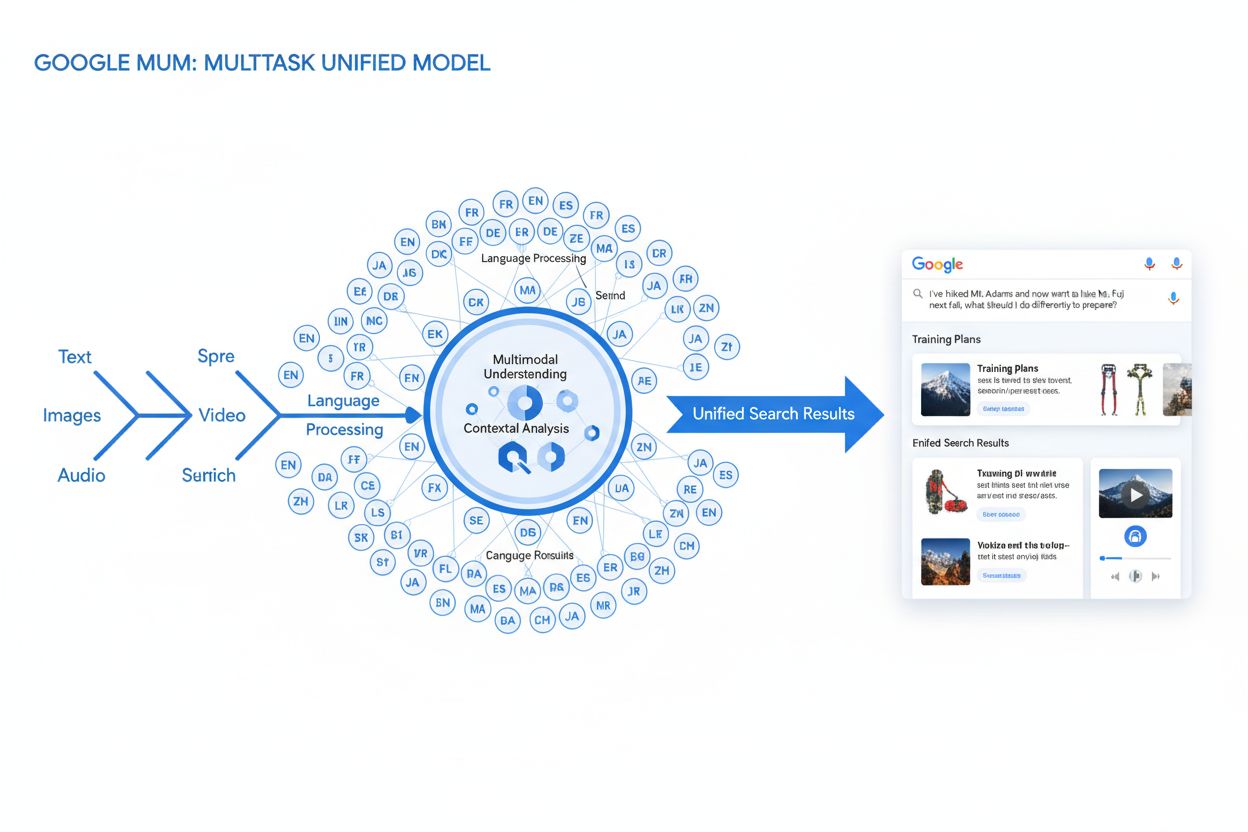
Definisjon av MUM (Multitask Unified Model)
MUM (Multitask Unified Model) er Googles avanserte multimodale kunstig intelligens-modell utviklet for å revolusjonere hvordan søkemotorer forstår og svarer på komplekse brukerforespørsler. Presentert i mai 2021 av Pandu Nayak, Google Fellow og visepresident for søk, representerer MUM et grunnleggende skifte innen informasjonshentingsteknologi. Bygget på T5 tekst-til-tekst-rammeverket og bestående av omtrent 110 milliarder parametere, er MUM 1 000 ganger kraftigere enn BERT, Googles forrige gjennombrudd innen naturlig språkprosessering. I motsetning til tradisjonelle søkealgoritmer som behandler tekst isolert, behandler MUM tekst, bilder, video og lyd samtidig og forstår informasjon på tvers av over 75 språk direkte. Denne multimodale og flerspråklige kapasiteten gjør MUM i stand til å forstå komplekse forespørsler som tidligere krevde at brukeren utførte flere søk, og forvandler søk fra en enkel nøkkelordmatching til et intelligent, kontekstuelt informasjonshentingssystem. MUM forstår ikke bare språk, men genererer det også, og gjør det mulig å syntetisere informasjon fra ulike kilder og formater for å gi omfattende, nyanserte svar som dekker hele brukerens hensikt.
Historisk kontekst og utvikling av Googles KI-modeller
Googles vei mot MUM representerer år med gradvis innovasjon innen naturlig språkprosessering og maskinlæring. Utviklingen startet med Hummingbird (2013), som introduserte semantisk forståelse for å tolke meningen bak søk i stedet for bare å matche nøkkelord. Dette ble etterfulgt av RankBrain (2015), som brukte maskinlæring for å forstå lange nøkkelordskjeder og nye søkemønstre. Neural Matching (2018) tok dette videre ved å bruke nevrale nettverk for å matche forespørsler med relevant innhold på et dypere semantisk nivå. BERT (Bidirectional Encoder Representations from Transformers), lansert i 2019, var et stort gjennombrudd ved å forstå kontekst i setninger og avsnitt, og forbedret Googles evne til å tolke nyansert språk. BERT hadde imidlertid betydelige begrensninger—den behandlet kun tekst, hadde begrenset flerspråklig støtte og kunne ikke håndtere kompleksiteten i forespørsler som krevde informasjonssyntese på tvers av flere formater. Ifølge Googles forskning stiller brukere i gjennomsnitt åtte separate forespørsler for å besvare komplekse spørsmål, som å sammenligne to fjelldestinasjoner eller vurdere produktvalg. Denne statistikken pekte på en kritisk mangel i søketeknologien som MUM var spesielt utviklet for å løse. Helpful Content Update (2022) og E-E-A-T-rammeverket (2023) forbedret ytterligere hvordan Google prioriterer autoritativt og troverdig innhold. MUM bygger på alle disse innovasjonene og introduserer egenskaper som overgår tidligere begrensninger, og representerer ikke bare en gradvis forbedring, men et paradigmeskifte i hvordan søkemotorer behandler og leverer informasjon.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Teknisk arkitektur og multimodal behandling
MUMs tekniske grunnlag hviler på transformer-arkitekturen, spesielt T5 (Text-to-Text Transfer Transformer)-rammeverket som Google utviklet tidligere. T5-rammeverket behandler alle oppgaver innen naturlig språkprosessering som tekst-til-tekst-problemer, ved å konvertere input og output til enhetlige tekstrepresentasjoner. MUM utvider denne tilnærmingen ved å inkludere multimodale behandlingsmuligheter, slik at den kan håndtere tekst, bilder, video og lyd samtidig innenfor én samlet modell. Dette arkitektoniske valget er viktig fordi det gjør MUM i stand til å forstå relasjoner og kontekst på tvers av ulike medietyper på måter tidligere modeller ikke kunne. For eksempel, når den behandler et spørsmål om å gå på Mt. Fuji kombinert med et bilde av spesifikke fjellstøvler, analyserer ikke MUM tekst og bilde separat—den behandler dem sammen og forstår hvordan støvelens egenskaper forholder seg til konteksten i spørsmålet. Modellens 110 milliarder parametere gir den kapasitet til å lagre og prosessere enorme mengder kunnskap om språk, visuelle konsepter og deres relasjoner. MUM er trent på 75 ulike språk og mange forskjellige oppgaver samtidig, noe som gjør at den utvikler en mer omfattende forståelse av informasjon og verdensforståelse enn modeller trent på ett språk eller én oppgave. Denne multitask-læringen gjør at MUM lærer å gjenkjenne mønstre og relasjoner som overføres på tvers av språk og domener, og gjør den mer robust og generaliserbar enn tidligere modeller. Samtidig behandling av flere språk under trening gjør at MUM kan utføre kunnskapsoverføring mellom språk, slik at den kan forstå informasjon skrevet på ett språk og bruke denne forståelsen på spørsmål på et annet språk, og dermed bryte ned språkbarrierer som tidligere begrenset søkeresultatene.
Sammenligningstabell: MUM vs. relaterte KI-modeller og teknologier
| Egenskap | MUM (2021) | BERT (2019) | RankBrain (2015) | T5-rammeverk |
|---|
| Primær funksjon | Multimodal spørsmålsforståelse og svarsyntese | Tekstbasert kontekstforståelse | Tolkning av lange nøkkelord | Tekst-til-tekst-overføringslæring |
| Input-modaliteter | Tekst, bilder, video, lyd | Kun tekst | Kun tekst | Kun tekst |
| Språkstøtte | Over 75 språk direkte | Begrenset flerspråklig støtte | Hovedsakelig engelsk | Hovedsakelig engelsk |
| Modellparametere | Ca. 110 milliarder | Ca. 340 millioner | Ikke oppgitt | Ca. 220 millioner |
| Kraft-sammenligning | 1 000x kraftigere enn BERT | Referansepunkt | Forgjenger til BERT | Grunnlag for MUM |
| Egenskaper | Forståelse + generering | Kun forståelse | Mønstergjenkjenning | Teksttransformasjon |
| SERP-påvirkning | Berikede resultater i flere formater | Bedre utdrag og kontekst | Forbedret relevans | Grunnleggende teknologi |
| Håndtering av query-kompleksitet | Komplekse flerstegsforespørsler | Enkelt-forespørsels-kontekst | Lange nøkkelord-variasjoner | Teksttransformasjons-oppgaver |
| Kunnskapsoverføring | På tvers av språk og modaliteter | Kun innenfor ett språk | Begrenset overføring | Overføring på tvers av oppgaver |
| Virkelig bruk | Google Søk, AI Overviews | Google Søk-rangering | Google Søk-rangering | Teknisk grunnlag for MUM |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Hvordan MUM behandler komplekse søk
MUMs forespørselsbehandling består av flere sofistikerte trinn som samarbeider for å levere omfattende og kontekstuelle svar. Når en bruker sender inn et søk, starter MUM med språkagnostisk forbehandling, og forstår forespørselen på hvilket som helst av de over 75 støttede språkene uten behov for oversettelse. Denne direkte språkforståelsen bevarer språklige nyanser og regional kontekst som kan gå tapt ved oversettelse. Deretter bruker MUM sekvens-til-sekvens-matching, og analyserer hele forespørselen som en meningssekvens i stedet for isolerte nøkkelord. Dette gjør MUM i stand til å forstå relasjoner mellom konsepter—for eksempel å gjenkjenne at et spørsmål om “forberedelse til Mt. Fuji etter å ha klatret Mt. Adams” innebærer sammenligning, forberedelse og konteksttilpasning. Samtidig utfører MUM multimodal input-analyse, og behandler eventuelle bilder, videoer eller annet media som inngår i forespørselen. Modellen foretar så simultan forespørselsbehandling, og vurderer flere mulige brukerintensjoner parallelt i stedet for å låse seg til én tolkning. Dette betyr at MUM kan forstå at et spørsmål om å gå på Mt. Fuji kan handle om fysisk forberedelse, valg av utstyr, kulturelle opplevelser eller reiselogistikk—og viser relevant informasjon for alle disse tolkningene. Vektorbasert semantisk forståelse omdanner forespørselen og indeksert innhold til høy-dimensjonale vektorer som representerer semantisk mening, slik at innhenting kan skje basert på konseptuell likhet og ikke bare nøkkelord. MUM bruker deretter innholdsfiltrering via kunnskapsoverføring, ved å bruke maskinlæring trent på søkelogger, nettleserdata og brukeratferd for å prioritere høykvalitets, autoritative kilder. Til slutt genererer MUM en multimedieberiket SERP-sammensetning, som kombinerer tekstutdrag, bilder, videoer, relaterte spørsmål og interaktive elementer til én visuelt lagdelt søkeopplevelse. Hele denne prosessen skjer på millisekunder, og lar MUM levere resultater som besvarer ikke bare det eksplisitte spørsmålet, men også forventede oppfølgingsspørsmål og beslektede informasjonsbehov.
Multimodale og flerspråklige egenskaper
MUMs multimodale egenskaper representerer et grunnleggende brudd med tekstbaserte søkesystemer. Modellen kan samtidig behandle og forstå informasjon fra tekst, bilder, video og lyd, trekke ut mening fra hver modalitet og syntetisere det til sammenhengende svar. Denne kapasiteten er spesielt kraftfull for spørsmål som drar nytte av visuell kontekst. Hvis en bruker for eksempel spør “Kan jeg bruke disse fjellstøvlene på Mt. Fuji?” mens de viser et bilde av støvlene sine, forstår MUM støvelens egenskaper ut fra bildet—materiale, sålemønster, høyde, farge—og kobler denne visuelle forståelsen med kunnskap om Mt. Fujis terreng, klima og turopplegg for å gi et kontekstuelt svar. Den flerspråklige dimensjonen til MUM er like transformativ. Med støtte for over 75 språk kan MUM utføre kunnskapsoverføring mellom språk, noe som betyr at den lærer fra kilder på ett språk og bruker denne kunnskapen på spørsmål på et annet. Dette bryter ned en betydelig barriere som tidligere begrenset søkeresultater til innhold på brukerens morsmål. Hvis utfyllende informasjon om Mt. Fuji primært finnes i japanske kilder—inkludert lokale turguider, sesongbasert vær og kulturelle innsikter—kan MUM forstå dette japanske innholdet og vise relevant informasjon til engelsktalende brukere. Ifølge Googles testing klarte MUM å liste 800 varianter av COVID-19-vaksiner på mer enn 50 språk i løpet av sekunder, noe som viser skalaen og hastigheten på dens flerspråklige prosessering. Denne flerspråklige forståelsen er særlig verdifull for brukere i ikke-engelskspråklige markeder og for spørsmål om temaer hvor informasjonen finnes på flere språk. Kombinasjonen av multimodal og flerspråklig behandling gjør at MUM kan vise det mest relevante innholdet uansett format og uansett hvilket språk det opprinnelig ble publisert på, og gir en virkelig global søkeopplevelse.
Påvirkning på søkeresultat og brukeropplevelse
MUM forandrer grunnleggende hvordan søkeresultater vises og oppleves av brukerne. I stedet for den tradisjonelle listen med blå lenker som dominerte søk i flere tiår, skaper MUM berikede, interaktive SERP-er som kombinerer flere innholdsformater på én side. Brukere kan nå se tekstutdrag, høyoppløselige bilder, videokaruser, relaterte spørsmål og interaktive elementer uten å forlate søkeresultatsiden. Dette har store konsekvenser for hvordan brukere interagerer med søk. I stedet for å utføre flere søk for å samle informasjon om et komplekst tema, kan brukeren utforske ulike vinkler og undertemaer direkte i SERP-en. Et søk om “forberedelse til Mt. Fuji på høsten” kan for eksempel vise høydesammenligninger, værmeldinger, utstyrsanbefalinger, videoguides og brukeranmeldelser—alt organisert kontekstuelt på én side. Google Lens-integrasjon drevet av MUM lar brukere søke med bilder i stedet for nøkkelord, og gjør visuelle elementer i bilder om til interaktive oppdagelsesverktøy. “Things to Know”-paneler deler opp komplekse spørsmål i håndterbare undertemaer, og veileder brukeren gjennom ulike aspekter med relevante utdrag for hvert. Zoom-bare, høyoppløselige bilder vises direkte i søkeresultatet, slik at brukeren kan sammenligne visuelt og redusere friksjon i beslutningsprosessen. “Refine and Broaden”-funksjonalitet foreslår relaterte konsepter for å hjelpe brukeren til å fordype seg eller utforske tilgrensende temaer. Disse endringene representerer et skifte fra søk som et enkelt gjenfinningsverktøy til søk som en interaktiv, utforskende opplevelse som forutser brukerbehov og gir omfattende informasjon i selve søkegrensesnittet. Forskning viser at denne rikere SERP-opplevelsen reduserer antall søk som kreves for å besvare komplekse spørsmål, men det betyr også at brukere i større grad konsumerer informasjonen direkte i søkeresultatet i stedet for å klikke seg videre til nettsteder.
MUMs rolle i AI-overvåking og merkevaresynlighet
For organisasjoner som overvåker sin tilstedeværelse i KI-systemer, representerer MUM en kritisk utvikling i hvordan informasjon oppdages og vises. Etter hvert som MUM blir mer integrert i Google Søk og påvirker andre KI-systemer, blir det avgjørende å forstå hvordan merkevarer og domener vises i MUM-drevne resultater for å opprettholde synlighet. MUMs multimodale behandling gjør at merkevarer må optimalisere på tvers av flere innholdsformater, ikke kun tekst. En merkevare som tidligere har stolt på rangering for bestemte nøkkelord, må nå sørge for at innholdet er synlig gjennom bilder, videoer og strukturert data. Modellens evne til å syntetisere informasjon fra ulike kilder gjør at merkevarens synlighet avhenger ikke bare av eget nettsted, men også av hvordan informasjonen fremstår og brukes i det bredere nettøkosystemet. MUMs flerspråklige kapasitet gir nye muligheter og utfordringer for globale merkevarer. Innhold publisert på ett språk kan nå oppdages av brukere som søker på et annet, og utvider rekkevidden. Dette gjør imidlertid også at merkevarer må sikre at informasjonen er korrekt og konsistent på tvers av språk, ettersom MUM kan hente informasjon fra flere språk for én og samme forespørsel. For KI-overvåkingsplattformer som AmICited er det avgjørende å spore MUMs påvirkning, fordi det representerer måten moderne KI-systemer henter og presenterer informasjon på. Når man overvåker hvor en merkevare vises i KI-responser—enten i Google AI Overviews, Perplexity, ChatGPT eller Claude—hjelper forståelsen av MUMs underliggende teknologi å forklare hvorfor visst innhold vises og hvordan man kan optimalisere for synlighet. Overgangen til multimodale, flerspråklige søk gjør at merkevarer trenger helhetlig overvåking som sporer deres tilstedeværelse på tvers av innholdsformater og språk, ikke bare tradisjonell nøkkelordrangering. Organisasjoner som forstår MUMs egenskaper, kan optimalisere sin innholdsstrategi bedre for å sikre synlighet i dette nye søkelandskapet.
Viktigste fordeler og gevinster med MUM
- Redusert søkefriksjon: Brukere trenger færre søk for å besvare komplekse spørsmål, da MUM syntetiserer informasjon fra flere kilder og formater til helhetlige svar
- Multimodal forståelse: Samtidig behandling av tekst, bilder, video og lyd gir rikere kontekst og mer presise svar på spørsmål som krever visuell eller multimedial forståelse
- Flerspråklig kunnskapsoverføring: Naturlig støtte for over 75 språk gjør at informasjon kan oppdages på tvers av språkbarrierer, og utvider rekkevidde og tilgjengelighet globalt
- Kontekstuell relevans: MUM forstår brukerhensikt på et dypere nivå, gjenkjenner relasjoner mellom konsepter og viser informasjon som svarer på forventede oppfølgingsspørsmål
- Beriket SERP-opplevelse: Interaktive, visuelt lagdelte søkeresultater gir mer informasjon direkte i søket, og forbedrer brukerengasjement og beslutningstaking
- Bedre håndtering av tvetydige spørsmål: MUMs evne til å vurdere flere tolkninger samtidig gjør at den kan gi relevante resultater selv for vage eller tvetydige spørsmål
- Kunnskapssyntese: I stedet for bare å hente eksisterende innhold, kan MUM syntetisere informasjon fra flere kilder for å lage helhetlige svar
- Forbedret tilgjengelighet: Multimodal og flerspråklig behandling gjør informasjon mer tilgjengelig for ulike brukere med ulike språkpreferanser og tilgjengelighetsbehov
- Avanserte featured snippets: MUM muliggjør mer sofistikert snippet-generering, med flere snippet-formater per forespørsel basert på ulike brukerhensikter
- Tverrformat innholdsoppdagelse: Innhold i alle formater—tekst, bilder, video, lyd—kan oppdages og vises, og belønner multimediale innholdsstrategier
Begrensninger og utfordringer med MUM
Selv om MUM representerer et betydelig fremskritt, introduserer den også nye utfordringer og begrensninger som organisasjoner må navigere. Lavere klikkrater er en stor bekymring for utgivere og innholdsskapere, fordi brukerne nå kan konsumere omfattende informasjon direkte i søkeresultatet uten å klikke seg videre til nettsteder. Dette gjør at tradisjonelle trafikkmålinger blir mindre pålitelige som suksessindikator. Økte tekniske SEO-krav innebærer at innhold må være godt strukturert med riktig schema markup, semantisk HTML og klare entitetsrelasjoner for å bli riktig forstått av MUM. Innhold uten dette tekniske grunnlaget kan bli dårligere indeksert eller ikke forstått av MUMs multimodale behandling. SERP-metning gir synlighetsutfordringer, da flere innholdsformater konkurrerer om oppmerksomhet på én side. Selv sterkt innhold kan få færre eller ingen klikk hvis brukere finner tilstrekkelig informasjon i selve SERP-en. Potensial for misvisende resultater finnes når MUM viser informasjon fra flere kilder som kan motsi hverandre, eller når kontekst går tapt i syntesen. Avhengighet av strukturert data gjør at ustrukturert eller dårlig formatert innhold kanskje ikke blir forstått eller synliggjort av MUM. Språk- og kulturutfordringer kan oppstå når MUM overfører kunnskap på tvers av språk, og kan gå glipp av kulturell kontekst eller regionale nyanser. Krav til datakraft for å kjøre MUM i stor skala er betydelige, selv om Google har investert i effektivisering for å redusere karbonavtrykket. Bekymringer rundt bias og rettferdighet krever kontinuerlig oppfølging for å sikre at MUM ikke viderefører skjevheter i treningsdata eller gir urettferdige utslag for visse perspektiver eller grupper.
Konsekvenser for SEO og innholdsstrategi
Fremveksten av MUM krever grunnleggende endringer i hvordan organisasjoner tilnærmer seg SEO og innholdsstrategi. Tradisjonell nøkkelordfokusert optimalisering blir mindre effektiv når MUM kan forstå hensikt og kontekst utover eksakt nøkkelordmatch. Temabasert innholdsstrategi blir viktigere enn nøkkelordbasert strategi, og organisasjoner må lage omfattende innholdsklynger som dekker temaer fra flere vinkler. Multimedieinnhold er ikke lenger valgfritt—organisasjoner må investere i høyoppløselige bilder, videoer og interaktivt innhold som kompletterer tekstbasert innhold. Implementering av strukturert data blir kritisk, da schema markup hjelper MUM å forstå innholdsstruktur og relasjoner. Entitetsbygging og semantisk optimalisering etablerer tematisk autoritet og forbedrer hvordan MUM forstår innholdsrelasjoner. Flerspråklig innholdsstrategi øker i betydning, ettersom MUMs språkoverføringsevner gjør at innhold kan oppdages på tvers av språkmarkeder. Kartlegging av brukerhensikt krever dypere forståelse, og organisasjoner må ta høyde for både primær hensikt og relaterte spørsmål og undertemaer brukerne kan utforske. Innholdets aktualitet og nøyaktighet blir viktigere ettersom MUM syntetiserer informasjon fra flere kilder—utdatert eller unøyaktig innhold kan bli nedprioritert. Tverrplattformoptimalisering gjelder ikke bare Google Søk, men også hvordan innhold vises i AI-systemer som Google AI Overviews, Perplexity og andre KI-drevne søkegrensesnitt. E-E-A-T-signaler (Erfaring, Ekspertise, Autoritet, Tiltro) blir stadig viktigere etter hvert som MUM prioriterer innhold fra autoritative kilder. Organisasjoner som tilpasser strategiene sine til MUMs egenskaper—fokusert på helhetlig, multimodalt, godt strukturert innhold som viser ekspertise og autoritet—vil opprettholde synlighet i det nye søkelandskapet.
Fremtidig utvikling og strategisk perspektiv
MUM er ikke et endepunkt, men et veiskille i utviklingen av KI-drevet søk. Google har indikert at MUM vil fortsette å utvide sine egenskaper, med stadig mer avansert video- og lydbehandling. Selskapet forsker aktivt på å redusere MUMs ressursbruk uten å gå på bekostning av ytelsen, og imøtekommer bærekraftshensyn knyttet til store KI-modeller. Integrasjonen av MUM med andre Google-teknologier antyder fremtidige utviklinger hvor MUMs forståelse ikke bare driver søk, men også Google Assistant, Google Lens og andre produkter. Konkurranse fra andre KI-systemer som OpenAIs ChatGPT, Anthropics Claude og Perplexitys AI-søkemotor innebærer at MUM trolig vil fortsette å utvikle seg for å opprettholde Googles konkurransefortrinn. Regulatorisk oppmerksomhet rundt KI-systemer kan påvirke hvordan MUM utvikles, særlig med tanke på bias, rettferdighet og åpenhet. Brukeradferd vil også forme MUMs utvikling—etter hvert som brukere venner seg til rikere og mer interaktive søkeopplevelser, vil forventningene til søkekvalitet og -omfang øke. Fremveksten av generativ KI betyr at MUMs evne til å syntetisere og generere informasjon trolig vil bli enda viktigere, og kan gjøre det mulig for MUM å generere originalt innhold i stedet for bare å hente og organisere eksisterende innhold. Multimodal KI blir standard, og MUMs tilnærming med å behandle flere formater samtidig vil trolig bli normen i KI-systemer. Personvern og databruk vil påvirke hvordan MUM bruker brukerdata og atferdssignaler for å tilpasse og forbedre resultatene. Organisasjoner bør forberede seg på kontinuerlig utvikling ved å bygge fleksible, tilpasningsdyktige innholdsstrategier som prioriterer kvalitet, helhet og teknisk fortreffelighet, i stedet for å stole på spesifikke taktikker som kan bli foreldet etter hvert som MUM utvikler seg. Det grunnleggende prinsippet—å skape innhold som faktisk svarer på brukerens hensikt på tvers av formater og språk—vil forbli relevant uansett hvordan MUMs spesifikke egenskaper utvikler seg.