
Forespørselsforbedring
Forespørselsforbedring er den iterative prosessen med å optimalisere søkefraser for bedre resultater i AI-søkemotorer. Lær hvordan det fungerer på tvers av Chat...
13 min lesing
Forespørselsreformulering er prosessen der AI-systemer tolker, omstrukturerer og forbedrer brukerforespørsler for å øke nøyaktigheten og relevansen i informasjonsinnhenting. Den omformer enkle eller tvetydige brukerinnspill til mer detaljerte, kontekstrike versjoner som samsvarer med AI-systemets forståelse, noe som muliggjør mer presise og omfattende svar.
Forespørselsreformulering er prosessen der AI-systemer tolker, omstrukturerer og forbedrer brukerforespørsler for å øke nøyaktigheten og relevansen i informasjonsinnhenting. Den omformer enkle eller tvetydige brukerinnspill til mer detaljerte, kontekstrike versjoner som samsvarer med AI-systemets forståelse, noe som muliggjør mer presise og omfattende svar.
Forespørselsreformulering er prosessen med å transformere, utvide eller omskrive en brukers opprinnelige søkeforespørsel for bedre å samsvare med det underliggende informasjonsinnhentingssystemets kapabiliteter og brukerens faktiske hensikt. I sammenheng med kunstig intelligens og naturlig språkprosessering (NLP), bygger forespørselsreformulering bro over det kritiske gapet mellom hvordan brukere naturlig uttrykker sine informasjonsbehov og hvordan AI-systemer tolker og behandler disse forespørslene. Denne teknikken er avgjørende i moderne AI-systemer fordi brukere ofte formulerer forespørsler upresist, bruker fagspråk inkonsekvent, eller utelater kontekstoplysninger som ville økt innhentingsnøyaktigheten. Forespørselsreformulering opererer i skjæringspunktet mellom informasjonsinnhenting, semantisk forståelse og maskinlæring, og gjør systemene i stand til å generere mer relevante resultater ved å tolke forespørsler gjennom flere linser—enten via synonymutvidelse, kontekstuell berikelse eller strukturell omorganisering. Ved å reformulere forespørsler intelligent, kan AI-systemer dramatisk forbedre svarkvaliteten, redusere tvetydighet og sikre at innhentet informasjon treffer brukerens hensikt mer presist.
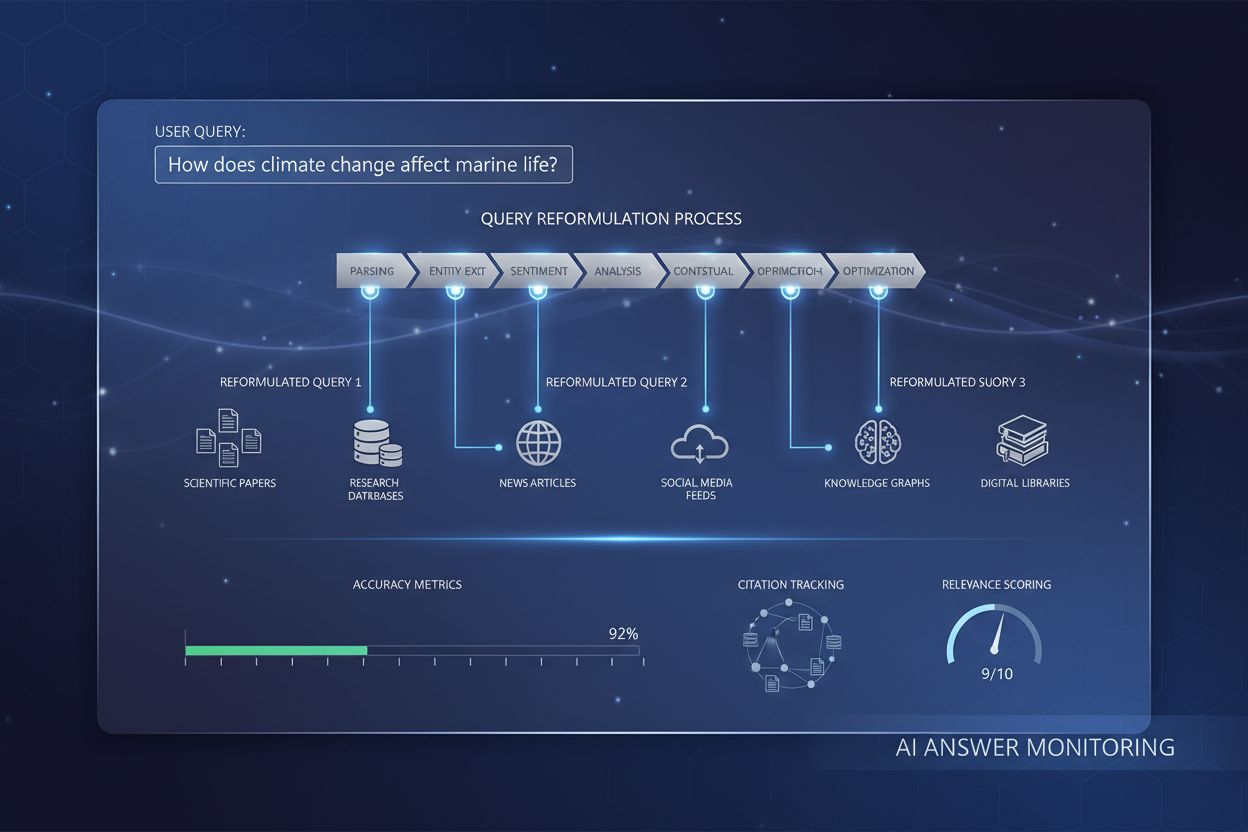
Forespørselsreformuleringssystemer opererer typisk gjennom fem sammenkoblede komponenter som samarbeider for å transformere rå brukerinnspill til optimaliserte søkeforespørsler. Inndataparsing bryter ned den opprinnelige forespørselen i dens bestanddeler, identifiserer nøkkelord, fraser og strukturelle elementer. Enhetsekstraksjon identifiserer navngitte entiteter (personer, steder, organisasjoner, produkter) og domene-spesifikke begreper med semantisk betydning. Sentimentanalyse ivaretar den emosjonelle tonen eller vurderende holdningen i den opprinnelige forespørselen, slik at reformulerte versjoner beholder brukerens perspektiv. Kontekstanalyse inkorporerer sesjonshistorikk, brukerprofilinformasjon og domenekunnskap for å berike forespørselen med implisitt mening. Spørsmålsgenerering konverterer deklarative utsagn eller fragmenter til velstrukturerte spørsmål som innhentingssystemer kan behandle mer effektivt.
| Komponent | Formål | Eksempel |
|---|---|---|
| Inndataparsing | Tokeniserer og segmenterer forespørselen i meningsfulle enheter | “beste Python-biblioteker” → [“beste”, “Python”, “biblioteker”] |
| Enhetsekstraksjon | Identifiserer navngitte entiteter og domenebegreper | “Apples nyeste iPhone” → Enhet: Apple (selskap), iPhone (produkt) |
| Sentimentanalyse | Bevarer vurderende tone og brukers perspektiv | “forferdelig kundeservice” → Beholder negativt sentiment i reformuleringen |
| Kontekstanalyse | Inkluderer sesjonshistorikk og domenekunnskap | Forrige forespørsel om “maskinlæring” påvirker nåværende “nevrale nettverk”-forespørsel |
| Spørsmålsgenerering | Gjør fragmenter om til strukturerte spørsmål | “Python-feilsøking” → “Hvordan feilsøker jeg Python-kode?” |
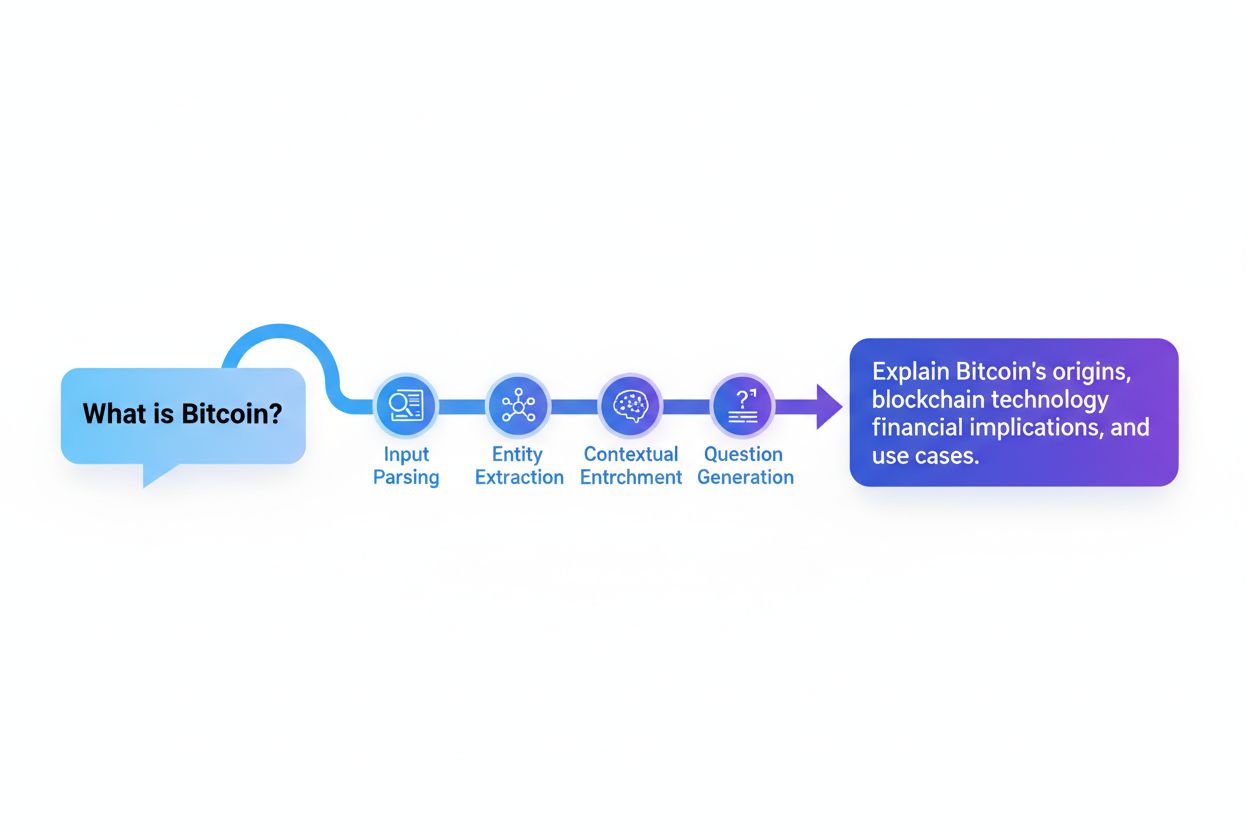
Forespørselsreformuleringsprosessen følger en systematisk seks-trinns metodikk designet for gradvis å forbedre forespørselskvalitet og relevans:
Parsing og normalisering av innspill
Ekstraksjon av entiteter og begreper
Bevaring av sentiment og hensikt
Kontekstuell berikelse
Forespørselsekspansjon og synonymsgenerering
Optimalisering og evaluering
Forespørselsreformulering benytter et bredt spekter av teknikker fra tradisjonelle leksikalske til avanserte nevrale metoder. Synonymbasert ekspansjon bruker etablerte ressurser som WordNet, word embeddings som Word2Vec og GloVe, samt kontekstuelle modeller som BERT for å identifisere semantisk lignende termer. Forespørselsrelaksasjon løsner gradvis forespørselsbegrensninger for å øke recall når innledende resultater er utilstrekkelige—for eksempel ved å fjerne sjeldne termer eller utvide datoperioder. Brukerfeedback og sesjonskontekst integreres slik at systemene kan lære av brukerinteraksjoner, og raffinere reformuleringer basert på hvilke resultater brukerne faktisk finner relevante. Transformerbaserte omskrivere som T5 (Text-to-Text Transfer Transformer) og GPT-modeller genererer helt nye forespørselsformuleringer ved å lære mønstre fra store treningsdatasett av forespørselspar. Hybride tilnærminger kombinerer flere teknikker—for eksempel ved å bruke regelbasert synonymutvidelse for høy-konfidens-termer, mens nevrale modeller benyttes for tvetydige fraser. Implementasjoner i praksis bruker ofte ensemble-metoder som genererer flere reformuleringer og rangerer dem med lærte relevansmodeller. For eksempel kan e-handelsplattformer kombinere domene-spesifikke synonymordbøker med BERT-embeddings for å håndtere både standardisert produktspråk og brukerslang, mens medisinske søkesystemer kan bruke spesialiserte ontologier sammen med transformer-modeller for å sikre klinisk nøyaktighet.
Forespørselsreformulering gir betydelige forbedringer på tvers av flere dimensjoner av AI-systemytelse og brukeropplevelse:
Bedre innhentingsnøyaktighet: Reformulerte forespørsler fanger brukerens hensikt mer presist, noe som gir mer kvalitative innhentede dokumenter og mer relevante AI-genererte svar. Ved å utvide forespørsler med synonymer og relaterte begreper, henter systemene dokumenter som kan bruke andre termer enn den opprinnelige forespørselen, og øker sjansen for å finne virkelig relevant informasjon dramatisk.
Økt recall og dekning: Forespørselsekspansjon øker antall relevante dokumenter ved å utforske semantiske variasjoner og relaterte begreper. Dette er spesielt verdifullt i spesialiserte domener der terminologien varierer mye, slik at brukere ikke går glipp av relevant informasjon på grunn av ordvalg.
Redusert tvetydighet og tydeliggjøring: Reformuleringsprosesser avklarer vage eller tvetydige forespørsler ved å inkludere kontekst og generere flere tolkninger. Dette gjør det mulig å håndtere forespørsler som “apple” (frukt vs. selskap) ved å generere kontekstavhengige reformuleringer som henter riktige resultater.
Bedre brukeropplevelse og tilfredshet: Brukere får mer relevante resultater raskere, og behovet for å raffinere egne søk reduseres. Færre feilslåtte søk og mer nøyaktige førstesvar gir bedre brukertilfredshet og lavere kognitiv belastning.
Skalerbarhet og effektivitet: Reformulering gjør systemene i stand til å håndtere brukere med varierende ordforråd, kunnskapsnivå og språkbakgrunn. En enkelt reformuleringsmotor kan betjene brukere på tvers av domener og språk, noe som øker skalerbarheten uten tilsvarende økning i infrastruktur.
Kontinuerlig forbedring og læring: Forespørselsreformuleringssystemer kan trenes på brukerinteraksjonsdata, og stadig forbedre reformuleringene basert på hvilke varianter som gir gode resultater. Dette skaper en positiv spiral hvor systemenes ytelse forbedres over tid etter hvert som mer brukerdata samles inn.
Domenetilpasning og spesialisering: Reformuleringsteknikker kan finjusteres for spesifikke domener (medisinsk, juridisk, teknisk) ved å trene på domene-spesifikke forespørselspar og inkorporere domeneontologier. Dette gjør spesialiserte systemer i stand til å håndtere domeneterminologi mer presist enn generiske tilnærminger.
Robusthet mot forespørselsvariasjoner: Systemene blir robuste mot skrivefeil, grammatiske feil og dagligtale ved å reformulere forespørsler til standardiserte former. Dette er spesielt nyttig for stemmebaserte grensesnitt og mobilsøk hvor inndata ofte varierer.
Forespørselsreformulering spiller en kritisk rolle for nøyaktigheten og påliteligheten til AI-genererte svar, og er dermed essensiell for AI-svarsovervåkingsplattformer som AmICited.com. Når AI-systemer reformulerer forespørsler før de genererer svar, påvirker kvaliteten på disse reformuleringene direkte om AI-en henter passende kilder og genererer nøyaktige, velbegrunnede svar. Dårlig reformulerte forespørsler kan føre til at AI-systemer henter irrelevante dokumenter, noe som gjør at svarene mangler forankring eller siterer upassende kilder. I sammenheng med AI-overvåking og siteringssporing er det avgjørende å forstå hvordan forespørsler reformuleres for å verifisere at AI-systemene faktisk besvarer brukerens opprinnelige spørsmål og ikke en fordreid versjon av det. AmICited.com sporer hvordan AI-systemer reformulerer forespørsler for å sikre at kildene som siteres i AI-genererte svar faktisk er relevante for brukerens opprinnelige spørsmål, og ikke bare for en feiltolket reformulering. Denne overvåkingen er spesielt viktig fordi forespørselsreformulering skjer usynlig for sluttbrukeren—de ser kun det endelige svaret og referansene, uten å vite hvordan underliggende forespørsel ble transformert. Ved å analysere reformuleringsmønstre kan AI-overvåkingsplattformer identifisere når AI-en gir svar basert på reformulerte forespørsler som avviker betydelig fra brukerens hensikt, og dermed flagge potensielle nøyaktighetsproblemer før de når brukerne. I tillegg hjelper innsikt i reformulering plattformene med å vurdere om AI-systemene håndterer tvetydige forespørsler riktig—ved å generere flere reformuleringer og syntetisere informasjon på tvers av dem—eller om de gjør ubegrunnede antakelser om brukerens hensikt.
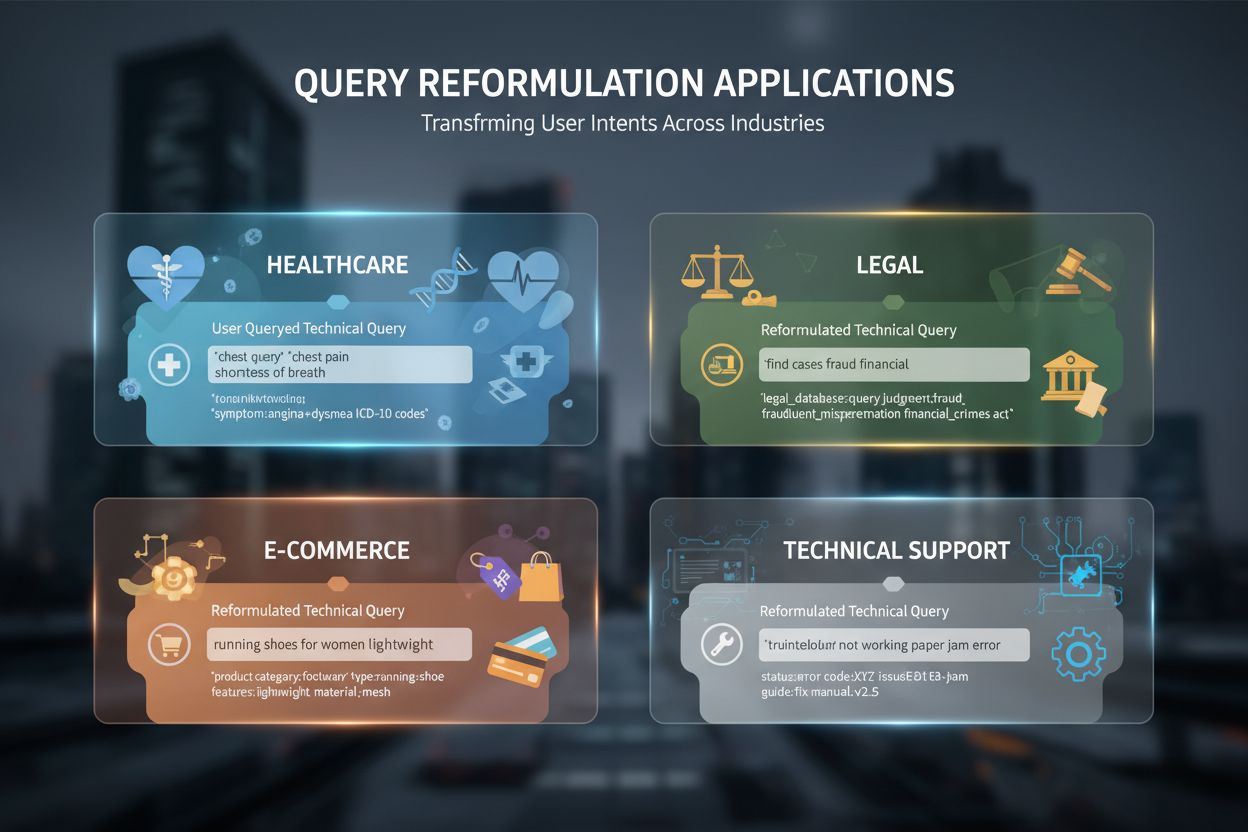
Forespørselsreformulering har blitt uunnværlig i en rekke AI-drevne applikasjoner og bransjer. I helsevesen og medisinsk forskning håndterer forespørselsreformulering kompleksiteten i medisinsk terminologi der pasienter kan søke etter “hjerteinfarkt” mens faglitteraturen bruker “myokardinfarkt”—reformulering lukker dette vokabulargapet for å hente klinisk korrekt informasjon. Juridiske dokumentsystemer bruker forespørselsreformulering for å håndtere presist, arkaisk språk i juridiske dokumenter samtidig som moderne søkeord aksepteres, slik at advokater finner relevante presedenser uavhengig av formulering. Teknisk supportsystemer reformulerer brukerforespørsler for å matche kunnskapsbaseartikler ved å konvertere dagligdagse problemstillinger (“PC-en min er treg”) til tekniske termer (“systemytelsesreduksjon”) og hente riktige feilsøkingsveiledninger. E-handelsøkoptimalisering benytter forespørselsreformulering for å håndtere produktsøk der brukere kan lete etter “joggesko” mens katalogen bruker “treningssko” eller spesifikke merkenavn, slik at kundene finner det de leter etter uansett terminologi. Samtale-AI og chatboter bruker forespørselsreformulering for å holde på konteksten i samtaler over flere runder, og reformulerer oppfølgingsspørsmål slik at implisitt kontekst fra tidligere utvekslinger tas med. Retrieval-Augmented Generation (RAG)-systemer er sterkt avhengige av forespørselsreformulering for å sikre at innhentet kontekst faktisk er relevant for brukerens spørsmål og direkte påvirker kvaliteten på genererte svar. For eksempel kan et RAG-system som skal svare på “Hvordan optimaliserer jeg databaseforespørsler?” reformulere dette til flere varianter som “optimalisering av databaseytelse”, “SQL-optimaliseringsteknikker” og “forespørselsutførelsesplaner” for å hente omfattende kontekst før det genererer et detaljert svar.
Til tross for fordelene, medfører forespørselsreformulering flere betydelige utfordringer som fagpersoner må forholde seg til. Beregningmessig kompleksitet øker betydelig når man genererer flere reformuleringer og rangerer dem etter relevans—hver reformulering krever prosessering, og man må balansere kvalitetsgevinster mot responstid, særlig i sanntidsapplikasjoner. Kvaliteten på treningsdata er avgjørende for reformuleringseffektivitet; systemer trent på dårlige forespørselspar eller skjeve datasett vil videreføre slike skjevheter, og i verste fall forsterke eksisterende problemer. Risiko for over-reformulering oppstår når systemer genererer så mange forespørselsvarianter at de mister fokus på opprinnelig hensikt, og henter mer og mer perifere resultater som forvirrer fremfor å avklare. Domene-spesifikk tilpasning krever betydelig innsats—modeller trent på generelle nettforespørsler gir ofte dårlige resultater i spesialiserte domener som medisin eller juss uten omfattende spesialtilpasning. Presisjon mot recall-balansen er et grunnleggende kompromiss: aggressiv forespørselsekspansjon øker recall, men kan senke presisjonen ved å hente irrelevante resultater, mens konservativ reformulering ivaretar presisjon, men kan gå glipp av relevante dokumenter. Potensiell skjevhetsintroduksjon kan oppstå dersom reformuleringssystemene koder inn samfunnsmessige skjevheter fra treningsdata, og dermed forsterker diskriminering i søkeresultater eller AI-genererte svar—for eksempel kan reformulering av “sykepleier”-forespørsler uforholdsmessig hente opp resultater assosiert med kvinner dersom treningsdataene reflekterer historiske kjønnsroller.
Forespørselsreformulering fortsetter å utvikle seg raskt etter hvert som AI-kapasitetene øker og nye teknikker dukker opp. Fremskritt innen LLM-basert reformulering muliggjør mer sofistikerte, kontekstbevisste forespørselstransformasjoner, ettersom store språkmodeller bedre forstår nyanser i brukerhensikt og genererer naturlige, semantisk rike reformuleringer. Multimodal AI-integrasjon vil utvide forespørselsreformulering utover tekst, slik at bilder, lyd og video kan reformuleres til tekstbeskrivelser som innhentingssystemene kan prosessere. Personalisering og læring gjør at forespørselsreformuleringssystemer kan tilpasse seg individuelle brukeres preferanser, vokabular og søkemønstre, og generere stadig mer personlige reformuleringer som reflekterer hver brukers unike kommunikasjonsstil. Sanntids adaptiv reformulering muliggjør dynamisk reformulering av forespørsler basert på mellomresultater, slik at innledende reformuleringer kan informere videre forbedringer. Kunnskapsgrafintegrasjon gjør det mulig for reformuleringssystemer å bruke strukturert kunnskap om entiteter og relasjoner, og generere mer semantisk presise reformuleringer forankret i eksplisitte kunnskapsrepresentasjoner. Fremvoksende standarder for evaluering og benchmarking av forespørselsreformulering vil gjøre det lettere å sammenligne systemer og drive frem bransjeomfattende forbedringer i reformuleringskvalitet og konsistens.
Forespørselsreformulering er den overordnede prosessen med å transformere en forespørsel for å forbedre innhenting, mens forespørselsekspansjon er en spesifikk teknikk innen reformulering som legger til synonymer og relaterte termer. Forespørselsekspansjon fokuserer på å utvide søkeomfanget, mens reformulering omfatter flere teknikker, inkludert parsing, enhetsekstraksjon, sentimentanalyse og kontekstuell berikelse for å fundamentalt forbedre forespørselskvaliteten.
Forespørselsreformulering hjelper AI-systemer å bedre forstå brukerens hensikt ved å klargjøre tvetydige begreper, legge til kontekst og generere flere tolkninger av den opprinnelige forespørselen. Dette fører til henting av mer relevante kildedokumenter, som igjen gjør at AI kan generere mer nøyaktige, godt begrunnede svar med riktige referanser.
Ja, forespørselsreformulering kan fungere som et sikkerhetslag ved å standardisere og rense brukerinnspill før de når hoved-AI-systemet. En spesialisert reformuleringsagent kan oppdage og nøytralisere potensielt skadelige innspill, filtrere mistenkelige mønstre og transformere forespørsler til trygge, standardiserte formater som reduserer sårbarheten for prompt injection-angrep.
I Retrieval-Augmented Generation (RAG)-systemer er forespørselsreformulering avgjørende for å sikre at innhentede kontekstdokumenter faktisk er relevante for brukerens spørsmål. Ved å reformulere forespørsler til flere varianter kan RAG-systemer hente mer omfattende og variert kontekst, noe som direkte forbedrer kvaliteten og nøyaktigheten på genererte svar.
Implementering innebærer vanligvis å velge egnede teknikker for ditt bruksområde: bruk synonymbasert ekspansjon med BERT eller Word2Vec for semantisk likhet, benytt transformer-modeller som T5 eller GPT for nevrale reformuleringer, inkorporer domene-spesifikke ontologier for spesialiserte felt, og implementer tilbakemeldingssløyfer for kontinuerlig å forbedre reformuleringene basert på brukerinteraksjoner og innhentingsmetrikker.
Beregningkostnadene varierer etter teknikk: enkel synonynekspansjon er lettvekter, mens transformerbasert reformulering krever betydelige GPU-ressurser. Ved å bruke mindre spesialiserte modeller for reformulering og større modeller kun for endelig svargenerering kan man optimalisere kostnadene. Mange systemer benytter caching og batch-prosessering for å fordele beregningskostnadene over flere forespørsler.
Forespørselsreformulering påvirker siteringsnøyaktigheten direkte fordi den reformulerte forespørselen avgjør hvilke dokumenter som hentes og siteres. Dersom reformuleringen avviker betydelig fra den opprinnelige brukerhensikten, kan AI sitere kilder som er relevante for den reformulerte forespørselen snarere enn det opprinnelige spørsmålet. AI-overvåkingsplattformer som AmICited sporer disse transformasjonene for å sikre at referansene faktisk er relevante for det brukerne faktisk spurte om.
Ja, forespørselsreformulering kan forsterke eksisterende skjevheter dersom treningsdata reflekterer samfunnsmessige fordommer. For eksempel kan reformulering av visse forespørsler uforholdsmessig hente resultater knyttet til spesielle demografier. Å redusere dette krever nøye utvalg av datasett, mekanismer for skjevhetsdeteksjon, varierte treningsdata og kontinuerlig overvåking av reformuleringsresultater for rettferdighet og representativitet.
Forespørselsreformulering påvirker hvordan AI-systemer forstår og siterer innholdet ditt. AmICited sporer disse transformasjonene for å sikre at merkevaren din får korrekt attribusjon i AI-genererte svar.
Forespørselsforbedring er den iterative prosessen med å optimalisere søkefraser for bedre resultater i AI-søkemotorer. Lær hvordan det fungerer på tvers av Chat...
Lær hvordan optimalisering av forespørselsekspansjon forbedrer AI-søkeresultater ved å bygge bro over vokabulargap. Oppdag teknikker, utfordringer og hvorfor de...

Samtaleforespørsler er naturlige språkspørsmål stilt til AI-systemer som ChatGPT og Perplexity. Lær hvordan de skiller seg fra nøkkelordssøk og påvirker merkeov...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.