
Transformer-arkitektur
Transformer-arkitektur er et nevralt nettverksdesign som bruker selvoppmerksomhetsmekanismer for å behandle sekvensielle data parallelt. Det driver ChatGPT, Cla...
14 min lesing
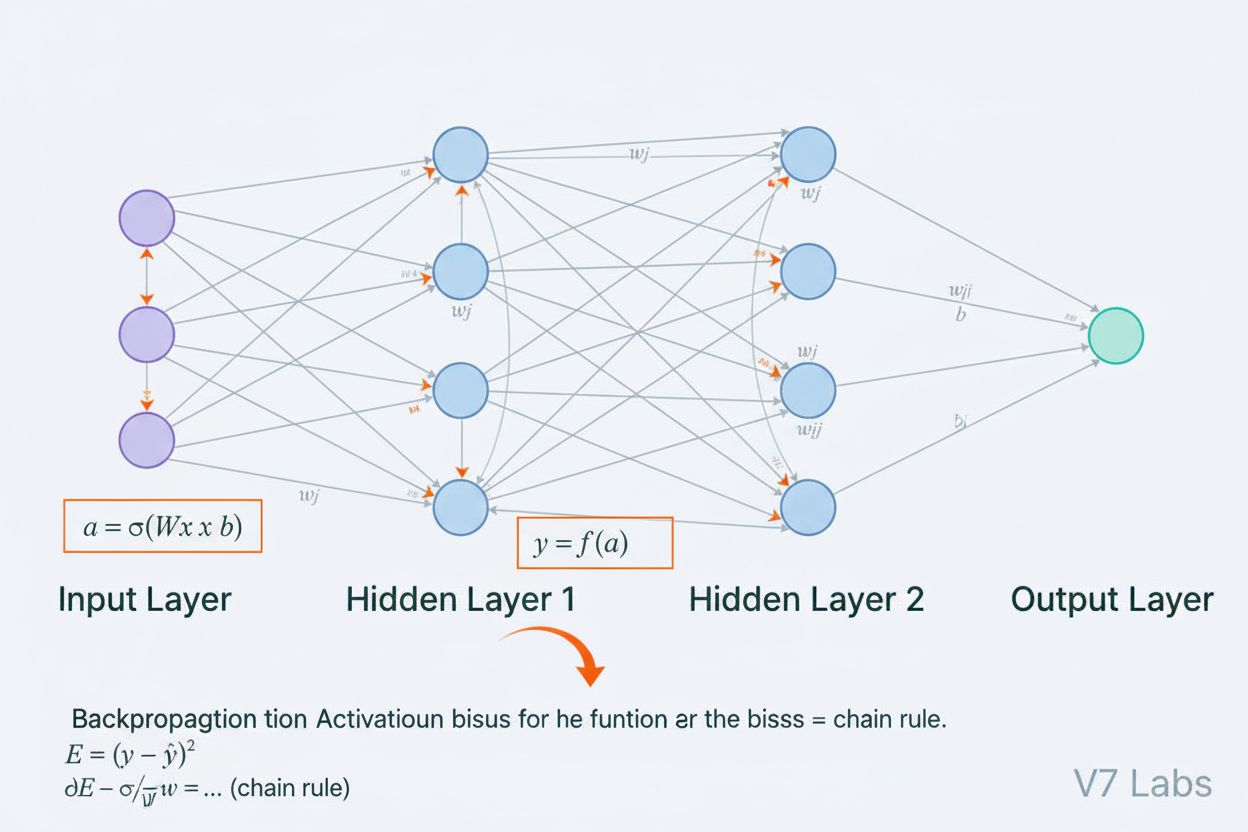
Et neuralt nettverk er et datasystem inspirert av biologiske nevrale nettverk, bestående av sammenkoblede kunstige nevroner organisert i lag, i stand til å lære mønstre fra data gjennom en prosess kalt tilbakepropagering. Disse systemene utgjør grunnlaget for moderne kunstig intelligens og dyp læring, og driver applikasjoner fra naturlig språkbehandling til datamaskinsyn.
Et neuralt nettverk er et datasystem inspirert av biologiske nevrale nettverk, bestående av sammenkoblede kunstige nevroner organisert i lag, i stand til å lære mønstre fra data gjennom en prosess kalt tilbakepropagering. Disse systemene utgjør grunnlaget for moderne kunstig intelligens og dyp læring, og driver applikasjoner fra naturlig språkbehandling til datamaskinsyn.
Et neuralt nettverk er et datasystem fundamentalt inspirert av strukturen og funksjonen til biologiske nevrale nettverk funnet i dyrehjerner. Det består av sammenkoblede kunstige nevroner organisert i lag—typisk et inngangslag, ett eller flere skjulte lag, og et utgangslag—som samarbeider for å behandle data, gjenkjenne mønstre og lage prediksjoner. Hver nevron mottar innganger, utfører matematiske transformasjoner gjennom vekter og bias, og sender resultatet gjennom en aktiveringsfunksjon for å produsere en utgang. Det som kjennetegner neurale nettverk er deres evne til å lære fra data gjennom en iterativ prosess kalt tilbakepropagering, hvor nettverket justerer interne parametere for å minimere prediksjonsfeil. Denne læringsevnen, kombinert med evnen til å modellere komplekse ikke-lineære relasjoner, har gjort neurale nettverk til grunnteknologien bak moderne kunstig intelligens, fra store språkmodeller til applikasjoner innen datamaskinsyn.
Konseptet kunstige neurale nettverk oppsto fra tidlige forsøk på å matematisk modellere hvordan biologiske nevroner kommuniserer og behandler informasjon. I 1943 foreslo Warren McCulloch og Walter Pitts den første matematiske modellen for en nevron, og viste at enkle beregningsenheter kunne utføre logiske operasjoner. Dette teoretiske grunnlaget ble fulgt av Frank Rosenblatts introduksjon av perceptronen i 1958, en algoritme for mønstergjenkjenning som ble forløperen til dagens avanserte neurale nettverksarkitekturer. Perceptronen var i utgangspunktet en lineær modell med begrenset utgang, i stand til å lære enkle beslutningsgrenser. Feltet møtte imidlertid betydelige tilbakeslag på 1970-tallet da forskere oppdaget at enkeltlags perceptroner ikke kunne løse ikke-lineære problemer som XOR-funksjonen, noe som førte til den såkalte “AI-vinteren”. Gjennombruddet kom på 1980-tallet med gjenoppdagelsen og videreutviklingen av tilbakepropagering, en algoritme som gjorde det mulig å trene flerlagede nettverk. Denne fremgangen akselererte dramatisk på 2010-tallet med tilgjengeligheten av massive datasett, kraftige GPU-er og forbedrede treningsmetoder, noe som ledet til dyp læring-revolusjonen som forvandlet kunstig intelligens.
Et neuralt nettverks arkitektur består av flere essensielle komponenter som jobber sammen. Inngangslaget mottar rå datafunksjoner fra eksterne kilder, hvor hver nevron i dette laget tilsvarer en funksjon. Skjulte lag står for den beregningsmessige hovedjobben, og omformer innganger til stadig mer abstrakte representasjoner gjennom vektede kombinasjoner og ikke-lineære aktiveringsfunksjoner. Antallet og størrelsen på de skjulte lagene bestemmer nettverkets kapasitet til å lære komplekse mønstre—dypere nettverk kan fange opp mer sofistikerte relasjoner, men krever mer data og datakraft. Utgangslaget produserer de endelige prediksjonene, med struktur avhengig av oppgaven: én nevron for regresjon, flere nevroner for multiklasseklassifisering eller spesialiserte arkitekturer for andre bruksområder. Hver forbindelse mellom nevroner har en vekt som bestemmer styrken på påvirkningen, mens hver nevron har en bias som forskyver aktiveringsterskelen. Disse vektene og biasene er de lærbare parameterne som nettverket justerer under trening. Aktiveringsfunksjonen som brukes i hver nevron tilfører avgjørende ikke-linearitet, noe som gjør nettverket i stand til å lære komplekse beslutningsgrenser og mønstre som lineære modeller ikke kan fange opp.
Neurale nettverk lærer gjennom en to-faset iterativ prosess. Under fremoverpropagering flyter inngangsdata gjennom nettverket fra inngangslaget til utgangslaget. For hver nevron beregnes den vektede summen av innganger pluss bias (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b), som deretter sendes gjennom en aktiveringsfunksjon for å produsere nevronens utgang. Denne prosessen gjentas gjennom hvert skjulte lag til man når utgangslaget, som gir nettverkets prediksjon. Nettverket beregner deretter feilen mellom sin prediksjon og den faktiske svaret ved hjelp av en tapsfunksjon, som kvantifiserer hvor langt unna prediksjonen er fra korrekt svar. Ved tilbakepropagering blir denne feilen forplantet bakover gjennom nettverket ved hjelp av kjerneregelen i kalkulus. For hver nevron beregner algoritmen gradienten til tapet med hensyn til hver vekt og bias, og avgjør hvor mye hver parameter har bidratt til totalfeilen. Disse gradientene styrer parameteroppdateringene: vekter og bias justeres i motsatt retning av gradienten, skalert av en læringsrate som styrer steglengden. Prosessen gjentas over mange iterasjoner gjennom treningsdatasettet, og reduserer gradvis tapet og forbedrer nettverkets prediksjoner. Kombinasjonen av fremoverpropagering, tapsberegning, tilbakepropagering og parameteroppdateringer utgjør hele treningssyklusen som gjør det mulig for neurale nettverk å lære fra data.
| Arkitekturtype | Primært bruksområde | Nøkkeltrekk | Styrker | Begrensninger |
|---|---|---|---|---|
| Fremovermatede nettverk | Klassifisering, regresjon på strukturerte data | Informasjon flyter kun én vei | Enkle, rask trening, tolkbare | Kan ikke håndtere sekvensielle eller romlige data godt |
| Konvolusjonsnevrale nettverk (CNNs) | Bildedeteksjon, datamaskinsyn | Konvolusjonslag oppdager romlige trekk | Svært gode på å fange lokale mønstre, parameter-effektive | Krever store merkede bildedatasett |
| Rekurrerende nevrale nettverk (RNNs) | Sekvensielle data, tidsserier, NLP | Skjult tilstand bevarer minne over tidsskritt | Kan behandle sekvenser av varierende lengde | Lider av forsvinnende/eksploderende gradienter |
| Long Short-Term Memory (LSTM) | Langtrekkende avhengigheter i sekvenser | Minneceller med inngangs/glemsel/utgangsporter | Håndterer langtidshukommelse effektivt | Mer komplekse, tregere trening enn RNNs |
| Transformer-nettverk | Naturlig språkbehandling, store språkmodeller | Multi-head attention, parallell behandling | Svært paralleliserbare, fanger langtrekkende avhengigheter | Krever massive datakraftressurser |
| Generative Adversarial Networks (GANs) | Bildegenerering, syntetisk dataskaping | Generator og diskriminator konkurrerer | Kan generere realistisk syntetisk data | Vanskelig å trene, problemer med mode collapse |
Innføringen av aktiveringsfunksjoner er en av de viktigste innovasjonene i utformingen av neurale nettverk. Uten aktiveringsfunksjoner ville et neuralt nettverk være matematisk ekvivalent med én lineær transformasjon, uavhengig av hvor mange lag det har. Dette skyldes at sammensetningen av lineære funksjoner er lineær, noe som sterkt begrenser nettverkets evne til å lære komplekse mønstre. Aktiveringsfunksjoner løser dette ved å tilføre ikke-linearitet i hver nevron. ReLU (Rectified Linear Unit)-funksjonen, definert som f(x) = max(0, x), har blitt det mest populære valget i moderne dyp læring på grunn av sin beregningseffektivitet og treningsdyktighet i dype nettverk. Sigmoidfunksjonen, f(x) = 1/(1 + e^(-x)), komprimerer utgangene til et område mellom 0 og 1, og brukes ofte for binære klassifiseringsoppgaver. Tanh-funksjonen, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), gir utganger mellom -1 og 1 og presterer ofte bedre enn sigmoid i skjulte lag. Valget av aktiveringsfunksjon påvirker nettverkets læringsdynamikk, konvergenshastighet og sluttresultat i stor grad. Moderne arkitekturer bruker gjerne ReLU i skjulte lag for effektivitet og sigmoid eller softmax i utgangslag for sannsynlighetsestimering. Ikke-lineariteten som aktiveringsfunksjonene gir, gjør at neurale nettverk kan tilnærme enhver kontinuerlig funksjon, et fenomen kjent som universell tilnærmings-teorem, som forklarer deres bemerkelsesverdige allsidighet på tvers av ulike bruksområder.
Markedet for neurale nettverk har opplevd eksplosiv vekst, noe som gjenspeiler teknologiens sentrale rolle i moderne kunstig intelligens. Ifølge ferske markedsanalyser ble det globale programvaremarkedet for neurale nettverk verdsatt til omtrent 34,76 milliarder dollar i 2025 og forventes å nå 139,86 milliarder dollar innen 2030, tilsvarende en årlig vekstrate (CAGR) på 32,10 %. Det bredere markedet for neurale nettverk viser enda mer dramatisk ekspansjon, med anslag som tyder på vekst fra 34,05 milliarder dollar i 2024 til 385,29 milliarder dollar innen 2033, med en CAGR på 31,4 %. Denne eksplosive veksten drives av flere faktorer: økt tilgjengelighet av store datasett, utvikling av mer effektive treningsalgoritmer, utbredelsen av GPU og spesialisert AI-maskinvare, og omfattende bruk av neurale nettverk på tvers av bransjer. Ifølge Stanfords AI Index Report for 2025 rapporterte 78 % av organisasjoner at de brukte AI i 2024, opp fra 55 % året før, hvor neurale nettverk utgjorde ryggraden i de fleste bedrifts-AI-implementasjoner. Adopsjonen omfatter helsevesen, finans, produksjon, detaljhandel og nærmest alle andre sektorer, ettersom virksomheter ser konkurransefortrinnet neurale nettverksbaserte systemer gir for mønstergjenkjenning, prediksjon og beslutningstaking.
Neurale nettverk driver de mest avanserte AI-systemene som er i bruk i dag, inkludert ChatGPT, Perplexity, Google AI Overviews og Claude. Disse store språkmodellene er bygget på transformerbaserte neurale nettverksarkitekturer som bruker oppmerksomhetsmekanismer til å behandle og generere menneskelig språk med bemerkelsesverdig sofistikasjon. Transformer-arkitekturen, introdusert i 2017, revolusjonerte naturlig språkbehandling ved å muliggjøre parallell behandling av hele sekvenser heller enn sekvensiell behandling, noe som dramatisk forbedret treningseffektivitet og modellprestasjon. I sammenheng med merkevareovervåkning og AI-sitasjonssporing er forståelsen av neurale nettverk avgjørende fordi disse systemene bruker nettverkene til å forstå kontekst, hente relevant informasjon og generere svar som kan referere til eller sitere din merkevare, ditt domene eller innhold. AmICited utnytter kunnskap om hvordan neurale nettverk behandler og henter informasjon for å overvåke hvor merkevaren din vises i AI-genererte svar på tvers av flere plattformer. Etter hvert som neurale nettverk stadig forbedrer sin evne til å forstå semantisk mening og hente relevant informasjon, blir det stadig viktigere å overvåke merkevarens tilstedeværelse i AI-svar for å opprettholde synlighet og håndtere omdømmet på nettet i en tid med AI-drevet søk og innholdsgenerering.
Effektiv trening av neurale nettverk byr på flere betydelige utfordringer som forskere og praktikere må håndtere. Overtilpasning oppstår når et nettverk lærer treningsdataene for godt, inkludert støy og særegenheter, noe som resulterer i dårlig ytelse på nye, usette data. Dette er spesielt problematisk med dype nettverk som har mange parametere i forhold til treningsdatasettets størrelse. Undertilpasning er det motsatte problemet, der nettverket mangler tilstrekkelig kapasitet eller trening til å fange de underliggende mønstrene i dataene. Forsvinningsproblem for gradienten oppstår i svært dype nettverk der gradientene blir eksponentielt mindre bakover i nettverket, slik at vektene i de tidlige lagene oppdateres svært sakte eller ikke i det hele tatt. Eksploderende gradientproblem er det motsatte, hvor gradientene blir eksponentielt større og fører til ustabil trening. Moderne løsninger inkluderer batchnormalisering, som normaliserer laginput for å opprettholde stabil gradientflyt; residualforbindelser (skip connections), som lar gradienter flyte direkte gjennom lag; og gradientklipping, som begrenser gradientenes størrelse. Regulariseringsteknikker som L1- og L2-regularisering gir straff for store vekter og oppmuntrer til enklere modeller med bedre generalisering. Dropout deaktiverer tilfeldig nevroner under trening, forhindrer samtilpasning og forbedrer generalisering. Valg av optimeringsalgoritme (slik som Adam, SGD eller RMSprop) og læringsrate påvirker i stor grad treningseffektivitet og sluttresultat. Praktikere må nøye balansere modellkompleksitet, treningsdatasettets størrelse, regulariseringsstyrke og optimaliseringsparametere for å oppnå nettverk som lærer effektivt uten overtilpasning.
Utviklingen av nevrale nettverksarkitekturer har fulgt en klar kurs mot stadig mer sofistikerte mekanismer for informasjonsbehandling. Tidlige fremovermatede nettverk var begrenset til faste innganger og kunne ikke fange opp tidsmessige eller sekvensielle avhengigheter. Rekurrerende nevrale nettverk (RNNs) introduserte tilbakekoblinger som gjør at informasjon kan vedvare over tidsskritt, og dermed muliggjør behandling av sekvenser med varierende lengde. RNNs slet imidlertid med gradientflytproblemer og var iboende sekvensielle, noe som hindret parallellisering på moderne maskinvare. Long Short-Term Memory (LSTM)-nettverk løste noen av disse utfordringene med minneceller og portmekanismer, men forble grunnleggende sekvensielle. Gjennombruddet kom med transformernettverk, som erstattet tilbakekobling fullstendig med oppmerksomhetsmekanismer. Oppmerksomhetsmekanismen gjør at nettverket dynamisk kan fokusere på ulike deler av inngangen, og beregne vektede kombinasjoner av alle inndataelementer parallelt. Dette gjør at transformere kan fange opp langtrekkende avhengigheter effektivt, samtidig som de er fullt paralleliserbare på GPU-klynger. Transformer-arkitekturen, kombinert med massiv skala (moderne språkmodeller inneholder milliarder til billioner av parametere), har vist seg å være svært effektiv for naturlig språkbehandling, datamaskinsyn og multimodale oppgaver. Suksessen til transformere har ført til at de er blitt standardarkitektur for toppmoderne AI-systemer, inkludert alle store språkmodeller. Denne utviklingen viser hvordan arkitektoniske innovasjoner, kombinert med økte datakraftressurser og større datasett, fortsetter å flytte grensene for hva neurale nettverk kan oppnå.
Feltet for neurale nettverk utvikler seg raskt med flere lovende retninger. Neuromorfisk databehandling har som mål å lage maskinvare som ligner mer på biologiske nevrale nettverk, med potensiale for større energieffektivitet og regnekraft. Forskning på few-shot og zero-shot learning fokuserer på å la neurale nettverk lære fra svært få eksempler, mer likt menneskelig læring. Forklarbarhet og tolkbarhet har blitt stadig viktigere, med utvikling av teknikker for å forstå og visualisere hva neurale nettverk lærer, avgjørende for bruk i helse, finans og rettsvesen. Føderert læring muliggjør trening av neurale nettverk på distribuert data uten å sentralisere sensitiv informasjon, og adresserer personvernhensyn. Kvante-neurale nettverk representerer en grense hvor kvantedatabehandling kombineres med neurale nettverksarkitekturer, med potensial for eksponentielle hastighetsforbedringer på enkelte problemer. Multimodale neurale nettverk som integrerer tekst, bilder, lyd og video blir stadig mer avanserte og muliggjør mer helhetlige AI-systemer. Energieffektive neurale nettverk utvikles for å redusere de beregningsmessige og miljømessige kostnadene ved trening og implementering av store modeller. Etter hvert som neurale nettverk fortsetter å utvikle seg, blir deres integrasjon i AI-overvåkningssystemer som AmICited stadig viktigere for organisasjoner som ønsker å forstå og håndtere merkevarens tilstedeværelse i AI-generert innhold og svar på plattformer som ChatGPT, Perplexity, Google AI Overviews og Claude.
Neurale nettverk er inspirert av strukturen og funksjonen til biologiske nevroner i menneskehjernen. I hjernen kommuniserer nevroner gjennom elektriske signaler via synapser, som kan styrkes eller svekkes basert på erfaring. Kunstige neurale nettverk etterligner denne oppførselen ved å bruke matematiske modeller av nevroner koblet sammen gjennom vektede forbindelser, slik at systemet kan lære og tilpasse seg fra data på en måte som ligner på hvordan biologiske hjerner behandler informasjon og danner minner.
Tilbakepropagering er den primære algoritmen som gjør det mulig for neurale nettverk å lære. Under fremoverpropagering flyter data gjennom nettverkslagene og produserer prediksjoner. Nettverket beregner deretter feilen mellom predikert og faktisk utgang ved hjelp av en tapsfunksjon. I den bakovergående prosessen blir denne feilen propagert bakover gjennom nettverket ved hjelp av kjerneregelen i kalkulus, og beregner hvor mye hver vekt og bias har bidratt til feilen. Vektene justeres deretter i retning som minimerer feilen, vanligvis ved hjelp av gradientbasert optimalisering.
De viktigste nevrale nettverksarkitekturene inkluderer fremovermatede nettverk (data flyter kun én vei), konvolusjonsnevrale nettverk eller CNNs (optimalisert for bildebehandling), rekurrerende nevrale nettverk eller RNNs (designet for sekvensielle data), long short-term memory-nettverk eller LSTMs (forbedrede RNNs med minneceller), og transformernettverk (som bruker oppmerksomhetsmekanismer for parallell behandling). Hver arkitektur er spesialisert for ulike typer data og oppgaver, fra bildedeteksjon til naturlig språkbehandling.
Moderne AI-systemer som ChatGPT, Perplexity og Claude er bygget på transformerbaserte neurale nettverk, som bruker oppmerksomhetsmekanismer for effektiv språkprosessering. Disse neurale nettverkene gjør det mulig for systemene å forstå kontekst, generere sammenhengende tekst og utføre komplekse resonnementer. Neurale nettverks evne til å lære fra store datasett og fange opp intrikate mønstre i språk gjør dem essensielle for å bygge konversasjons-AI som kan forstå og svare på menneskelige forespørsler med bemerkelsesverdig nøyaktighet.
Vekter i neurale nettverk styrer styrken på forbindelsene mellom nevroner, og bestemmer hvor stor innflytelse hver inngang har på utgangen. Bias er ekstra parametere som forskyver aktiveringsterskelen til nevronene, slik at de kan aktiveres selv når inngangene er svake. Sammen utgjør vekter og bias de lærbare parameterne i nettverket som justeres under trening for å minimere prediksjonsfeil og gjøre det mulig for nettverket å lære komplekse mønstre fra data.
Aktiveringsfunksjoner tilfører ikke-linearitet til neurale nettverk, noe som gjør dem i stand til å lære komplekse, ikke-lineære relasjoner i data. Uten aktiveringsfunksjoner ville flere lag fortsatt bare resultere i lineære transformasjoner, noe som sterkt begrenser nettverkets læringsevne. Vanlige aktiveringsfunksjoner inkluderer ReLU (Rectified Linear Unit), sigmoid og tanh, som hver tilfører ulike typer ikke-linearitet som hjelper nettverket å fange opp intrikate mønstre og lage mer sofistikerte prediksjoner.
Skjulte lag er mellomlag mellom inngangs- og utgangslag hvor nettverket utfører mesteparten av sine beregninger. Disse lagene trekker ut og transformerer trekk fra rå inngangsdata til stadig mer abstrakte representasjoner. Dybden og bredden på de skjulte lagene avgjør nettverkets evne til å lære komplekse mønstre. Dypere nettverk med flere skjulte lag kan fange opp mer sofistikerte relasjoner i data, men krever mer datakraft og nøye trening for å unngå overtilpasning.
Begynn å spore hvordan AI-chatbots nevner merkevaren din på tvers av ChatGPT, Perplexity og andre plattformer. Få handlingsrettede innsikter for å forbedre din AI-tilstedeværelse.
Transformer-arkitektur er et nevralt nettverksdesign som bruker selvoppmerksomhetsmekanismer for å behandle sekvensielle data parallelt. Det driver ChatGPT, Cla...
Navigasjonsstruktur er systemet som organiserer nettsidens sider og lenker for å veilede brukere og AI-roboter. Lær hvordan det påvirker SEO, brukeropplevelse o...

Lær hva innholdsbeskjæring for KI er, hvordan det fungerer, ulike beskjæringsmetoder og hvorfor det er essensielt for å implementere effektive KI-modeller på ed...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.