere rammeverk (PyTorch, TensorFlow, ONNX) og modelltyper (LLM-er, datavisjon, tidsserier). Databehandlingslaget administrerer testdatasett, fiksturer og syntetisk datagenerering, samtidig som det opprettholder dataisolasjon og samsvar. Evalueringsrammeverket inkluderer metrikmotorer, påstandsbiblioteker og poengsystemer som måler modellutdata mot forventede resultater. Overvåkings- og logglaget fanger opp kjørespor, ytelsesmetrikker, latensdata og feillogger for analyse etter testing. Orkestreringslaget håndterer testarbeidsflyter, parallell kjøring, ressursallokering og miljøtilrettelegging. Nedenfor er en sammenligning av sentrale arkitekturkomponenter på tvers av ulike testmiljøtyper:
| Komponent | LLM-testing | Datavisjon | Tidsserier | Multi-modal |
|---|---|---|---|---|
| Modell-runtime | Transformer-inferens | GPU-akselerert inferens | Sekvensiell behandling | Hybridkjøring |
| Dataformat | Tekst/tokens | Bilder/tensorer | Numeriske sekvenser | Blandet media |
| Evalueringsmetrikker | Semantisk likhet, hallusinasjon | Nøyaktighet, IoU, F1-score | RMSE, MAE, MAPE | Tverrmodal justering |
| Latenskrav | 100–500ms typisk | 50–200ms typisk | <100ms typisk | 200–1000ms typisk |
| Isolasjonsmetode | Container/VM | Container/VM | Container/VM | Firecracker microVM |
Moderne AI-testmiljøer må støtte heterogene modellekosystemer, slik at team kan evaluere applikasjoner på tvers av ulike LLM-leverandører, rammeverk og utrullingsmål samtidig. Multiplattform-testing gjør det mulig for organisasjoner å sammenligne modellutdata fra OpenAI GPT-4, Anthropic Claude, Mistral og åpne alternativer som Llama i samme testrammeverk, og legge til rette for informerte modellvalg. Plattformer som E2B tilbyr isolerte sandkasser som kjører kode generert av enhver LLM, og støtter Python, JavaScript, Ruby og C++ med full filsystemtilgang, terminalfunksjonalitet og pakkeinstallasjon. IntelIQ.dev muliggjør side-ved-side-sammenligning av flere AI-modeller med enhetlige grensesnitt, slik at team kan teste guardrailede prompt og policy-bevisste maler mot ulike leverandører. Testmiljøer må håndtere:
AI-testmiljøer betjener ulike organisatoriske behov innen utvikling, kvalitetssikring og samsvar. Utviklingsteam bruker testmiljøer til å validere modellatferd under iterativ utvikling, teste promptvariasjoner, finjustere parametre og feilsøke uventede utdata før integrasjon. Datavitenskapsteam benytter disse miljøene for å evaluere modellprestasjon på holdout-datasett, sammenligne ulike arkitekturer og måle metrikker som nøyaktighet, presisjon, tilbakekalling og F1-score. Produksjonsovervåking innebærer kontinuerlig testing av utrullede modeller mot basislinjemetrikker, oppdage ytelsesforringelse og utløse treningspipelines når kvalitetsterskler overskrides. Samsvars- og sikkerhetsteam bruker testmiljøer for å sikre at modeller møter regulatoriske krav, ikke gir partiske utdata og håndterer sensitiv data korrekt. Foretaksapplikasjoner inkluderer:
AI-testlandskapet inkluderer spesialiserte plattformer for ulike testscenarier og organisasjonsstørrelser. DeepEval er et åpen kildekode LLM-evalueringsrammeverk som tilbyr 50+ forskningsbaserte metrikker inkludert svarkorrekthet, semantisk likhet, hallusinasjonsdeteksjon og toksisitetsscore, med innebygd Pytest-integrasjon for CI/CD-arbeidsflyter. LangSmith (fra LangChain) tilbyr omfattende observerbarhet, evaluering og utrulling med innebygd sporing, promptversjonering og datasettadministrasjon for LLM-applikasjoner. E2B gir sikre, isolerte sandkasser drevet av Firecracker microVMs, støtter kodekjøring med under 200 ms oppstartstid, opptil 24-timers økter og integrasjon med store LLM-leverandører. IntelIQ.dev fokuserer på personvern-først-testing med ende-til-ende-kryptering, rollebasert tilgangskontroll og støtte for flere AI-modeller, inkludert GPT-4, Claude og åpne alternativer. Tabellen under sammenligner sentrale egenskaper:
| Verktøy | Hovedfokus | Metrikker | CI/CD-integrasjon | Flermodellstøtte | Prisstruktur |
|---|---|---|---|---|---|
| DeepEval | LLM-evaluering | 50+ metrikker | Innebygd Pytest | Begrenset | Åpen kildekode + sky |
| LangSmith | Observerbarhet og evaluering | Egendefinerte metrikker | API-basert | LangChain-økosystem | Freemium + enterprise |
| E2B | Kodekjøring | Ytelsesmetrikker | GitHub Actions | Alle LLM-er | Betal per bruk + enterprise |
| IntelIQ.dev | Personvern-først-testing | Egendefinerte metrikker | Arbeidsflytbygger | GPT-4, Claude, Mistral | Abonnementsbasert |
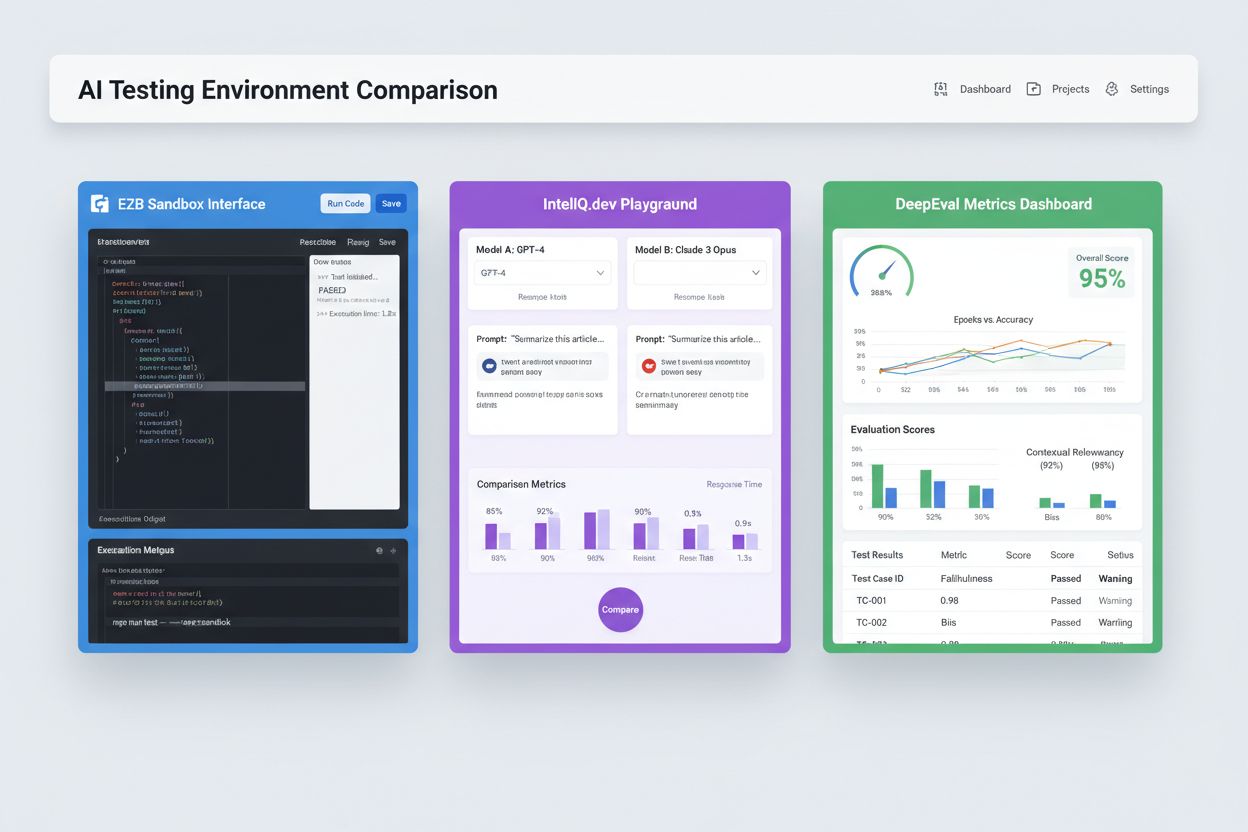
Foretaks-AI-testmiljøer må implementere strenge sikkerhetskontroller for å beskytte sensitiv data, opprettholde regulatorisk samsvar og forhindre uautorisert tilgang. Dataisolasjon krever at testdata aldri lekker til eksterne API-er eller tredjepartstjenester; plattformer som E2B bruker Firecracker microVM-er for full prosessisolasjon uten delt kjernekontakt. Krypteringsstandarder bør inkludere ende-til-ende-kryptering for data i ro og under overføring, med støtte for HIPAA, SOC 2 Type 2 og GDPR-krav. Tilgangskontroller må håndheve rollebaserte tillatelser, revisjonslogging og godkjenningsflyter for sensitive testscenarier. Beste praksis inkluderer: å holde separate testdatasett fri for produksjonsdata, bruke datamasking for personidentifiserbar informasjon (PII), benytte syntetisk datagenerering for realistisk testing uten personvernsrisiko, gjennomføre regelmessige sikkerhetsrevisjoner av testinfrastrukturen og dokumentere alle testresultater for samsvarsformål. Organisasjoner bør også implementere biasdeteksjon for å avdekke diskriminerende modellatferd, bruke tolkingsverktøy som SHAP eller LIME for å forstå modellbeslutninger, og etablere beslutningslogging for å spore hvordan modeller kommer frem til bestemte utfall for regulatorisk ansvarlighet.
AI-testmiljøer må sømløst integreres i eksisterende kontinuerlige integrasjons- og utrullingspipelines for å muliggjøre automatiserte kvalitetsporter og raske iterasjoner. Naturlig CI/CD-integrasjon gjør at testrutiner kan utløses automatisk ved kode-commits, pull requests eller planlagte intervaller via plattformer som GitHub Actions, GitLab CI eller Jenkins. DeepEval sin Pytest-integrasjon lar utviklere skrive testcaser som vanlige Python-tester som kjøres i eksisterende CI-arbeidsflyter, med resultater rapportert sammen med tradisjonelle enhetstester. Automatisert evaluering kan måle modellens ytelsesmetrikker, sammenligne utdata mot basisversjoner og blokkere utrulling hvis kvalitetskrav ikke oppfylles. Artefaktforvaltning innebærer lagring av testdatasett, modellkontrollpunkter og evalueringsresultater i versjonskontroll eller artefaktlagre for reproduserbarhet og revisjonsspor. Integrasjonsmønstre inkluderer:
AI-testmiljølandskapet utvikler seg raskt for å møte nye utfordringer innen modellkompleksitet, skala og heterogenitet. Agentisk testing blir stadig viktigere etter hvert som AI-systemer går utover enkel modellinferens til flertrinnsarbeidsflyter der agenter bruker verktøy, tar beslutninger og samhandler med eksterne systemer—noe som krever nye evalueringsrammeverk for å måle oppgavegjennomføring, sikkerhet og pålitelighet. Distribuert evaluering muliggjør testing i skala gjennom tusenvis av samtidige testinstanser i skyinfrastruktur, kritisk for forsterkende læring og storstilt modelltrening. Sanntidsovervåking går fra batch-evaluering til kontinuerlig, produksjonsgradert testing som oppdager ytelsesforringelse, datadrift og fremvoksende bias i levende systemer. Observerbarhetsplattformer som AmICited blir essensielle for omfattende AI-overvåking og innsikt, med sentraliserte dashbord som sporer modellprestasjon, bruksmønstre og kvalitetsmetrikker på tvers av hele AI-porteføljer. Fremtidige testmiljøer vil i økende grad innlemme automatisert utbedring, hvor systemer ikke bare oppdager problemer men automatisk utløser treningspipelines eller modelloppdateringer, samt tverrmodal evaluering, med støtte for samtidig testing av tekst-, bilde-, lyd- og videomodeller i enhetlige rammeverk.
Et AI-testmiljø er en isolert sandkasse hvor du trygt kan teste modeller, prompt og konfigurasjoner uten å påvirke levende systemer eller brukere. Produksjonsutrulling er det levende miljøet hvor modeller betjener ekte brukere. Testmiljøer lar deg fange opp problemer, optimalisere ytelse og validere endringer før de når produksjon, noe som reduserer risiko og sikrer kvalitet.
Ja, moderne AI-testmiljøer støtter testing av flere modeller samtidig. Plattformer som E2B, IntelIQ.dev og DeepEval lar deg teste samme prompt eller input på tvers av ulike LLM-leverandører (OpenAI, Anthropic, Mistral osv.) samtidig, slik at du kan sammenligne utdata og ytelsesmetrikker direkte.
Enterprise AI-testmiljøer implementerer flere sikkerhetslag, inkludert dataisolering (containere eller microVM-er), ende-til-ende-kryptering, rollebasert tilgangskontroll, revisjonslogging og samsvarssertifiseringer (SOC 2, GDPR, HIPAA). Data forlater aldri det isolerte miljøet med mindre det eksplisitt eksporteres, noe som beskytter sensitiv informasjon.
Testmiljøer muliggjør samsvar ved å tilby revisjonsspor for alle modelevalueringer, støtte datamasking og syntetisk datagenerering, håndheve tilgangskontroller og opprettholde full isolasjon av testdata fra produksjonssystemer. Denne dokumentasjonen og kontrollen hjelper organisasjoner å møte regulatoriske krav som GDPR, HIPAA og SOC 2.
Viktige metrikker avhenger av brukstilfellet: for LLM-er, følg nøyaktighet, semantisk likhet, hallusinasjonsrater og latens; for RAG-systemer, mål kontekstpresisjon/tilbakekalling og troverdighet; for klassifiseringsmodeller, overvåk presisjon, tilbakekalling og F1-score; for alle modeller, følg ytelsesforringelse over tid og biasindikatorer.
Kostnadene varierer per plattform: DeepEval er åpen kildekode og gratis; LangSmith tilbyr et gratis nivå med betalte planer fra $39/måned; E2B bruker betalings-per-bruk basert på sandkassens kjøretid; IntelIQ.dev tilbyr abonnementsløsninger. Mange plattformer har også enterprise-priser for storskala utrulling.
Ja, de fleste moderne testmiljøer støtter CI/CD-integrasjon. DeepEval integreres naturlig med Pytest, E2B fungerer med GitHub Actions og GitLab CI, og LangSmith tilbyr API-basert integrasjon. Dette muliggjør automatisert testing ved hver kode-commit og håndheving av utrullingsporter.
Ende-til-ende-testing behandler hele AI-applikasjonen som en svart boks, og tester sluttresultatet mot forventet utfall. Komponentnivå-testing evaluerer individuelle deler (LLM-kall, retrievere, verktøybruk) separat med sporing og instrumentering. Komponentnivå-testing gir dypere innsikt i hvor problemer oppstår, mens ende-til-ende-testing validerer systemets samlede oppførsel.
AmICited sporer hvordan AI-systemer refererer til ditt merke og innhold på tvers av ChatGPT, Claude, Perplexity og Google AI. Få sanntidsoversikt over din AI-tilstedeværelse med omfattende overvåking og analyser.
Bli ekspert på A/B-testing for AI-synlighet med vår omfattende guide. Lær GEO-eksperimenter, metodikk, beste praksis og virkelige casestudier for bedre AI-overv...
Lær hva et AI Visibility Center of Excellence er, dets sentrale ansvarsområder, overvåkingskapasiteter, og hvordan det gjør det mulig for organisasjoner å oppre...
Lær hva et AI-plattform-økosystem er, hvordan sammenkoblede AI-systemer samarbeider, og hvorfor det er viktig å håndtere din merkevaretilstedeværelse på tvers a...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.