
Informasjonstetthet: Skap innhold med høy verdi for AI
Lær hvordan du lager innhold med høy informasjonstetthet som AI-systemer foretrekker. Mestre hypotesen om uniform informasjonstetthet og optimaliser innholdet d...
9 min lesing
Informasjonstetthet er forholdet mellom nyttig, unik informasjon og total innholdslengde. Høyere tetthet øker sannsynligheten for AI-sitater fordi AI-systemer prioriterer innhold som gir maksimal innsikt med færrest mulig ord. Det representerer et skifte fra søkeordfokusert optimalisering til informasjonsfokusert optimalisering, der hver setning må tilføre særskilt verdi. Denne målingen påvirker direkte om AI-systemer henter, vurderer og siterer innholdet ditt som autoritative kilder.
Informasjonstetthet er forholdet mellom nyttig, unik informasjon og total innholdslengde. Høyere tetthet øker sannsynligheten for AI-sitater fordi AI-systemer prioriterer innhold som gir maksimal innsikt med færrest mulig ord. Det representerer et skifte fra søkeordfokusert optimalisering til informasjonsfokusert optimalisering, der hver setning må tilføre særskilt verdi. Denne målingen påvirker direkte om AI-systemer henter, vurderer og siterer innholdet ditt som autoritative kilder.
Informasjonstetthet representerer forholdet mellom nyttig, unik og handlingsrettet informasjon og total innholdslengde—et kritisk mål som avgjør hvor effektivt AI-systemer kan trekke ut, vurdere og sitere innholdet ditt. I motsetning til forgjengeren søkeordtetthet, som målte prosentandelen av målsøkeord i et innhold, fokuserer informasjonstetthet på faktisk verdi og presisjon i hver setning. AI-systemer, spesielt store språkmodeller som driver GPT-er, Perplexity og Google AI Overviews, prioriterer innhold som gir maksimal innsikt med færrest mulig ord. Denne preferansen kommer av hvordan disse systemene behandler informasjon: de belønner semantisk rikdom—dybden av mening formidlet per tekstmengde—fremfor gjentakelse av søkeord. Når et AI-system møter innhold med høy tetthet, gjenkjenner det materialet som autoritativt, presist og verdig til sitering fordi hver setning tilfører særskilt verdi i stedet for fyll eller gjentakelser. Se forskjellen mellom disse to tilnærmingene til forklaring av fornybar energi: En lavtetthetsversjon kan lyde: “Fornybar energi er viktig. Fornybar energi kommer fra naturen. Fornybar energi er ren. Mange bruker fornybar energi.” Disse 24 ordene formidler ett grunnleggende konsept uten spesifisitet. Et alternativ med høy tetthet sier: “Solcelleanlegg omdanner 15–22 % av sollyset til elektrisitet, mens moderne vindturbiner oppnår kapasitetsfaktor på 35–45 %, noe som gjør begge til levedyktige alternativer til kullkraftverk som opererer på 33–48 % effektivitet.” Denne versjonen bruker 28 ord til å levere konkrete effektivitetsmålinger, fagterminologi og sammenlignende analyse—betydelig mer informasjonsverdi.
| Aspekt | Lav tetthet | Høy tetthet |
|---|---|---|
| Antall ord | 24 ord | 28 ord |
| Datapunkter | 0 | 4 spesifikke prosenttall |
| Fagtermer | 0 | 3 (fotovoltaisk, kapasitetsfaktor, effektivitet) |
| Sammenlignende verdi | Generisk utsagn | Direkte sammenligning mellom tre energikilder |
| Sannsynlighet for sitering | Lav | Høy |
Dette skillet har stor betydning for AI-sitater. Når AI-systemer skanner innhold for svar, vurderer de ikke bare relevans, men også informasjonsspesifisitet—forekomst av konkrete data, navngitte enheter, fagterminologi og direkte svar. Innhold med høy tetthet signaliserer ekspertise og gir nøyaktig den informasjonen AI-systemer trenger for å generere trygge svar med korrekt kildehenvisning. Dette skiftet fra søkeordbasert til informasjonsbasert optimalisering reflekterer hvordan moderne AI faktisk vurderer innholdskvalitet.
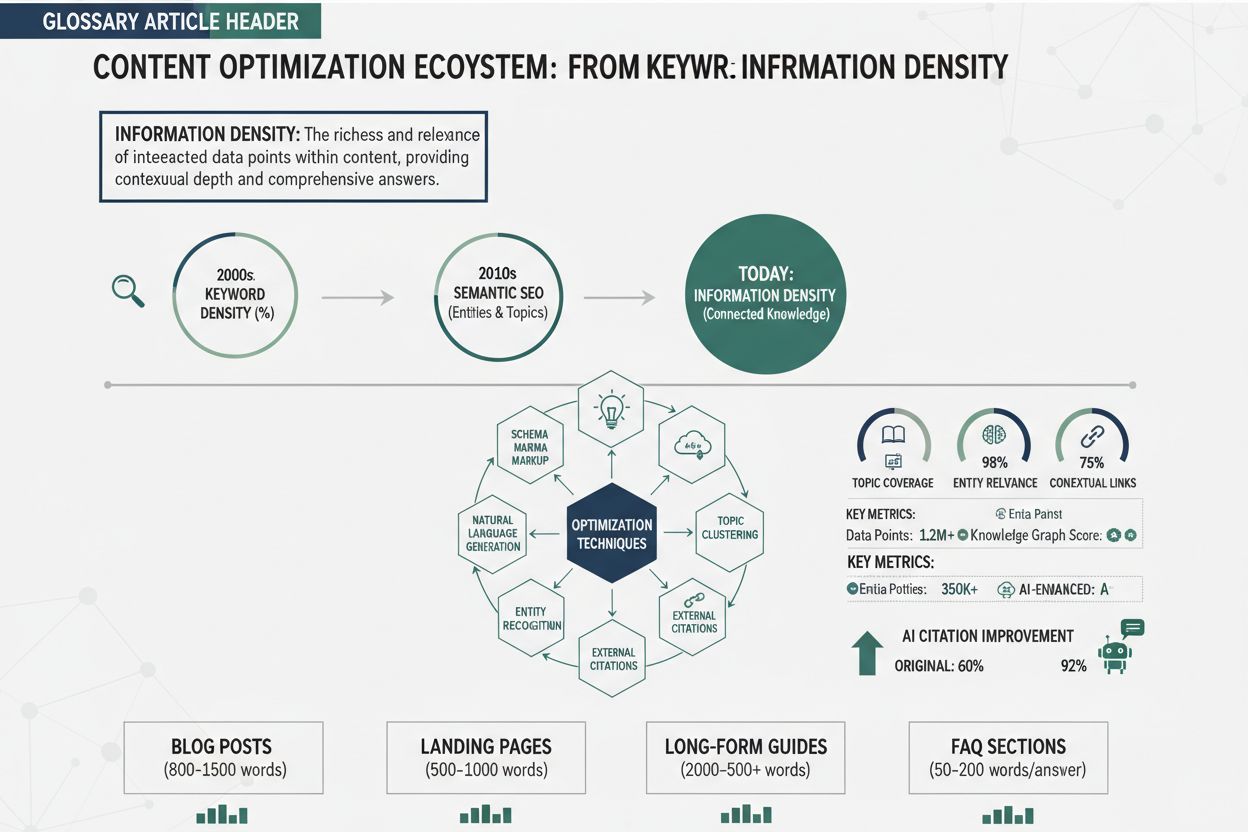
Utviklingen fra søkeordtetthet til informasjonstetthet markerer et grunnleggende skifte i hvordan søkemotorer og AI-systemer vurderer innholdskvalitet. Søkeordtetthet, det opprinnelige SEO-målet, målte hvor stor andel av innholdet som bestod av målsøkeord—typisk med mål om 1–3 % tetthet. Dette oppstod fra tidlige søkemotor-algoritmer som i stor grad baserte relevans på søkeordmatching. Men optimalisering for søkeordtetthet utartet raskt til overbruk av søkeord, hvor innholdsskapere tvang inn søkeord på unaturlig vis, og ofret lesbarhet og verdi for algoritmisk fordel. Fraser som “beste pizzarestaurant, beste pizza, pizzarestaurant nær meg, beste pizza nær meg” gjentatt på en side, illustrerte denne hule tilnærmingen—høy søkeordtetthet, men ingen ekstra informasjon. Den grunnleggende feilen med søkeordtetthet var antakelsen om at søkemotorer verdsatte antall søkeord over innholdskvalitet, og førte til et kappløp der kvantitet trumfet kvalitet.
Innføringen av maskinlæring og semantisk forståelse endret dette radikalt. Moderne AI-systemer, trent på milliarder av teksteksempler, lærte å gjenkjenne og straffe overbruk av søkeord, og belønne semantisk relevans—det konseptuelle forholdet mellom innhold og forespørsler, uavhengig av eksakt søkeordmatching. Latent Semantic Indexing (LSI) og senere transformermodeller som BERT viste at søkemotorer kunne forstå mening, kontekst og tematisk autoritet uten å telle søkeord. Dette åpnet for en ny optimaliseringsfilosofi: i stedet for å gjenta søkeord, kunne innhold skrives naturlig, så lenge hver setning tilførte unik, verdifull informasjon. Tidslinjen for denne utviklingen viser progresjonen tydelig:
Dagens AI-systemer vurderer innhold ut fra informasjonstetthet, og spør ikke “hvor ofte nevnes søkeordet?” men “hvor mye unik, verdifull og spesifikk informasjon gir dette innholdet?” Dette er en fullstendig omvendt tilnærming fra søkeordtetthet, og belønner innhold som gir maksimal innsikt fremfor søkeordgjentakelse.
AI-systemer henter og siterer innhold gjennom en avansert prosess kalt passasjeindeksering, der store dokumenter deles i mindre, semantisk sammenhengende biter som kan vurderes uavhengig for relevans og kvalitet. Når en bruker spør et AI-system, matcher ikke modellen bare søkeord—den søker i millioner av indekserte passasjer for å finne den mest relevante, autoritative og spesifikke informasjonen. Informasjonstetthet påvirker denne prosessen direkte fordi AI-systemer gir høyere tillitspoeng til biter som leverer konsentrert, spesifikk informasjon. En bit med tre konkrete datapunkter, navngitte enheter og fagterminologi får høyere relevanspoeng enn en like lang bit med generiske utsagn og gjentakelser. Denne mekanismen styrer siteringsatferd: AI-systemer siterer kilder de vurderer som svært autoritative og spesifikke, og innhold med høy tetthet får konsekvent disse høye poengene.
Konseptet svartetthet forklarer denne sammenhengen ytterligere. Svartetthet måler hvor direkte og fullstendig en bit svarer på et spesifikt spørsmål innenfor sin ordmengde. En 200-ords bit som svarer direkte med spesifikke data, metode og kontekst har høy svartetthet og får sterke siteringssignaler. Den samme 200-ords biten med innledning, forbehold og sidespor har lav svartetthet og får svakere signaler. AI-systemer optimaliserer for svartetthet fordi det korrelerer med brukeropplevelse—brukere foretrekker direkte, spesifikke svar fremfor lange forklaringer. Viktige faktorer som forbedrer informasjonstetthet og siteringsverdi inkluderer:
Forskning viser at biter med tre eller flere spesifikke datapunkter får 2,5 ganger høyere siteringsrate enn generiske utsagn. Biter som svarer på spørsmål i løpet av de første 1–2 setningene gir 40 % høyere gjenfinningsfrekvens. Dette viser at informasjonstetthet ikke bare er en stilpreferanse—det er en målbar faktor som direkte avgjør om AI-systemer henter, vurderer og siterer innholdet ditt. Når du optimaliserer for informasjonstetthet, optimaliserer du for mekanismene AI-systemer faktisk bruker for å identifisere autoritative, verdifulle kilder.
For å forbedre informasjonstetthet må du systematisk bruke konkrete teknikker som fjerner fyll, tilfører spesifisitet og strukturerer innholdet for AI-gjenfinning. Disse seks tiltakene forvandler generisk innhold til høy tetthet som AI-systemer kjenner igjen som autoritativt og siteringsverdig:
1. Fjern unødvendig fyll og overflødige ord: Fjern innledende fraser, overgangsord og gjentakelser som ikke gir ny innsikt.
Før: “I dagens moderne verden er det viktig å forstå at fornybar energi blir stadig mer populært og flere begynner å bruke det.” (24 ord, ingen informasjon)
Etter: “Solinstallasjoner økte med 23 % årlig fra 2020–2023 og utgjør nå 4,2 % av amerikansk strømproduksjon.” (15 ord, tre datapunkter)
2. Legg til spesifikke datapunkter og målinger: Bytt ut vage påstander med konkrete tall, prosent, datoer og målinger.
Før: “Mange selskaper bruker skybaserte løsninger fordi det er kostnadseffektivt.” (8 ord)
Etter: “Skybaserte løsninger reduserer IT-kostnader med 30–40 % og gir raske utrullinger fra uker til timer, ifølge Gartner 2023.” (21 ord, fire målinger)
3. Bruk fag- og bransjeterminologi: Inkluder presist vokabular som signaliserer ekspertise og hjelper AI å forstå tematisk autoritet.
Før: “Å gjøre nettsider raskere innebærer flere tekniske forbedringer.” (10 ord)
Etter: “Optimalisering av Core Web Vitals—reduksjon av Largest Contentful Paint til <2,5 sek, First Input Delay til <100ms og Cumulative Layout Shift til <0,1—har direkte sammenheng med konverteringsrate.” (27 ord, teknisk presisjon)
4. Svar direkte og umiddelbart: Led med konklusjoner og spesifikke svar i stedet for å bygge gradvis opp til dem.
Før: “Det er mange faktorer å vurdere ved valg av prosjektstyringsverktøy. Ulike verktøy har ulike funksjoner. Noen passer bedre for visse team. Det beste verktøyet avhenger av behov. Asana fungerer bra for store team.” (38 ord)
Etter: “Asana optimaliserer storskalateam med 15+ tilpassede felttyper, tidslinjevisning og porteføljestyring—ideelt for team over 50 medlemmer med 100+ samtidige prosjekter.” (25 ord, direkte og spesifikt)
5. Strukturér innhold som et datafeed: Organiser informasjon i lister, tabeller og strukturerte formater som AI lett kan lese.
Før: “Det er flere fordeler med denne metoden. Det sparer tid. Det gir færre feil. Det gir bedre kvalitet. Det koster mindre.” (21 ord)
Etter: Bruk en strukturert liste: “Fordeler: 40 % tidsbesparelse, 92 % færre feil, 3,2x kvalitetsforbedring, 35 % kostnadsreduksjon” (13 ord, skannbart og spesifikt)
6. Skriv med trygghet og sikkerhet: Bytt ut forbehold med trygge, dokumenterte utsagn som AI vurderer som autoritative.
Før: “Det kan hende at dette potensielt kan hjelpe med å forbedre resultatene i noen tilfeller.” (15 ord, ingen trygghet)
Etter: “Denne tilnærmingen økte konverteringsraten med 18 % på tvers av 47 A/B-tester gjennom 12 måneder.” (14 ord, høy trygghet)
Disse teknikkene virker best i kombinasjon: å bruke alle seks forvandler generisk innhold til høy tetthet som AI med trygghet kan hente og sitere.
En seiglivet myte hevder at lengre innhold rangerer bedre og får flere sitater—en misforståelse som forveksler korrelasjon med årsakssammenheng. I realiteten er innholdslengde ikke en rangeringsfaktor for AI-systemer; det er informasjonstetthet som avgjør. Langt innhold fylt med fyll, gjentakelser og lavverdi-informasjon presterer dårligere enn kort og tettpakket innhold med konkrete data, innsikter og handlingsinformasjon. En 800-ords artikkel med generiske utsagn og fyll får færre sitater enn en 400-ords artikkel med konsentrert, spesifikk informasjon. AI-systemer vurderer innholdskvalitet gjennom semantisk tetthet—mengden meningsfull informasjon per tekstmengde—ikke bare antall ord.
Riktig innholdslengde avhenger helt av brukerintensjon og kompleksiteten i temaet. Et enkelt spørsmål som “Hva er kokepunktet til vann?” krever 1–2 setninger med høy tetthet; å utvide dette til 2 000 ord er kontraproduktivt. Et komplekst tema som “hvordan implementere maskinlæring i bedriftssystemer” kan kreve 3 000–5 000 ord, men bare hvis hver setning tilfører unik verdi. Kvalitet fremfor kvantitet betyr å skrive minimum nødvendig lengde for å dekke temaet, med maksimal informasjonstetthet i hver setning. Viktige indikatorer for riktig lengde:
To tilnærminger til kryptovaluta: En 3 000-ords artikkel som forklarer blockchain, mining, lommebøker, børser og regelverk med generiske beskrivelser har lav tetthet. En 1 200-ords artikkel om samme tema med tekniske detaljer, fersk statistikk, regulatoriske referanser og praktiske råd har høy tetthet og får flere AI-sitater. Den kortere, tettere artikkelen overgår den lengre, tynnere fordi AI gjenkjenner den som mer autoritativ og verdifull. Dette endrer innholdsstrategien fundamentalt: i stedet for å spørre “Hvor lang bør artikkelen være?”, bør du spørre “Hvilken spesifikk informasjon krever temaet, og hvordan leverer jeg det mest effektivt?”
AI-systemer vurderer ikke innhold som helhetlige dokumenter; de bruker passasjeindeksering, en teknikk der store dokumenter deles i mindre, semantisk sammenhengende biter som kan hentes og vurderes uavhengig. Å forstå denne chunkingen er essensielt for å optimalisere informasjonstetthet, fordi det avgjør hvordan innholdet ditt blir fragmentert, indeksert og hentet. De fleste AI-systemer deler innhold i biter på 200–400 ord, avhengig av type og semantiske grenser. Hver bit må være kontekstuavhengig—kunne stå alene og svare på et spørsmål eller gi verdi uten at leseren trenger å se andre biter. Dette former hvordan du bør strukturere innhold: hver paragraf eller seksjon bør gi fullstendig informasjon.
Optimal bitstørrelse varierer med innholdstype, og forståelsen av retningslinjene hjelper deg å strukturere for maksimal gjenfinnbarhet. Et FAQ-svar kan deles i 100–200 token (omtrent 75–150 ord), så flere spørsmål/svar kan indekseres separat. Teknisk dokumentasjon deles ofte i 300–500 token (225 ord) for tilstrekkelig kontekst. Langformartikler deles i 400–600 token (300–450 ord) for å balansere kontekst og granulering. Produktbeskrivelser deles i 200–300 token (150–225 ord) for å isolere funksjoner og fordeler. Nyhetsartikler deles i 300–400 token (225–300 ord) for å skille historiedeler.
| Innholdstype | Optimal bitstørrelse (token) | Tilsvarende ord | Struktureringsstrategi |
|---|---|---|---|
| FAQ | 100–200 | 75–150 ord | Ett Q&A per bit |
| Teknisk dokumentasjon | 300–500 | 225–375 ord | Ett konsept per bit |
| Langformartikler | 400–600 | 300–450 ord | En seksjon per bit |
| Produktbeskrivelser | 200–300 | 150–225 ord | Ett funksjonssett per bit |
| Nyhetsartikler | 300–400 | 225–300 ord | Ett storyelement per bit |
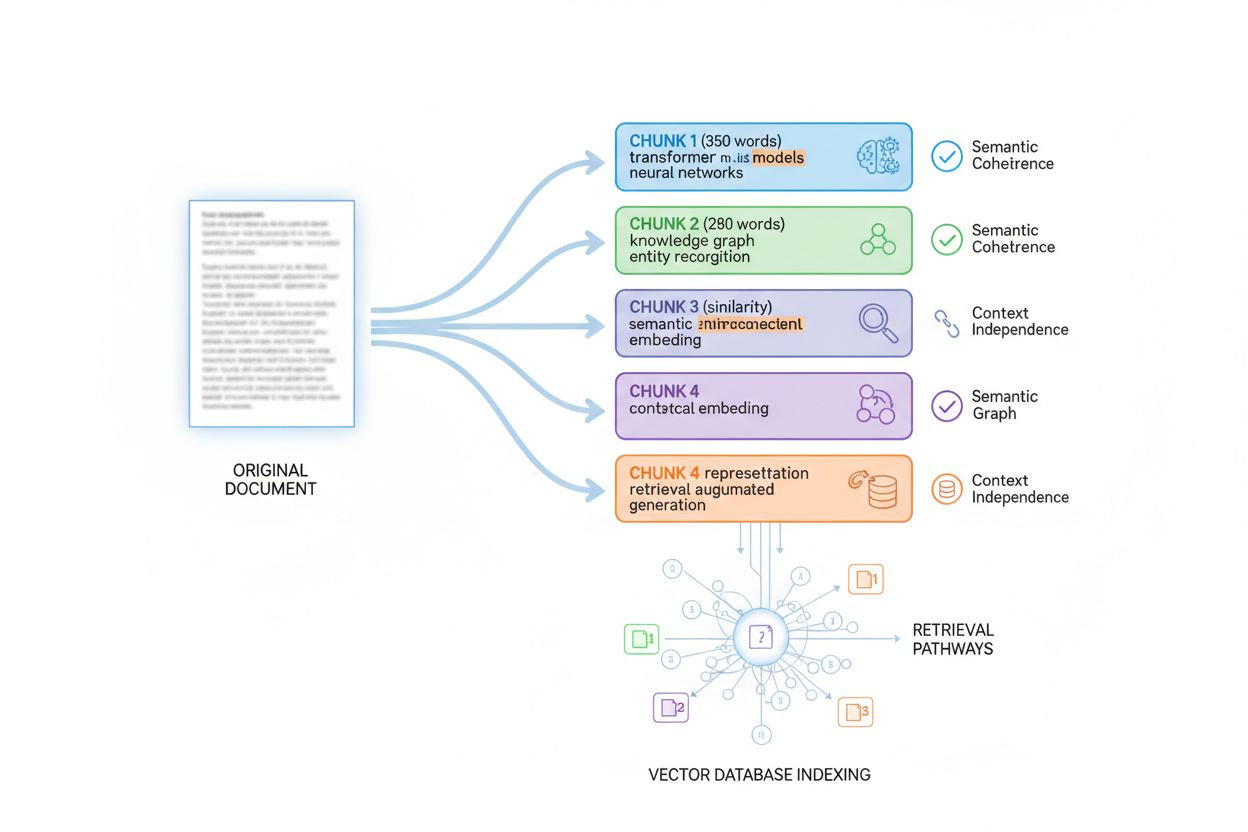
Beste praksis for optimal chunking inkluderer:
Når du strukturerer innhold med chunking i tankene, sikrer du at hver indeksert bit har høy tetthet og kan hentes uavhengig. Dette forbedrer gjenfinnbarheten betydelig fordi det samsvarer med hvordan AI faktisk prosesserer og indekserer innhold.
Å revidere innhold for informasjonstetthet krever systematisk vurdering av hvor mye unik, verdifull informasjon hver seksjon gir i forhold til lengden. Prosessen starter med å identifisere målpassasjene—de delene som mest sannsynlig blir hentet av AI-systemer som svar på vanlige spørsmål i ditt felt. For hver bit, beregn svartetthet ved å måle hvor direkte og fullstendig biten svarer på hovedspørsmålet innenfor ordtallet. En bit som svarer i første setning med støttende data og metode har høy svartetthet; en bit som bruker tre setninger på å stille spørsmålet og fem på å bygge opp til svaret, har lav svartetthet. Verktøy som NEURONwriter gir semantisk tetthetsscore som vurderer innholdskvalitet utover søkeord. AmICited.com overvåker hvor ofte innholdet ditt siteres i AI-systemer og gir direkte tilbakemelding på om tiltakene virker.
Revisjonsprosessen følger disse trinnene:
Viktige måltall å følge under forbedringsprosessen:
Den iterative prosessen innebærer å måle startverdier, implementere optimaliseringstiltak, måle på nytt etter 2–4 uker og justere basert på resultatene. Innhold som øker fra ett datapunkt per 100 ord til tre datapunkter per 100 ord får typisk 40–60 % økning i AI-sitatfrekvens. Å følge disse målingene over tid viser hvilke tiltak som fungerer best for din innholdstype og bransje, og lar deg kontinuerlig finjustere tilnærmingen. AmICited.com er ditt overvåkingsdashbord som viser nøyaktig hvilke deler av innholdet AI-systemer siterer og hvor ofte, og gir konkret tilbakemelding på om forbedringer i informasjonstetthet gir økt synlighet i AI.
Overgangen fra lav til høy informasjonstetthet gir målbare forbedringer i AI-sitatfrekvens på tvers av innholdstyper. Tenk på en teknologiblogg med tittelen “Hvorfor skybaserte løsninger er viktig”, som åpnet med: “Skybaserte løsninger er viktig i dagens forretningsverden. Mange bruker skybaserte løsninger. Skybaserte løsninger har mange fordeler. Bedrifter bør vurdere skybaserte løsninger.” Denne 28-ords innledningen ga null spesifikk informasjon og fikk få AI-sitater. Revidert versjon åpnet med: “Skybaserte løsninger reduserer infrastrukturkostnader med 30–40 % og muliggjør utrulling på timer i stedet for uker—kritiske fordeler som gjør at 94 % av virksomheter tar i bruk hybridløsninger innen 2024, ifølge Gartners siste undersøkelse.” Denne 32-ords innledningen ga fire spesifikke målinger, en navngitt kilde og en konkret statistikk. Sitatfrekvensen for denne artikkelen økte med 340 % i løpet av seks uker.
Side ved side: Teknologiartikkel
| Element | Original (lav tetthet) | Revidert (høy tetthet) | Forbedring |
|---|---|---|---|
| Åpningssetning | “Skybaserte løsninger er viktig” | “Skybaserte løsninger reduserer kostnader med 30–40 %” | Spesifikk måling lagt til |
| Datapunkter | 0 | 4 (30–40 %, timer vs. uker, 94 %, 2024) | 4x økning |
| Navngitte kilder | 0 | 1 (Gartner) | Autoritet etablert |
| Antall ord | 28 | 32 | +14 % (minimal økning) |
| AI-sitatfrekvens | Grunnivå | +340 % | Stor forbedring |
En produktbeskrivelse for en nettbutikk lød opprinnelig: “Vår programvare hjelper bedrifter med prosjektstyring. Den har mange funksjoner. Den fungerer for team. Kunder liker å bruke den.” Denne 24-ords beskrivelsen hadde ingen konkrete opplysninger om funksjoner, pris eller bruksområder. Revidert: “Prosjektstyringsverktøy med 15+ tilpassede felt, Gantt-tidslinje, porteføljestyring og sanntidssamarbeid—optimalisert for team på 50–500 med 100+ samtidige prosjekter til 29 dollar per bruker per måned.” Denne 28-ords beskrivelsen ga funksjonstall, målgruppe, prosjektkapasitet og pris. Produktbeskrivelse-sitater i AI-shoppingassistenter økte 280 %, og konverteringsraten økte 18 % fordi AI nå kunne gi konkrete, detaljerte svar til potensielle kunder.
Side ved side: Produktbeskrivelse
| Aspekt | Original | Revidert | Resultat |
|---|---|---|---|
| Opplistede funksjoner | “mange funksjoner” (vagt) | “15+ tilpassede felt, Gantt-tidslinje, porteføljestyring” (spesifikt) | 3x mer detaljert |
| Målgruppe | “team” (uspesifikt) | “team på 50–500” (spesifikk intervall) | Tydelig posisjonering |
| Prisinfo | Ingen | “29 dollar/bruker/mnd” | Mer åpenhet |
| AI-sitatøkning | Grunnivå | +280 % | Betydelig økning |
| Konverteringspåvirkning | Grunnivå | +18 % | Forretningsresultat |
En FAQ svarte opprinnelig “Hva er maskinlæring?” slik: “Maskinlæring er en type kunstig intelligens. Det bruker algoritmer. Det lærer fra data. Det blir mer populært.” Dette 24-ords svaret ga ingen handlingsinformasjon. Revidert: “Maskinlæring bruker algoritmer trent på historiske data for å identifisere mønstre og lage prediksjoner—muliggjør applikasjoner fra svindeldeteksjon (99,9 % nøyaktighet) til anbefalingsmotorer (35 % konverteringsløft) og medisinsk diagnostikk (94 % sensitivitet ved kreftpåvisning).” Dette 35-ords svaret ga
Søkeordtetthet målte prosentandelen målsøkeord i innholdet, noe som ofte førte til overbruk av søkeord og lavkvalitetsmateriale. Informasjonstetthet måler forholdet mellom nyttig, unik informasjon og total innholdslengde, med fokus på verdi og spesifisitet. Moderne AI-systemer vurderer informasjonstetthet i stedet for søkeordfrekvens, og premierer innhold som leverer maksimal innsikt effektivt.
AI-systemer gir høyere tillitspoeng til avsnitt med høy informasjonstetthet fordi de inneholder spesifikke datapunkter, navngitte enheter og fagterminologi. Innhold med 3+ datapunkter får 2,5 ganger høyere siteringsrate enn generisk innhold. Avsnitt som svarer på spørsmål i løpet av de første 1–2 setningene viser 40 % høyere gjenfinningsfrekvens i AI-systemer.
Innholdslengde avhenger av emnets kompleksitet og brukerintensjon, ikke et fast antall ord. Et enkelt spørsmål kan kreve 1–2 setninger med høy tetthet, mens komplekse emner kan trenge 3 000–5 000 ord. Nøkkelen er å levere maksimal informasjonsverdi på et minimum av nødvendig lengde—kvalitet trumfer alltid kvantitet hos AI-systemer.
Gå gjennom innholdet ditt ved å telle datapunkter per 100 ord (mål: 2–4), navngitte enheter (mål: 1–3), og vurder hvor direkte avsnittet svarer på hovedspørsmålet. Verktøy som NEURONwriter gir semantisk tetthetsscore. AmICited.com sporer hvor ofte AI-systemer siterer innholdet ditt og gir direkte tilbakemelding på hvor effektiv optimaliseringen er.
Ja, absolutt. En artikkel på 400 ord fylt med spesifikke data, statistikk, fagterminologi og konkrete eksempler har høyere informasjonstetthet enn en artikkel på 2 000 ord med generiske utsagn og gjentakelser. AI-systemer vurderer tetthet per tekstmengde, ikke absolutt lengde. Kortere, tettere innhold overgår ofte lengre og 'tynnere' innhold.
AI-systemer deler innhold i biter på 200–400 ord for uavhengig indeksering og gjenfinning. Hver bit må være kontekstuavhengig og gi verdi på egenhånd. Høy informasjonstetthet sikrer at hver bit inneholder tilstrekkelig spesifikk informasjon til å kunne bli hentet og sitert uavhengig, noe som forbedrer innholdets gjenfinnbarhet på tvers av AI-systemer.
NEURONwriter og Contadu gir semantisk tetthetsscore og innholdsanalyse. AmICited.com overvåker hvor ofte AI-systemer siterer innholdet ditt, og viser hvilke deler som fungerer. Google Search Console avslører hvilke avsnitt som vises i utvalgte utdrag. Disse verktøyene sammen gir helhetlig tilbakemelding på hvor effektivt du optimaliserer informasjonstetthet.
Selv om informasjonstetthet ikke er en direkte rangeringsfaktor, korrelerer det sterkt med kvalitetssignaler som AI-systemer vurderer. Innhold med høy tetthet får flere sitater, gir mer engasjement og viser tematisk autoritet. Disse faktorene forbedrer indirekte rangeringen fordi AI-systemer gjenkjenner innhold med høy tetthet som mer verdifullt og autoritativt enn alternativer med lav tetthet.
Følg med på hvordan AI-systemer refererer til merkevaren din på tvers av GPT-er, Perplexity, Google AI Overviews og andre AI-plattformer. Forstå hvilket innhold som blir sitert og optimaliser for maksimal synlighet.
Lær hvordan du lager innhold med høy informasjonstetthet som AI-systemer foretrekker. Mestre hypotesen om uniform informasjonstetthet og optimaliser innholdet d...

Lær hva innholdsomfattendehet betyr for AI-systemer som ChatGPT, Perplexity og Google AI Overviews. Oppdag hvordan du lager komplette, selvstendige svar som AI ...
Lær hva innholdsautentisitet betyr for AI-søkemotorer, hvordan AI-systemer verifiserer kilder, og hvorfor det er viktig for nøyaktige AI-genererte svar fra Chat...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.